Recognition: no theorem link
FORGE: Fragment-Oriented Ranking and Generation for Context-Aware Molecular Optimization
Pith reviewed 2026-05-12 05:21 UTC · model grok-4.3
The pith
FORGE reformulates molecular optimization as context-aware fragment editing with mined pairs, letting a 0.6B model outperform larger language models and graph methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
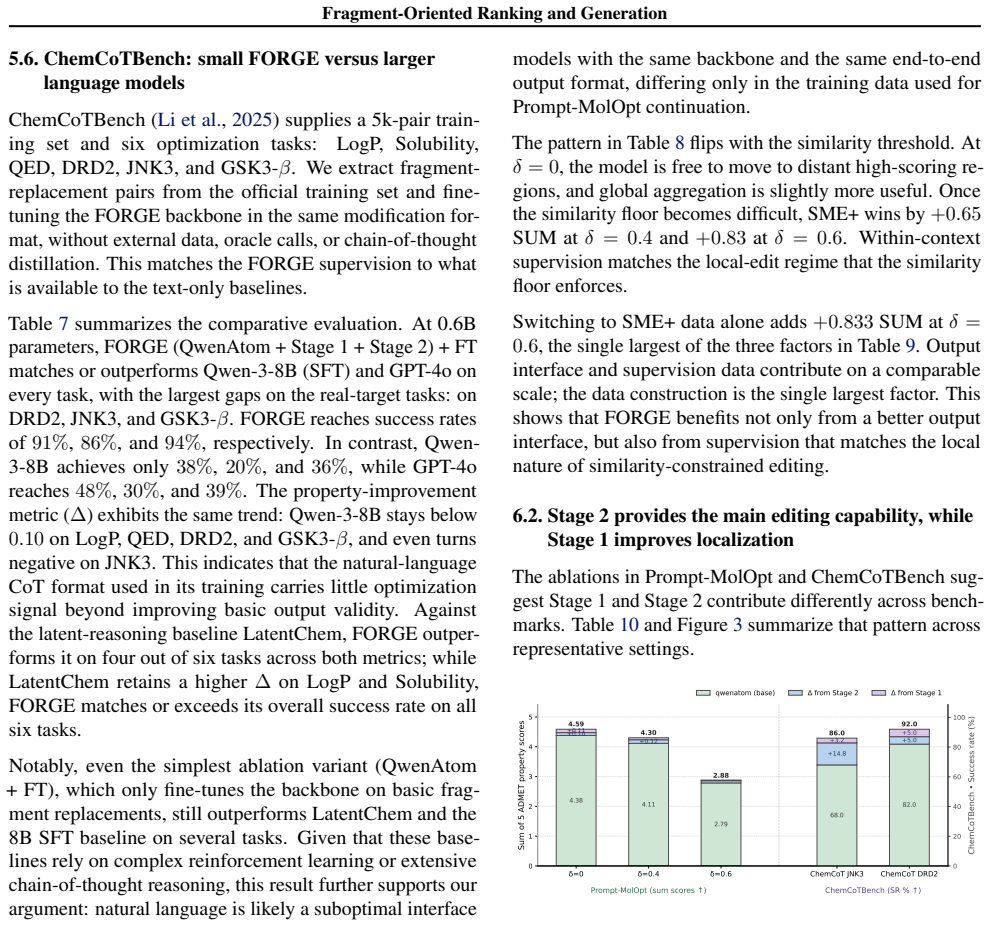
FORGE is a two-stage framework that reformulates molecular optimization as context-aware local editing. Stage 1 ranks candidate fragments by their property contribution under the full molecular context using automatically mined and verified low-to-high edit pairs; Stage 2 generates the explicit fragment replacements. Built on a 0.6B language model that adapts to unseen black-box objectives through in-context demonstrations, the method outperforms prior approaches including substantially larger language models and graph methods on Prompt-MolOpt, PMO-1k, and ChemCoTBench.
What carries the argument
Two-stage ranking-then-generation on mined low-to-high edit pairs that evaluates each fragment's effect inside the complete molecule rather than through language prompts.
If this is right
- Molecular optimization can proceed without expensive human text annotations while still preserving structural similarity to the starting compound.
- A compact model suffices for black-box objectives once fragment contributions are ranked in full context.
- Explicit fragment replacements reduce chemical hallucinations compared with free-form sequence generation.
- Performance gains on standard benchmarks arise from local edits whose effects are measured against the surrounding molecule rather than global text conditioning.
Where Pith is reading between the lines
- The same mining and ranking approach could be tested on other structured objects such as proteins or materials where local edits must be evaluated inside global context.
- If fragment effects prove strongly context-dependent, the ranked candidates themselves might surface previously hidden structure-property patterns for human inspection.
- Extending the edit-pair mining to multi-step trajectories could turn the method into a general planner for longer optimization sequences.
Load-bearing premise
Automatically mined and verified low-to-high edit pairs supply a sufficient, unbiased chemical prior that captures the strong context dependence of fragment effects better than natural-language supervision.
What would settle it
A new benchmark or test set of molecules where FORGE produces more invalid structures or lower property gains than larger language-model baselines would falsify the claim that the mined pairs provide a superior prior.
Figures



read the original abstract
Molecular optimization seeks to improve a molecule through small structural edits while preserving similarity to the starting compound. Recent language-model approaches typically treat this task as prompt-conditioned sequence generation. However, relying on natural language introduces an inherent data-scaling bottleneck, often leads to chemical hallucinations, and ignores the strong context dependence of fragment effects. We present FORGE, a two-stage framework that reformulates molecular optimization as context-aware local editing. By utilizing automatically mined, verified low-to-high edit pairs instead of expensive human text annotations, Stage 1 ranks candidate fragments by their property contribution under the full molecular context to inject chemical prior, and Stage 2 generates explicit fragment replacements. Built on a compact 0.6B language model, FORGE further adapts to unseen black-box objectives through in-context demonstrations. Across Prompt-MolOpt, PMO-1k and ChemCoTBench, FORGE consistently outperforms prior methods, including substantially larger language models and graph methods. These results highlight the value of explicit fragment-level supervision as a more easily obtainable, scalable, and hallucination-less alternative to natural language training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FORGE, a two-stage framework for molecular optimization that reformulates the task as context-aware local editing. Stage 1 ranks candidate fragments by their property contribution under full molecular context using automatically mined and verified low-to-high edit pairs; Stage 2 generates explicit fragment replacements. The approach is built on a compact 0.6B language model that adapts to unseen black-box objectives via in-context demonstrations, and it reports consistent outperformance over prior methods (including substantially larger LMs and graph methods) on the Prompt-MolOpt, PMO-1k, and ChemCoTBench benchmarks.
Significance. If the empirical results prove robust, the work demonstrates that explicit fragment-level supervision derived from mined edit pairs can serve as a scalable, chemically grounded, and hallucination-resistant alternative to natural-language supervision for molecular optimization, potentially lowering data requirements while preserving context dependence of fragment effects.
major comments (2)
- [Methods (likely §3–4)] The central claim that automatically mined low-to-high edit pairs supply an unbiased chemical prior capturing strong context dependence of fragment effects (stronger than natural-language supervision) rests on the mining/verification pipeline. The methods section provides only a high-level description of this pipeline and does not specify the mining algorithm, the verification oracle, or controls against selection bias or leakage from the property predictors later used in benchmarking; without these details the reported gains on Prompt-MolOpt, PMO-1k and ChemCoTBench cannot be evaluated for generalizability.
- [Experimental results (likely §5)] The experimental results section claims consistent outperformance but supplies no information on data splits, baseline re-implementations, statistical significance tests, or whether the same property predictors appear in both the mining stage and the evaluation; these omissions are load-bearing for the claim that FORGE outperforms larger LMs and graph methods.
minor comments (2)
- [Abstract] The abstract refers to “substantially larger language models” without naming the models or reporting parameter counts; this comparison should be made explicit.
- [Introduction and Methods] Notation for fragment ranking scores and in-context demonstration formatting is introduced without a dedicated notation table or early definition, which reduces readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important areas for improving clarity and reproducibility. We will revise the manuscript to provide the requested details on the mining pipeline and experimental setup while preserving the core contributions.
read point-by-point responses
-
Referee: [Methods (likely §3–4)] The central claim that automatically mined low-to-high edit pairs supply an unbiased chemical prior capturing strong context dependence of fragment effects (stronger than natural-language supervision) rests on the mining/verification pipeline. The methods section provides only a high-level description of this pipeline and does not specify the mining algorithm, the verification oracle, or controls against selection bias or leakage from the property predictors later used in benchmarking; without these details the reported gains on Prompt-MolOpt, PMO-1k and ChemCoTBench cannot be evaluated for generalizability.
Authors: We agree that the original submission described the mining/verification pipeline at a high level. In the revised manuscript we will expand Section 3 with the exact mining algorithm (including fragmentation rules, property-delta thresholds, and pair extraction logic), the verification oracle (chemical validity filters plus property-improvement checks), and explicit controls for selection bias and leakage. We will also document the data partitioning that keeps mining data disjoint from the evaluation benchmarks and confirm that property predictors used during mining are independent of those used in benchmarking. revision: yes
-
Referee: [Experimental results (likely §5)] The experimental results section claims consistent outperformance but supplies no information on data splits, baseline re-implementations, statistical significance tests, or whether the same property predictors appear in both the mining stage and the evaluation; these omissions are load-bearing for the claim that FORGE outperforms larger LMs and graph methods.
Authors: We acknowledge these omissions in the experimental reporting. The revised Section 5 will specify the data splits for each benchmark, provide implementation details and hyperparameter settings for all re-implemented baselines, report statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests with p-values), and explicitly state that the property predictors employed in the mining stage are distinct from those used in evaluation, thereby eliminating leakage. revision: yes
Circularity Check
No circularity; empirical benchmark claims independent of self-referential steps
full rationale
The paper describes a two-stage framework (ranking then generation) that relies on automatically mined edit pairs as chemical prior and evaluates via external benchmarks (Prompt-MolOpt, PMO-1k, ChemCoTBench). No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central outperformance claim rests on comparative results rather than any reduction of outputs to inputs by construction. The mining/verification process is noted as a potential empirical weakness but does not constitute circularity under the defined patterns, as no self-definition or ansatz smuggling is exhibited.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Fragment effects on molecular properties are strongly context-dependent
- domain assumption Automatically mined low-to-high edit pairs can be verified and provide unbiased chemical prior
Reference graph
Works this paper leans on
-
[1]
Genmol: A drug discovery generalist with discrete diffusion , author=. arXiv preprint arXiv:2501.06158 , year=
-
[2]
Advances in Neural Information Processing Systems , volume=
Molecule generation with fragment retrieval augmentation , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Nature communications , volume=
Chemistry-intuitive explanation of graph neural networks for molecular property prediction with substructure masking , author=. Nature communications , volume=. 2023 , publisher=
work page 2023
-
[4]
Nature Machine Intelligence , volume=
Leveraging language model for advanced multiproperty molecular optimization via prompt engineering , author=. Nature Machine Intelligence , volume=. 2024 , publisher=
work page 2024
-
[5]
Advances in neural information processing systems , volume=
Sample efficiency matters: a benchmark for practical molecular optimization , author=. Advances in neural information processing systems , volume=
-
[6]
Beyond Chemical QA: Evaluating LLM's Chemical Reasoning with Modular Chemical Operations , author=. arXiv preprint arXiv:2505.21318 , year=
-
[7]
Lico: Large language models for in-context molecular optimization , author=. arXiv preprint arXiv:2406.18851 , year=
-
[8]
arXiv preprint arXiv:2602.07075 , year=
Latentchem: From textual cot to latent thinking in chemical reasoning , author=. arXiv preprint arXiv:2602.07075 , year=
-
[9]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
mmpdb: An Open-Source Matched Molecular Pair Platform for Large Multiproperty Data Sets , journal =
Dalke, Andrew and Hert, J. mmpdb: An Open-Source Matched Molecular Pair Platform for Large Multiproperty Data Sets , journal =. 2018 , doi =
work page 2018
-
[11]
Gaulton, Anna and Bellis, Louisa J. and Bento, A. Patricia and Chambers, Jon and Davies, Mark and Hersey, Anne and Light, Yvonne and McGlinchey, Shaun and Michalovich, David and Al-Lazikani, Bissan and Overington, John P. , title =. Nucleic Acids Research , volume =. 2012 , month =. doi:10.1093/nar/gkr777 , url =
-
[12]
arXiv preprint arXiv:2510.08744 , year=
Graph diffusion transformers are in-context molecular designers , author=. arXiv preprint arXiv:2510.08744 , year=
-
[13]
Nature machine intelligence , volume=
A deep generative model for molecule optimization via one fragment modification , author=. Nature machine intelligence , volume=. 2021 , publisher=
work page 2021
-
[14]
Journal of chemical information and modeling , volume=
Exposing the limitations of molecular machine learning with activity cliffs , author=. Journal of chemical information and modeling , volume=. 2022 , publisher=
work page 2022
-
[15]
International conference on machine learning , pages=
Junction tree variational autoencoder for molecular graph generation , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[16]
Advances in neural information processing systems , volume=
Graph convolutional policy network for goal-directed molecular graph generation , author=. Advances in neural information processing systems , volume=
-
[17]
Artificial intelligence review , volume=
Machine learning in drug discovery: a review , author=. Artificial intelligence review , volume=. 2022 , publisher=
work page 2022
-
[18]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Graph polish: A novel graph generation paradigm for molecular optimization , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2021 , publisher=
work page 2021
-
[19]
Jannik Philipp Roth , title =. ChemRxiv , volume =. 2026 , doi =. https://chemrxiv.org/doi/pdf/10.26434/chemrxiv.15002302/v1 , abstract =
-
[20]
arXiv preprint arXiv:2505.22252 , year=
B-XAIC Dataset: Benchmarking Explainable AI for Graph Neural Networks Using Chemical Data , author=. arXiv preprint arXiv:2505.22252 , year=
-
[21]
arXiv preprint arXiv:2508.15015 , year=
Fragment-Wise Interpretability in Graph Neural Networks via Molecule Decomposition and Contribution Analysis , author=. arXiv preprint arXiv:2508.15015 , year=
-
[22]
Seyone Chithrananda, Gabriel Grand, Bharath Ramsun- dar, et al
ChemBERTa: large-scale self-supervised pretraining for molecular property prediction , author=. arXiv preprint arXiv:2010.09885 , year=
-
[23]
Gp-molformer: A foundation model for molecular generation , author=. Digital Discovery , volume=. 2025 , publisher=
work page 2025
-
[24]
arXiv preprint arXiv:2601.15279 , year=
MolecularIQ: Characterizing Chemical Reasoning Capabilities Through Symbolic Verification on Molecular Graphs , author=. arXiv preprint arXiv:2601.15279 , year=
-
[25]
arXiv preprint arXiv:2407.18897 , year=
Small molecule optimization with large language models , author=. arXiv preprint arXiv:2407.18897 , year=
-
[26]
Communications Chemistry , year=
ChemFM as a scaling law guided foundation model pre-trained on informative chemicals , author=. Communications Chemistry , year=
-
[27]
arXiv preprint arXiv:2402.09391 (2024)
Llasmol: Advancing large language models for chemistry with a large-scale, comprehensive, high-quality instruction tuning dataset , author=. arXiv preprint arXiv:2402.09391 , year=
-
[28]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
Tabpfn: A transformer that solves small tabular classification problems in a second , author=. arXiv preprint arXiv:2207.01848 , year=
work page internal anchor Pith review arXiv
-
[29]
Tabicl: A tabular foundation model for in-context learning on large data , author=. arXiv preprint arXiv:2502.05564 , year=
-
[30]
Journal of Chemical Information and Modeling , volume=
Test-time training scaling laws for chemical exploration in drug design , author=. Journal of Chemical Information and Modeling , volume=. 2025 , publisher=
work page 2025
-
[31]
Boom: benchmarking out-of-distribution molecular property predictions of machine learning models , author=. arXiv preprint arXiv:2505.01912 , year=
-
[32]
Forty-second International Conference on Machine Learning , year=
Drug-tta: Test-time adaptation for drug virtual screening via multi-task meta-auxiliary learning , author=. Forty-second International Conference on Machine Learning , year=
-
[33]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
The Eleventh International Conference on Learning Representations , year=
Uni-Mol: A Universal 3D Molecular Representation Learning Framework , author=. The Eleventh International Conference on Learning Representations , year=
-
[35]
MoleculeNet: a benchmark for molecular machine learning , author=. Chemical science , volume=. 2018 , publisher=
work page 2018
-
[36]
International conference on machine learning , pages=
Hierarchical generation of molecular graphs using structural motifs , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[37]
arXiv preprint arXiv:2508.13408 , year=
NovoMolGen: Rethinking Molecular Language Model Pretraining , author=. arXiv preprint arXiv:2508.13408 , year=
-
[38]
Molecular De Novo Design through Deep Reinforcement Learning. arXiv e-prints , keywords =. doi:10.48550/arXiv.1704.07555 , archivePrefix =. 1704.07555 , primaryClass =
-
[39]
Advances in Neural Information Processing Systems , volume=
Genetic-guided GFlowNets for sample efficient molecular optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Sterling, Teague and Irwin, John J. , title =. Journal of Chemical Information and Modeling , year =. doi:10.1021/acs.jcim.5b00559 , url =
-
[41]
Jensen, Jan H. , title =. Chemical Science , year =. doi:10.1039/c8sc05372c , publisher =
-
[42]
Gaussian process optimization in the bandit setting: No regret and experimental design,
Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design. arXiv e-prints , keywords =. doi:10.48550/arXiv.0912.3995 , archivePrefix =. 0912.3995 , primaryClass =
-
[43]
Chemllm: A chemical large language model.arXiv preprint arXiv:2402.06852, 2024
ChemLLM: A Chemical Large Language Model. arXiv e-prints , keywords =. doi:10.48550/arXiv.2402.06852 , archivePrefix =. 2402.06852 , primaryClass =
-
[44]
Training a scientific reasoning model for chemistry.arXiv preprint arXiv:2506.17238, 2025
Training a Scientific Reasoning Model for Chemistry. arXiv e-prints , keywords =. doi:10.48550/arXiv.2506.17238 , archivePrefix =. 2506.17238 , primaryClass =
-
[45]
Efficient evolutionary search over chemical space with large language models, 2025
Efficient Evolutionary Search Over Chemical Space with Large Language Models. arXiv e-prints , keywords =. doi:10.48550/arXiv.2406.16976 , archivePrefix =. 2406.16976 , primaryClass =
-
[46]
Augmented Memory: Capitalizing on Experience Replay to Accelerate De Novo Molecular Design. arXiv e-prints , keywords =. doi:10.48550/arXiv.2305.16160 , archivePrefix =. 2305.16160 , primaryClass =
-
[47]
Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models. arXiv e-prints , keywords =. doi:10.48550/arXiv.2306.08018 , archivePrefix =. 2306.08018 , primaryClass =
-
[48]
arXiv preprint arXiv:1812.01070 , year=
Learning multimodal graph-to-graph translation for molecular optimization , author=. arXiv preprint arXiv:1812.01070 , year=
-
[49]
arXiv preprint arXiv:1907.11223 , year=
Hierarchical graph-to-graph translation for molecules , author=. arXiv preprint arXiv:1907.11223 , year=
-
[50]
Journal of chemical information and modeling , volume=
GuacaMol: benchmarking models for de novo molecular design , author=. Journal of chemical information and modeling , volume=. 2019 , publisher=
work page 2019
-
[51]
Journal of the American Chemical Society , volume=
Deep lead optimization: leveraging generative AI for structural modification , author=. Journal of the American Chemical Society , volume=. 2024 , publisher=
work page 2024
-
[52]
AI-driven drug discovery: a comprehensive review , author=. ACS omega , volume=. 2025 , publisher=
work page 2025
-
[53]
Journal of Cheminformatics , volume=
Reinvent 4: Modern AI--driven generative molecule design , author=. Journal of Cheminformatics , volume=. 2024 , publisher=
work page 2024
-
[54]
Journal of Cheminformatics , volume=
kGCN: a graph-based deep learning framework for chemical structures , author=. Journal of Cheminformatics , volume=. 2020 , publisher=
work page 2020
-
[55]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
BioT5: Enriching Cross-modal Integration in Biology with Chemical Knowledge and Natural Language Associations , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023
work page 2023
-
[56]
Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S
MoleculeNet: A Benchmark for Molecular Machine Learning. arXiv e-prints , keywords =. doi:10.48550/arXiv.1703.00564 , archivePrefix =. 1703.00564 , primaryClass =
-
[57]
Retrieval-based Controllable Molecule Generation. arXiv e-prints , keywords =. doi:10.48550/arXiv.2208.11126 , archivePrefix =. 2208.11126 , primaryClass =
-
[58]
Exploring Chemical Space with Score-based Out-of-distribution Generation. arXiv e-prints , keywords =. doi:10.48550/arXiv.2206.07632 , archivePrefix =. 2206.07632 , primaryClass =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.