Recognition: 2 theorem links
· Lean TheoremFollow the Mean: Reference-Guided Flow Matching
Pith reviewed 2026-05-13 06:10 UTC · model grok-4.3
The pith
Flow matching admits controllable generation by shifting the conditional endpoint mean computed from a reference set, enabling training-free guidance on frozen pretrained models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For deterministic interpolants, the velocity field is solely governed by a conditional endpoint mean; shifting this mean shifts the flow itself.
Load-bearing premise
That the interpolants remain deterministic and that the endpoint mean fully determines the velocity field without additional dependencies on the reference distribution or noise schedule.
Figures




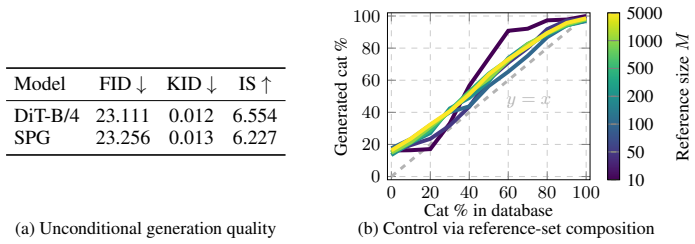



























read the original abstract
Existing approaches to controllable generation typically rely on fine-tuning, auxiliary networks, or test-time search. We show that flow matching admits a different control interface: adaptation through examples. For deterministic interpolants, the velocity field is solely governed by a conditional endpoint mean; shifting this mean shifts the flow itself. This yields a simple principle for controllable generation: steer a pretrained model by changing the reference set it follows. We instantiate this idea in two forms. Reference-Mean Guidance is training-free: it computes a closed-form endpoint-mean correction from a reference bank and applies it to a frozen FLUX.2-klein (4B) model, enabling control of color, identity, style, and structure while keeping the prompt, seed, and weights fixed. Semi-Parametric Guidance amortizes the same idea through an explicit mean anchor and learned residual refiner, matching unconditional DiT-B/4 quality on AFHQv2 while allowing the reference set to be swapped at inference time. These results point to a broader direction: generative models that adapt through data, not parameter updates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that flow matching with deterministic interpolants allows the velocity field to be controlled solely through the conditional endpoint mean, enabling reference-guided generation by shifting this mean using example sets. This is instantiated as training-free Reference-Mean Guidance applied to a frozen FLUX.2-klein model for attribute control, and as Semi-Parametric Guidance that amortizes the approach while maintaining quality on AFHQv2.
Significance. If the central theoretical claim holds and is supported by rigorous derivation and experiments, this work could offer a significant advance in controllable generation for flow-based models by providing a simple, training-free adaptation mechanism based on reference data rather than parameter updates or auxiliary models. The application to a large-scale pretrained model like FLUX.2-klein highlights practical potential, though stronger quantitative evidence is needed to establish the method's reliability.
major comments (3)
- The core assertion that 'for deterministic interpolants, the velocity field is solely governed by a conditional endpoint mean' lacks a detailed derivation showing that the proposed closed-form correction implements exactly v_t(x_t) = (E[x_1 | x_t] - x_t)/(1-t) with no residual terms from p_t(x_t), reference marginals, or the noise schedule; this is load-bearing for the claim that shifting the mean shifts the flow itself.
- In the Reference-Mean Guidance instantiation on the frozen FLUX.2-klein (4B) model, the manuscript does not verify that the endpoint-mean correction avoids injecting schedule-dependent scaling or reference-set covariance effects into the effective velocity, as required by the skeptic's concern on implicit dependencies.
- The claim that Semi-Parametric Guidance matches unconditional DiT-B/4 quality on AFHQv2 while allowing reference-set swapping is stated without quantitative metrics, ablations, or error analysis, which is necessary to substantiate that the amortized mean anchor preserves fidelity without introducing new dependencies.
minor comments (2)
- Clarify notation for 'FLUX.2-klein (4B)' and 'reference bank' for consistency across sections.
- The abstract would benefit from a brief mention of any evaluation metrics used for the qualitative control results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications, additional derivations, and planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: The core assertion that 'for deterministic interpolants, the velocity field is solely governed by a conditional endpoint mean' lacks a detailed derivation showing that the proposed closed-form correction implements exactly v_t(x_t) = (E[x_1 | x_t] - x_t)/(1-t) with no residual terms from p_t(x_t), reference marginals, or the noise schedule; this is load-bearing for the claim that shifting the mean shifts the flow itself.
Authors: We agree that a self-contained derivation is necessary for rigor. In the revision we will add a full proof in the appendix establishing that, for deterministic linear interpolants, the flow-matching velocity reduces exactly to v_t(x_t) = (E[x_1 | x_t] - x_t)/(1-t) with no residual dependence on the marginal p_t(x_t), reference marginals, or noise schedule. The proof proceeds by substituting the deterministic interpolant into the conditional expectation and showing that all other terms cancel. revision: yes
-
Referee: In the Reference-Mean Guidance instantiation on the frozen FLUX.2-klein (4B) model, the manuscript does not verify that the endpoint-mean correction avoids injecting schedule-dependent scaling or reference-set covariance effects into the effective velocity, as required by the skeptic's concern on implicit dependencies.
Authors: We acknowledge the need for explicit verification. In the revised manuscript we will insert a dedicated analysis subsection that substitutes the closed-form mean correction into the velocity expression and algebraically confirms the absence of schedule-dependent scaling and reference-set covariance terms. We will also add targeted empirical diagnostics on the FLUX.2-klein outputs to corroborate that no unintended dependencies are introduced. revision: yes
-
Referee: The claim that Semi-Parametric Guidance matches unconditional DiT-B/4 quality on AFHQv2 while allowing reference-set swapping is stated without quantitative metrics, ablations, or error analysis, which is necessary to substantiate that the amortized mean anchor preserves fidelity without introducing new dependencies.
Authors: We agree that quantitative evidence is required. In the revision we will report FID scores comparing Semi-Parametric Guidance against the unconditional DiT-B/4 baseline on AFHQv2, include ablations isolating the mean-anchor and residual-refiner components, and provide error analysis demonstrating that reference-set swapping preserves fidelity without introducing new dependencies beyond those of the base model. revision: yes
Circularity Check
No significant circularity; core claim follows from standard deterministic flow-matching properties
full rationale
The paper derives the control principle directly from the mathematical property of deterministic linear interpolants in flow matching, where the velocity satisfies v_t(x_t) = (E[x_1|x_t] - x_t)/(1-t) by definition of the conditional expectation under the path x_t = (1-t)x_0 + t x_1. This is presented as an external fact of the interpolant construction rather than a fitted parameter or self-referential equation. No load-bearing step reduces to a self-citation, ansatz smuggled via prior work, or renaming of a known result; the reference-mean guidance is an application of this property to a frozen model. The derivation remains self-contained against external flow-matching theory and does not force the target result by construction from its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Deterministic interpolants govern the velocity field solely via conditional endpoint mean
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
For the commonly used linear interpolant ... ut(x) = μt(x)−x / (1−t), μt(x) := E[x1 | xt = x]
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the velocity field is solely governed by a conditional endpoint mean; shifting this mean shifts the flow itself
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=PqvMRDCJT9t
work page 2023
-
[2]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=XVjTT1nw5z
work page 2023
-
[3]
Building normalizing flows with stochastic in- terpolants
Michael Samuel Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic in- terpolants. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=li7qeBbCR1t
work page 2023
-
[4]
William Peebles and Saining Xie. Scalable diffusion models with transformers. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), page 4172–4182, Paris, France, October 2023. IEEE. ISBN 979-8-3503-0718-4. doi: 10.1109/ICCV51070.2023.00387. URL https://ieeexplore. ieee.org/document/10377858/
-
[5]
FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
work page 2025
-
[6]
Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
work page 2023
-
[7]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=nZeVKeeFYf9
work page 2022
-
[8]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023
work page 2023
-
[9]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat GANs on image synthesis. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, 2021. URLhttps://openreview.net/forum?id=AAWuCvzaVt
work page 2021
-
[10]
On the guidance of flow matching
Ruiqi Feng, Chenglei Yu, Wenhao Deng, Peiyan Hu, and Tailin Wu. On the guidance of flow matching. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/ forum?id=pKaNgFzJBy
work page 2025
- [11]
-
[12]
Shyamgopal Karthik, Karsten Roth, Massimiliano Mancini, and Zeynep Akata. If at first you don’t succeed, try, try again: Faithful diffusion-based text-to-image generation by selection, 2023. URL https://arxiv.org/abs/2305.13308
-
[13]
Luhuan Wu, Brian L. Trippe, Christian A. Naesseth, David M. Blei, and John P. Cunningham. Practical and asymptotically exact conditional sampling in diffusion models, 2024. URL https://arxiv.org/ abs/2306.17775
-
[14]
Oscar Mañas, Pietro Astolfi, Melissa Hall, Candace Ross, Jack Urbanek, Adina Williams, Aishwarya Agrawal, Adriana Romero-Soriano, and Michal Drozdzal. Improving text-to-image consistency via automatic prompt optimization.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URLhttps://openreview.net/forum?id=g12Gdl6aDL. Featured Certification
work page 2024
-
[15]
ReNO: Enhanc- ing one-step text-to-image models through reward-based noise optimization
Luca Eyring, Shyamgopal Karthik, Karsten Roth, Alexey Dosovitskiy, and Zeynep Akata. ReNO: Enhanc- ing one-step text-to-image models through reward-based noise optimization. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum? id=MXY0qsGgeO
work page 2024
-
[16]
Naesseth, Max Welling, and Jan-Willem van de Meent
Floor Eijkelboom, Grigory Bartosh, Christian A. Naesseth, Max Welling, and Jan-Willem van de Meent. Variational flow matching for graph generation. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=UahrHR5HQh
work page 2024
-
[17]
Training flow matching: The role of weighting and parameterization
Anne Gagneux, Ségolène Tiffany Martin, Rémi Gribonval, and Mathurin Massias. Training flow matching: The role of weighting and parameterization. InICLR 2026 2nd Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy, 2026. URL https://openreview.net/forum?id= RYQBTBZxNl. 11
work page 2026
-
[18]
On the closed-form of flow match- ing: Generalization does not arise from target stochasticity
Quentin Bertrand, Anne Gagneux, Mathurin Massias, and Rémi Emonet. On the closed-form of flow match- ing: Generalization does not arise from target stochasticity. InThe Thirty-ninth Annual Conference on Neu- ral Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=kVz9uvqUna
work page 2025
-
[19]
How do flow matching models memorize and generalize in sample data subspaces?, 2024
Weiguo Gao and Ming Li. How do flow matching models memorize and generalize in sample data subspaces?, 2024. URLhttps://arxiv.org/abs/2410.23594
-
[20]
Nearest neighbour score estimators for diffusion generative models
Matthew Niedoba, Dylan Green, Saeid Naderiparizi, Vasileios Lioutas, Jonathan Wilder Lavington, Xiaoxuan Liang, Yunpeng Liu, Ke Zhang, Setareh Dabiri, Adam Scibior, Berend Zwartsenberg, and Frank Wood. Nearest neighbour score estimators for diffusion generative models. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jo...
work page 2024
-
[21]
Christopher Scarvelis, Haitz Sáez de Ocáriz Borde, and Justin Solomon. Closed-form diffusion models. Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https://openreview.net/ forum?id=JkMifr17wc
work page 2025
-
[22]
Your other Left! Vision-Language Models Fail to Identify Relative Positions in Medical Images
Daniel Wolf, Heiko Hillenhagen, Billurvan Taskin, Alex Bäuerle, Meinrad Beer, Michael Götz, and Timo Ropinski. Your other Left! Vision-Language Models Fail to Identify Relative Positions in Medical Images. InProceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2025, volume LNCS 15964. Springer Nature Switzerland, September 2025
work page 2025
-
[23]
Geneval: An object-focused framework for eval- uating text-to-image alignment
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for eval- uating text-to-image alignment. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URLhttps://openreview.net/forum?id=Wbr51vK331
work page 2023
-
[24]
Albergo, Carles Domingo-Enrich, Nicholas M
Amirmojtaba Sabour, Michael S. Albergo, Carles Domingo-Enrich, Nicholas M. Boffi, Sanja Fidler, Karsten Kreis, and Eric Vanden-Eijnden. Test-time scaling of diffusions with flow maps, 2025. URL https://arxiv.org/abs/2511.22688
-
[25]
Diamond Maps: Efficient Reward Alignment via Stochastic Flow Maps
Peter Holderrieth, Douglas Chen, Luca Eyring, Ishin Shah, Giri Anantharaman, Yutong He, Zeynep Akata, Tommi Jaakkola, Nicholas M. Boffi, and Max Simchowitz. Diamond maps: Efficient reward alignment via stochastic flow maps, 2026. URLhttps://arxiv.org/abs/2602.05993
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Retrieval- augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval- augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, volume 33, 2020
work page 2020
-
[27]
Improving language models by retrieving from trillions of tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego De Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, ...
work page 2022
-
[28]
Semi-parametric neural image synthesis
Andreas Blattmann, Robin Rombach, Kaan Oktay, Jonas Müller, and Björn Ommer. Semi-parametric neural image synthesis. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum? id=Bqk9c0wBNrZ
work page 2022
-
[29]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems, volume 33, 2020
work page 2020
-
[30]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations, 2021. URLhttps://openreview.net/forum?id=PxTIG12RRHS
work page 2021
-
[31]
Alexander Tong, Kilian FATRAS, Nikolay Malkin, Guillaume Huguet, Yanlei Zhang, Jarrid Rector- Brooks, Guy Wolf, and Yoshua Bengio. Improving and generalizing flow-based generative models with minibatch optimal transport.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id=CD9Snc73AW. Expert Certification. 12
work page 2024
-
[32]
Nanye Ma, Mark Goldstein, Michael S. Albergo, Nicholas M. Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. In European Conference on Computer Vision, 2024
work page 2024
-
[33]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021. URL https://openreview.net/forum?id= qw8AKxfYbI
work page 2021
-
[34]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i- adapter: learning adapters to dig out more controllable ability for text-to-image diffusion models. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and...
-
[35]
Prompt-to- prompt image editing with cross-attention control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to- prompt image editing with cross-attention control. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=_CDixzkzeyb
work page 2023
-
[36]
Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xiaohu Qie, and Yinqiang Zheng. Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 22560–22570, October 2023
work page 2023
-
[37]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. IP-adapter: Text compatible image prompt adapter for text-to-image diffusion models, 2023. URLhttps://arxiv.org/abs/2308.06721
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Dongxu Li, Junnan Li, and Steven C. H. Hoi. BLIP-diffusion: Pre-trained subject representation for controllable text-to-image generation and editing. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[39]
Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519, 2024
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, Anthony Chen, Huaxia Li, Xu Tang, and Yao Hu. Instantid: Zero-shot identity-preserving generation in seconds, 2024. URL https://arxiv.org/abs/ 2401.07519
-
[40]
Generalization through memorization: Nearest neighbor language models
Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. Generalization through memorization: Nearest neighbor language models. InInternational Conference on Learning Representations, 2020. URLhttps://openreview.net/forum?id=HklBjCEKvH
work page 2020
-
[41]
An image is worth one word: Personalizing text-to-image generation using textual inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview. net/forum?id=NAQvF08TcyG
work page 2023
-
[42]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
work page 2023
-
[43]
James Seale Smith, Yen-Chang Hsu, Lingyu Zhang, Ting Hua, Zsolt Kira, Yilin Shen, and Hongxia Jin. Continual diffusion: Continual customization of text-to-image diffusion with c-loRA.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id= TZdEgwZ6f3
work page 2024
-
[44]
Test-time training with self-supervision for generalization under distribution shifts
Yu Sun, Xiaolong Wang, Zhuang Liu, John Miller, Alexei Efros, and Moritz Hardt. Test-time training with self-supervision for generalization under distribution shifts. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 9229–9248. PMLR,...
work page 2020
-
[45]
Tent: Fully test-time adaptation by entropy minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=uXl3bZLkr3c
work page 2021
-
[46]
Generalization in diffusion models arises from geometry-adaptive harmonic representations
Zahra Kadkhodaie, Florentin Guth, Eero P Simoncelli, and Stéphane Mallat. Generalization in diffusion models arises from geometry-adaptive harmonic representations. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=ANvmVS2Yr0
work page 2024
-
[47]
Repa-e: Unlocking vae for end-to-end tuning with latent diffusion transformers, 2025
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. Repa-e: Unlocking vae for end-to-end tuning with latent diffusion transformers, 2025. URL https://arxiv. org/abs/2504.10483. 13
-
[48]
Symbolic discovery of optimization algorithms
Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, and Quoc V Le. Symbolic discovery of optimization algorithms. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview. net/forum?id=ne6zeqLFCZ
work page 2023
-
[49]
On aliased resizing and surprising subtleties in gan evaluation
Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. On aliased resizing and surprising subtleties in gan evaluation. InCVPR, 2022
work page 2022
-
[50]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine...
work page 2021
-
[51]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution, 2024. URLhttps://arxiv.org/abs/2409.121...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.