Recognition: no theorem link
Valid Best-Model Identification for LLM Evaluation via Low-Rank Factorization
Pith reviewed 2026-05-12 05:01 UTC · model grok-4.3
The pith
Doubly robust estimators let low-rank predictions speed up valid best-LLM identification
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We derive doubly robust estimators of each model's performance that use the low-rank predictions to reduce variance. This enables the construction of valid finite-sample confidence intervals in our setting, where models are selected adaptively and examples are sampled without replacement.
What carries the argument
Doubly robust estimators that blend observed scores with low-rank predicted scores for variance reduction while preserving unbiasedness under adaptive sampling.
If this is right
- Fewer model-example evaluations suffice to identify the best LLM with statistical confidence
- Valid finite-sample confidence intervals remain available despite adaptive selection
- Correct identification holds even if low-rank predictions contain bias
- Real-world benchmarks show meaningful reductions in compute while selecting the top model accurately
Where Pith is reading between the lines
- The same doubly robust correction could apply to adaptive evaluation in other matrix-structured settings such as recommender systems
- Savings scale with how strongly low-rank structure fits the score matrix of a given benchmark
- One could test the method by replacing low-rank predictions with other cheap estimators and verifying interval coverage
Load-bearing premise
The doubly robust estimators remain unbiased and achieve correct coverage even when low-rank predictions are biased and under adaptive model selection with sampling without replacement.
What would settle it
Run repeated trials of the adaptive evaluation protocol on a fixed benchmark and check whether the constructed confidence intervals cover the true model performances at the nominal rate.
Figures

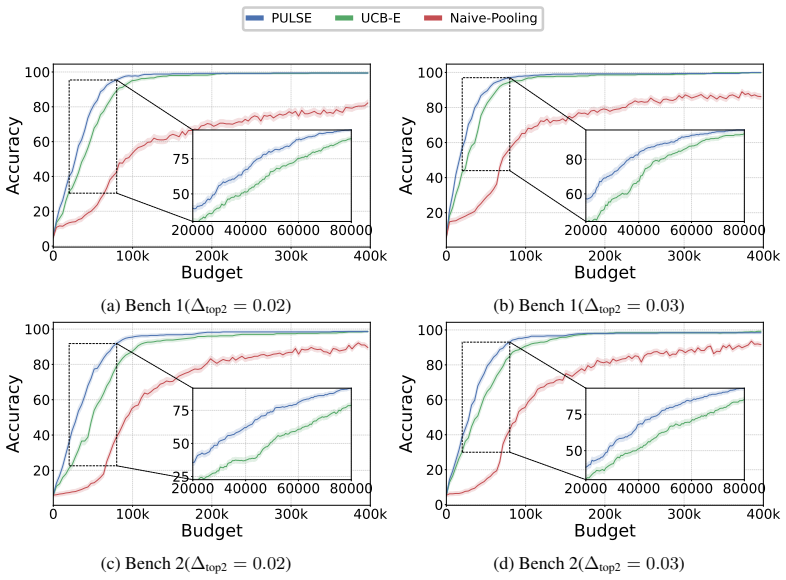


read the original abstract
Selecting the best large language model (LLM) for a fixed benchmark is often expensive, since exhaustive evaluation requires running every model on every example. Multi-armed bandit (MAB) algorithms can reduce the number of LLM calls by sequentially selecting the next model-example pair to evaluate, thereby avoiding wasted evaluations on clearly underperforming models. Further savings can be achieved by predicting model scores from the partially observed model-example score matrix using low-rank factorization. However, such predictions are not ground truth: they can be biased and may therefore lead to incorrect identification of the best model. In this work, we propose a principled framework that combines MAB with cheap predicted scores without compromising statistical validity. Specifically, we derive doubly robust estimators of each model's performance that use the low-rank predictions to reduce variance. This enables the construction of valid finite-sample confidence intervals in our setting, where models are selected adaptively and examples are sampled without replacement. Empirical results on real-world benchmarks show that our approach reduces the number of required evaluations, yielding meaningful savings in compute and cost while accurately identifying the best-performing model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes combining multi-armed bandit (MAB) algorithms with low-rank factorization of the partially observed model-example score matrix to reduce the number of LLM evaluations needed for best-model identification. It derives doubly robust estimators for each model's mean performance that incorporate the low-rank predictions for variance reduction, and claims these estimators yield valid finite-sample confidence intervals despite adaptive model selection and sampling of examples without replacement. Empirical results on real benchmarks are said to show meaningful reductions in evaluations while still correctly identifying the best model.
Significance. If the doubly robust estimators can be shown to remain unbiased and deliver correct finite-sample coverage under adaptive MAB selection and without-replacement sampling (even when the low-rank predictions are biased), the work would offer a practical advance for statistically valid, compute-efficient LLM benchmarking. The approach directly targets the high cost of exhaustive evaluation while addressing the risk of biased predictions leading to incorrect model selection.
major comments (2)
- [derivation of doubly robust estimators (abstract and main technical sections)] The central claim that the derived doubly robust estimators remain unbiased and produce valid finite-sample CIs under adaptive MAB selection plus without-replacement sampling is load-bearing, yet the manuscript provides no explicit derivation, no statement of the required assumptions on the propensity scores, and no proof that the estimator accounts for the martingale dependence (past outcomes affect future sampling probabilities). Standard DR unbiasedness does not automatically extend to this setting if propensities are treated as fixed.
- [confidence interval construction] The finite-population correction for sampling without replacement must be incorporated into the variance estimator and CI construction; it is unclear whether the proposed intervals include this correction or whether the coverage guarantee holds only asymptotically.
minor comments (2)
- [experiments] The abstract states that 'empirical savings are claimed but not quantified'; the experimental section should report concrete numbers for evaluation reduction, coverage rates, and identification accuracy across multiple benchmarks and random seeds.
- [preliminaries and method] Notation for the low-rank factorization, the MAB policy, and the DR estimator should be introduced with explicit definitions and distinguished from standard DR notation to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments have prompted us to strengthen the technical exposition and clarify key aspects of the finite-sample guarantees. We respond to each major comment below and indicate the revisions made.
read point-by-point responses
-
Referee: [derivation of doubly robust estimators (abstract and main technical sections)] The central claim that the derived doubly robust estimators remain unbiased and produce valid finite-sample CIs under adaptive MAB selection plus without-replacement sampling is load-bearing, yet the manuscript provides no explicit derivation, no statement of the required assumptions on the propensity scores, and no proof that the estimator accounts for the martingale dependence (past outcomes affect future sampling probabilities). Standard DR unbiasedness does not automatically extend to this setting if propensities are treated as fixed.
Authors: We agree that greater explicitness is warranted. While Appendix B contained a derivation, it was insufficiently cross-referenced and did not fully address the martingale structure. We have revised the manuscript by expanding the main technical section (now Section 3.2) to include the complete derivation of the doubly robust estimator. We explicitly state Assumption 1 on the propensity scores (they are known and determined by the realized history of the adaptive MAB policy) and add Lemma 1, which shows that the estimator is a martingale difference sequence with respect to the natural filtration. Unbiasedness then follows from the optional stopping theorem, extending standard DR results to this dependent setting. The low-rank predictions enter only as an auxiliary model and do not affect unbiasedness provided the propensities are correctly specified. revision: yes
-
Referee: [confidence interval construction] The finite-population correction for sampling without replacement must be incorporated into the variance estimator and CI construction; it is unclear whether the proposed intervals include this correction or whether the coverage guarantee holds only asymptotically.
Authors: We thank the referee for this important clarification request. The variance estimator in Equation (8) does incorporate the finite-population correction factor (N-n)/(N-1), where N is the total number of examples. Theorem 2 establishes exact finite-sample coverage (not merely asymptotic) by combining the unbiasedness of the DR estimator with the exact hypergeometric-style variance under without-replacement sampling, adjusted for the adaptive policy via the martingale property. To improve clarity we have added an explicit remark in Section 4.2 describing the correction term and its role in the coverage proof. We have also included a brief finite-sample coverage verification in the appendix. revision: partial
Circularity Check
Derivation of doubly robust estimators remains self-contained
full rationale
The paper's core contribution is the derivation of doubly robust estimators that incorporate low-rank predictions for variance reduction while preserving unbiasedness and finite-sample CI validity under adaptive MAB selection and without-replacement sampling. No quoted equations or steps reduce the claimed validity result to a tautology, a fitted parameter renamed as a prediction, or a load-bearing self-citation chain. The derivation is presented as an adaptation of standard DR theory to the specific protocol, with the low-rank component used only for efficiency rather than as a definitional input. This is the most common honest finding for a methods paper whose central claim is an estimator construction rather than a re-expression of its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology, 35 (2):1–72, 2026
work page 2026
-
[3]
Emergent Abilities of Large Language Models
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models.arXiv preprint arXiv:2206.07682, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
work page 2024
-
[5]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021
work page 2021
-
[6]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. In B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, editors,International Conference on Learning Representations, volume 2024, pages 9025–9049, 2024. URL https://proceedings.iclr.cc/paper_files/paper/ 2024/fil...
work page 2024
-
[7]
Efficient benchmarking of AI agents
Franck Ndzomga. Efficient benchmarking of ai agents.arXiv preprint arXiv:2603.23749, 2026
-
[8]
Sayash Kapoor et al. Holistic agent leaderboard: The missing infrastructure for AI agent evaluation.arXiv preprint arXiv:2510.11977, 2025
-
[9]
Best arm identification in multi-armed bandits
Jean-Yves Audibert and Sébastien Bubeck. Best arm identification in multi-armed bandits. In COLT-23th Conference on learning theory-2010, pages 13–p, 2010
work page 2010
-
[10]
On speeding up language model evaluation
Jin Peng Zhou, Christian K Belardi, Ruihan Wu, Travis Zhang, Carla P Gomes, Wen Sun, and Kilian Q Weinberger. On speeding up language model evaluation. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[11]
James M Robins and Andrea Rotnitzky. Semiparametric efficiency in multivariate regression models with missing data.Journal of the American Statistical Association, 90(429):122–129, 1995
work page 1995
-
[12]
Anastasios A Tsiatis.Semiparametric theory and missing data. Springer, 2006
work page 2006
-
[13]
Prediction-powered inference.Science, 382(6671):669–674, 2023
Anastasios N Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I Jordan, and Tijana Zrnic. Prediction-powered inference.Science, 382(6671):669–674, 2023
work page 2023
-
[14]
arXiv preprint arXiv:2311.01453 , year=
Anastasios N Angelopoulos, John C Duchi, and Tijana Zrnic. PPI++: Efficient prediction- powered inference.arXiv preprint arXiv:2311.01453, 2023. 10
-
[15]
Vitor Hadad, David A Hirshberg, Ruohan Zhan, Stefan Wager, and Susan Athey. Confidence intervals for policy evaluation in adaptive experiments.Proceedings of the national academy of sciences, 118(15):e2014602118, 2021
work page 2021
-
[16]
Doubly robust policy evaluation and learning
Miroslav Dudík, John Langford, and Lihong Li. Doubly robust policy evaluation and learning. arXiv preprint arXiv:1103.4601, 2011
-
[17]
Optimal and adaptive off-policy evalua- tion in contextual bandits
Yu-Xiang Wang, Alekh Agarwal, and Miroslav Dudık. Optimal and adaptive off-policy evalua- tion in contextual bandits. InInternational Conference on Machine Learning, pages 3589–3597. PMLR, 2017
work page 2017
-
[18]
Maria Dimakopoulou, Zhimei Ren, and Zhengyuan Zhou. Online multi-armed bandits with adaptive inference.Advances in Neural Information Processing Systems, 34:1939–1951, 2021
work page 1939
-
[19]
Masahiro Kato, Kenichiro McAlinn, and Shota Yasui. The adaptive doubly robust estimator and a paradox concerning logging policy.Advances in neural information processing systems, 34:1351–1364, 2021
work page 2021
-
[20]
Aurélien Bibaut, Maria Dimakopoulou, Nathan Kallus, Antoine Chambaz, and Mark van Der Laan. Post-contextual-bandit inference.Advances in neural information processing systems, 34:28548–28559, 2021
work page 2021
-
[21]
Off-policy evaluation via adaptive weighting with data from contextual bandits
Ruohan Zhan, Vitor Hadad, David A Hirshberg, and Susan Athey. Off-policy evaluation via adaptive weighting with data from contextual bandits. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 2125–2135, 2021
work page 2021
-
[22]
Doubly-robust lasso bandit.Advances in Neural Information Processing Systems, 32, 2019
Gi-Soo Kim and Myunghee Cho Paik. Doubly-robust lasso bandit.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[23]
Wonyoung Kim, Gi-Soo Kim, and Myunghee Cho Paik. Doubly robust thompson sampling with linear payoffs.Advances in neural information processing systems, 34:15830–15840, 2021
work page 2021
-
[24]
Multi-Armed Bandits With Machine Learning-Generated Surrogate Rewards
Wenlong Ji, Yihan Pan, Ruihao Zhu, and Lihua Lei. Multi-armed bandits with machine learning-generated surrogate rewards.arXiv preprint arXiv:2506.16658, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Best arm identification with llm judges and limited human audits.Available at SSRN 6147806, 2026
Ruicheng Ao, Hongyu Chen, Siyang Gao, Hanwei Li, and David Simchi-Levi. Best arm identification with llm judges and limited human audits.Available at SSRN 6147806, 2026
work page 2026
-
[26]
Efficient Evaluation of LLM Performance with Statistical Guarantees
Skyler Wu, Yash Nair, and Emmanuel J Candés. Efficient evaluation of llm performance with statistical guarantees.arXiv preprint arXiv:2601.20251, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Concentration inequalities for sampling without replacement.Bernoulli, 2015
Rémi Bardenet and Odalric-Ambrym Maillard. Concentration inequalities for sampling without replacement.Bernoulli, 2015
work page 2015
-
[28]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, and Quoc V Le. H chi, denny zhou, et al. 2022. challenging big-bench tasks and whether chain-of-thought can solve them.arXiv preprint arXiv:2210.09261, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google- proof q&a benchmark. InFirst Conference on Language Modeling, 2024. URL https: //openreview.net/forum?id=Ti67584b98
work page 2024
-
[30]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023. 11
work page 2023
-
[32]
Musr: Testing the limits of chain-of-thought with multistep soft reasoning
Zayne Sprague, Xi Ye, Kaj Bostrom, Swarat Chaudhuri, and Greg Durrett. Musr: Testing the limits of chain-of-thought with multistep soft reasoning. In B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, editors,In- ternational Conference on Learning Representations, volume 2024, pages 14670– 14728, 2024. URL https://proceedings.iclr.cc/pap...
work page 2024
-
[33]
Jerome H Friedman, Trevor Hastie, and Rob Tibshirani. Regularization paths for generalized linear models via coordinate descent.Journal of statistical software, 33:1–22, 2010
work page 2010
-
[34]
Kacha Dzhaparidze and JH Van Zanten. On bernstein-type inequalities for martingales.Stochas- tic processes and their applications, 93(1):109–117, 2001
work page 2001
-
[35]
David A Freedman. On tail probabilities for martingales.the Annals of Probability, pages 100–118, 1975. A Proofs A.1 Proof of Lemma 1 Lemma 3.Assumeπ k i , λk i and ˆSk ij areF k−1 measurable, then for eachk≥1,E[ ˆθk i | F k−1] =µ i Proof. E[ˆθk i | F k−1] =E 1 n X j∈O k−1 i Si,j + X j∈U k i λk i ˆSk i,j + Si,jk −λ k i ˆSk i,jk πk i ! Fk−1 ...
work page 1975
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.