Recognition: 2 theorem links
· Lean TheoremRemember to Forget: Gated Adaptive Positional Encoding
Pith reviewed 2026-05-12 04:40 UTC · model grok-4.3
The pith
GAPE adds content-aware gates to rotary encodings so important distant tokens stay accessible while irrelevant ones lose attention mass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
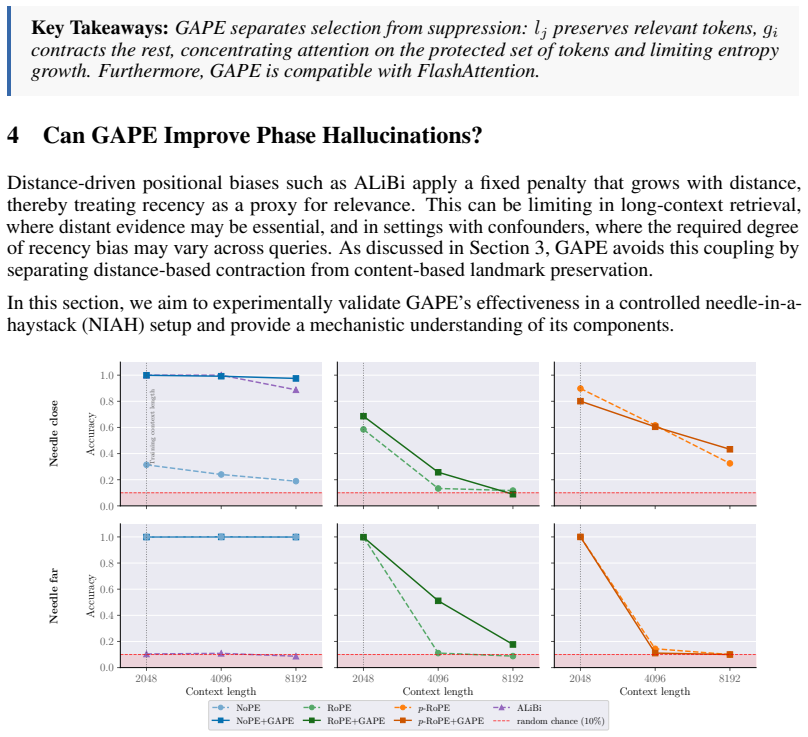
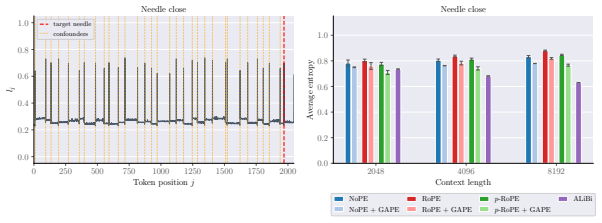
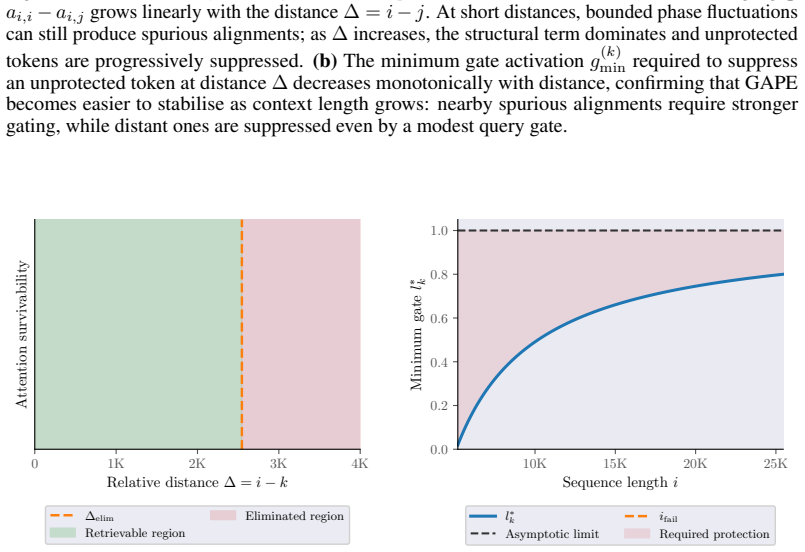
GAPE augments positional encodings by adding a content-aware bias directly into the attention logits while preserving the rotary geometry. It decouples distance-based suppression from token importance through a query-dependent gate that contracts irrelevant context and a key-dependent gate that preserves salient distant tokens. Protected tokens remain accessible, while the attention mass assigned to unprotected distant tokens decays as a function of the query gate. GAPE can be implemented within standard scaled dot-product attention.
What carries the argument
Query-dependent and key-dependent gates that apply a content-aware bias to attention logits, preserving rotary geometry while modulating distance effects according to token salience.
If this is right
- Salient tokens at arbitrary distances remain reachable without spurious alignments.
- Unprotected distant tokens receive attention mass that decays with the query gate value.
- The method requires only local changes inside existing scaled dot-product attention layers.
- Empirical results indicate consistently sharper attention and higher scores on long-context and synthetic retrieval benchmarks.
Where Pith is reading between the lines
- The gate mechanism could be combined with other positional schemes to stabilize performance when context lengths grow further.
- Dynamic adjustment of the gates at inference time might allow models to focus compute on relevant spans without fixed context windows.
- Similar content-dependent modulation might reduce wasted attention on irrelevant tokens in other transformer components.
Load-bearing premise
The content-aware gates can be trained to distinguish important from unimportant tokens stably and without introducing new biases or instabilities.
What would settle it
If long-context retrieval accuracy or attention sharpness on sequences beyond training length shows no improvement over standard rotary baselines, or if protected tokens lose accessibility in the attention computation, the central claims would fail.
Figures










read the original abstract
Rotary Positional Encoding (RoPE) is widely used in modern large language models. However, when sequences are extended beyond the range seen during training, rotary phases can enter out-of-distribution regimes, leading to spurious long-range alignments, diffuse attention, and degraded retrieval. Existing remedies only partially address these failures, as they often trade local positional resolution for long-context stability. We propose GAPE (Gated Adaptive Positional Encoding), a drop-in augmentation for positional encodings that introduces a content-aware bias directly into the attention logits while preserving the rotary geometry. GAPE decouples distance-based suppression from token importance through a query-dependent gate that contracts irrelevant context and a key-dependent gate that preserves salient distant tokens. We prove that protected tokens remain accessible, while the attention mass assigned to unprotected distant tokens decays as a function of the query gate. We further show that GAPE can be implemented within standard scaled dot-product attention. We validate these properties empirically, finding that GAPE consistently yields sharper attention and improved long-context robustness over rotary baselines across both synthetic retrieval and long-context benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Gated Adaptive Positional Encoding (GAPE) as a drop-in augmentation to Rotary Positional Encoding (RoPE) for large language models. GAPE adds content-aware biases to attention logits via a query-dependent gate that contracts irrelevant context and a key-dependent gate that preserves salient distant tokens, while preserving the underlying rotary geometry. The authors claim to prove that protected tokens remain accessible and that attention mass assigned to unprotected distant tokens decays as a function of the query gate; they further show that GAPE integrates into standard scaled dot-product attention. Empirical results indicate consistently sharper attention maps and improved robustness on synthetic retrieval tasks and long-context benchmarks relative to rotary baselines.
Significance. If the central proof is correct and the reported empirical gains are reproducible, the work offers a conceptually clean way to mitigate RoPE's out-of-distribution phase issues in long sequences without the usual local-resolution trade-offs. The explicit separation of distance-based suppression from token importance, together with the drop-in implementation, could be practically useful for extending context windows in transformer-based models.
minor comments (3)
- [Abstract] Abstract: the specific long-context benchmarks and synthetic retrieval tasks are not named; adding the exact dataset names and sequence lengths would improve clarity for readers scanning the abstract.
- [§3] §3 (method): the exact placement of the gates relative to the rotary embedding (before or after the phase rotation) should be stated explicitly in the attention formula to confirm the claimed compatibility with standard scaled dot-product attention.
- [Table 2 / Figure 3] Table 2 or Figure 3 (empirical results): the reported attention sharpness metric lacks a precise definition or formula; a short equation or reference to the computation would make the 'sharper attention' claim easier to interpret.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work on Gated Adaptive Positional Encoding (GAPE) as a drop-in augmentation to RoPE. The recommendation for minor revision is noted, and we appreciate the recognition of the conceptual separation of distance-based suppression from token importance as well as the empirical improvements on long-context tasks. No specific major comments were provided in the report.
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces GAPE as an additive content-aware bias to rotary attention logits, with an explicit claimed proof that protected tokens remain accessible while unprotected distant mass decays as a function of the query gate, plus a demonstration that the mechanism fits inside standard scaled dot-product attention. These elements are presented as independent mathematical and implementation contributions rather than reductions of fitted parameters or self-citations. No self-definitional equations, predictions that are statistically forced by construction, or load-bearing self-citations appear in the abstract or strongest claims; the empirical validation on synthetic retrieval and long-context benchmarks is treated as separate corroboration. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- gate parameters
axioms (1)
- standard math Standard scaled dot-product attention framework
invented entities (1)
-
GAPE gates
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Round and round we go! what makes rotary positional encodings useful?, 2025
Federico Barbero et al. “Round and round we go! what makes rotary positional encodings useful?” In:arXiv preprint arXiv:2410.06205(2024)
-
[2]
Extending Context Window of Large Language Models via Positional Interpolation
Shouyuan Chen et al. “Extending context window of large language models via positional interpolation”. In:arXiv preprint arXiv:2306.15595(2023)
work page internal anchor Pith review arXiv 2023
-
[3]
Kerple: Kernelized relative positional embedding for length extrapolation
Ta-Chung Chi et al. “Kerple: Kernelized relative positional embedding for length extrapolation”. In:Advances in Neural Information Processing Systems35 (2022), pp. 8386–8399
work page 2022
-
[4]
Transformer-xl: Attentive language models beyond a fixed-length context
Zihang Dai et al. “Transformer-xl: Attentive language models beyond a fixed-length context”. In:Proceedings of the 57th annual meeting of the association for computational linguistics. 2019, pp. 2978–2988
work page 2019
-
[5]
Tri Dao.FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
-
[6]
arXiv:2307.08691 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Tri Dao et al.FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
-
[8]
arXiv:2205.14135 [cs.LG]
work page internal anchor Pith review arXiv
-
[9]
Bert: Pre-training of deep bidirectional transformers for language un- derstanding
Jacob Devlin et al. “Bert: Pre-training of deep bidirectional transformers for language un- derstanding”. In:Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 2019, pp. 4171–4186
work page 2019
-
[10]
LongRoPE: Extending LLM context window beyond 2 million tokens
Yiran Ding et al. “Longrope: Extending llm context window beyond 2 million tokens”. In: arXiv preprint arXiv:2402.13753(2024)
-
[11]
Aaron Grattafiori et al.The Llama 3 Herd of Models. 2024. arXiv:2407.21783 [cs.AI]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh et al. “RULER: What’s the Real Context Size of Your Long-Context Language Models?” In:arXiv preprint arXiv:2404.06654(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Functional interpolation for relative positions improves long context transformers
Shanda Li et al. “Functional interpolation for relative positions improves long context trans- formers”. In:arXiv preprint arXiv:2310.04418(2023)
- [14]
-
[15]
Scaling laws of rope-based extrapolation
Xiaoran Liu et al. “Scaling laws of rope-based extrapolation”. In:arXiv preprint arXiv:2310.05209(2023)
-
[16]
Base of rope bounds context length
Xin Men et al. “Base of rope bounds context length”. In:arXiv preprint arXiv:2405.14591 (2024)
-
[17]
Yui Oka et al. “Frequency Bands in RoPE: Base Frequency and Context Length Shape the Interpolation–Extrapolation Trade-off”. In:The Fourteenth International Conference on Learning Representations
-
[18]
Probing Rotary Position Embeddings through Frequency Entropy
Yui Oka et al. “Probing Rotary Position Embeddings through Frequency Entropy”. In:The Fourteenth International Conference on Learning Representations
-
[19]
Team Olmo et al.Olmo 3. 2025. arXiv:2512.13961 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Guilherme Penedo et al. “The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale”. In:The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track. 2024
work page 2024
-
[21]
YaRN: Efficient Context Window Extension of Large Language Models
Bowen Peng et al. “Yarn: Efficient context window extension of large language models”. In: arXiv preprint arXiv:2309.00071(2023)
work page internal anchor Pith review arXiv 2023
-
[22]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Ofir Press, Noah A Smith, and Mike Lewis. “Train short, test long: Attention with linear biases enables input length extrapolation”. In:arXiv preprint arXiv:2108.12409(2021). 10
work page internal anchor Pith review arXiv 2021
-
[23]
Exploring the limits of transfer learning with a unified text-to-text trans- former
Colin Raffel et al. “Exploring the limits of transfer learning with a unified text-to-text trans- former”. In:Journal of machine learning research21.140 (2020), pp. 1–67
work page 2020
-
[24]
Flashattention-3: Fast and accurate attention with asynchrony and low- precision
Jay Shah et al. “Flashattention-3: Fast and accurate attention with asynchrony and low- precision”. In:Advances in Neural Information Processing Systems37 (2024), pp. 68658– 68685
work page 2024
-
[25]
Self-attention with relative position representations
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. “Self-attention with relative position representations”. In:Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018, pp. 464–468
work page 2018
-
[26]
Roformer: Enhanced transformer with rotary position embedding
Jianlin Su et al. “Roformer: Enhanced transformer with rotary position embedding”. In: Neurocomputing568 (2024), p. 127063
work page 2024
-
[27]
Gemma Team et al.Gemma: Open Models Based on Gemini Research and Technology. 2024. arXiv:2403.08295 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Ashish Vaswani et al. “Attention is all you need”. In:Advances in neural information process- ing systems30 (2017)
work page 2017
- [29]
-
[30]
Frayed RoPE and Long Inputs: A Geometric Perspective
Davis Wertheimer et al. “Frayed RoPE and Long Inputs: A Geometric Perspective”. In:arXiv preprint arXiv:2603.18017(2026)
-
[31]
Base of rope bounds context length
Mingyu Xu et al. “Base of rope bounds context length”. In:Advances in Neural Information Processing Systems37 (2024), pp. 87386–87410
work page 2024
-
[32]
Ted Zadouri et al.FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmet- ric Hardware Scaling. 2026. arXiv:2603.05451 [cs.CL]. 11 Remember to Forget: Gated Adaptive Positional Encoding Supplementary Material Contents A Gated Adaptive Positional Encoding: Proofs and Further Explanations 13 A.1 Landmark Protection . . . . . . . . . . . . ....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.