Recognition: no theorem link
Can Muon Fine-tune Adam-Pretrained Models?
Pith reviewed 2026-05-12 03:47 UTC · model grok-4.3
The pith
LoRA mitigates the optimizer mismatch that degrades Muon performance when fine-tuning Adam-pretrained models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Muon and Adam possess different implicit biases; switching to Muon for fine-tuning disrupts the knowledge stored in an Adam-pretrained model, and the degree of disruption scales with update strength. Constraining updates through LoRA reduces this disruption and thereby narrows the performance difference between the two optimizers that appears under full fine-tuning.
What carries the argument
The optimizer mismatch driven by distinct implicit biases of Muon versus Adam, which scales with update strength and is mitigated by constraining updates via LoRA.
If this is right
- The size of the performance gap between Muon and Adam in full fine-tuning increases as update strength grows.
- Lower LoRA ranks, which more tightly constrain updates, further reduce the observed mismatch.
- Greater catastrophic forgetting occurs under stronger updates when the optimizers are switched.
- Other low-rank or constrained-update methods produce similar reductions in mismatch severity.
Where Pith is reading between the lines
- Fine-tuning pipelines may need to prioritize optimizer compatibility with pretraining to best preserve learned features.
- Update-constraining techniques could serve as a general tool for making different optimizers interchangeable in transfer settings.
- Design of future optimizers might incorporate explicit control over implicit bias to improve compatibility with existing pretrained checkpoints.
Load-bearing premise
The performance degradation arises specifically from Muon's bias disrupting pretrained knowledge rather than from hyperparameter choices or unrelated factors, and that LoRA addresses the root cause by limiting update strength.
What would settle it
A controlled experiment in which Muon and Adam are given identical effective update magnitudes during full fine-tuning yet still produce a performance gap would falsify the claim that update strength is the mediating factor.
Figures


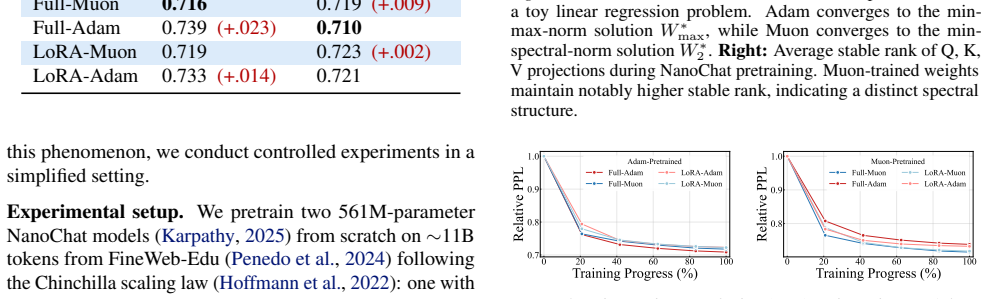










read the original abstract
Muon has emerged as an efficient alternative to Adam for pretraining, yet remains underused for fine-tuning. A key obstacle is that most open models are pretrained with Adam, and naively switching to Muon for fine-tuning leads to degraded performance due to an optimizer mismatch. We investigate this mismatch through controlled experiments and relate it to the distinct implicit biases of Adam and Muon. We provide evidence that the mismatch disrupts pretrained knowledge, and that this disruption scales with update strength. This leads us to hypothesize that constraining updates should mitigate the mismatch. We validate this with LoRA: across language and vision tasks, LoRA reduces the performance gap between Adam and Muon observed under full fine-tuning. Studies on LoRA rank, catastrophic forgetting, and LoRA variants further confirm that mismatch severity correlates with update strength. These results shed light on how optimizer mismatch affects fine-tuning and how it can be mitigated. Our code is available at https://github.com/XingyuQu/muon-finetune.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that naively switching from Adam to Muon for fine-tuning Adam-pretrained models causes performance degradation due to an optimizer mismatch arising from their distinct implicit biases. This mismatch is said to disrupt pretrained knowledge in a manner that scales with update strength. The authors hypothesize that constraining updates mitigates the issue and validate this via LoRA, which reduces the Adam-Muon performance gap relative to full fine-tuning across language and vision tasks. Additional studies on LoRA rank, catastrophic forgetting, and LoRA variants are presented to confirm the correlation with update strength. Reproducible code is released.
Significance. If the results hold, the work provides practical guidance on applying Muon to Adam-pretrained models and illuminates how optimizer implicit biases interact with fine-tuning. The open code is a clear strength, enabling verification of the controlled experiments and extension to new tasks.
major comments (2)
- [§3 (Experimental Setup)] §3 (Experimental Setup): The description of 'naively switching' to Muon does not specify whether Muon hyperparameters (learning rate, momentum coefficients, weight decay) received independent optimization equivalent to Adam on the same tasks and data. Without this, the full fine-tuning gap cannot be confidently attributed to implicit-bias mismatch rather than suboptimal Muon tuning, which directly undermines the causal claim and the interpretation that LoRA mitigates mismatch by constraining updates.
- [§4.2 and §5 (LoRA and Update Strength Analysis)] §4.2 and §5 (LoRA and Update Strength Analysis): The scaling of degradation with update strength is central to the hypothesis, yet the manuscript provides no explicit definition or measurement of update strength (e.g., update norm, effective step size, or gradient statistics) that is compared quantitatively between full fine-tuning and LoRA settings. This leaves the mediator role of update strength correlational rather than demonstrated.
minor comments (2)
- [Abstract] Abstract: The mention of 'studies on LoRA rank, catastrophic forgetting, and LoRA variants' would benefit from naming the specific tasks, datasets, and metrics used in those studies for immediate clarity.
- [Tables/Figures] Tables/Figures: Include statistical details (e.g., standard deviations over multiple runs or significance tests) when reporting performance gaps to strengthen the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive suggestions. We address the major comments point by point below, and we will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: §3 (Experimental Setup): The description of 'naively switching' to Muon does not specify whether Muon hyperparameters (learning rate, momentum coefficients, weight decay) received independent optimization equivalent to Adam on the same tasks and data. Without this, the full fine-tuning gap cannot be confidently attributed to implicit-bias mismatch rather than suboptimal Muon tuning, which directly undermines the causal claim and the interpretation that LoRA mitigates mismatch by constraining updates.
Authors: We appreciate this observation. Upon review, the original manuscript did not provide sufficient detail on the hyperparameter tuning procedure for Muon. In the revised version, we will expand §3 to explicitly describe the independent hyperparameter optimization performed for Muon, including the grid search over learning rates, momentum coefficients, and weight decay values, conducted equivalently to Adam on the same tasks and datasets. This clarification will support the attribution of the performance gap to the optimizer mismatch arising from implicit biases. revision: yes
-
Referee: §4.2 and §5 (LoRA and Update Strength Analysis): The scaling of degradation with update strength is central to the hypothesis, yet the manuscript provides no explicit definition or measurement of update strength (e.g., update norm, effective step size, or gradient statistics) that is compared quantitatively between full fine-tuning and LoRA settings. This leaves the mediator role of update strength correlational rather than demonstrated.
Authors: We agree that a more rigorous quantification of update strength would better substantiate the hypothesis. In the revised manuscript, we will introduce an explicit definition of update strength, measured as the L2 norm of the parameter updates averaged over training steps. We will include quantitative comparisons of these update norms between full fine-tuning and various LoRA configurations, along with additional plots correlating update strength with performance degradation. This will provide stronger evidence for the mediating role of update strength. revision: yes
Circularity Check
Empirical study with no derivation chain or self-referential reductions
full rationale
The paper is a controlled empirical study comparing Adam and Muon fine-tuning, with claims supported by experiments on performance gaps, LoRA mitigation, and correlations with update strength. No equations, fitted parameters, or mathematical derivations are present that could reduce predictions or hypotheses to inputs by construction. Self-citations are absent from the provided text, and the central claims rely on observable experimental outcomes rather than any load-bearing self-referential logic. Hyperparameter concerns raised by the skeptic are valid experimental-design questions but do not constitute circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Adam and Muon have distinct implicit biases that affect how they update parameters and preserve pretrained knowledge.
Reference graph
Works this paper leans on
-
[1]
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
work page 2024
-
[2]
Diederik P. Kingma and Jimmy Ba , title =. International Conference on Learning Representations , year =
-
[3]
International Conference on Learning Representations , year =
Ilya Loshchilov and Frank Hutter , title =. International Conference on Learning Representations , year =
-
[4]
Muon is Scalable for LLM Training
Liu, Jingyuan and Su, Jianlin and Yao, Xingcheng and Jiang, Zhejun and Lai, Guokun and Du, Yulun and Qin, Yidao and Xu, Weixin and Lu, Enzhe and Yan, Junjie and others , title =. arXiv preprint arXiv:2502.16982 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Practical efficiency of muon for pretraining.arXiv preprint arXiv:2505.02222, 2025
Practical efficiency of muon for pretraining , author=. arXiv preprint arXiv:2505.02222 , year=
-
[6]
Kimi K2: Open Agentic Intelligence
Kimi Team and Bai, Yifan and Bao, Yiping and Chen, Guanduo and Chen, Jiahao and Chen, Ningxin and Chen, Ruijue and Chen, Yanru and Chen, Yuankun and Chen, Yutian and others , title =. arXiv preprint arXiv:2507.20534 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Glm-4.5: Agentic, reasoning, and coding (arc) foundation models , author=. arXiv preprint arXiv:2508.06471 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [8]
-
[9]
International Conference on Learning Representations , year =
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu and others , title =. International Conference on Learning Representations , year =
-
[10]
Psychology of learning and motivation , volume=
Catastrophic interference in connectionist networks: The sequential learning problem , author=. Psychology of learning and motivation , volume=. 1989 , publisher=
work page 1989
-
[11]
Trends in cognitive sciences , volume=
Catastrophic forgetting in connectionist networks , author=. Trends in cognitive sciences , volume=. 1999 , publisher=
work page 1999
-
[12]
Noah Amsel and David Persson and Christopher Musco and Robert M. Gower , title =. International Conference on Learning Representations , year =
-
[13]
A rank stabilization scaling factor for fine-tuning with lora
A rank stabilization scaling factor for fine-tuning with lora , author=. arXiv preprint arXiv:2312.03732 , year=
-
[14]
Yuanhe Zhang and Fanghui Liu and Yudong Chen , booktitle=. Lo
-
[15]
Advances in Neural Information Processing Systems , year=
Pissa: Principal singular values and singular vectors adaptation of large language models , author=. Advances in Neural Information Processing Systems , year=
-
[16]
Biderman, Dan and Portes, Jacob and Ortiz, Jose Javier Gonzalez and Paul, Mansheej and Greengard, Philip and Jennings, Connor and King, Daniel and Havens, Sam and Chiley, Vitaliy and Frankle, Jonathan and others , journal=
-
[17]
Penedo, Guilherme and Kydl\'. The. Advances in Neural Information Processing Systems , year =
-
[18]
Advances in Neural Information Processing Systems , year =
Hoffmann, Jordan and Borgeaud, Sebastian and Mensch, Arthur and Buchatskaya, Elena and Cai, Trevor and Rutherford, Eliza and Casas, Diego de Las and Hendricks, Lisa Anne and Welbl, Johannes and Clark, Aidan and others , title =. Advances in Neural Information Processing Systems , year =
-
[19]
Advances in Neural Information Processing Systems , year =
Li, Jeffrey and Fang, Alex and Smyrnis, Georgios and Ivgi, Maor and Jordan, Matt and Gadre, Samir Yitzhak and Bansal, Hritik and Guha, Etash and Keh, Sedrick Scott and Arora, Kushal and others , title =. Advances in Neural Information Processing Systems , year =
-
[20]
International Conference on Learning Representations , year=
Pointer Sentinel Mixture Models , author=. International Conference on Learning Representations , year=
-
[21]
Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
Old optimizer, new norm: An anthology , author=. arXiv preprint arXiv:2409.20325 , year=
-
[22]
Chenyang Zhang and Difan Zou and Yuan Cao , booktitle=. The Implicit Bias of
-
[23]
Advances in Neural Information Processing Systems , year=
Implicit Bias of Spectral Descent and Muon on Multiclass Separable Data , author=. Advances in Neural Information Processing Systems , year=
-
[24]
Transactions on Machine Learning Research , year=
Muon Optimizes Under Spectral Norm Constraints , author=. Transactions on Machine Learning Research , year=
-
[25]
Understanding gradient orthogonalization for deep learning via non-euclidean trust-region optimization , author=. arXiv preprint arXiv:2503.12645 , year=
- [26]
-
[27]
Bernstein, Jeremy and Wang, Yu-Xiang and Azizzadenesheli, Kamyar and Anandkumar, Animashree , booktitle=
-
[28]
Samyam Rajbhandari and Jeff Rasley and Olatunji Ruwase and Yuxiong He , title=. 2020 , booktitle=
work page 2020
-
[29]
Dion: Distributed orthonormalized updates.arXiv preprint arXiv:2504.05295, 2025
Dion: Distributed Orthonormalized Updates , author=. arXiv preprint: 2504.05295 , year=
-
[30]
Li, Zichong and Liu, Liming and Liang, Chen and Chen, Weizhu and Zhao, Tuo , journal=
-
[31]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Shaowen Wang and Linxi Yu and Jian Li , booktitle=. Lo
-
[33]
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. Journal of Machine Learning Research , year =
-
[34]
Alex Wang and Amanpreet Singh and Julian Michael and Felix Hill and Omer Levy and Samuel R. Bowman , title=. 2019 , booktitle=
work page 2019
- [35]
-
[36]
Yu, Longhui and JIANG, Weisen and Shi, Han and YU, Jincheng and Liu, Zhengying and Zhang, Yu and Kwok, James and Li, Zhenguo and Weller, Adrian and Liu, Weiyang , booktitle =
-
[37]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Tianyu Zheng and Ge Zhang and Tianhao Shen and Xueling Liu and Bill Yuchen Lin and Jie Fu and Wenhu Chen and Xiang Yue , title=. 2024 , booktitle=
work page 2024
-
[39]
Evaluating Large Language Models Trained on Code , author=. 2021 , journal=
work page 2021
-
[40]
Can Xu and Qingfeng Sun and Kai Zheng and Xiubo Geng and Pu Zhao and Jiazhan Feng and Chongyang Tao and Qingwei Lin and Daxin Jiang , booktitle=. Wizard
-
[41]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Rowan Zellers and Ari Holtzman and Yonatan Bisk and Ali Farhadi and Yejin Choi , title=. 2019 , booktitle=
work page 2019
-
[43]
Yonatan Bisk and Rowan Zellers and Ronan LeBras and Jianfeng Gao and Yejin Choi , title=. 2020 , booktitle=
work page 2020
-
[44]
Keisuke Sakaguchi and Ronan Le Bras and Chandra Bhagavatula and Yejin Choi , title=. 2020 , booktitle=
work page 2020
-
[45]
Christopher Clark and Kenton Lee and Ming-Wei Chang and Tom Kwiatkowski and Michael Collins and Kristina Toutanova , title=. 2019 , booktitle=
work page 2019
-
[46]
Todor Mihaylov and Peter Clark and Tushar Khot and Ashish Sabharwal , title=. 2018 , booktitle=
work page 2018
-
[47]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and others , title =. doi:10.5281/zenodo.12608602 , url =
-
[48]
Tao Li and Zhengbao He and Yujun Li and Yasheng Wang and Lifeng Shang and Xiaolin Huang , booktitle=
-
[49]
Wang, Zhengbo and Liang, Jian and He, Ran and Wang, Zilei and Tan, Tieniu , booktitle=
-
[50]
Proceedings of the International Conference on Machine Learning , year =
Learning Transferable Visual Models From Natural Language Supervision , author =. Proceedings of the International Conference on Machine Learning , year =
-
[51]
Proceedings of the IEEE International Conference on Computer Vision Workshops , year=
3D Object Representations for Fine-Grained Categorization , author=. Proceedings of the IEEE International Conference on Computer Vision Workshops , year=
-
[52]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year =
Cimpoi, Mircea and Maji, Subhransu and Kokkinos, Iasonas and Mohamed, Sammy and Vedaldi, Andrea , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year =
-
[53]
The German Traffic Sign Recognition Benchmark: A multi-class classification competition , year=
Stallkamp, Johannes and Schlipsing, Marc and Salmen, Jan and Igel, Christian , booktitle=. The German Traffic Sign Recognition Benchmark: A multi-class classification competition , year=
-
[54]
Remote Sensing Image Scene Classification: Benchmark and State of the Art , year=
Cheng, Gong and Han, Junwei and Lu, Xiaoqiang , journal=. Remote Sensing Image Scene Classification: Benchmark and State of the Art , year=
-
[55]
and Oliva, Aude and Torralba, Antonio , booktitle=
Xiao, Jianxiong and Hays, James and Ehinger, Krista A. and Oliva, Aude and Torralba, Antonio , booktitle=. 2010 , pages=
work page 2010
-
[56]
NIPS workshop on deep learning and unsupervised feature learning , year=
Reading digits in natural images with unsupervised feature learning , author=. NIPS workshop on deep learning and unsupervised feature learning , year=
-
[57]
International Conference on Learning Representations , year=
Understanding Catastrophic Forgetting in Language Models via Implicit Inference , author=. International Conference on Learning Representations , year=
-
[58]
International Conference on Learning Representations , year=
Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning , author=. International Conference on Learning Representations , year=
-
[59]
Jui-Nan Yen and Si Si and Zhao Meng and Felix Yu and Sai Surya Duvvuri and Inderjit S Dhillon and Cho-Jui Hsieh and Sanjiv Kumar , booktitle=. Lo
-
[60]
Shih-yang Liu and Chien-Yi Wang and Hongxu Yin and Pavlo Molchanov and Yu-Chiang Frank Wang and Kwang-Ting Cheng and Min-Hung Chen , booktitle=. Do
-
[61]
International Conference on Learning Representations , year=
LoFT: Low-Rank Adaptation That Behaves Like Full Fine-Tuning , author=. International Conference on Learning Representations , year=
- [62]
-
[63]
Accelerating Newton-Schulz Iteration for Orthogonalization via Chebyshev-type Polynomials , author=. arXiv preprint arXiv:2506.10935 , year=
-
[64]
Isotropic Curvature Model for Understanding Deep Learning Optimization: Is Gradient Orthogonalization Optimal? , author=. arXiv preprint arXiv:2511.00674 , year=
-
[65]
Attention is All you Need , year =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , year =
-
[66]
RoFormer: Enhanced Transformer with Rotary Position Embedding,
Ro. Neurocomputing , volume =. 2024 , issn =. doi:https://doi.org/10.1016/j.neucom.2023.127063 , author =
-
[67]
Advances in Neural Information Processing Systems , year=
Searching for Efficient Transformers for Language Modeling , author=. Advances in Neural Information Processing Systems , year=
-
[68]
Gaussian Error Linear Units (GELUs)
Gaussian Error Linear Units (Gelus) , author=. arXiv preprint arXiv:1606.08415 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
doi:10.5281/zenodo.15403103 , url =
Cherti, Mehdi and Beaumont, Romain , title =. doi:10.5281/zenodo.15403103 , url =
-
[70]
Hongyu Li and Liang Ding and Meng Fang and Dacheng Tao , title=. 2024 , booktitle=
work page 2024
-
[71]
Nikhil Vyas and Depen Morwani and Rosie Zhao and Itai Shapira and David Brandfonbrener and Lucas Janson and Sham M. Kakade , booktitle=
-
[72]
Kimi Linear: An Expressive, Efficient Attention Architecture , author=. 2025 , journal=
work page 2025
-
[73]
and Klusowski, Jason Matthew and Shigida, Boris , booktitle =
Cattaneo, Matias D. and Klusowski, Jason Matthew and Shigida, Boris , booktitle =. On the Implicit Bias of
-
[74]
Query-Key Normalization for Transformers
Henry, Alex and Dachapally, Prudhvi Raj and Pawar, Shubham Shantaram and Chen, Yuxuan. Query-Key Normalization for Transformers. Findings of the Association for Computational Linguistics: EMNLP. 2020
work page 2020
-
[75]
International Conference on Learning Representations , year=
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima , author=. International Conference on Learning Representations , year=
-
[76]
Language models are unsupervised multitask learners , author=. OpenAI blog , year=
-
[77]
The large learning rate phase of deep learning: the catapult mechanism , author=. arXiv preprint arXiv:2003.02218 , year=
-
[78]
Thejas and Nipun Kwatra and Ramachandran Ramjee and Muthian Sivathanu , title =
Nikhil Iyer and V. Thejas and Nipun Kwatra and Ramachandran Ramjee and Muthian Sivathanu , title =. Journal of Machine Learning Research , year =
-
[79]
International Conference on Machine Learning , year=
Shampoo: Preconditioned stochastic tensor optimization , author=. International Conference on Machine Learning , year=
-
[80]
Reece S Shuttleworth and Jacob Andreas and Antonio Torralba and Pratyusha Sharma , booktitle=. Lo
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.