Recognition: 1 theorem link
· Lean TheoremAdaPaD: Adaptive Parallel Deflation for PEFT with Self-Correcting Rank Discovery
Pith reviewed 2026-05-12 04:45 UTC · model grok-4.3
The pith
AdaPaD trains rank-1 components simultaneously so that each refines against improving deflation targets from the others, producing self-correcting error decay and dynamic rank discovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
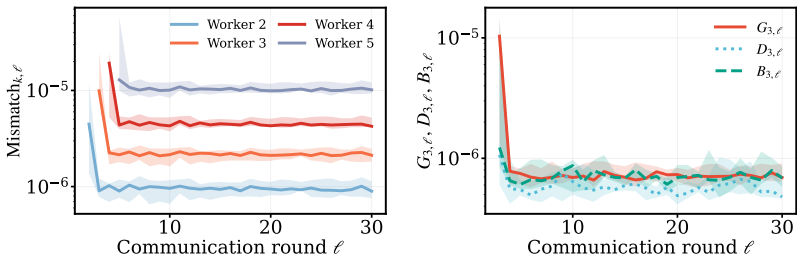
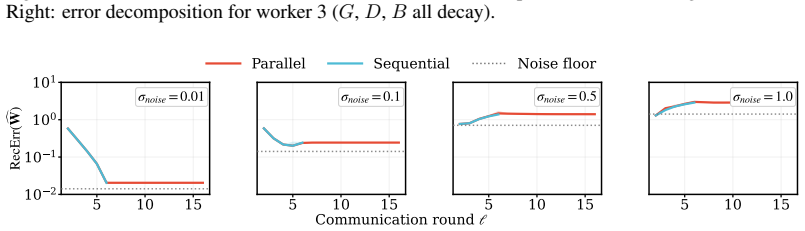
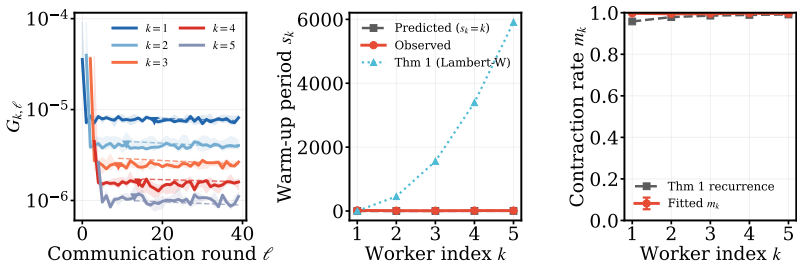
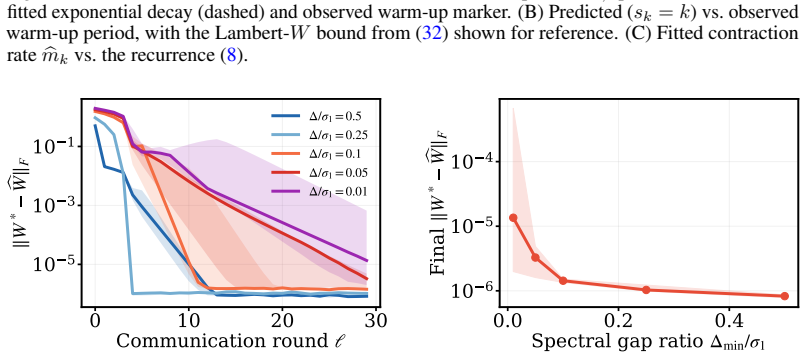
AdaPaD performs adaptive parallel deflation: all rank-1 factors are optimized concurrently, each against a deflation target built from the latest estimates of the preceding factors; as those estimates improve, the targets improve, driving deflation errors to zero over rounds instead of leaving permanent residuals. The method further incorporates advance learning (private pre-training of each component before joint activation) and per-module dynamic rank growth driven by importance scores until a shared parameter budget is exhausted. The analysis shows exponential decay of per-component error after warm-up together with a generalization bound whose algorithmic part vanishes while the data-siz
What carries the argument
self-correcting parallel deflation, in which each rank-1 component is refined against a deflation target assembled from the current estimates of all predecessors so that improving estimates produce improving targets and vanishing residuals.
If this is right
- Rank selection becomes an output of training rather than a hyper-parameter chosen before training begins.
- The generalization bound separates cleanly into an algorithmic term that vanishes with more rounds and a statistical term that depends only on data size and model capacity.
- All rank-1 components can be trained in parallel while still enjoying per-component guarantees that sequential deflation methods lose once a component is frozen.
- A fixed total parameter budget can be allocated adaptively across modules according to importance, producing smaller adapters that remain competitive.
Where Pith is reading between the lines
- The self-correction mechanism may extend to other sequential low-rank factorizations beyond LoRA, such as tensor decompositions or matrix factorizations in non-fine-tuning settings.
- Because ranks are discovered per module, the method could be combined with pruning or quantization pipelines that also operate on a global budget.
- The exponential decay guarantee suggests that early stopping per component could be safe once its residual norm falls below a threshold, potentially saving compute.
Load-bearing premise
The deflation targets assembled from the latest estimates of preceding components improve enough over rounds for the self-correction property to produce the claimed exponential error decay.
What would settle it
An experiment that keeps the same per-component update rule and budget but records per-component residual norms across rounds and finds that at least one component's error fails to decay exponentially after the warm-up window.
Figures


read the original abstract
Fine-tuning large language models with LoRA requires choosing a rank r before training starts. Existing approaches either extract rank-1 components sequentially, freezing each component's error permanently into every subsequent residual, or optimize the full low-rank factorization jointly with guarantees that describe only the joint update, not individual rank-1 directions. We present AdaPaD (Adaptive Parallel Deflation), which trains all rank-1 components simultaneously: each worker refines its component against a deflation target built from the latest estimates of all predecessors, and as those estimates improve, the targets improve too. We call this property self-correction: deflation errors converge to zero over rounds rather than persisting as fixed residuals. On top of this backbone, AdaPaD adds advance learning (private pre-training before activation) and per-module dynamic rank discovery (importance-based growth until a shared budget is exhausted), making the rank distribution an output rather than an input. We prove that every component's error decays exponentially after a warm-up period, with a generalization bound that splits into a vanishing algorithmic term and an irreducible statistical floor. Empirically, AdaPaD is competitive with adaptive-rank LoRA baselines on GLUE with DeBERTaV3-base at matched parameter budgets, and competitive with fixed-rank LoRA on Qwen3-0.6B SQuAD/SQuAD v2 while deploying an adapter that is on average 30.7% smaller.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AdaPaD for parameter-efficient fine-tuning of LLMs via LoRA. It trains all rank-1 components in parallel, with each refining against a deflation target built from the latest predecessor estimates (self-correction property, so errors converge rather than persist as fixed residuals). It adds advance learning (private pre-training) and per-module dynamic rank discovery (importance-based growth until a shared budget is exhausted), making rank allocation an output. The authors claim a proof that every component's error decays exponentially after a warm-up period, plus a generalization bound splitting into a vanishing algorithmic term and an irreducible statistical floor. Empirically, AdaPaD is competitive with adaptive-rank LoRA baselines on GLUE using DeBERTaV3-base at matched budgets and with fixed-rank LoRA on Qwen3-0.6B SQuAD/SQuAD v2 while producing adapters that are on average 30.7% smaller.
Significance. If the self-correction and exponential-decay claims hold, the work would be significant for PEFT: it supplies the first parallel deflation scheme with per-component guarantees, overcoming the permanent residual error of sequential methods and the lack of individual-direction analysis in joint factorizations. The dynamic rank discovery (rank as output) and the split generalization bound are practical and theoretical strengths. Credit is due for attempting an explicit contraction argument rather than joint-update bounds only.
major comments (2)
- The central claim of exponential error decay for every component after warm-up (abstract) rests on self-correction via parallel-updated predecessor estimates. In a fully parallel scheme this creates a potential circular dependence: the contraction factor for component k at round t implicitly requires that components 1..k-1 have already contracted sufficiently in the same round. The manuscript must supply the specific lemma, assumption list, or joint Lyapunov/contraction-mapping argument that bounds the maximum lag across active components independently of the dynamic rank-discovery process; without it the uniform exponential rate may not hold once new components are added.
- Empirical claims are stated only as 'competitive' (abstract) without visible quantitative tables, baseline details, statistical significance tests, or error bars. This undermines assessment of whether the self-correcting parallel scheme actually delivers the claimed efficiency gains at matched parameter budgets on GLUE and SQuAD.
minor comments (2)
- Clarify the precise assumptions (e.g., on improvement rate of deflation targets) required for the exponential decay to begin after the warm-up period.
- The generalization bound description ('vanishing algorithmic term and irreducible statistical floor') should be cross-referenced to the exact theorem statement and proof sketch.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's potential significance and for the constructive feedback. We address each of the major comments below.
read point-by-point responses
-
Referee: The central claim of exponential error decay for every component after warm-up (abstract) rests on self-correction via parallel-updated predecessor estimates. In a fully parallel scheme this creates a potential circular dependence: the contraction factor for component k at round t implicitly requires that components 1..k-1 have already contracted sufficiently in the same round. The manuscript must supply the specific lemma, assumption list, or joint Lyapunov/contraction-mapping argument that bounds the maximum lag across active components independently of the dynamic rank-discovery process; without it the uniform exponential rate may not hold once new components are added.
Authors: We agree that a more explicit treatment of the parallel update dynamics is warranted to fully substantiate the exponential decay claim. The current proof sketch relies on a warm-up period during which initial estimates stabilize, followed by a contraction argument for each component's error relative to its deflation target. To resolve the potential circular dependence and account for dynamic rank discovery, we will add a dedicated lemma in the revised manuscript. This lemma will use a joint contraction mapping over the active set of components, showing that the lag in predecessor estimates is bounded by a term that decays exponentially with the number of rounds, independently of when new components are introduced by the rank discovery process. The assumptions (e.g., bounded gradients and a uniform contraction factor ρ < 1 after warm-up) will be listed explicitly. We believe this addition will strengthen the theoretical section without altering the core claims. revision: yes
-
Referee: Empirical claims are stated only as 'competitive' (abstract) without visible quantitative tables, baseline details, statistical significance tests, or error bars. This undermines assessment of whether the self-correcting parallel scheme actually delivers the claimed efficiency gains at matched parameter budgets on GLUE and SQuAD.
Authors: The full manuscript does include quantitative tables (Table 1 for GLUE with DeBERTaV3-base and Table 2 for SQuAD with Qwen3-0.6B) that report performance metrics against baselines including fixed-rank LoRA, AdaLoRA, and other adaptive methods at matched parameter budgets. The 30.7% smaller adapter size is computed from the average final ranks across modules. However, we acknowledge that the presentation could be improved for clarity. In the revision, we will add error bars to the relevant figures, include standard deviations and run counts in the tables, and report results of statistical significance tests (paired t-tests) comparing AdaPaD to the strongest baselines. Baseline details will be expanded in the experimental setup section. These changes will make the efficiency gains more transparent. revision: yes
Circularity Check
No circularity: derivation relies on independent proof of contraction under parallel updates.
full rationale
The central claim is a proof that component errors decay exponentially after warm-up due to the self-correction mechanism in parallel deflation, where each rank-1 update uses the latest predecessor estimates to form improving targets. This mechanism is described as arising from the simultaneous training procedure rather than being presupposed; the exponential rate is presented as a derived consequence under stated assumptions about improvement rates, not as a renaming or redefinition of the input. No equations reduce a prediction to a fitted parameter by construction, no self-citation chain bears the load of the uniqueness or contraction argument, and the generalization bound is structured as a standard decomposition into algorithmic and statistical terms without tautological dependence on the target result. The derivation is therefore self-contained against external verification of the proof steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- shared rank budget
axioms (1)
- domain assumption Deflation targets improve over rounds so that early errors do not persist as fixed residuals
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We prove that every component's error decays exponentially after a warm-up period... self-correction: deflation errors converge to zero over rounds rather than persisting as fixed residuals (Proposition 2, Theorem 1).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Conference on Learning Theory , pages=
Dropping convexity for faster semi-definite optimization , author=. Conference on Learning Theory , pages=. 2016 , organization=
work page 2016
-
[2]
SIAM Journal on Imaging Sciences , volume=
Finding low-rank solutions via nonconvex matrix factorization, efficiently and provably , author=. SIAM Journal on Imaging Sciences , volume=. 2018 , publisher=
work page 2018
-
[3]
Fast quantum state reconstruction via accelerated non-convex programming , author=. Photonics , volume=. 2023 , publisher=
work page 2023
-
[4]
IEEE Transactions on Signal Processing , volume=
A non-Euclidean gradient descent framework for non-convex matrix factorization , author=. IEEE Transactions on Signal Processing , volume=. 2018 , publisher=
work page 2018
-
[5]
International Conference on Artificial Intelligence and Statistics , pages=
Low-rank regularization and solution uniqueness in over-parameterized matrix sensing , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
work page 2020
-
[6]
Artificial intelligence and statistics , pages=
Non-square matrix sensing without spurious local minima via the Burer-Monteiro approach , author=. Artificial intelligence and statistics , pages=. 2017 , organization=
work page 2017
-
[7]
Advances in Neural Information Processing Systems , year =
Arora, Sanjeev and Cohen, Nadav and Hu, Wei and Luo, Yuping , title =. Advances in Neural Information Processing Systems , year =
- [8]
-
[9]
Burer, Samuel and Monteiro, Renato D. C. , title =. Mathematical Programming , volume =
-
[10]
Exact Matrix Completion via Convex Optimization , journal =
Cand. Exact Matrix Completion via Convex Optimization , journal =
- [11]
-
[12]
International Conference on Learning Representations , year =
Gemp, Ian and McWilliams, Brian and Sandholm, Tuomas and Vernade, Claire , title =. International Conference on Learning Representations , year =
-
[13]
Journal of Educational Psychology , volume =
Hotelling, Harold , title =. Journal of Educational Psychology , volume =
-
[14]
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =. International Conference on Learning Representations , year =
-
[15]
Advances in Neural Information Processing Systems , year =
Jain, Prateek and Meka, Raghu and Dhillon, Inderjit , title =. Advances in Neural Information Processing Systems , year =
-
[16]
Journal of Mathematical Imaging and Vision , volume =
Kyrillidis, Anastasios and Cevher, Volkan , title =. Journal of Mathematical Imaging and Vision , volume =
-
[17]
npj Quantum Information , volume =
Kyrillidis, Anastasios and Kalev, Amir and Park, Daniel and Bhojanapalli, Srinadh and Caramanis, Constantine and Sanghavi, Sujay , title =. npj Quantum Information , volume =
-
[18]
Proceedings of the 41st International Conference on Machine Learning (ICML) , pages =
Liao, Fangshuo and Kim, Junhyung Lyle and Barnum, Cruz and Kyrillidis, Anastasios , title =. Proceedings of the 41st International Conference on Machine Learning (ICML) , pages =
-
[19]
Proceedings of the Conference on Parsimony and Learning (CPAL) , year =
Liao, Fangshuo and Su, Wenyi and Kyrillidis, Anastasios , title =. Proceedings of the Conference on Parsimony and Learning (CPAL) , year =
-
[20]
Advances in Neural Information Processing Systems , year =
Mackey, Lester , title =. Advances in Neural Information Processing Systems , year =
- [21]
-
[22]
International Conference on Machine Learning , year =
Tu, Stephen and Boczar, Ross and Simchowitz, Max and Soltanolkotabi, Mahdi and Recht, Benjamin , title =. International Conference on Machine Learning , year =
-
[23]
arXiv preprint arXiv:2505.22602 , year =
Vandchali, Mahtab Alizadeh and Liao, Fangshuo and Kyrillidis, Anastasios , title =. arXiv preprint arXiv:2505.22602 , year =
-
[24]
Perturbation Bounds in Connection with Singular Value Decomposition , journal =
Wedin, Per-. Perturbation Bounds in Connection with Singular Value Decomposition , journal =
-
[25]
Mathematische Annalen , volume =
Weyl, Hermann , title =. Mathematische Annalen , volume =
-
[26]
IEEE Transactions on Signal Processing , volume =
Yang, Bin , title =. IEEE Transactions on Signal Processing , volume =
-
[27]
Proceedings of the 45th Annual ACM Symposium on Theory of Computing (STOC) , pages=
Low-rank Matrix Completion using Alternating Minimization , author=. Proceedings of the 45th Annual ACM Symposium on Theory of Computing (STOC) , pages=
-
[28]
Proceedings of the 33rd International Conference on Machine Learning (ICML) , pages=
Low-rank Solutions of Linear Matrix Equations via Procrustes Flow , author=. Proceedings of the 33rd International Conference on Machine Learning (ICML) , pages=
-
[29]
Advances in Neural Information Processing Systems , year=
A Convergent Gradient Descent Algorithm for Rank Minimization and Semidefinite Programming from Random Linear Measurements , author=. Advances in Neural Information Processing Systems , year=
-
[30]
Proceedings of the 34th International Conference on Machine Learning (ICML) , pages=
No Spurious Local Minima in Nonconvex Low Rank Problems: A Unified Geometric Analysis , author=. Proceedings of the 34th International Conference on Machine Learning (ICML) , pages=
-
[31]
International Conference on Learning Representations , year =
Zhang, Qingru and Chen, Minshuo and Bukharin, Alexander and He, Pengcheng and Cheng, Yu and Chen, Weizhu and Zhao, Tuo , title =. International Conference on Learning Representations , year =
-
[32]
arXiv preprint arXiv:2308.12043 , year =
Zhang, Feiyu and Li, Liangzhi and Chen, Junhao and Jiang, Zhouqiang and Wang, Bowen and Qian, Yiming , title =. arXiv preprint arXiv:2308.12043 , year =
-
[33]
Valipour, Mojtaba and Rezagholizadeh, Mehdi and Kobyzev, Ivan and Ghodsi, Ali , title =. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , pages =
-
[34]
Ding, Ning and Lv, Xingtai and Wang, Qiaosen and Chen, Yulin and Zhou, Bowen and Liu, Zhiyuan and Sun, Maosong , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
work page 2023
-
[35]
International Conference on Learning Representations (ICLR) , year =
Lialin, Vladislav and Shivagunde, Namrata and Muckatira, Sherin and Rumshisky, Anna , title =. International Conference on Learning Representations (ICLR) , year =
-
[36]
Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung , title =. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[37]
Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
Hayou, Soufiane and Ghosh, Nikhil and Yu, Bin , title =. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[38]
Proceedings of the 41st International Conference on Machine Learning , year =
Zhao, Jiawei and Zhang, Zhenyu and Chen, Beidi and Wang, Zhangyang and Anandkumar, Animashree and Tian, Yuandong , title =. Proceedings of the 41st International Conference on Machine Learning , year =
-
[39]
Wang, Sheng and Xue, Boyang and Ye, Jiacheng and Jiang, Jiyue and Chen, Liheng and Kong, Lingpeng and Wu, Chuan , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
-
[40]
Li, Xiang Lisa and Liang, Percy , title =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP) , pages =
-
[41]
Proceedings of the 36th International Conference on Machine Learning (ICML) , pages =
Houlsby, Neil and Giurgiu, Andrei and Jastrzebski, Stanislaw and Morrone, Bruna and de Laroussilhe, Quentin and Gesmundo, Andrea and Attariyan, Mona and Gelly, Sylvain , title =. Proceedings of the 36th International Conference on Machine Learning (ICML) , pages =
-
[42]
Ben Zaken, Elad and Ravfogel, Shauli and Goldberg, Yoav , title =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages =
-
[43]
Journal of Mathematical Biology , volume =
Oja, Erkki , title =. Journal of Mathematical Biology , volume =
-
[44]
International Conference on Learning Representations (ICLR) , year =
Zangrando, Emanuele and Venturini, Sara and Rinaldi, Francesco and Tudisco, Francesco , title =. International Conference on Learning Representations (ICLR) , year =
-
[45]
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy , title =. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
work page 2016
- [46]
-
[47]
Neural Tangent Kernel: Convergence and Generalization in Neural Networks , booktitle =
Jacot, Arthur and Gabriel, Franck and Hongler, Cl. Neural Tangent Kernel: Convergence and Generalization in Neural Networks , booktitle =
-
[48]
and Hu, Wei and Li, Zhiyuan and Salakhutdinov, Russ and Wang, Ruosong , title =
Arora, Sanjeev and Du, Simon S. and Hu, Wei and Li, Zhiyuan and Salakhutdinov, Russ and Wang, Ruosong , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[49]
and Bahri, Yasaman and Novak, Roman and Sohl-Dickstein, Jascha and Pennington, Jeffrey , title =
Lee, Jaehoon and Xiao, Lechao and Schoenholz, Samuel S. and Bahri, Yasaman and Novak, Roman and Sohl-Dickstein, Jascha and Pennington, Jeffrey , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[50]
International Conference on Machine Learning (ICML) , year =
Malladi, Sadhika and Wettig, Alexander and Yu, Dingli and Chen, Danqi and Arora, Sanjeev , title =. International Conference on Machine Learning (ICML) , year =
-
[51]
Rajpurkar, Pranav and Jia, Robin and Liang, Percy , title =. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
- [52]
-
[53]
The Quarterly Journal of Mathematics , volume =
Mirsky, Leon , title =. The Quarterly Journal of Mathematics , volume =
-
[54]
IEEE Transactions on Artificial Intelligence , year =
Shinwari, Abdul Rafay and Usama, Muhammad , title =. IEEE Transactions on Artificial Intelligence , year =
- [55]
- [56]
-
[57]
Proceedings of the VLDB Endowment , volume =
Li, Shen and Zhao, Yanli and Varma, Rohan and Salpekar, Omkar and Noordhuis, Pieter and Li, Teng and Paszke, Adam and Smith, Jeff and Vaughan, Brian and Damania, Pritam and Chintala, Soumith , title =. Proceedings of the VLDB Endowment , volume =
-
[58]
Horovod: fast and easy distributed deep learning in TensorFlow
Sergeev, Alexander and Del Balso, Mike , title =. arXiv preprint arXiv:1802.05799 , year =
-
[59]
Rajbhandari, Samyam and Rasley, Jeff and Ruwase, Olatunji and He, Yuxiong , title =. Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC) , year =
-
[60]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Shoeybi, Mohammad and Patwary, Mostofa and Puri, Raul and LeGresley, Patrick and Casper, Jared and Catanzaro, Bryan , title =. arXiv preprint arXiv:1909.08053 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[61]
International Conference on Learning Representations (ICLR) , year =
He, Pengcheng and Gao, Jianfeng and Chen, Weizhu , title =. International Conference on Learning Representations (ICLR) , year =
-
[62]
arXiv preprint arXiv:2505.09388 , year =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.