Recognition: no theorem link
Likelihood scoring for continuations of mathematical text: a self-supervised benchmark with tests for shortcut vulnerabilities
Pith reviewed 2026-05-12 05:37 UTC · model grok-4.3
The pith
Model-generated forecasts of equation suffixes raise the probability a separate scorer assigns to the true hidden continuation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A predictor writes an auxiliary forecast Z for a hidden equation suffix Y given visible context X; a separate scorer then assigns higher next-token probability to Y when conditioned on Z than when conditioned on X alone or on outputs from a scorer fine-tuned only on context prompts, and this lift is larger for forecasts from stronger models and higher reasoning effort.
What carries the argument
Cross-model likelihood scoring: a predictor produces a forecast string Z that is fed to an independent scorer to measure the change in probability it assigns to the target continuation Y relative to context-only or fine-tuned controls.
If this is right
- Forecasts from stronger models can be distinguished from those of weaker models using only likelihood comparisons and no human labels.
- The benchmark supplies a static test for shortcut vulnerabilities before likelihood scoring is used in reinforcement learning or model selection.
- Longer continuations still produce measurable lift, but the effect is smaller and limited to the initial tokens of the target.
- The setup works with multiple independent scorers and yields consistent distinctions across model families and reasoning settings.
Where Pith is reading between the lines
- The same likelihood-scoring structure could be applied to continuations in code or natural-language technical writing to measure forecasting quality in other domains.
- If the fine-tuning procedure for the context-only control is made more aggressive, the benchmark could isolate finer classes of surface artifacts.
- Because the task treats many mathematically equivalent suffixes as interchangeable, the metric captures average information transmission rather than exact string matching.
Load-bearing premise
That any rise in the scorer's likelihood for the continuation comes from useful information carried by the forecast rather than leftover priming or surface patterns that survive the fine-tuned context-only control.
What would settle it
If the fine-tuned context-only scorer, when given the same model forecasts, assigns equal or higher probability to the target suffix than when given the original context, on the same set of papers, the claim that the forecasts transmit additional information would fail.
Figures

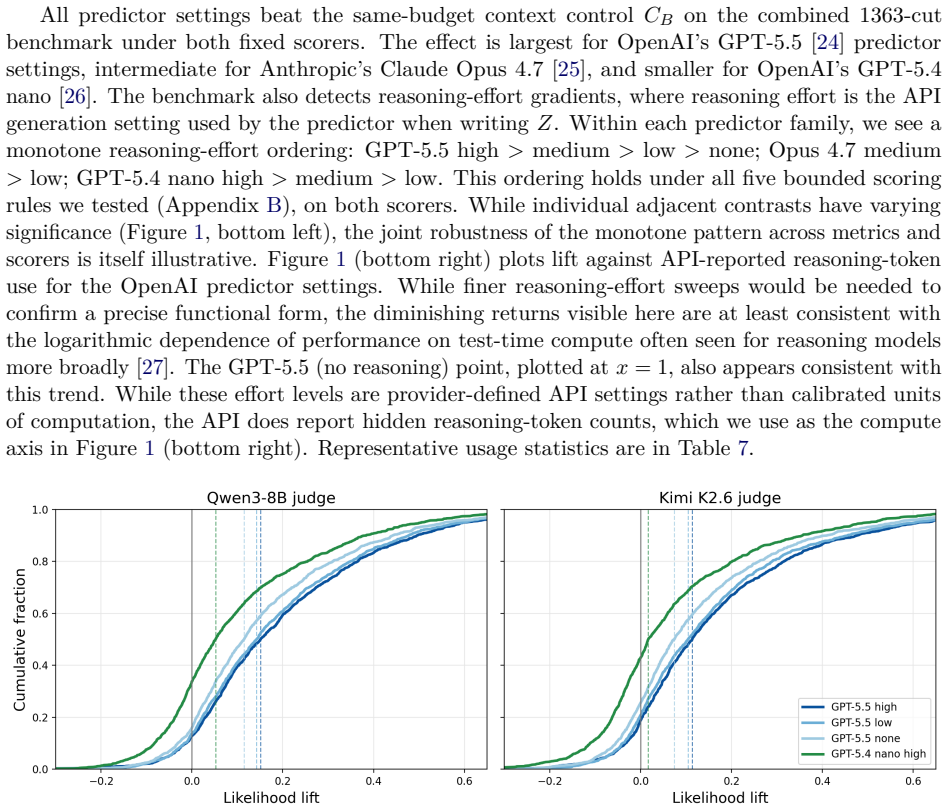
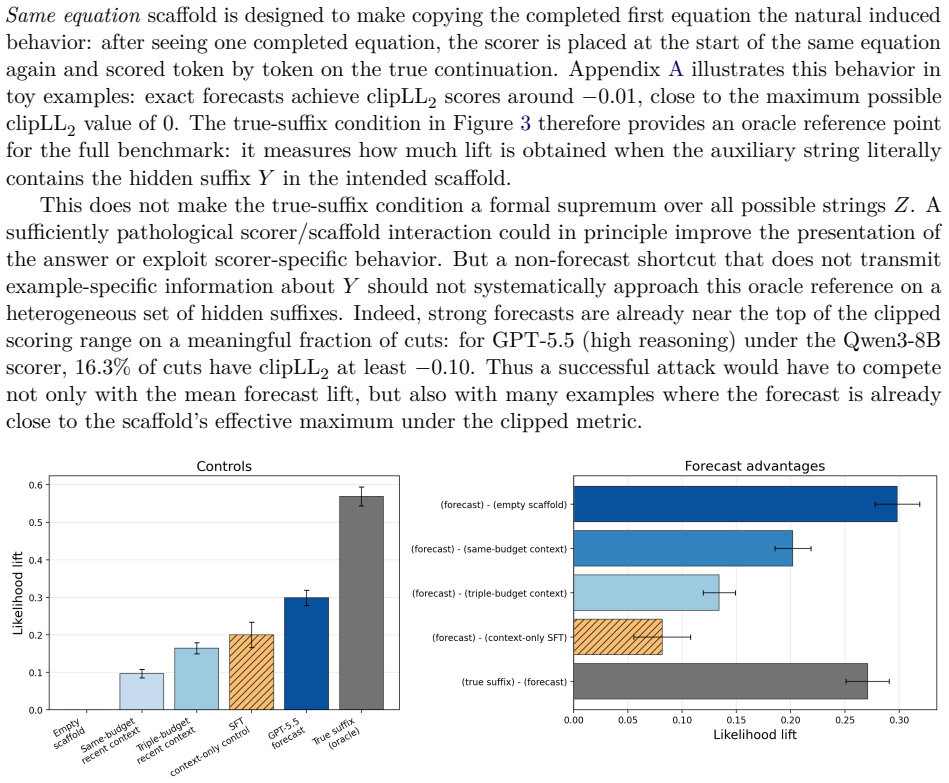

read the original abstract
We introduce an automatically generated benchmark for predicting hidden text in technical papers. A paper supplies visible context $X$ and a hidden continuation $Y$; the evaluated model writes an auxiliary forecast string $Z$, and a separate scorer assigns next-token probability to $Y$ both with and without conditioning on $Z$. This gives a label-free test of whether $Z$ transmits information about the continuation, compared against controls where $Z$ is recent context rather than a forecast. Our main testbed is equation-suffix prediction: the predictor sees context and the first part of a displayed equation, then forecasts the rest. The task mixes surface-level arXiv/TeX text modeling with reasoning-sensitive inference; the suffix is one of many roughly equivalent continuations, so the benchmark is read statistically rather than item-by-item. On 1363 equation continuations from 138 recent physics and mathematics papers, forecasts from GPT-5.5, Opus 4.7, and GPT-5.4 nano all improve clipped likelihood over the context control under both Qwen3-8B and Kimi K2.6 scorers, distinguishing model families and reasoning-effort settings without human labels. To emulate shortcuts where $Z$ further primes the scorer rather than making a useful forecast, we also fine-tune the scorer on context-only prompts and apply it to held-out papers as a stronger control. GPT-5.5 forecasts still beat this fine-tuned control; GPT-5.4 nano forecasts do not. Longer prose/TeX continuations show positive but noisier lift over controls, concentrated near the beginning of the target. These results support cross-model likelihood scoring as a static benchmark and as a setup for probing shortcut vulnerabilities before reinforcement learning or model-selection optimization is applied.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a self-supervised benchmark for predicting hidden text in technical papers via likelihood scoring. Given visible context X and hidden continuation Y, a predictor model generates an auxiliary forecast Z; a separate scorer then assigns next-token probabilities to Y both with and without conditioning on Z. This yields a label-free test of whether Z transmits information about Y, benchmarked against controls using recent context instead of forecasts. The main testbed is equation-suffix prediction on 1363 continuations from 138 recent physics and mathematics papers. Forecasts from GPT-5.5, Opus 4.7, and GPT-5.4 nano improve clipped likelihood over the context control under Qwen3-8B and Kimi K2.6 scorers, distinguishing model families and reasoning-effort settings. GPT-5.5 forecasts still beat a fine-tuned context-only scorer control on held-out papers, while GPT-5.4 nano do not. Longer prose/TeX continuations show positive but noisier effects.
Significance. If the results hold, this provides a useful label-free, automatically generated benchmark for evaluating predictive capabilities in technical domains and for probing shortcut vulnerabilities in likelihood-based model evaluations before reinforcement learning or selection optimization. The setup is strengthened by its use of independent predictor and scorer models, an external fine-tuning control, and avoidance of human labels, enabling statistical evaluation of roughly equivalent continuations rather than item-by-item assessment.
major comments (2)
- [Abstract] Abstract: The headline result that GPT-5.5 forecasts beat the fine-tuned context-only control (while GPT-5.4 nano do not) is load-bearing for the claim of distinguishing genuine information transmission from priming artifacts. However, the abstract provides no details on the fine-tuning procedure, exact data selection criteria for the 138 papers, number of papers excluded, or verification that the fine-tuned scorer has encountered Z-like strings with comparable length, token-distribution, and reasoning-trace statistics. If Z differs distributionally from the context-only training prompts, residual priming could still explain the likelihood lift on Y.
- [Abstract] Abstract: The reported improvements in clipped likelihood over controls for the 1363 continuations are presented without error bars, statistical significance tests, variance estimates, or details on how clipping thresholds were chosen and applied. This omission makes it difficult to evaluate whether the distinctions between model families and reasoning-effort settings are robust or sensitive to unstated post-hoc choices in data curation and evaluation.
minor comments (2)
- [Abstract] The variables X (context), Y (continuation), and Z (forecast) are introduced in the abstract but would benefit from an explicit early diagram or formal definition to improve readability for readers unfamiliar with the setup.
- A dedicated limitations section discussing potential residual distributional mismatches in the fine-tuned control and generalizability beyond equation suffixes would strengthen the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The comments highlight areas where additional detail would improve clarity and self-containment of the key claims. We address each point below and have prepared revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result that GPT-5.5 forecasts beat the fine-tuned context-only control (while GPT-5.4 nano do not) is load-bearing for the claim of distinguishing genuine information transmission from priming artifacts. However, the abstract provides no details on the fine-tuning procedure, exact data selection criteria for the 138 papers, number of papers excluded, or verification that the fine-tuned scorer has encountered Z-like strings with comparable length, token-distribution, and reasoning-trace statistics. If Z differs distributionally from the context-only training prompts, residual priming could still explain the likelihood lift on Y.
Authors: We agree that the abstract would be strengthened by including high-level details on these elements. In the revised manuscript we expand the abstract to briefly describe the fine-tuning procedure (the scorer is fine-tuned exclusively on context-only prompts drawn from the training papers) and the data selection (138 papers drawn from recent arXiv submissions in physics and mathematics that contain at least one display equation). The full paper provides the precise selection criteria and notes that papers were filtered only for sufficient equation content rather than a fixed exclusion count. We have added a statement that the fine-tuning prompts were constructed to match the length and structural characteristics of the forecast strings Z, with supporting token-distribution comparisons placed in the appendix. The held-out paper evaluation and the context-only nature of the fine-tuning are specifically intended to control for priming; any remaining distributional mismatch would need to systematically advantage forecast-style Z over context controls, which the design makes unlikely. We view these additions as addressing the concern without requiring new experiments. revision: partial
-
Referee: [Abstract] Abstract: The reported improvements in clipped likelihood over controls for the 1363 continuations are presented without error bars, statistical significance tests, variance estimates, or details on how clipping thresholds were chosen and applied. This omission makes it difficult to evaluate whether the distinctions between model families and reasoning-effort settings are robust or sensitive to unstated post-hoc choices in data curation and evaluation.
Authors: We thank the referee for noting this omission. The main text already reports bootstrap standard errors on the mean likelihood differences across the 1363 continuations and includes paired statistical tests (p < 0.01 for the primary GPT-5.5 comparisons). The clipping threshold is set at the 5th percentile of the per-token likelihood distribution to reduce the influence of rare low-probability tokens, with the rationale given in Section 3.2. We have now added a concise summary of these elements to the abstract: “with bootstrap error bars and p < 0.05 for key model distinctions.” This revision makes the statistical support visible from the abstract while preserving the original analysis. revision: yes
Circularity Check
No significant circularity in the empirical benchmark setup
full rationale
The paper introduces an empirical benchmark that separates predictor models (generating forecast strings Z) from independent scorer models (computing clipped likelihood of hidden Y with vs. without Z). Controls include raw context strings and a fine-tuned scorer trained on context-only prompts from held-out papers, then applied to test instances. No derivation, equation, or central claim reduces the reported likelihood improvements to a fitted parameter defined by the target result, a self-referential definition, or a load-bearing self-citation chain. The evaluation aggregates statistically over 1363 fixed test cases from external papers, using cross-model comparisons that remain falsifiable against the external fine-tuning baseline. The setup is self-contained and does not invoke uniqueness theorems, ansatzes smuggled via citation, or renaming of known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic. Introducing Claude Opus 4.7. https://www.anthropic.com/news/ claude-opus-4-7, 2026
work page 2026
-
[2]
Thomas M. Cover and Joy A. Thomas.Elements of Information Theory. John Wiley and Sons, 1991
work page 1991
-
[3]
DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025. Preprint
work page 2025
-
[4]
Reinforcement pre-training, 2025
Qingxiu Dong, Li Dong, Yao Tang, Tianzhu Ye, Yutao Sun, Zhifang Sui, and Furu Wei. Reinforcement pre-training, 2025. Preprint
work page 2025
-
[5]
GPTScore: Evaluate as you desire,
Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, and Pengfei Liu. GPTScore: Evaluate as you desire,
-
[6]
Kanishk Gandhi, Agam Bhatia, and Noah D. Goodman. Learning to simulate human dialogue,
-
[7]
Scaling laws for reward model overoptimization,
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization,
-
[8]
Learning to reason for long-form story generation, 2025
Alexander Gurung and Mirella Lapata. Learning to reason for long-form story generation, 2025. Preprint
work page 2025
-
[9]
RLP: Reinforcement as a pretraining objective, 2025
Ali Hatamizadeh, Syeda Nahida Akter, Shrimai Prabhumoye, Jan Kautz, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, and Yejin Choi. RLP: Reinforcement as a pretraining objective, 2025. Preprint
work page 2025
-
[10]
LLMs gaming verifiers: RLVR can lead to reward hacking, 2026
Lukas Helff, Quentin Delfosse, David Steinmann, Ruben Härle, et al. LLMs gaming verifiers: RLVR can lead to reward hacking, 2026. Preprint
work page 2026
-
[11]
Hu, Moksh Jain, Eric Elmoznino, Younesse Kaddar, Guillaume Lajoie, Yoshua Bengio, and Nikolay Malkin
Edward J. Hu, Moksh Jain, Eric Elmoznino, Younesse Kaddar, Guillaume Lajoie, Yoshua Bengio, and Nikolay Malkin. Amortizing intractable inference in large language models. In International Conference on Learning Representations, 2024. ICLR 2024
work page 2024
-
[12]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Inference-time reward hacking in large language models, 2025
Hadi Khalaf, Claudio Mayrink Verdun, Alex Oesterling, Himabindu Lakkaraju, and Flavio du Pin Calmon. Inference-time reward hacking in large language models, 2025. Preprint
work page 2025
-
[14]
Prometheus: Inducing fine-grained evaluation capability in language models, 2023
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, and Minjoon Seo. Prometheus: Inducing fine-grained evaluation capability in language models, 2023. Preprint
work page 2023
-
[15]
Kimi K2: Open Agentic Intelligence
Kimi Team. Kimi K2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Prover-verifier games improve legibility of LLM outputs, 2024
Jan Hendrik Kirchner, Yining Chen, Harri Edwards, Jan Leike, Nat McAleese, and Yuri Burda. Prover-verifier games improve legibility of LLM outputs, 2024. Preprint. 25
work page 2024
-
[17]
Likelihood- based reward designs for general LLM reasoning, 2026
Ariel Kwiatkowski, Natasha Butt, Ismail Labiad, Julia Kempe, and Yann Ollivier. Likelihood- based reward designs for general LLM reasoning, 2026. Preprint
work page 2026
-
[18]
Reinforcement learning on pre-training data, 2025
Siheng Li, Kejiao Li, Zenan Xu, Guanhua Huang, Evander Yang, Kun Li, Haoyuan Wu, Jiajia Wu, Zihao Zheng, Chenchen Zhang, Kun Shi, Kyrierl Deng, Qi Yi, Ruibin Xiong, Tingqiang Xu, Yuhao Jiang, Jianfeng Yan, Yuyuan Zeng, Guanghui Xu, Jinbao Xue, Zhijiang Xu, Zheng Fang, Shuai Li, Qibin Liu, Xiaoxue Li, Zhuoyu Li, Yangyu Tao, Fei Gao, Cheng Jiang, Bo Chao Wa...
work page 2025
-
[19]
Zi Liang, Liantong Yu, Shiyu Zhang, Qingqing Ye, and Haibo Hu. How much do large language models cheat on evaluation? benchmarking overestimation under the one-time-pad-based framework.arXiv preprint arXiv:2507.19219, 2025
-
[20]
Let’s verify step by step, 2023
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step, 2023. Preprint
work page 2023
-
[21]
G-Eval: NLG evaluation using GPT-4 with better human alignment, 2023
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-Eval: NLG evaluation using GPT-4 with better human alignment, 2023. Preprint
work page 2023
-
[22]
LLMs as narcissistic evaluators: When ego inflates evaluation scores, 2024
Yiqi Liu, Nafise Sadat Moosavi, and Chenghua Lin. LLMs as narcissistic evaluators: When ego inflates evaluation scores, 2024. Preprint
work page 2024
-
[23]
OpenAI. Learning to reason with LLMs. https://openai.com/index/ learning-to-reason-with-llms/, 2024
work page 2024
-
[24]
GPT-5.5 system card.https://openai.com/index/gpt-5-5-system-card/, 2026
OpenAI. GPT-5.5 system card.https://openai.com/index/gpt-5-5-system-card/, 2026
work page 2026
-
[25]
Introducing GPT-5.4 mini and nano
OpenAI. Introducing GPT-5.4 mini and nano. https://openai.com/index/ introducing-gpt-5-4-mini-and-nano/, 2026
work page 2026
-
[26]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The LAMBADA dataset: Word prediction requiring a broad discourse context. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics, pages 1525–1534, 2016
work page 2016
-
[27]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Bradley Knox, Chelsea Finn, and Scott Niekum
Rafael Rafailov, Yaswanth Chittepu, Ryan Park, Harshit Sikchi, Joey Hejna, W. Bradley Knox, Chelsea Finn, and Scott Niekum. Scaling laws for reward model overoptimization in direct alignment algorithms, 2024. Preprint
work page 2024
-
[29]
Nitin Sharma et al. From raw corpora to domain benchmarks: Automated evaluation of LLM domain expertise.arXiv preprint arXiv:2506.07658, 2025
-
[30]
BOW: Bottlenecked next word exploration, 2025
Ming Shen, Zhikun Xu, Xiao Ye, Jacob Dineen, and Ben Zhou. BOW: Bottlenecked next word exploration, 2025. Preprint
work page 2025
-
[31]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024. 26
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
LLM-as-a-judge and reward model: What they can and cannot do, 2024
Guijin Son, Hyunwoo Ko, Hoyoung Lee, Yewon Kim, and Seunghyeok Hong. LLM-as-a-judge and reward model: What they can and cannot do, 2024. Preprint
work page 2024
-
[33]
Yunhao Tang, Sid Wang, Lovish Madaan, and Remi Munos. Beyond verifiable rewards: Scaling reinforcement learning for language models to unverifiable data, 2025. Preprint
work page 2025
-
[34]
Reward under attack: Analyzing the robustness and hackability of process reward models, 2026
Rishabh Tiwari et al. Reward under attack: Analyzing the robustness and hackability of process reward models, 2026. Preprint
work page 2026
-
[35]
LiveBench: A challenging, contamination-limited LLM benchmark
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Benjamin Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Sreemanti Dey, Shubh Agrawal, Sandeep Singh Sandha, Siddartha Venkat Naidu, Chinmay Hegde, Yann LeCun, Tom Goldstein, Willie Neiswanger, and Micah Goldblum. LiveBench: A challenging, contamination-limited LLM benchmark. In...
work page 2025
-
[36]
Xiaobao Wu, Liangming Pan, Yuxi Xie, Ruiwen Zhou, Shuai Zhao, Yubo Ma, Mingzhe Du, Rui Mao, Anh Tuan Luu, and William Yang Wang. AntiLeak-Bench: Preventing data contamination by automatically constructing benchmarks with updated real-world knowledge, 2024. Preprint; ACL 2025 version available
work page 2024
-
[37]
Logic-RL: Unleashing LLM reasoning with rule-based reinforcement learning, 2025
Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, and Chong Luo. Logic-RL: Unleashing LLM reasoning with rule-based reinforcement learning, 2025. Preprint
work page 2025
-
[38]
Benchmarking LLMs’ judgments with no gold standard, 2025
Shengwei Xu, Yuxuan Lu, Grant Schoenebeck, and Yuqing Kong. Benchmarking LLMs’ judgments with no gold standard, 2025. ICLR 2025
work page 2025
-
[39]
DAPO: An open-source LLM reinforcement learning system at scale, 2025
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, et al. DAPO: An open-source LLM reinforcement learning system at scale, 2025. Preprint
work page 2025
-
[40]
RLPR: Extrapolating RLVR to general domains without verifiers, 2025
Tianyu Yu, Bo Ji, Shouli Wang, Shu Yao, Zefan Wang, Ganqu Cui, Lifan Yuan, Ning Ding, Yuan Yao, Zhiyuan Liu, Maosong Sun, and Tat-Seng Chua. RLPR: Extrapolating RLVR to general domains without verifiers, 2025. Preprint
work page 2025
-
[41]
BARTScore: Evaluating generated text as text generation, 2021
Weizhe Yuan, Graham Neubig, and Pengfei Liu. BARTScore: Evaluating generated text as text generation, 2021. Preprint
work page 2021
-
[42]
Eric Zelikman, Georges Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, and Noah D. Goodman. Quiet-STaR: Language models can teach themselves to think before speaking, 2024. Preprint
work page 2024
-
[43]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
work page 2019
-
[44]
Generative verifiers: Reward modeling as next-token prediction, 2024
Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. Generative verifiers: Reward modeling as next-token prediction, 2024. Preprint
work page 2024
-
[45]
One token to fool LLM-as-a-judge, 2025
Yulai Zhao, Haolin Liu, Dian Yu, Sunyuan Kung, Meijia Chen, Haitao Mi, and Dong Yu. One token to fool LLM-as-a-judge, 2025. Preprint
work page 2025
-
[46]
Variation in verification: Understanding verification dynamics in large language models, 2025
Yefan Zhou, Austin Xu, Yilun Zhou, Janvijay Singh, Jiang Gui, and Shafiq Joty. Variation in verification: Understanding verification dynamics in large language models, 2025. Preprint. 27
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.