Recognition: no theorem link
Beyond Red-Teaming: Formal Guarantees of LLM Guardrail Classifiers
Pith reviewed 2026-05-12 04:11 UTC · model grok-4.3
The pith
LLM guardrail classifiers can be formally certified for safety by checking the worst-case point in convex harmful regions of their pre-activation space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
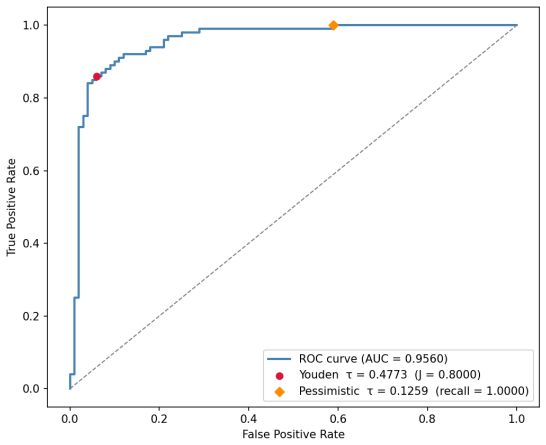
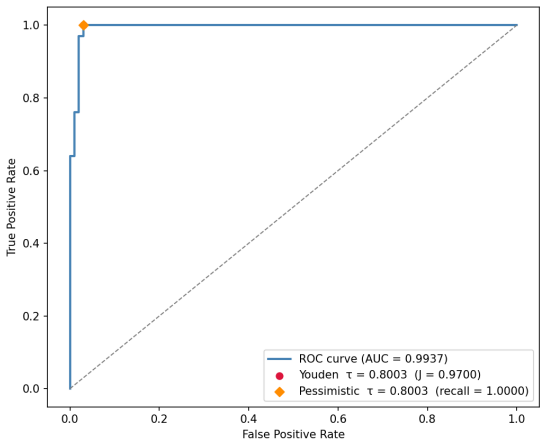
By defining harmful regions as convex shapes around known harmful prompt representations in pre-activation space and exploiting the monotonicity of the sigmoid classification head, the authors obtain a closed-form soundness proof that certifies the safety of an entire region by checking only its worst-case point in O(d) time. SVD-aligned hyper-rectangles produce exact SAT/UNSAT certificates that reveal safety holes in all three tested classifiers, while Gaussian Mixture Model regions produce probabilistic certificates showing that GPT-2 and Llama-3.1-8B maintain 80-90 percent coverage across thresholds whereas BERT's coverage collapses to 55 percent at its optimal threshold.
What carries the argument
The monotonic sigmoid classification head, which reduces the safety certification of any convex harmful region to the verification of a single worst-case point.
If this is right
- Exact SAT/UNSAT certificates become available for any SVD-aligned hyper-rectangular harmful region in linear time.
- Probabilistic coverage certificates from GMMs expose model-specific differences in how stably harm is represented across thresholds.
- High empirical accuracy on held-out test sets does not imply the absence of formally verifiable safety holes.
- Some classifiers require markedly more conservative decision thresholds to reach full coverage of the harmful region.
Where Pith is reading between the lines
- Training pipelines could incorporate these certificates as a regularizer to enforce formal safety properties during optimization.
- The same convex-region technique could be applied to other safety-related binary classifiers in natural language processing.
- Tighter certificates might be obtained by replacing convex enclosures with unions of smaller convex sets that still respect the monotonicity argument.
Load-bearing premise
A convex shape around the pre-activation vectors of known harmful prompts captures the semantic notion of harm that the guardrail must block.
What would settle it
A single harmful prompt whose pre-activation representation lies inside a hyper-rectangle that the method has certified as fully safe would falsify the guarantees.
Figures




read the original abstract
Guardrail Classifiers defend production language models against harmful behavior, but although results seem promising in testing, they provide no formal guarantees. Providing formal guarantees for such models is hard because "harmful behavior" has no natural specification in a discrete input space: and the standard epsilon-ball properties used in other domains do not carry semantic meaning. We close this gap by shifting verification from the discrete input space to the classifier's pre-activation space, where we define a harmful region as a convex shape enclosing the representations of known harmful prompts. Because the sigmoid classification head is monotonic, certifying the worst-case point is sufficient to certify the entire region, yielding a closed-form soundness proof without approximation in O(d) time. To formally evaluate these classifiers, we propose two constructions of such regions: SVD-aligned hyper-rectangles, which yield exact SAT/UNSAT certificates, and Gaussian Mixture Models, which yield probabilistic certificates over semantically coherent clusters. Applying this framework to three author-trained Guardrail Classifiers on the toxicity domain, every hyper-rectangle configuration returns SAT, exposing verifiable safety holes across all classifiers, despite seemingly high empirical metrics. Probabilistic GMM certificates also expose a divergent structural stability in how these models represent harm. While GPT-2 and Llama-3.1-8B maintain robust coverage of 90% and 80% across varying boundaries, BERT's safety guarantees prove uniquely volatile. This 'coverage collapse' to 55% at the optimal threshold reveals a sparsely populated safety margin in BERT, which only achieves full coverage by adopting an extremely conservative pessimistic threshold. These approaches combined, provide new insights on how effective Guardrail Classifiers really are, beyond traditional red-teaming.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes shifting formal verification of LLM guardrail classifiers from discrete input space to the continuous pre-activation embedding space. It defines harmful regions as convex shapes (SVD-aligned hyper-rectangles or GMM clusters) enclosing embeddings of known harmful prompts. Leveraging monotonicity of the sigmoid head, it claims that certifying the worst-case (minimum-logit) point suffices to certify the entire region, yielding an exact closed-form O(d) soundness proof with SAT/UNSAT certificates for hyper-rectangles and probabilistic certificates for GMMs. Evaluation on three author-trained toxicity guardrails finds all hyper-rectangle configurations return SAT (safety holes) despite high empirical accuracy, while GMMs reveal divergent coverage stability (e.g., BERT coverage collapse to 55% at optimal threshold).
Significance. If the convex regions are faithful proxies for semantic harm, the framework supplies a scalable, non-approximate method for certifying guardrail coverage beyond red-teaming and could expose structural weaknesses invisible to empirical testing. The O(d) closed-form claim and exact certificates would be a notable technical contribution for monotonic classifiers; the empirical findings on coverage collapse provide concrete, falsifiable observations about model differences.
major comments (3)
- [Abstract and §3] Abstract and §3 (Formal Verification Framework): The central claim of a 'closed-form soundness proof without approximation in O(d) time' that reduces certification of any convex region to its worst-case point is asserted but supplied with no derivation, proof sketch, or verification details. This is load-bearing for the formal-guarantees contribution; without it the reduction from monotonicity to exact SAT/UNSAT cannot be assessed.
- [§4 and §5] §4 (Region Construction) and §5 (Empirical Evaluation): The harmful region is defined as the convex hull (or GMM) of embeddings of known harmful prompts. Because the embedding map is nonlinear, convex combinations inside this region need not correspond to any valid input text or to semantically harmful content. Consequently, a SAT certificate at an interior point demonstrates a hole only inside the auxiliary geometric object, not necessarily a hole in coverage of actual harmful behavior. This directly affects the interpretation of 'verifiable safety holes' reported for all three classifiers.
- [§5] §5 (Results): The claims that hyper-rectangle configurations 'expose verifiable safety holes across all classifiers' and that GMMs show 'coverage collapse' to 55% for BERT rest on the region definitions above; no error bars, multiple random seeds, or baseline comparisons against standard adversarial or red-teaming metrics are reported, weakening the strength of the empirical conclusions.
minor comments (2)
- [§3] Notation for the pre-activation space and the exact definition of the SVD-aligned hyper-rectangle (e.g., how the axes are chosen and whether the rectangle is axis-aligned in the SVD basis) should be stated explicitly with an equation.
- [§4] The manuscript would benefit from a short discussion of how the chosen toxicity prompts were selected and whether the convex/GMM regions are intended to be exhaustive or merely illustrative.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important aspects of the formal claims, interpretation of the regions, and empirical robustness. Below we respond point-by-point and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Formal Verification Framework): The central claim of a 'closed-form soundness proof without approximation in O(d) time' that reduces certification of any convex region to its worst-case point is asserted but supplied with no derivation, proof sketch, or verification details. This is load-bearing for the formal-guarantees contribution; without it the reduction from monotonicity to exact SAT/UNSAT cannot be assessed.
Authors: We agree that the manuscript does not provide an explicit derivation or proof sketch for the O(d) closed-form reduction. The claim follows directly from the monotonicity of the final sigmoid: for any convex set the minimum logit occurs at an extreme point, which for hyper-rectangles can be evaluated coordinate-wise in linear time. In the revised version we will insert a dedicated subsection in §3 containing (i) the formal statement, (ii) the short proof that monotonicity implies the worst-case point suffices, and (iii) the explicit O(d) algorithm together with the SAT/UNSAT certificate construction. This will make the soundness argument fully verifiable. revision: yes
-
Referee: [§4 and §5] §4 (Region Construction) and §5 (Empirical Evaluation): The harmful region is defined as the convex hull (or GMM) of embeddings of known harmful prompts. Because the embedding map is nonlinear, convex combinations inside this region need not correspond to any valid input text or to semantically harmful content. Consequently, a SAT certificate at an interior point demonstrates a hole only inside the auxiliary geometric object, not necessarily a hole in coverage of actual harmful behavior. This directly affects the interpretation of 'verifiable safety holes' reported for all three classifiers.
Authors: The referee correctly identifies a semantic gap between the geometric region and realizable text. Our framework deliberately certifies coverage relative to the chosen proxy regions rather than claiming universal coverage over all possible harmful text. Because the embedding is continuous, points near the convex hull are close in representation space to known harmful examples; a hole inside the hull therefore indicates that the classifier fails to cover a neighborhood of harmful representations. We will revise §4 and the discussion in §5 to (a) explicitly label the regions as representation-space proxies, (b) add a paragraph on the limitations of the proxy (including the nonlinearity issue), and (c) note that GMM clusters, being fitted to coherent groups, provide a somewhat stronger semantic anchor than pure convex hulls. We do not claim the certificates are sufficient for all possible harmful inputs. revision: partial
-
Referee: [§5] §5 (Results): The claims that hyper-rectangle configurations 'expose verifiable safety holes across all classifiers' and that GMMs show 'coverage collapse' to 55% for BERT rest on the region definitions above; no error bars, multiple random seeds, or baseline comparisons against standard adversarial or red-teaming metrics are reported, weakening the strength of the empirical conclusions.
Authors: We accept that the empirical section would be strengthened by additional statistical controls. In the revision we will (i) rerun the GMM coverage experiments with at least five random seeds and report mean ± std, (ii) add a short comparison table against two standard red-teaming baselines (GCG-style adversarial prompts and a simple synonym-substitution attack), and (iii) include the raw coverage numbers for each threshold so readers can assess sensitivity. These additions will be placed in §5 and the appendix. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation chain rests on the standard mathematical fact that a monotonic sigmoid head reduces region certification to its worst-case pre-activation point, which holds for any fixed convex set and does not depend on how the set is constructed or on fitted parameters from the evaluation data. The harmful regions (SVD hyper-rectangles or GMMs) are defined explicitly from embeddings of known prompts, but the O(d) closed-form check and soundness claim are independent of that construction and do not reduce to it by definition or by self-citation. No load-bearing self-citations, ansatz smuggling, or renaming of known results appear in the abstract or described framework. The empirical findings on author-trained models are separate from the formal argument and do not create circularity in the proof.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math The sigmoid classification head is monotonic
- domain assumption Harmful behavior can be captured by a convex region enclosing known harmful prompt representations in pre-activation space
invented entities (2)
-
SVD-aligned hyper-rectangles
no independent evidence
-
Gaussian Mixture Model harmful clusters
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Author, First and Author, Second , title =. Conference Name , year =
-
[2]
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming , author=. 2025 , eprint=
work page 2025
-
[3]
Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks , author=. 2026 , eprint=
work page 2026
-
[4]
Reluplex: An Efficient SMT Solver for Verifying Deep Neural Networks , author=. 2017 , eprint=
work page 2017
-
[5]
ANTONIO: Towards a Systematic Method of Generating NLP Benchmarks for Verification , author=. 2023 , eprint=
work page 2023
-
[6]
Language Models are Unsupervised Multitask Learners , author=
-
[7]
AEGIS 2.0: A Diverse AI Safety Dataset and Risks Taxonomy for Alignment of LLM Guardrails
Ghosh, Shaona and Varshney, Prasoon and Sreedhar, Makesh Narsimhan and Padmakumar, Aishwarya and Rebedea, Traian and Varghese, Jibin Rajan and Parisien, Christopher. AEGIS 2.0: A Diverse AI Safety Dataset and Risks Taxonomy for Alignment of LLM Guardrails. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Com...
- [8]
-
[9]
ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection , author=. 2022 , eprint=
work page 2022
-
[10]
Safeguarding Large Language Models: A Survey , author=. 2024 , eprint=
work page 2024
-
[11]
Katz, Guy and Huang, Derek A. and Ibeling, Duligur and Julian, Kyle and Lazarus, Christopher and Lim, Rachel and Shah, Parth and Thakoor, Shantanu and Wu, Haoze and Zelji \' c , Aleksandar and Dill, David L. and Kochenderfer, Mykel J. and Barrett, Clark. The Marabou Framework for Verification and Analysis of Deep Neural Networks. Computer Aided Verification. 2019
work page 2019
-
[12]
Advances in Neural Information Processing Systems , volume=
Efficient Neural Network Robustness Certification with General Activation Functions , author=. Advances in Neural Information Processing Systems , volume=. 2018 , url=
work page 2018
-
[13]
Wang, Shiqi and Zhang, Huan and Xu, Kaidi and Lin, Xue and Jana, Suman and Hsieh, Cho-Jui and Kolter, J Zico , journal=
-
[14]
Kaidi Xu and Huan Zhang and Shiqi Wang and Yihan Wang and Suman Jana and Xue Lin and Cho-Jui Hsieh , booktitle=. 2021 , url=
work page 2021
-
[15]
Proceedings of the ACM on Programming Languages , volume =
Singh, Gagandeep and Gehr, Timon and P\". An abstract domain for certifying neural networks , year =. Proc. ACM Program. Lang. , month = jan, articleno =. doi:10.1145/3290354 , abstract =
-
[16]
Certifying Confidence via Randomized Smoothing , author=. 2020 , eprint=
work page 2020
-
[17]
NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails , author=. 2023 , eprint=
work page 2023
-
[18]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations , author=. 2023 , eprint=
work page 2023
-
[19]
Campello, Ricardo J. G. B. and Moulavi, Davoud and Sander, Joerg. Density-Based Clustering Based on Hierarchical Density Estimates. Advances in Knowledge Discovery and Data Mining. 2013
work page 2013
-
[20]
Scalable Verified Training for Provably Robust Image Classification , year=
Gowal, Sven and Dvijotham, Krishnamurthy and Stanforth, Robert and Bunel, Rudy and Qin, Chongli and Uesato, Jonathan and Arandjelovic, Relja and Mann, Timothy Arthur and Kohli, Pushmeet , booktitle=. Scalable Verified Training for Provably Robust Image Classification , year=
-
[21]
SoK: Certified Robustness for Deep Neural Networks , author=. 2023 , eprint=
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.