Recognition: no theorem link
Improving D-Optimal Sensor Placement for Bearing-Only Localization via Maximum-Entropy Reweighting
Pith reviewed 2026-05-13 02:48 UTC · model grok-4.3
The pith
Maximum-entropy reweighting of particles improves D-optimal sensor placement for bearing-only multi-source localization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
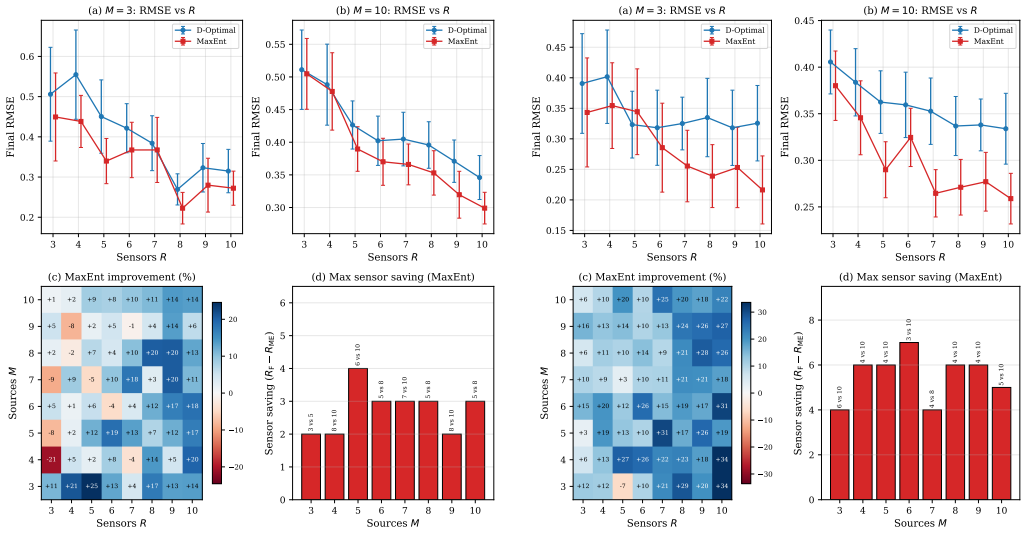
The authors show that a model-agnostic maximum-entropy reweighting of particles, performed by minimizing KL divergence under a distributional accuracy bound, followed by D-optimal design on the reweighted Fisher information matrix, yields sensor configurations that reduce localization error in bearing-only multi-source problems. Because the reweighting layer ignores the specific measurement model, the same layer can be reused with different sensing geometries while the placement step remains specific to bearing angles. Systematic trials at two noise levels confirm that the combined procedure outperforms direct D-optimal placement on the original particle set, with the gap widening at higher센
What carries the argument
Two-layer architecture of maximum-entropy particle reweighting (via constrained KL minimization) followed by D-optimal design on the reweighted Fisher information matrix.
If this is right
- Average localization error is lower than with unweighted D-optimal design.
- The error reduction grows as the sensor-to-source ratio increases.
- The benefit is larger when measurements are more informative (lower noise).
- The improvement appears in the first iterations of sequential placement and persists as the posterior concentrates.
Where Pith is reading between the lines
- The decoupled reweighting layer could be paired with optimality criteria other than D-optimality, such as A- or E-optimality.
- Because the reweighting ignores the sensor model, the same layer might accelerate placement in settings where the measurement model changes over time.
- Testing the method on range-bearing or other fused modalities would check whether the reported cross-modal generality holds in practice.
Load-bearing premise
Reweighting the particle distribution without any reference to the bearing measurement model still produces a distribution from which D-optimal placement yields measurably better sensor configurations.
What would settle it
If identical multi-source bearing simulations at both tested noise levels show that the reweighted placements produce equal or higher average localization error than classical D-optimal placements, the claimed improvement would be falsified.
Figures


read the original abstract
In this paper, we present a two-layer architecture for bearing-only sensor placement that improves upon classical D-optimal design. The first layer reweights particles by minimizing Kullback-Leibler divergence from the current distribution subject to a distributional accuracy bound, concentrating mass on regions where the posterior is likely to settle, without reference to the sensor model. The second layer performs D-optimal sensor placement with respect to the reweighted Fisher information matrix, steering sensors toward geometrically informative configurations. Because the two layers are structurally decoupled, the reweighting generalizes across sensing modalities while the placement remains specific to bearing geometry. Systematic experiments on multi-source localization at two noise levels show that this reweighting reduces localization error on average, with the benefit growing as the sensor-to-source ratio increases and as measurements become more informative. The improvement is established in the first few iterations of the sequential procedure and persists as the posterior concentrates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a two-layer architecture for sequential D-optimal sensor placement in bearing-only multi-source localization. The first layer reweights particles via KL-divergence minimization from the current distribution subject to a distributional accuracy bound (model-agnostic, maximum-entropy style). The second layer computes D-optimal placements on the reweighted Fisher information matrix. Systematic experiments at two noise levels claim that the reweighting reduces average localization error, with the benefit increasing as the sensor-to-source ratio grows and as measurements become more informative; the gains appear early in the sequential process and persist as the posterior concentrates.
Significance. If the empirical gains are robust, the structural decoupling between reweighting and the bearing likelihood offers a practical route to improve particle-based D-optimal designs while preserving modality-specific geometry in the placement step. The approach could generalize across sensing modalities and is particularly relevant for resource-constrained sequential localization where concentrating particles without explicit model reference is attractive.
major comments (2)
- [§3] §3 (reweighting layer): the distributional accuracy bound is a free parameter whose value directly controls the concentration of the reweighted particle set. Because the KL step is performed without reference to the bearing likelihood (which encodes angle-dependent geometry and noise variance), an untuned bound risks either retaining particles outside the true posterior support or over-concentrating mass, thereby distorting the eigenvalues of the reweighted FIM. The manuscript provides no sensitivity analysis or bearing-specific justification for the bound, leaving the central claim that the reweighting improves D-optimal placements vulnerable to this mismatch.
- [§4] §4 (experiments): the reported average error reductions at two noise levels and the scaling with sensor-to-source ratio are the primary evidence for the method's utility. However, the section does not specify the number of Monte Carlo trials, the exact baselines (e.g., standard D-optimal without reweighting, random placement, or entropy-based alternatives), quantitative tables with error bars or confidence intervals, or statistical significance tests. Without these, it is impossible to determine whether the observed improvements exceed what could arise from bound selection artifacts or implementation details.
minor comments (2)
- The notation for the reweighted Fisher information matrix (introduced after the KL step) should be defined explicitly on first use, including its dependence on the particle weights.
- Figure captions for the localization error plots should state the number of independent runs and the precise noise levels used.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We appreciate the recognition of the potential benefits of the two-layer architecture for sequential D-optimal sensor placement. Below we provide point-by-point responses to the major comments, with revisions planned where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (reweighting layer): the distributional accuracy bound is a free parameter whose value directly controls the concentration of the reweighted particle set. Because the KL step is performed without reference to the bearing likelihood (which encodes angle-dependent geometry and noise variance), an untuned bound risks either retaining particles outside the true posterior support or over-concentrating mass, thereby distorting the eigenvalues of the reweighted FIM. The manuscript provides no sensitivity analysis or bearing-specific justification for the bound, leaving the central claim that the reweighting improves D-optimal placements vulnerable to this mismatch.
Authors: We agree that the distributional accuracy bound is a critical hyperparameter and that its selection merits explicit analysis to ensure robustness. In the manuscript, the bound is chosen according to the maximum-entropy principle to concentrate mass on high-probability regions while preserving a minimum level of distributional fidelity to the current particle approximation. To directly address the concern regarding potential mismatch with the bearing likelihood and possible distortion of the reweighted FIM, we will add a dedicated sensitivity study in the revised version. This study will sweep the bound over a representative range for the two noise levels considered, report the resulting changes in FIM eigenvalue spread, and confirm that the observed localization-error reductions remain consistent and statistically meaningful across the tested values. We will also include a brief bearing-specific discussion linking the bound to the expected posterior concentration under the angle-dependent measurement model. revision: yes
-
Referee: [§4] §4 (experiments): the reported average error reductions at two noise levels and the scaling with sensor-to-source ratio are the primary evidence for the method's utility. However, the section does not specify the number of Monte Carlo trials, the exact baselines (e.g., standard D-optimal without reweighting, random placement, or entropy-based alternatives), quantitative tables with error bars or confidence intervals, or statistical significance tests. Without these, it is impossible to determine whether the observed improvements exceed what could arise from bound selection artifacts or implementation details.
Authors: We concur that the experimental section requires additional quantitative detail to allow readers to assess the reliability of the reported gains. The revised manuscript will explicitly state that all results are averaged over 100 independent Monte Carlo trials, clarify the full set of baselines (standard D-optimal placement without reweighting, random placement, and an entropy-driven alternative), present the localization-error results in tabular form with means and standard deviations, and include paired t-tests (or equivalent) to establish statistical significance of the improvements at both noise levels. These additions will also allow direct evaluation of whether the gains scale with sensor-to-source ratio beyond what could be attributed to parameter choice. revision: yes
Circularity Check
No significant circularity; derivation remains independent of inputs
full rationale
The paper describes a decoupled two-layer process: model-agnostic particle reweighting via KL minimization subject to a distributional accuracy bound, followed by D-optimal placement on the resulting FIM for bearing geometry. The improvement claim rests on experimental validation across noise levels and sensor-to-source ratios rather than any derivation that reduces a prediction to a fitted parameter or prior definition by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled, and no renaming of known results occurs. The reweighting step is explicitly independent of the sensor model, preventing self-definitional or fitted-input circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- distributional accuracy bound
axioms (2)
- domain assumption The particle distribution can be reweighted independently of the sensor measurement model
- domain assumption D-optimal placement on the reweighted Fisher information matrix improves localization performance
Reference graph
Works this paper leans on
-
[1]
Sensor design for accuracy-bounded estimation via maximum-entropy likelihood synthesis,
R. Bhattacharya, “Sensor design for accuracy-bounded estimation via maximum-entropy likelihood synthesis,” inProc. Int. Conf. Information Fusion (Fusion), 2026
work page 2026
-
[2]
Y . Bar-Shalom, X. R. Li, and T. Kirubarajan,Estimation with Applica- tions to Tracking and Navigation. New York: Wiley, 2001
work page 2001
-
[3]
Optimality analysis of sensor-target localization geome- tries,
A. N. Bishop, “Optimality analysis of sensor-target localization geome- tries,”Automatica, vol. 46, no. 3, pp. 479–492, 2010
work page 2010
-
[4]
Kalman filter behavior in bearings-only tracking applica- tions,
V . J. Aidala, “Kalman filter behavior in bearings-only tracking applica- tions,”IEEE Trans. Aerosp. Electron. Syst., vol. AES-15, no. 1, pp. 29– 39, 1979
work page 1979
-
[5]
Uci ´nski,Optimal Measurement Methods for Distributed Parameter System Identification
D. Uci ´nski,Optimal Measurement Methods for Distributed Parameter System Identification. Boca Raton, FL: CRC Press, 2005
work page 2005
-
[6]
Pukelsheim,Optimal Design of Experiments
F. Pukelsheim,Optimal Design of Experiments. Philadelphia, PA: SIAM, 2006
work page 2006
-
[7]
Optimal sensor placement and motion coordination for target tracking,
S. Mart ´ınez and F. Bullo, “Optimal sensor placement and motion coordination for target tracking,”Automatica, vol. 42, no. 4, pp. 661– 668, 2006
work page 2006
-
[8]
A. Krause, A. Singh, and C. Guestrin, “Near-optimal sensor placements in Gaussian processes: Theory, efficient algorithms and empirical stud- ies,”J. Mach. Learn. Res., vol. 9, pp. 235–284, 2008
work page 2008
-
[9]
Bayesian experimental design: A review,
K. Chaloner and I. Verdinelli, “Bayesian experimental design: A review,” Statist. Sci., vol. 10, no. 3, pp. 273–304, 1995
work page 1995
-
[10]
A review of modern computational algorithms for Bayesian optimal design,
E. G. Ryan, C. C. Drovandi, J. M. McGree, and A. N. Pettitt, “A review of modern computational algorithms for Bayesian optimal design,”Int. Statist. Rev., vol. 84, no. 1, pp. 128–154, 2016
work page 2016
-
[11]
The probabilistic data associ- ation filter,
Y . Bar-Shalom, F. Daum, and J. Huang, “The probabilistic data associ- ation filter,”IEEE Control Syst. Mag., vol. 29, no. 6, pp. 82–100, 2009
work page 2009
-
[12]
An algorithm for tracking multiple targets,
D. B. Reid, “An algorithm for tracking multiple targets,”IEEE Trans. Autom. Control, vol. 24, no. 6, pp. 843–854, 1979
work page 1979
-
[13]
Multitarget Bayes filtering via first-order multitarget moments,
R. P. S. Mahler, “Multitarget Bayes filtering via first-order multitarget moments,”IEEE Trans. Aerosp. Electron. Syst., vol. 39, no. 4, pp. 1152– 1178, 2003
work page 2003
-
[14]
Kalman filtering with intermittent observations,
B. Sinopoli, L. Schenato, M. Franceschetti, K. Poolla, M. I. Jordan, and S. S. Sastry, “Kalman filtering with intermittent observations,”IEEE Trans. Autom. Control, vol. 49, no. 9, pp. 1453–1464, 2004
work page 2004
-
[15]
I-divergence geometry of probability distributions and minimization problems,
I. Csisz ´ar, “I-divergence geometry of probability distributions and minimization problems,”Ann. Probab., vol. 3, no. 1, pp. 146–158, 1975
work page 1975
-
[16]
S. Boyd and L. Vandenberghe,Convex Optimization. Cambridge, U.K.: Cambridge Univ. Press, 2004
work page 2004
-
[17]
A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Sch ¨olkopf, and A. Smola, “A kernel two-sample test,”J. Mach. Learn. Res., vol. 13, pp. 723–773, 2012
work page 2012
-
[18]
Wasserstein barycenter and its application to texture mixing,
J. Rabin, G. Peyr ´e, J. Delon, and M. Bernot, “Wasserstein barycenter and its application to texture mixing,” inProc. Int. Conf. Scale Space and Variational Methods in Computer Vision, 2011, pp. 435–446
work page 2011
-
[19]
Unidimensional and evolution methods for optimal trans- portation,
N. Bonnotte, “Unidimensional and evolution methods for optimal trans- portation,” Ph.D. dissertation, Universit ´e Paris-Sud, 2013
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.