Recognition: 2 theorem links
· Lean TheoremLanguage Modeling with Hyperspherical Flows
Pith reviewed 2026-05-13 06:49 UTC · model grok-4.3
The pith
S-FLM rotates vectors on the hypersphere to let continuous flow language models approach masked diffusion on reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
S-FLM generates sequences by rotating vectors in S^{d-1} along a velocity field learned with cross-entropy, avoiding the overhead of materializing one-hot vectors. This substantially improves continuous flow language models on large-vocabulary reasoning and closes the gap to masked diffusion under standard-temperature sampling (T=1), while a gap remains under optimized low-temperature (T=0.1) decoding.
What carries the argument
The hyperspherical flow that rotates points on the unit sphere S^{d-1} according to a learned velocity field to transport noise to data.
If this is right
- Continuous flow language models become practical for large vocabularies without materializing one-hot vectors.
- Flow models reach performance comparable to masked diffusion on reasoning tasks when sampling at temperature 1.
- High-likelihood samples become more reliable in verifiable domains such as math and code.
- A performance gap to diffusion persists under low-temperature decoding and requires separate optimization.
Where Pith is reading between the lines
- The sphere may better encode semantic similarities than Euclidean one-hot spaces for discrete sequences.
- Similar manifold flows could be tested on other discrete structures such as graphs or molecules.
- Hybrid models that combine hyperspherical flows with short autoregressive segments might close the remaining low-temperature gap.
Load-bearing premise
Rotating vectors on the hypersphere supplies a semantically meaningful transport from noise to structured language data.
What would settle it
If S-FLM shows no improvement over prior flow language models on math or code reasoning benchmarks, or if the gap to masked diffusion fails to close at temperature 1, the benefit of the hyperspherical representation would be refuted.
Figures




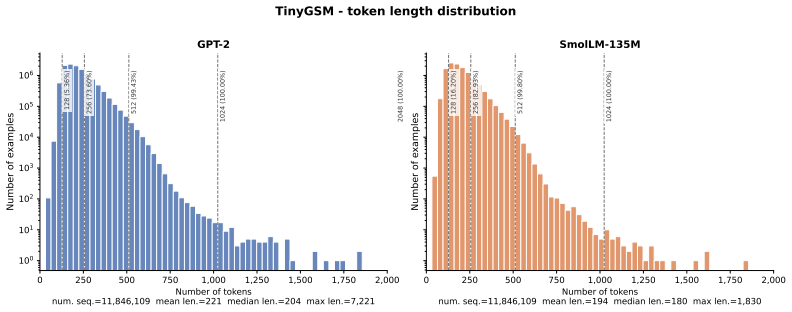

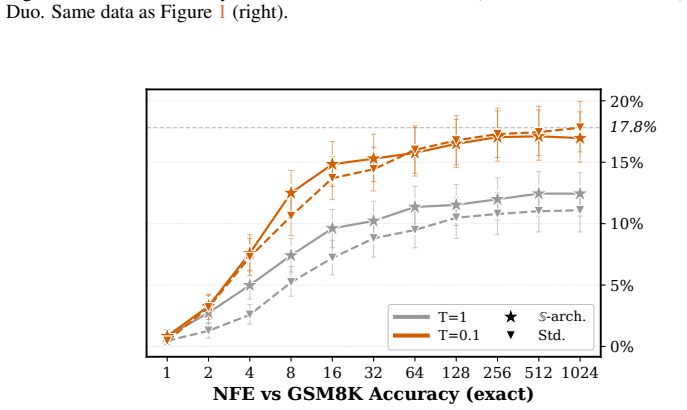



read the original abstract
Discrete Diffusion Language Models progressed rapidly as an alternative to autoregressive (AR) models, motivated by their parallel generation abilities. However, for tractability, discrete diffusion models sample from a factorized distribution, which is less expressive than AR. Recent Flow Language Models (FLMs) apply continuous flows to language, transporting noise to data with a deterministic ODE that avoids factorized sampling. FLMs operate on one-hot vectors whose dimension scales with the vocabulary size, making FLMs costly to train. Moreover, since all distinct one-hot embeddings are equidistant in $\ell_2$, adding Gaussian noise does not have a clear semantic interpretation (unlike images, where Gaussian noise progressively degrades structure). We introduce $\mathbb{S}$-FLM, a latent FLM in the hypersphere. $\mathbb{S}$-FLM generates sequences by rotating vectors in $\mathbb{S}^{d-1}$ along a velocity field learned with cross-entropy, avoiding the overhead of materializing one-hot vectors. Previous FLMs match AR in Generative Perplexity (Gen.\ PPL), but samples with high likelihood are not necessarily correct in verifiable domains such as math and code. $\mathbb{S}$-FLM substantially improves continuous flow language models on large-vocabulary reasoning and closes the gap to masked diffusion under standard-temperature sampling ($T=1$), while a gap remains under optimized low-temperature ($T=0.1$) decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces S-FLM, a latent continuous flow language model that transports noise to data by rotating vectors on the hypersphere S^{d-1} via a learned velocity field trained with cross-entropy loss. This avoids the vocabulary-sized one-hot embeddings of prior FLMs, whose equidistant l2 geometry lacks semantic interpretation under Gaussian noise. The central claim is that S-FLM substantially improves continuous flow models on large-vocabulary reasoning tasks and closes the performance gap to masked diffusion under standard-temperature (T=1) sampling, though a gap persists at optimized low temperature (T=0.1).
Significance. If the hyperspherical construction yields semantically meaningful transport (as opposed to gains from reduced dimensionality or optimization differences alone), the work would strengthen the case for continuous flows as a non-factorized alternative to discrete diffusion for language, particularly in verifiable domains like math and code. The parameter efficiency from operating in fixed latent dimension d rather than |V| is a clear practical advantage over prior FLMs.
major comments (2)
- [Abstract] Abstract: The performance claim that S-FLM 'substantially improves' reasoning and 'closes the gap' to masked diffusion at T=1 is presented without reference to experimental details such as exact baselines, number of runs, statistical tests, or ablations isolating the hyperspherical geometry from other factors like latent dimension or training procedure. This leaves the central empirical result only moderately supported.
- [Abstract and implied experiments] Method/Experiments (implied by abstract claims): No verification is provided that the learned velocity field exploits sphere geometry for semantic transport, e.g., via cosine-similarity analysis of ODE trajectories, nearest-token interpolation between noise and data, or ablation comparing hyperspherical vs. Euclidean latent flows. Without such evidence, the attribution of gains to 'semantically meaningful' rotation (contrasted with equidistant one-hots) cannot be distinguished from alternative explanations such as lower parameter count.
minor comments (2)
- [Abstract] Notation: The abstract refers to 'standard-temperature sampling (T=1)' and 'optimized low-temperature (T=0.1) decoding' without defining how temperature is applied to the flow ODE or velocity field; a brief clarification in the method section would aid reproducibility.
- [Abstract] Clarity: The abstract states that previous FLMs 'match AR in Generative Perplexity' but then pivots to reasoning tasks; a short sentence distinguishing Gen. PPL from verifiable correctness metrics would better motivate the focus on math/code domains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below and have revised the manuscript to strengthen the presentation of experimental details and supporting analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance claim that S-FLM 'substantially improves' reasoning and 'closes the gap' to masked diffusion at T=1 is presented without reference to experimental details such as exact baselines, number of runs, statistical tests, or ablations isolating the hyperspherical geometry from other factors like latent dimension or training procedure. This leaves the central empirical result only moderately supported.
Authors: We agree that the abstract would benefit from explicit references to the supporting experimental details. In the revised manuscript we have updated the abstract to include parenthetical citations to Section 4 (which reports results over multiple independent runs with standard deviations) and the relevant tables detailing baselines, ablations on latent dimension, and training procedure. We have also added a brief statement on the statistical tests used to assess significance of the reported improvements. These changes make the central claims more clearly grounded without altering the underlying results. revision: yes
-
Referee: [Abstract and implied experiments] Method/Experiments (implied by abstract claims): No verification is provided that the learned velocity field exploits sphere geometry for semantic transport, e.g., via cosine-similarity analysis of ODE trajectories, nearest-token interpolation between noise and data, or ablation comparing hyperspherical vs. Euclidean latent flows. Without such evidence, the attribution of gains to 'semantically meaningful' rotation (contrasted with equidistant one-hots) cannot be distinguished from alternative explanations such as lower parameter count.
Authors: We acknowledge that the original submission did not include direct analyses verifying semantic transport along the flow. In the revised manuscript we have added a new subsection with cosine-similarity measurements of ODE trajectories and nearest-token interpolation examples between noise and data points. We have also included an ablation comparing the hyperspherical model against a Euclidean latent flow baseline with matched parameter count. These additions help isolate the contribution of the spherical geometry from dimensionality or optimization effects alone. revision: yes
Circularity Check
No significant circularity in S-FLM derivation chain
full rationale
The paper defines S-FLM as a hyperspherical latent flow where a velocity field is trained via standard cross-entropy to rotate unit vectors on S^{d-1} from noise to data embeddings. Performance claims (improved Gen. PPL and reasoning at T=1) are measured on held-out benchmarks and compared to baselines; these are not equivalent to the training objective or any fitted parameter by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the abstract or description. The semantic-transport assumption is stated but treated as an empirical hypothesis rather than a definitional reduction. The derivation remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- latent dimension d
axioms (1)
- domain assumption Rotation of vectors on the hypersphere provides a meaningful semantic degradation path analogous to Gaussian noise on images
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
We introduce S-FLM, a latent FLM in the hypersphere. S-FLM generates sequences by rotating vectors in S^{d-1} along a velocity field learned with cross-entropy... SLERP(z0, z1, αt)
-
IndisputableMonolith/Foundation/AlexanderDualityProof.leanlinking_dimension echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
The geodesic distance between p,q ∈ S^{d-1} is the angle dS(p,q) = arccos(p⊤q)... exponential map expp(v) = cos(∥v∥)p + sin(∥v∥) v/∥v∥
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Albergo and Eric Vanden-Eijnden
Michael S. Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants, 2023
work page 2023
-
[2]
Smollm2: When smol goes big – data-centric training of a small language model, 2025
Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martín Blázquez, Guilherme Penedo, Lewis Tunstall, Andrés Marafioti, Hynek Kydlíˇcek, Agustín Piqueres Lajarín, Vaibhav Srivastav, Joshua Lochner, Caleb Fahlgren, Xuan-Son Nguyen, Clémentine Fourrier, Ben Burtenshaw, Hugo Larcher, Haojun Zhao, Cyril Zakka, Mathieu Morlon, Colin Raffel, Leandro von Wer...
work page 2025
-
[3]
Ali Alp. Sudoku puzzle generator. https://github.com/alicommit-malp/sudoku, 2024
work page 2024
-
[4]
Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov
Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models, 2025
work page 2025
-
[5]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces, 2023
work page 2023
-
[6]
Princeton University Press, Princeton, NJ, 1961
Richard Bellman.Adaptive Control Processes: A Guided Tour. Princeton University Press, Princeton, NJ, 1961
work page 1961
-
[7]
Accelerated sampling from masked diffusion models via entropy bounded unmasking, 2025
Heli Ben-Hamu, Itai Gat, Daniel Severo, Niklas Nolte, and Brian Karrer. Accelerated sampling from masked diffusion models via entropy bounded unmasking, 2025
work page 2025
-
[8]
Riemannian score-based generative modelling, 2022
Valentin De Bortoli, Emile Mathieu, Michael Hutchinson, James Thornton, Yee Whye Teh, and Arnaud Doucet. Riemannian score-based generative modelling, 2022
work page 2022
-
[9]
A continuous time framework for discrete denoising models, 2022
Andrew Campbell, Joe Benton, Valentin De Bortoli, Tom Rainforth, George Deligiannidis, and Arnaud Doucet. A continuous time framework for discrete denoising models, 2022. 10
work page 2022
-
[10]
Andrew Campbell, Jason Yim, Regina Barzilay, Tom Rainforth, and Tommi Jaakkola. Gener- ative flows on discrete state-spaces: Enabling multimodal flows with applications to protein co-design, 2024
work page 2024
-
[11]
Ricky T. Q. Chen and Yaron Lipman. Flow matching on general geometries, 2024
work page 2024
-
[12]
https://arxiv.org/abs/1806.07366
Tian Qi Chen, Yulia Rubanova, Jesse Bettencourt, and David Kristjanson Duvenaud. Neural ordinary differential equations.NeurIPS 2018, abs/1806.07366, 2018
-
[13]
Analog bits: Generating discrete data using diffusion models with self-conditioning, 2022
Ting Chen, Ruixiang Zhang, and Geoffrey Hinton. Analog bits: Generating discrete data using diffusion models with self-conditioning, 2022
work page 2022
-
[14]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021
work page 2021
-
[15]
Coddington and Norman Levinson.Theory of Ordinary Differential Equations
Earl A. Coddington and Norman Levinson.Theory of Ordinary Differential Equations. McGraw- Hill, New York, 1955
work page 1955
-
[16]
Davidson, Luca Falorsi, Nicola De Cao, Thomas Kipf, and Jakub M
Tim R. Davidson, Luca Falorsi, Nicola De Cao, Thomas Kipf, and Jakub M. Tomczak. Hyper- spherical variational auto-encoders, 2018
work page 2018
-
[17]
Fisher flow matching for generative modeling over discrete data, 2024
Oscar Davis, Samuel Kessler, Mircea Petrache, ˙Ismail ˙Ilkan Ceylan, Michael Bronstein, and Avishek Joey Bose. Fisher flow matching for generative modeling over discrete data, 2024
work page 2024
-
[18]
Promises, outlooks and challenges of diffusion language modeling, 2024
Justin Deschenaux and Caglar Gulcehre. Promises, outlooks and challenges of diffusion language modeling, 2024
work page 2024
-
[19]
The diffusion duality, chapter ii:ψ-samplers and efficient curriculum, 2026
Justin Deschenaux, Caglar Gulcehre, and Subham Sekhar Sahoo. The diffusion duality, chapter ii:ψ-samplers and efficient curriculum, 2026
work page 2026
-
[20]
Partition generative modeling: Masked modeling without masks, 2025
Justin Deschenaux, Lan Tran, and Caglar Gulcehre. Partition generative modeling: Masked modeling without masks, 2025
work page 2025
-
[21]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021
work page 2021
-
[22]
Sander Dieleman, Laurent Sartran, Arman Roshannai, Nikolay Savinov, Yaroslav Ganin, Pierre H. Richemond, Arnaud Doucet, Robin Strudel, Chris Dyer, Conor Durkan, Curtis Hawthorne, Rémi Leblond, Will Grathwohl, and Jonas Adler. Continuous diffusion for categor- ical data, 2022
work page 2022
-
[23]
Mathematics: Theory & Applications
Manfredo Perdigão do Carmo.Riemannian Geometry. Mathematics: Theory & Applications. Birkhäuser Boston, 1992
work page 1992
-
[24]
Bootstrap methods: Another look at the jackknife.The Annals of Statistics, 7(1):1–26, 1979
Bradley Efron. Bootstrap methods: Another look at the jackknife.The Annals of Statistics, 7(1):1–26, 1979
work page 1979
-
[25]
Variational flow matching for graph generation, 2025
Floor Eijkelboom, Grigory Bartosh, Christian Andersson Naesseth, Max Welling, and Jan- Willem van de Meent. Variational flow matching for graph generation, 2025
work page 2025
-
[26]
Theoretical benefit and limitation of diffusion language model, 2025
Guhao Feng, Yihan Geng, Jian Guan, Wei Wu, Liwei Wang, and Di He. Theoretical benefit and limitation of diffusion language model, 2025
work page 2025
-
[27]
F. N. Fritsch and J. Butland. A method for constructing local monotone piecewise cubic interpolants.SIAM Journal on Scientific and Statistical Computing, 5(2):300–304, 1984
work page 1984
-
[28]
Itai Gat, Tal Remez, Neta Shaul, Felix Kreuk, Ricky T. Q. Chen, Gabriel Synnaeve, Yossi Adi, and Yaron Lipman. Discrete flow matching, 2024
work page 2024
-
[29]
Gemini: A family of highly capable multimodal models, 2025
Gemini Team, Rohan Anil, Sebastian Borgeaud, et al. Gemini: A family of highly capable multimodal models, 2025
work page 2025
-
[30]
Aaron Gokaslan and Vanya Cohen. Openwebtext corpus. http://Skylion007.github.io/ OpenWebTextCorpus, 2019. 11
work page 2019
- [31]
-
[32]
Will Grathwohl, Ricky T. Q. Chen, Jesse Bettencourt, Ilya Sutskever, and David Duvenaud. Ffjord: Free-form continuous dynamics for scalable reversible generative models, 2018
work page 2018
- [33]
-
[34]
Xiaochuang Han, Sachin Kumar, and Yulia Tsvetkov. Ssd-lm: Semi-autoregressive simplex- based diffusion language model for text generation and modular control, 2023
work page 2023
-
[35]
Denoising diffusion probabilistic models, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models, 2020
work page 2020
-
[36]
Classifier-free diffusion guidance, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance, 2022
work page 2022
-
[37]
Continuous diffusion model for language modeling, 2025
Jaehyeong Jo and Sung Ju Hwang. Continuous diffusion model for language modeling, 2025
work page 2025
-
[38]
Loopholing discrete diffusion: Deterministic bypass of the sampling wall, 2025
Mingyu Jo, Jaesik Yoon, Justin Deschenaux, Caglar Gulcehre, and Sungjin Ahn. Loopholing discrete diffusion: Deterministic bypass of the sampling wall, 2025
work page 2025
-
[39]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020
work page 2020
-
[40]
Dense passage retrieval for open-domain question answering, 2020
Vladimir Karpukhin, Barlas O ˘guz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen tau Yih. Dense passage retrieval for open-domain question answering, 2020
work page 2020
-
[41]
Analyzing and improving the training dynamics of diffusion models, 2024
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models, 2024
work page 2024
-
[42]
Pan, Hyeji Kim, Sham Kakade, and Sitan Chen
Jaeyeon Kim, Seunggeun Kim, Taekyun Lee, David Z. Pan, Hyeji Kim, Sham Kakade, and Sitan Chen. Fine-tuning masked diffusion for provable self-correction, 2025
work page 2025
-
[43]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017
work page 2017
-
[44]
The factorization curse: Which tokens you predict underlie the reversal curse and more, 2024
Ouail Kitouni, Niklas Nolte, Diane Bouchacourt, Adina Williams, Mike Rabbat, and Mark Ibrahim. The factorization curse: Which tokens you predict underlie the reversal curse and more, 2024
work page 2024
-
[45]
Chanhyuk Lee, Jaehoon Yoo, Manan Agarwal, Sheel Shah, Jerry Huang, Aditi Raghunathan, Seunghoon Hong, Nicholas M. Boffi, and Jinwoo Kim. One-step language modeling via continuous denoising, 2026
work page 2026
- [46]
-
[47]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling, 2023
work page 2023
-
[48]
TinyGSM: Achieving >80% on GSM8k with small language models, 2023
Bingbin Liu, Sebastien Bubeck, Ronen Eldan, Janardhan Kulkarni, Yuanzhi Li, Anh Nguyen, Rachel Ward, and Yi Zhang. TinyGSM: Achieving >80% on GSM8k with small language models, 2023
work page 2023
-
[49]
Flow straight and fast: Learning to generate and transfer data with rectified flow, 2022
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow, 2022
work page 2022
-
[50]
ngpt: Normalized transformer with representation learning on the hypersphere, 2024
Ilya Loshchilov, Cheng-Ping Hsieh, Simeng Sun, and Boris Ginsburg. ngpt: Normalized transformer with representation learning on the hypersphere, 2024
work page 2024
-
[51]
Neural manifold ordinary differential equations, 2020
Aaron Lou, Derek Lim, Isay Katsman, Leo Huang, Qingxuan Jiang, Ser-Nam Lim, and Christopher De Sa. Neural manifold ordinary differential equations, 2020
work page 2020
-
[52]
Discrete diffusion modeling by estimating the ratios of the data distribution, 2024
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution, 2024. 12
work page 2024
-
[53]
Scaling riemannian diffusion models, 2023
Aaron Lou, Minkai Xu, and Stefano Ermon. Scaling riemannian diffusion models, 2023
work page 2023
-
[54]
Justin Lovelace, Varsha Kishore, Chao Wan, Eliot Shekhtman, and Kilian Q. Weinberger. Latent diffusion for language generation, 2022
work page 2022
-
[55]
Rabeeh Karimi Mahabadi, Hamish Ivison, Jaesung Tae, James Henderson, Iz Beltagy, Matthew E. Peters, and Arman Cohan. TESS: Text-to-text self-conditioned simplex diffu- sion, 2023
work page 2023
-
[56]
Riemannian continuous normalizing flows, 2020
Emile Mathieu and Maximilian Nickel. Riemannian continuous normalizing flows, 2020
work page 2020
- [57]
-
[58]
Efficient estimation of word representations in vector space, 2013
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space, 2013
work page 2013
-
[59]
Mervin E. Muller. A note on a method for generating points uniformly on n-dimensional spheres. Communications of the ACM, 2(4):19–20, 1959
work page 1959
-
[60]
Vaishnavh Nagarajan, Chen Henry Wu, Charles Ding, and Aditi Raghunathan. Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction.arXiv preprint arXiv:2504.15266, 2025
-
[61]
Scaling up masked diffusion models on text, 2025
Shen Nie, Fengqi Zhu, Chao Du, Tianyu Pang, Qian Liu, Guangtao Zeng, Min Lin, and Chongxuan Li. Scaling up masked diffusion models on text, 2025
work page 2025
-
[62]
Hunter Nisonoff, Junhao Xiong, Stephan Allenspach, and Jennifer Listgarten. Unlocking guidance for discrete state-space diffusion and flow models.arXiv preprint arXiv:2406.01572, 2024
- [63]
-
[64]
Gpt-oss: open-weight language models by openai
OpenAI. Gpt-oss: open-weight language models by openai. https://github.com/openai/ gpt-oss, 2024. GitHub repository
work page 2024
-
[65]
Arrows of time for large language models, 2024
Vassilis Papadopoulos, Jérémie Wenger, and Clément Hongler. Arrows of time for large language models, 2024
work page 2024
-
[66]
Scalable diffusion models with transformers, 2023
William Peebles and Saining Xie. Scalable diffusion models with transformers, 2023
work page 2023
-
[67]
GloVe: Global vectors for word representation
Jeffrey Pennington, Richard Socher, and Christopher Manning. GloVe: Global vectors for word representation. InProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543. Association for Computational Linguistics, 2014
work page 2014
-
[68]
Peter Potaptchik, Jason Yim, Adhi Saravanan, Peter Holderrieth, Eric Vanden-Eijnden, and Michael S. Albergo. Discrete flow maps, 2026
work page 2026
-
[69]
Candi: Hybrid discrete-continuous diffusion models, 2025
Patrick Pynadath, Jiaxin Shi, and Ruqi Zhang. Candi: Hybrid discrete-continuous diffusion models, 2025
work page 2025
- [70]
-
[71]
Language models are unsupervised multitask learners, 2019
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners, 2019
work page 2019
-
[72]
Creating confidence intervals for machine learning classifiers
Sebastian Raschka. Creating confidence intervals for machine learning classifiers. https:// sebastianraschka.com/blog/2022/confidence-intervals-for-ml.html , 2022. Ac- cessed 2026-05-05
work page 2022
-
[73]
Information-guided noise allocation for efficient diffusion training, 2026
Gabriel Raya, Bac Nguyen, Georgios Batzolis, Yuhta Takida, Dejan Stancevic, Naoki Murata, Chieh-Hsin Lai, Yuki Mitsufuji, and Luca Ambrogioni. Information-guided noise allocation for efficient diffusion training, 2026
work page 2026
-
[74]
Sentence-bert: Sentence embeddings using siamese bert- networks, 2019
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks, 2019. 13
work page 2019
-
[75]
Daan Roos, Oscar Davis, Floor Eijkelboom, Michael Bronstein, Max Welling, ˙Ismail ˙Ilkan Ceylan, Luca Ambrogioni, and Jan-Willem van de Meent. Categorical flow maps, 2026
work page 2026
-
[76]
Simple and effective masked diffusion language models, 2024
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models, 2024
work page 2024
-
[77]
Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin Chiu, and V olodymyr Kuleshov. The diffusion duality, 2025
work page 2025
-
[78]
Scaling beyond masked diffusion language models, 2026
Subham Sekhar Sahoo, Jean-Marie Lemercier, Zhihan Yang, Justin Deschenaux, Jingyu Liu, John Thickstun, and Ante Jukic. Scaling beyond masked diffusion language models, 2026
work page 2026
-
[79]
Esoteric language models, 2025
Subham Sekhar Sahoo, Zhihan Yang, Yash Akhauri, Johnna Liu, Deepansha Singh, Zhoujun Cheng, Zhengzhong Liu, Eric Xing, John Thickstun, and Arash Vahdat. Esoteric language models, 2025
work page 2025
-
[80]
de Almeida, Alexander Rush, Thomas Pierrot, and V olodymyr Kuleshov
Yair Schiff, Subham Sekhar Sahoo, Hao Phung, Guanghan Wang, Sam Boshar, Hugo Dalla- torre, Bernardo P. de Almeida, Alexander Rush, Thomas Pierrot, and V olodymyr Kuleshov. Simple guidance mechanisms for discrete diffusion models, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.