Recognition: 2 theorem links
· Lean TheoremOptimistic Dual Averaging Unifies Modern Optimizers
Pith reviewed 2026-05-13 05:49 UTC · model grok-4.3
The pith
Optimistic dual averaging unifies Muon, Lion, AdEMAMix and NAdam as instances of one framework and supplies a fixed 1/k weight decay schedule.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
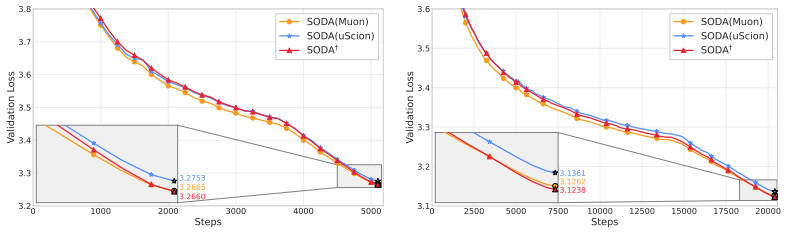
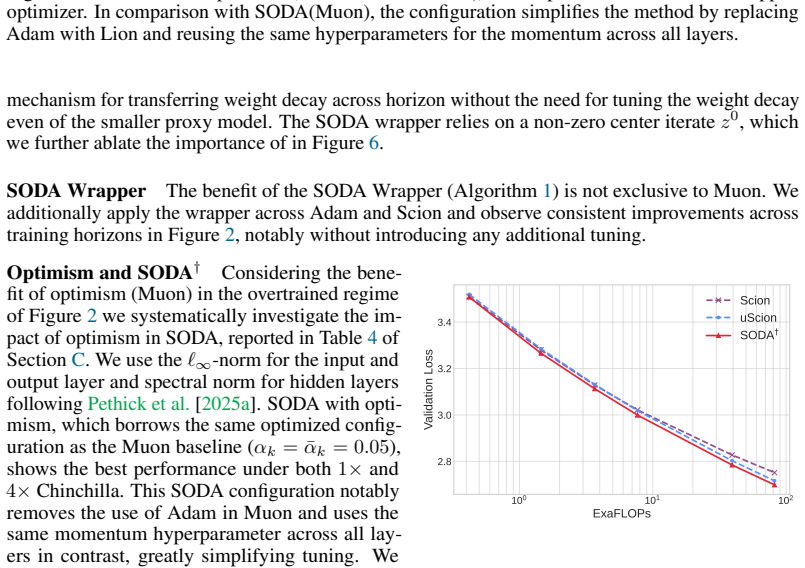
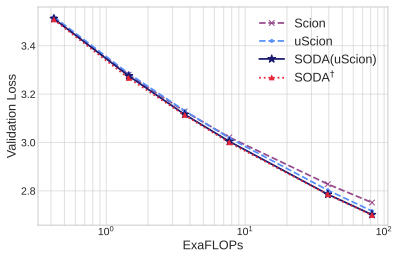
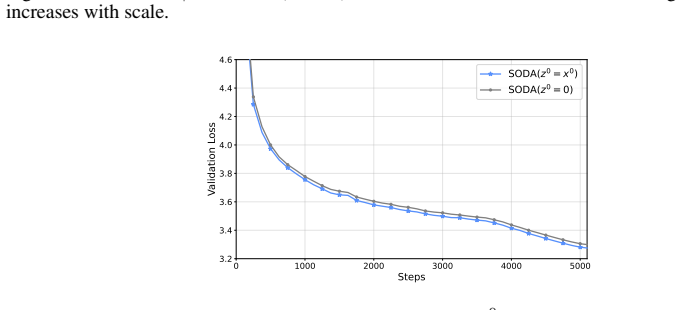
SODA generalizes optimistic dual averaging so that Muon, Lion, AdEMAMix and NAdam all appear as optimistic instances of the same framework. This perspective yields a practical wrapper that applies any base optimizer together with a theoretically derived 1/k weight decay schedule, removing the need to tune that hyperparameter. Empirical tests across scales and training horizons show consistent gains from the wrapper without extra hyperparameter search.
What carries the argument
The SODA generalization of optimistic dual averaging, which recasts listed modern optimizers as optimistic instances and derives the 1/k weight decay schedule from that view.
If this is right
- The listed optimizers inherit convergence properties associated with optimistic dual averaging.
- The 1/k weight decay schedule can be added to any base optimizer without introducing new tunable parameters.
- Performance improvements from the wrapper hold across different model scales and training lengths.
- Weight decay tuning effort can be replaced by the fixed schedule derived from the framework.
Where Pith is reading between the lines
- The unification may suggest systematic ways to combine features from the listed optimizers to create new variants.
- The 1/k schedule might extend usefully to other regularization terms beyond weight decay.
- Large-scale training pipelines could adopt the wrapper as a default to reduce hyperparameter search budgets.
Load-bearing premise
The named optimizers can be expressed as optimistic dual averaging instances without changing their essential behavior or performance characteristics.
What would settle it
A controlled run in which the SODA wrapper with 1/k decay applied to one of the listed optimizers produces lower final performance than the original version with its hand-tuned weight decay on the same benchmark and scale.
Figures


read the original abstract
We introduce SODA, a generalization of Optimistic Dual Averaging, which provides a common perspective on state-of-the-art optimizers like Muon, Lion, AdEMAMix and NAdam, showing that they can all be viewed as optimistic instances of this framework. Based on this framing, we propose a practical SODA wrapper for any base optimizer that eliminates weight decay tuning through a theoretically-grounded $1/k$ decay schedule. Empirical results across various scales and training horizons show that SODA consistently improves performance without any additional hyperparameter tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SODA as a generalization of optimistic dual averaging that unifies state-of-the-art optimizers (Muon, Lion, AdEMAMix, NAdam) by casting them as optimistic instances of the framework. It derives a 1/k weight-decay schedule from the framework and proposes a SODA wrapper applicable to any base optimizer that removes the need to tune weight decay. The authors claim that empirical results across scales and horizons show consistent performance gains with no additional hyperparameter tuning.
Significance. If the unification is exact (i.e., each listed optimizer is recovered precisely from the SODA recurrence without auxiliary terms or altered momentum/weight-decay interactions) and the 1/k schedule is shown to be a direct consequence rather than an ad-hoc addition, the work would supply a useful theoretical lens on recent optimizer design and a practical tuning-reduction technique. The empirical support, once properly documented, could strengthen adoption in large-scale training.
major comments (3)
- [§3] §3 (unification derivations): The manuscript must explicitly derive the update rules for Muon, Lion, AdEMAMix, and NAdam as special cases of the SODA recurrence via choice of optimism operator and regularizer, confirming that no auxiliary terms, gradient rescalings, or effective changes to momentum/weight-decay interaction are introduced. Without this exact embedding, the claim that convergence or practical behavior is inherited from the dual-averaging analysis does not hold.
- [Empirical results section] Empirical results section: The abstract asserts 'consistent improvement' yet provides no information on baselines, number of independent runs, statistical tests, model scales, or data exclusion rules. This omission prevents evaluation of whether the data support the central claim that the 1/k wrapper improves performance without hidden tuning.
- [§4] §4 (1/k schedule derivation): The paper should clarify whether the 1/k decay follows directly from the SODA equations without additional fitting or assumptions; if the schedule reduces to a fitted quantity by construction, the 'theoretically-grounded' framing requires revision.
minor comments (2)
- [§2] Notation for the optimism operator and regularizer should be introduced with explicit definitions before the unification claims to improve readability.
- [Abstract] The abstract would benefit from a one-sentence statement of the precise form of the 1/k schedule.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: [§3] §3 (unification derivations): The manuscript must explicitly derive the update rules for Muon, Lion, AdEMAMix, and NAdam as special cases of the SODA recurrence via choice of optimism operator and regularizer, confirming that no auxiliary terms, gradient rescalings, or effective changes to momentum/weight-decay interaction are introduced. Without this exact embedding, the claim that convergence or practical behavior is inherited from the dual-averaging analysis does not hold.
Authors: We agree that explicit derivations are necessary to rigorously support the unification. In the revised manuscript we will expand §3 with a new subsection containing complete, step-by-step derivations. For each optimizer we will specify the exact optimism operator and regularizer that recover its update rule from the SODA recurrence, verifying that no auxiliary terms, gradient rescalings, or alterations to momentum/weight-decay interactions are required. This will confirm that the convergence properties carry over directly. revision: yes
-
Referee: [Empirical results section] Empirical results section: The abstract asserts 'consistent improvement' yet provides no information on baselines, number of independent runs, statistical tests, model scales, or data exclusion rules. This omission prevents evaluation of whether the data support the central claim that the 1/k wrapper improves performance without hidden tuning.
Authors: We acknowledge that the current empirical section lacks sufficient methodological detail. The revised version will add an expanded experimental protocol subsection that explicitly lists: the full set of baselines (including weight-decay-tuned variants), the number of independent runs with distinct random seeds, statistical reporting (means, standard deviations, and significance tests where appropriate), the range of model scales and training horizons, and any data exclusion or preprocessing rules. These additions will allow readers to assess the robustness of the reported gains. revision: yes
-
Referee: [§4] §4 (1/k schedule derivation): The paper should clarify whether the 1/k decay follows directly from the SODA equations without additional fitting or assumptions; if the schedule reduces to a fitted quantity by construction, the 'theoretically-grounded' framing requires revision.
Authors: The 1/k schedule arises directly from the SODA analysis by choosing a time-varying regularization coefficient that yields optimal regret bounds under the optimistic dual-averaging framework; it is not obtained by fitting. In the revision we will augment §4 with the complete derivation, showing the precise steps from the SODA recurrence to the 1/k form. We will also revise the surrounding text to emphasize that the schedule is a theoretical consequence rather than an empirical choice. revision: yes
Circularity Check
No circularity: unification via special cases and derived schedule are independent of inputs
full rationale
The paper frames SODA as a generalization of optimistic dual averaging whose recurrence can recover listed optimizers (Muon, Lion, AdEMAMix, NAdam) by choice of optimism operator and regularizer. This is a standard embedding into an existing framework rather than a self-definition or fitted renaming. The 1/k weight-decay schedule is presented as a consequence of the dual-averaging analysis applied to the wrapper; no equation in the abstract or description reduces the schedule or the unification claim to a parameter fit performed on the target optimizers themselves. No self-citation is invoked as the sole justification for uniqueness or the central premise. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Optimistic dual averaging convergence assumptions (standard step-size and boundedness conditions)
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SODA recurrence with αk,¯αk,λk,¯λk and zk+1∈∂h∗k(−γk¯mk+1); 1/k schedule from λk=1/(k+2) and hk(x)=ψk(x−z0)
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Table 1 mapping Muon/Lion/NAdam to optimistic instances via specific hk (spectral, sign, smoothed ℓ∞)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv:2409.20325,
-
[2]
Michael Crawshaw, Chirag Modi, Mingrui Liu, and Robert M Gower. An exploration of non-euclidean gradient descent: Muon and its many variants.arXiv preprint arXiv:2510.09827,
-
[3]
doi: 10.52202/ 079017-0320. URL https://proceedings.neurips.cc/paper_files/paper/2024/ file/136b9a13861308c8948cd308ccd02658-Paper-Conference.pdf. Aaron Defazio, Konstantin Mishchenko, Parameswaran Raman, Hao-Jun Michael Shi, and Lin Xiao. Smoothing DiLoCo with primal averaging for faster training of LLMs.arXiv preprint arXiv:2512.17131,
-
[4]
Diloco: Distributed low- communication training of language models.arXiv preprint arXiv:2311.08105,
Arthur Douillard, Qixuan Feng, Andrei A Rusu, Rachita Chhaparia, Yani Donchev, Adhiguna Kuncoro, Marc’Aurelio Ranzato, Arthur Szlam, and Jiajun Shen. Diloco: Distributed low- communication training of language models.arXiv preprint arXiv:2311.08105,
-
[5]
10 Damien Ferbach, Courtney Paquette, Gauthier Gidel, Katie Everett, and Elliot Paquette. Logarithmic- time schedules for scaling language models with momentum.arXiv preprint arXiv:2602.05298,
-
[6]
Samy Jelassi and Aaron Defazio. Dual averaging is surprisingly effective for deep learning optimiza- tion.arXiv preprint arXiv:2010.10502,
-
[7]
Dominik Kallusky, Vinay Rao, Vishal Nandavanam, and Hao-Jun Michael Shi. SNOO: Step-k Nesterov outer optimizer-the surprising effectiveness of Nesterov momentum applied to pseudo- gradients.arXiv preprint arXiv:2510.15830,
-
[8]
Ali Kavis, Kfir Y Levy, Francis Bach, and V olkan Cevher. Unixgrad: A universal, adaptive algorithm with optimal guarantees for constrained optimization.Advances In Neural Information Processing Systems 32 (Nips 2019), 32(CONF),
work page 2019
-
[9]
Frederik Kunstner, Jacques Chen, Jonathan Wilder Lavington, and Mark Schmidt. Noise is not the main factor behind the gap between sgd and adam on transformers, but sign descent might be. arXiv preprint arXiv:2304.13960,
-
[10]
Depen Morwani, Nikhil Vyas, Hanlin Zhang, and Sham Kakade. Connections between schedule-free optimizers, AdEMAMix, and accelerated sgd variants.arXiv preprint arXiv:2502.02431,
-
[12]
A Modern Introduction to Online Learning
URL http://arxiv.org/abs/1912.13213. Matteo Pagliardini, Pierre Ablin, and David Grangier. The AdEMAMix optimizer: Better, faster, older.arXiv preprint arXiv:2409.03137,
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[13]
Training deep learning models with norm-constrained LMOs
Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-Falls, and V olkan Cevher. Training deep learning models with norm-constrained LMOs. InInternational Conference on Machine Learning, 2025a. Thomas Pethick, Wanyun Xie, Mete Erdogan, Kimon Antonakopoulos, Tony Silveti-Falls, and V olkan Cevher. Generalized gradient norm clipping ...
-
[14]
Meyer Scetbon, Chao Ma, Wenbo Gong, and Edward Meeds. Gradient multi-normalization for stateless and scalable LLM training.arXiv preprint arXiv:2502.06742,
-
[15]
Fabian Schaipp, Alexander Hägele, Adrien Taylor, Umut Simsekli, and Francis Bach. The surprising agreement between convex optimization theory and learning-rate scheduling for large model training.arXiv preprint arXiv:2501.18965,
-
[16]
Rethinking conventional wisdom in machine learning: From generalization to scaling
Lechao Xiao. Rethinking conventional wisdom in machine learning: From generalization to scaling. arXiv preprint arXiv:2409.15156,
-
[17]
Implicit bias of adamw: L inf norm constrained optimization
Shuo Xie and Zhiyuan Li. Implicit bias of AdamW: ℓ∞ norm constrained optimization.arXiv preprint arXiv:2404.04454,
-
[18]
arXiv preprint arXiv:2512.24880 , year=
Zhenda Xie, Yixuan Wei, Huanqi Cao, Chenggang Zhao, Chengqi Deng, Jiashi Li, Damai Dai, Huazuo Gao, Jiang Chang, Liang Zhao, et al. mHC: Manifold-constrained hyper-connections. arXiv preprint arXiv:2512.24880,
-
[19]
12 Appendix Table of Contents A Preliminaries 14 B Proofs for Section 4 (Analysis) 14 C Experiments 19 13 A Preliminaries Lemma A.1.Let∥ · ∥be a norm with dual norm∥ · ∥ ∗, and letD={x:∥x∥ ≤1}. Then s♯ =−∥s∥ ∗ lmo(s). Proof.Let u∈arg max ∥v∥≤1 ⟨s, v⟩, so that⟨s, u⟩=∥s∥ ∗. Then lmo(s)∈arg min ∥x∥≤1 ⟨s, x⟩=−u. Also, writingx=tvwitht≥0and∥v∥= 1, s♯ ∈arg max ...
work page 2013
-
[20]
Thusz k ∈∂h ∗(ˆθk)and θk = ˆθk −ηa k(gk −g k−1)
Set θk :=−η Pk i=0 aigi, θ −1 := 0, ˆθk :=θ k−1 −ηa kgk−1. Thusz k ∈∂h ∗(ˆθk)and θk = ˆθk −ηa k(gk −g k−1). 14 Sincehisµ-strongly convex,h ∗ is1/µ-smooth, hence h∗(θk)≤h ∗(ˆθk)−ηa k ⟨gk −g k−1, zk⟩+ η2a2 k 2µ gk −g k−1 2 ∗ . By Fenchel–Young, ⟨ˆθk, zk⟩=h(z k) +h ∗(ˆθk),⟨θ k, x⟩ ≤h(x) +h ∗(θk). Therefore ηak ⟨gk, zk −x⟩=ηa k ⟨gk −g k−1, zk⟩+ηa k ⟨gk−1, zk⟩...
work page 2024
-
[21]
Substituting the stated choice ofηgives the claim
Hence E[f(x n−1)−f(x ⋆)]≤ R⋆ ηn + 2ηG2 µ . Substituting the stated choice ofηgives the claim. B.2 Gradient Lipschitz The following refinement of Theorem B.2 is used to exploit smoothness of f. It follows the argument in Defazio et al. [2024, Thm. 5] directly, but allows for an non-Euclidean norm. For differentiablef, we write the objective Bregman diverge...
work page 2024
-
[22]
Proof.The choiceλ k−1 =a k/Ak implies xk = 1 Ak Pk i=0 aizi, k= 0, . . . , n−1. Fork= 0, . . . , n−1, following Defazio et al. [2024, Thm. 5], a direct expansion gives Ak f(x k)−f(x) −A k−1 f(x k−1)−f(x) =a k ⟨∇f(y k), zk −x⟩ − ak ¯λk−1 Df(yk, xk)− ak(1−¯λk−1) ¯λk−1 Df(xk, yk) −A k−1Df(xk−1, xk)−a kDf(x, yk), with the convention that the terms involving A...
work page 2024
-
[23]
For simplicity, consider ¯αk = 0 and ¯λk = 0, which disable optimism and enables primal extrapolation. In the context of Frank-Wolfe based methods such as Scion [Pethick et al., 2025a], SODA then corresponds to i) centering the update around the initialization z0 instead of the origin, and ii) setting the Frank-Wolfe stepsizeλ k = 1/(k+ 2)while the radius...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.