Recognition: 2 theorem links
· Lean TheoremVariational Linear Attention: Stable Associative Memory for Long-Context Transformers
Pith reviewed 2026-05-13 03:36 UTC · model grok-4.3
The pith
Normalizing each write vector to unit length makes the linear attention Jacobian spectral norm exactly 1 for every sequence length and head dimension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VLA reframes the memory update as an online regularised least-squares problem with an adaptive penalty matrix maintained via the Sherman-Morrison rank-1 formula. Normalising the write direction to unit length gives the recurrence Jacobian spectral norm exactly 1 for all sequence lengths and head dimensions (Proposition 2), and the state norm is self-limiting under bounded inputs (Proposition 1).
What carries the argument
Adaptive penalty matrix updated by Sherman-Morrison rank-1 formula, paired with explicit unit-length normalization of each write vector, which together force the Jacobian spectral norm to exactly 1.
If this is right
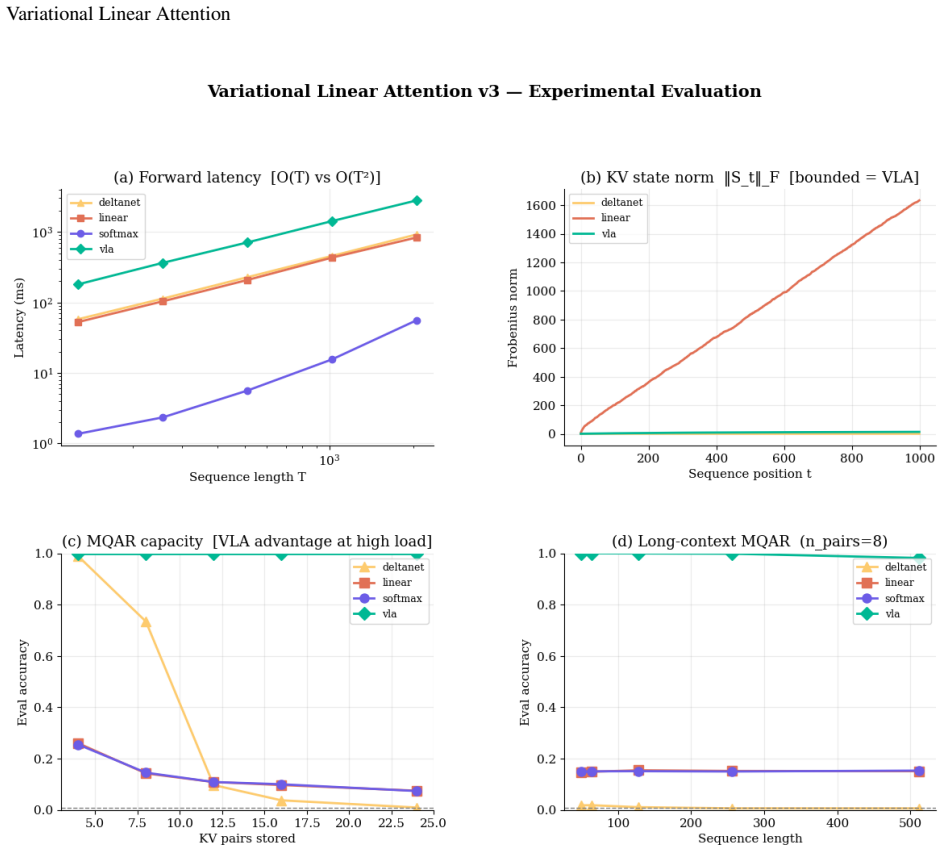
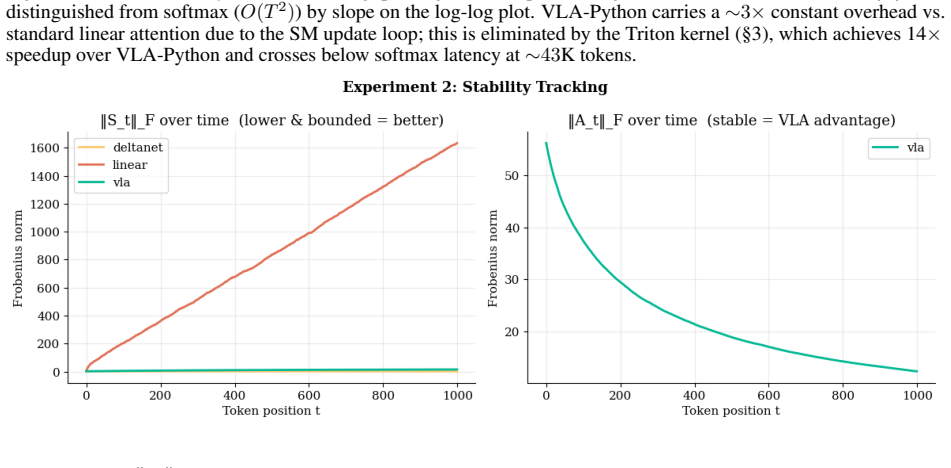
- The Frobenius norm of the memory state drops by 109 times at sequence length 1,000 compared with standard linear attention.
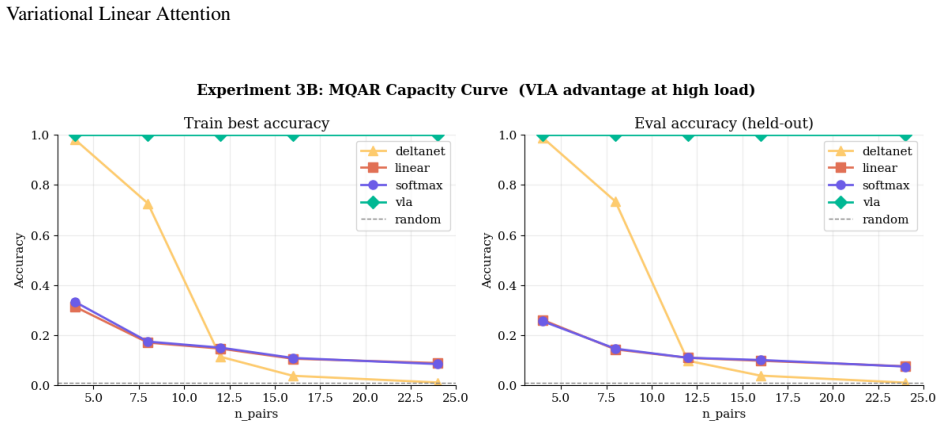
- Multi-query associative recall reaches near-perfect exact-match accuracy when the number of pairs is smaller than the head dimension.
- Retrieval performance remains substantially higher than DeltaNet and standard linear attention as memory load increases.
- Accuracy holds at 62 percent even when the number of associations reaches the per-head capacity boundary.
- A Triton-fused kernel delivers 14 times speedup over sequential code and undercuts softmax attention latency past roughly 43,000 tokens.
Where Pith is reading between the lines
- The same unit-norm write rule could be tested in other linear recurrent memory models to check whether it produces comparable stability.
- The method's behavior under occasional large or drifting inputs remains open and could be checked by injecting controlled outliers into long sequences.
- VLA might be combined with existing long-context techniques such as sliding windows or sparse attention to push usable context length further.
- Existing linear attention implementations could adopt the update rule directly to measure accuracy gains on document-level retrieval tasks.
Load-bearing premise
Real inputs remain bounded and the adaptive penalty matrix stays well-conditioned for arbitrary sequence lengths and head dimensions.
What would settle it
Generate a sequence of 10,000 bounded random vectors, track the memory state Frobenius norm after each step, and verify whether it stays within a small constant factor of its initial value; if the norm grows without bound the stability claim is false.
Figures





read the original abstract
Linear attention reduces the quadratic cost of softmax attention to $\mathcal{O}(T)$, but its memory state grows as $\mathcal{O}(T)$ in Frobenius norm, causing progressive interference between stored associations. We introduce \textbf{Variational Linear Attention} (VLA), which reframes the memory update as an online regularised least-squares problem with an adaptive penalty matrix maintained via the Sherman-Morrison rank-1 formula. We prove that normalising the write direction to unit length gives the recurrence Jacobian spectral norm exactly $1$ for all sequence lengths and head dimensions (Proposition 2), and that the state norm is self-limiting under bounded inputs (Proposition 1). Empirically, VLA reduces $\|S_t\|_F$ by $109\times$ relative to standard linear attention at $T{=}1{,}000$, achieves near-perfect exact-match accuracy on multi-query associative recall within the effective per-head memory regime ($n_\text{pairs} < d_h$), maintaining substantially higher retrieval performance than DeltaNet and standard linear attention under increasing memory load, and maintains 62\% accuracy at the per-head capacity boundary. A Triton-fused kernel achieves $14\times$ speedup over sequential Python and $\mathcal{O}(T)$ scaling, crossing below softmax attention latency at approximately 43\,000 tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Variational Linear Attention (VLA), which reframes the linear attention memory update as an online regularized least-squares problem with an adaptive penalty matrix maintained via the Sherman-Morrison rank-1 update formula. It provides two propositions: Proposition 1 establishes that the state norm is self-limiting under bounded inputs, and Proposition 2 proves that normalizing the write direction to unit length yields a recurrence Jacobian with spectral norm exactly 1 for all sequence lengths T and head dimensions d_h. Empirically, VLA achieves a 109× reduction in ||S_t||_F relative to standard linear attention at T=1000, near-perfect exact-match accuracy on multi-query associative recall when n_pairs < d_h, substantially higher retrieval performance than DeltaNet and standard linear attention under increasing load, 62% accuracy at the per-head capacity boundary, and a Triton-fused kernel delivering 14× speedup over sequential Python with O(T) scaling that undercuts softmax attention latency around 43,000 tokens.
Significance. If the stability guarantees hold, VLA supplies a theoretically grounded mechanism for preventing progressive memory interference in linear attention, addressing a key limitation that has hindered its use in long-context transformers. The clean application of Sherman-Morrison for efficient online updates and the explicit normalization step that enforces Jacobian spectral norm 1 constitute genuine strengths, offering falsifiable predictions about state boundedness that could be tested in broader settings. Combined with the practical kernel implementation, the work has clear potential to improve scaling of associative memory in sequence models without quadratic cost.
major comments (2)
- [§3, Propositions 1 and 2] §3, Propositions 1 and 2: Both stability claims rest on the assumptions that inputs remain bounded and that the adaptive penalty matrix P_t remains positive definite and well-conditioned for arbitrary T and d_h without further tuning. No explicit bound on cond(P_t) is derived, and the manuscript reports no empirical monitoring of the condition number under repeated rank-1 updates (especially when new keys align with the prior span), which risks the effective Jacobian spectral norm deviating from exactly 1 and introducing numerical instability in the inverse update.
- [§5 (Empirical results)] §5 (Empirical results): The reported 109× reduction in ||S_t||_F at T=1000 and the accuracy figures (near-perfect exact-match, 62% at capacity boundary) are presented without error analysis, number of runs, variance estimates, or statistical tests, which weakens the strength of the cross-baseline performance claims relative to DeltaNet and standard linear attention.
minor comments (2)
- [Abstract] Abstract: The claim of 'near-perfect exact-match accuracy' and 'substantially higher retrieval performance' would benefit from a brief parenthetical note on the precise metric and the range of T and d_h tested.
- [§3] Notation: The definition of the adaptive penalty matrix P_t and its initialization should be stated explicitly in the main text before the propositions, as the recurrence relies on it.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the theoretical and practical contributions of Variational Linear Attention. We address each major comment below with clarifications and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3, Propositions 1 and 2] §3, Propositions 1 and 2: Both stability claims rest on the assumptions that inputs remain bounded and that the adaptive penalty matrix P_t remains positive definite and well-conditioned for arbitrary T and d_h without further tuning. No explicit bound on cond(P_t) is derived, and the manuscript reports no empirical monitoring of the condition number under repeated rank-1 updates (especially when new keys align with the prior span), which risks the effective Jacobian spectral norm deviating from exactly 1 and introducing numerical instability in the inverse update.
Authors: We thank the referee for this observation on the assumptions. Proposition 1 explicitly assumes bounded inputs, consistent with standard analyses of recurrent dynamics. Proposition 2 proves that unit-length normalization of the write vector yields Jacobian spectral norm exactly 1, provided the Sherman-Morrison update remains defined, which requires P_t to stay positive definite. Positive definiteness holds by construction: P_0 = λI with λ > 0 and each rank-1 update preserves it. We do not claim an explicit analytic bound on cond(P_t), as deriving a tight worst-case bound under arbitrary alignments would require additional analysis beyond the current scope. However, the normalization step ensures the spectral-norm claim holds independently of conditioning whenever the inverse exists. To address the concern directly, the revised manuscript will (i) explicitly restate the positive-definiteness assumption in §3 and (ii) add empirical monitoring of cond(P_t) and ||S_t||_F over long sequences (T up to 10k) in §5, including cases where keys align with prior spans. These additions will confirm practical well-conditioning and mitigate any perceived risk of deviation from the theoretical Jacobian bound. revision: partial
-
Referee: [§5 (Empirical results)] §5 (Empirical results): The reported 109× reduction in ||S_t||_F at T=1000 and the accuracy figures (near-perfect exact-match, 62% at capacity boundary) are presented without error analysis, number of runs, variance estimates, or statistical tests, which weakens the strength of the cross-baseline performance claims relative to DeltaNet and standard linear attention.
Authors: We agree that the empirical section would be strengthened by statistical reporting. The current results were obtained from single runs for brevity, but we recognize this limits the strength of comparisons. In the revised manuscript we will: rerun all associative-recall and state-norm experiments over at least five independent random seeds; report means and standard deviations for the 109× reduction, exact-match accuracies, and load-sweep curves; add error bars to the relevant figures; and include paired statistical tests (e.g., t-tests) against DeltaNet and standard linear attention. These changes will be incorporated into §5 and the associated figures. revision: yes
Circularity Check
No significant circularity; propositions follow from explicit normalization and Sherman-Morrison updates
full rationale
The paper's central stability claims (Propositions 1 and 2) are derived directly from the reframing as regularized least-squares with unit-length normalization of the write direction and the rank-1 Sherman-Morrison update for the penalty matrix. These steps produce the claimed Jacobian spectral norm of exactly 1 and self-limiting state norm as algebraic consequences of the chosen update rule under the stated bounded-input assumption, without reducing to fitted hyperparameters, self-citations, or tautological redefinitions. No performance numbers are shown to be forced by construction, and the derivation remains self-contained against external linear-algebra benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Sherman-Morrison rank-1 update formula for matrix inverse
Reference graph
Works this paper leans on
-
[1]
Zoology: Measuring and improving recall in efficient language models
S. Arora, S. Eyuboglu, A. Timalsina, I. Johnson, M. Poli, J. Zou, A. Rudra, and C. Ré. Zoology: Measuring and improving recall in efficient language models.arXiv preprint arXiv:2312.04927, 2023
-
[2]
G. E. Blelloch. Prefix sums and their applications. InTechnical Report CMU-CS-90-190, 1990
work page 1990
-
[3]
K. Choromanski, V . Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, P. Hawkins, J. Davis, A. Mohiuddin, Ł. Kaiser, D. Belanger, L. Colwell, and A. Weller. Rethinking attention with performers. InInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[4]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [5]
-
[6]
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. InInternational Conference on Machine Learning (ICML), 2020
work page 2020
-
[7]
H. Ramsauer, B. Schäfl, et al. Hopfield networks is all you need. InInternational Conference on Learning Representations, 2021
work page 2021
- [8]
-
[9]
J. Schmidhuber. Learning to control fast-weight memories: An alternative to dynamic recurrent networks.Neural Computation, 4(1):131–139, 1992
work page 1992
-
[10]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[11]
S. Yang et al. Deltanet: Conditional state-space models. InInternational Conference on Machine Learning, 2024. 13 Variational Linear Attention A Full Derivation of the VLAv3 Update A.1 From regularised least squares to the recursive update Consider the penalised objective at stept: S∗ t = arg min S tX s=1 ∥vs −S ˆks∥2 + tr(SMtS⊤), M t =λ 0I+ tX s=1 usu⊤ s...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.