Recognition: 2 theorem links
· Lean TheoremLatent Chain-of-Thought Improves Structured-Data Transformers
Pith reviewed 2026-05-13 01:44 UTC · model grok-4.3
The pith
Latent chain-of-thought via recurrent feedback tokens improves transformer performance on time-series forecasting and tabular prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
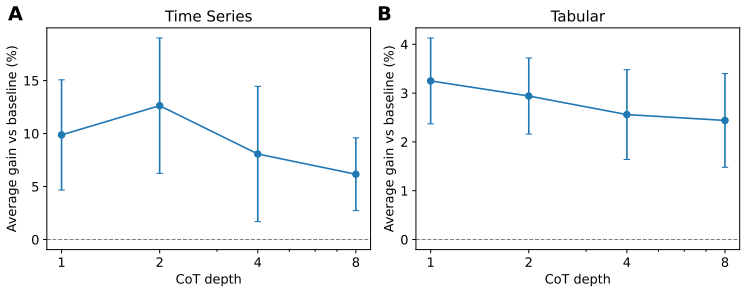
The central claim is that latent chain-of-thought, implemented through compression of query-position hidden states into feedback tokens that are appended and re-processed recurrently, augments expressive power for structured-data transformers. Across 36 datasets the method improves over the baseline on 8 of 9 time-series cases with 10.99% average gain and on 22 of 27 tabular cases with 5.31% average gain, and the CoT models achieve the highest average performance overall when compared to no-CoT, deeper, and weight-tied looped baselines.
What carries the argument
Latent chain-of-thought recurrent scheme that compresses query-position hidden states into appended feedback tokens for additional processing rounds.
Load-bearing premise
The observed gains are caused by the specific chain-of-thought feedback tokens rather than incidental effects from recurrence or extra computation alone.
What would settle it
An ablation that replaces the compressed hidden-state feedback tokens with random or constant values while keeping the recurrent architecture fixed, then checks whether the accuracy gains disappear on the same datasets.
Figures

read the original abstract
Chain-of-thought and more broadly test-time compute are known to augment the expressive capabilities of language models and have led to major innovations in reasoning. Motivated by this success, this paper explores latent chain-of-thought as well as the impact of depth and looping for time-series and tabular data. We propose a recurrent scheme in which a structured-data transformer, after an initial forward pass, compresses its query-position hidden states into feedback tokens that are appended to the input and processed again, allowing multiple rounds of latent computation before prediction. We compare CoT models against a same-depth no-CoT baseline, a deeper baseline matched to the CoT model in effective depth, and a looped transformer with weight-tied recurrence but no additional chain-of-thought tokens. Across 36 datasets in time-series forecasting and tabular prediction, latent chain-of-thought improves over the baseline on 8/9 time-series datasets (+10.99\% average gain) and 22/27 tabular datasets (+5.31\% average gain). Across both settings, the CoT models perform the best on average. These results demonstrate that chain-of-thought is a useful axis for scaling test-time compute for structured data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a recurrent latent chain-of-thought scheme for structured-data transformers: after an initial forward pass, query-position hidden states are compressed into feedback tokens that are appended to the input and re-processed for multiple rounds of latent computation before final prediction. It evaluates this approach against a same-depth no-CoT baseline, a deeper baseline matched in effective depth, and a weight-tied looped transformer without the additional CoT tokens, reporting consistent wins across 36 datasets (8/9 time-series with +10.99% average gain; 22/27 tabular with +5.31% average gain), with CoT models performing best on average.
Significance. The paper's broad empirical evaluation across two distinct structured-data domains and a large number of datasets provides a substantial test of whether test-time compute scaling via latent reasoning can transfer beyond language models. If the gains survive tighter controls that isolate the compression operator and recurrence from the latent CoT mechanism itself, the result would usefully extend chain-of-thought ideas to tabular and time-series transformers.
major comments (3)
- [Methods (§3) and Experimental Controls (§4.2)] The looped baseline (weight-tied recurrence without extra tokens) does not match the CoT variant on the learned compression step that maps hidden states to feedback tokens. This operator can inject additional capacity or change information routing even when total depth is controlled, so the reported gains cannot yet be attributed specifically to latent chain-of-thought rather than the compression itself. The central claim therefore rests on an incompletely isolated comparison.
- [Results (§5, Tables 1–3)] Aggregate results are presented as average percentage gains without reported per-dataset variances, random-seed statistics, or correction for multiple comparisons across 36 datasets. This makes it difficult to assess whether the headline +10.99% and +5.31% improvements are robust or could be explained by chance or hyperparameter sensitivity.
- [Ablation Studies (§5.3)] No ablation is shown that holds the recurrent loop and token count fixed while varying only the presence or training of the compression function (e.g., random or identity compression). Such a control would directly test whether the performance delta arises from the latent reasoning pathway or from the extra learned module.
minor comments (2)
- [Abstract and §1] The abstract and introduction could more explicitly state the number of recurrent rounds used and the precise architecture of the compression module (e.g., linear projection, attention-based, or MLP) to allow immediate replication.
- [§3] Notation for hidden states, query positions, and feedback tokens should be unified across the methods and appendix to avoid minor ambiguity when readers compare equations.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the isolation of the latent chain-of-thought contribution and the statistical robustness of the results. We address each major point below and will incorporate revisions to provide tighter controls and additional reporting.
read point-by-point responses
-
Referee: [Methods (§3) and Experimental Controls (§4.2)] The looped baseline (weight-tied recurrence without extra tokens) does not match the CoT variant on the learned compression step that maps hidden states to feedback tokens. This operator can inject additional capacity or change information routing even when total depth is controlled, so the reported gains cannot yet be attributed specifically to latent chain-of-thought rather than the compression itself. The central claim therefore rests on an incompletely isolated comparison.
Authors: We agree that the learned compression operator introduces an additional trainable component absent from the weight-tied looped baseline, and that this could contribute to the observed differences. The looped baseline was intended to control for recurrence and effective depth without the explicit feedback-token mechanism. To better isolate the contribution of the latent reasoning pathway, we will add an ablation in the revised manuscript that replaces the learned compression with a fixed operator (e.g., mean pooling of query-position states or a random linear projection) while keeping the number of loops and feedback tokens identical to the CoT model. This will clarify whether the gains stem primarily from the learned compression or from the recurrent latent computation enabled by the tokens. revision: yes
-
Referee: [Results (§5, Tables 1–3)] Aggregate results are presented as average percentage gains without reported per-dataset variances, random-seed statistics, or correction for multiple comparisons across 36 datasets. This makes it difficult to assess whether the headline +10.99% and +5.31% improvements are robust or could be explained by chance or hyperparameter sensitivity.
Authors: We acknowledge that reporting only aggregate averages limits assessment of robustness. Although each dataset was evaluated with multiple random seeds, only mean gains were reported. In the revision we will add per-dataset standard deviations across seeds, include error bars on the aggregate figures, and report the number of wins with a simple sign test to address multiplicity. We note that the pattern of improvements (8/9 time-series and 22/27 tabular) is consistent, but we will explicitly discuss the absence of formal multiple-comparison correction and its implications for interpreting the headline percentages. revision: yes
-
Referee: [Ablation Studies (§5.3)] No ablation is shown that holds the recurrent loop and token count fixed while varying only the presence or training of the compression function (e.g., random or identity compression). Such a control would directly test whether the performance delta arises from the latent reasoning pathway or from the extra learned module.
Authors: This suggestion directly complements the first comment. We will add the requested ablation to §5.3, fixing the number of recurrent loops and feedback tokens while varying only the compression function: comparing the learned compressor against a random projection and, where token dimensionality permits, an identity or mean-pooling baseline. Results will be reported alongside the existing comparisons to quantify how much of the performance delta is attributable to the trainable compression versus the latent chain-of-thought structure itself. revision: yes
Circularity Check
No circularity in empirical performance claims
full rationale
This is an empirical comparison paper whose central claims consist of measured performance deltas on 36 datasets after controlling for depth and recurrence. No equations, derivations, or fitted parameters are presented that could reduce to self-definition or tautology. The method is described as a recurrent scheme with compression and feedback tokens, but the headline results are reported as direct experimental outcomes rather than predictions derived from the inputs by construction. Self-citations, if present, are not load-bearing for the attribution of gains to latent CoT. The evaluation is externally falsifiable via replication.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearrecurrent scheme in which a structured-data transformer, after an initial forward pass, compresses its query-position hidden states into feedback tokens that are appended to the input and processed again
Reference graph
Works this paper leans on
- [1]
-
[2]
Daya Guo et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
work page 2025
-
[3]
Scaling llm test-time compute optimally can be more effective than scaling model parameters, 2024
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters, 2024
work page 2024
-
[4]
Chain-of-thought prompting elicits reasoning in large language models, 2023
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023
work page 2023
-
[5]
Training large language models to reason in a continuous latent space, 2025
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space, 2025
work page 2025
-
[6]
Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach, 2025
work page 2025
-
[7]
Emrullah Ildiz, Xuechen Zhang, Hrayr Harutyunyan, Ankit Singh Rawat, and Samet Oymak
Halil Alperen Gozeten, M. Emrullah Ildiz, Xuechen Zhang, Hrayr Harutyunyan, Ankit Singh Rawat, and Samet Oymak. Continuous chain of thought enables parallel exploration and reasoning, 2025. Accepted to ICLR 2026
work page 2025
-
[8]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. Universal transformers, 2019
work page 2019
-
[9]
Lee, and Dimitris Papailiopoulos
Angeliki Giannou, Shashank Rajput, Jy yong Sohn, Kangwook Lee, Jason D. Lee, and Dimitris Papailiopoulos. Looped transformers as programmable computers, 2023
work page 2023
-
[10]
Think before you speak: Training language models with pause tokens, 2024
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens, 2024
work page 2024
-
[11]
Tabpfn: A transformer that solves small tabular classification problems in a second, 2023
Noah Hollmann, Samuel M¨ uller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification problems in a second, 2023. 5
work page 2023
-
[12]
Tabpfn-2.5: Advancing the state of the art in tabular foundation models, 2026
L´ eo Grinsztajn et al. Tabpfn-2.5: Advancing the state of the art in tabular foundation models, 2026
work page 2026
-
[13]
Tabicl: A tabular foundation model for in-context learning on large data, 2025
Jingang Qu, David Holzm¨ uller, Ga¨ el Varoquaux, and Marine Le Morvan. Tabicl: A tabular foundation model for in-context learning on large data, 2025
work page 2025
-
[14]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, page 785–794. ACM, August 2016
work page 2016
-
[15]
Chronos: Learning the language of time series, 2024
Abdul Fatir Ansari, Lorenzo Stella, et al. Chronos: Learning the language of time series, 2024
work page 2024
-
[16]
A decoder-only foundation model for time-series forecasting, 2024
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting, 2024
work page 2024
-
[17]
Unified training of universal time series forecasting transformers, 2024
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Unified training of universal time series forecasting transformers, 2024
work page 2024
-
[18]
Fincast: A foundation model for financial time-series forecasting, 2025
Zhuohang Zhu, Haodong Chen, Qiang Qu, and Vera Chung. Fincast: A foundation model for financial time-series forecasting, 2025
work page 2025
-
[19]
Mantis: A Foundation Model for Mechanistic Disease Forecasting
Carson Dudley, Reiden Magdaleno, Christopher Harding, Ananya Sharma, and Marisa Eisenberg. Mantis: A foundation model for mechanistic disease forecasting.arXiv preprint arXiv:2508.12260, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Are transformers effective for time series forecasting?, 2022
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting?, 2022
work page 2022
-
[21]
Bernd Bischl, Giuseppe Casalicchio, Matthias Feurer, Pieter Gijsbers, Frank Hutter, Michel Lang, Rafael G. Mantovani, Jan N. van Rijn, and Joaquin Vanschoren. Openml benchmarking suites, 2021
work page 2021
-
[22]
Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam
Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers, 2023
work page 2023
-
[23]
Towards thinking-optimal scaling of test-time compute for llm reasoning, 2025
Wenkai Yang, Shuming Ma, Yankai Lin, and Furu Wei. Towards thinking-optimal scaling of test-time compute for llm reasoning, 2025
work page 2025
-
[24]
Andrea Banino, Jan Balaguer, and Charles Blundell. Pondernet: Learning to ponder, 2021. A Architecture and training details All models are trained from scratch on each dataset using the same optimizer and schedule. We use AdamW with learning rate 3 × 10−4, cosine annealing, weight decay 10 −4, batch size 128, and a maximum of 100 epochs with early stoppin...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.