Recognition: no theorem link
Neural Statistical Functions
Pith reviewed 2026-05-13 01:53 UTC · model grok-4.3
The pith
Neural statistical functions directly infer statistics over continuous ranges from pre-trained single-sample predictors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By transforming diverse statistical functions into prefix statistics over intervals and training on the identity between those prefixes and single-case regression targets, neural statistical functions output the desired statistics directly across operating condition ranges.
What carries the argument
Prefix statistics, which recast integrals, quantiles, and maxima as interval-conditional regression targets via their identity with individual-case predictions.
Load-bearing premise
The identity between prefix statistics and individual-case regression holds sufficiently well to serve as a reliable learning objective when trained only on scattered data samples and pre-trained single-sample predictors.
What would settle it
A test case in which the neural statistical function's output for a given interval deviates substantially from the empirical statistics obtained by repeated forward passes of the pre-trained single-sample predictor over many samples drawn from that interval.
Figures

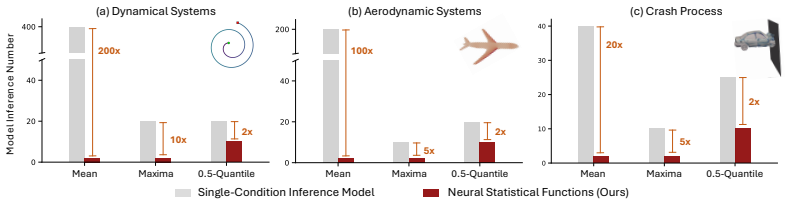






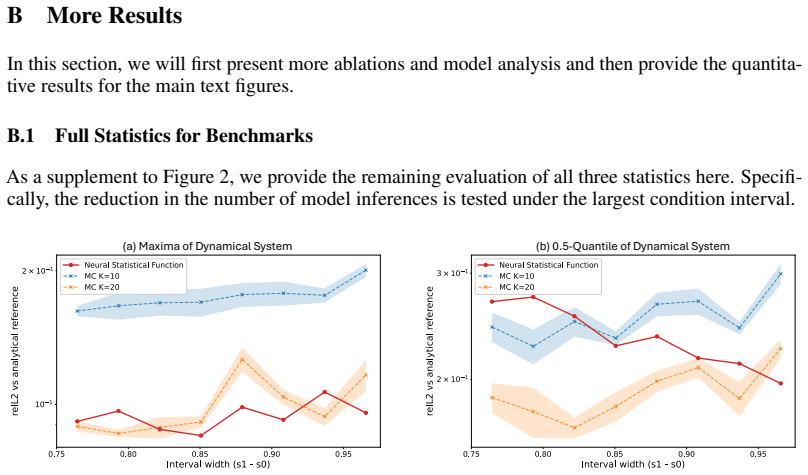





read the original abstract
Classical deep learning typically operates on individual cases. Despite its success, real-world usage often requires repeated inference to estimate statistical quantities for complex decision-making tasks involving uncertainty or extreme-value analysis, resulting in substantial latency. We introduce neural statistical functions, a new family of models learned from pre-trained single-sample predictors and scattered data samples, which can directly infer statistics over continuous operating condition ranges without explicit sampling. By introducing the notion of prefix statistics, we transform and unify diverse statistical functions (e.g., integrals, quantiles, and maxima) into an interval-conditional framework, in which a principled identity between the prefix statistics and the individual-case regression serves as the learning objective. Neural statistical functions achieve strong performance in estimating essential statistics of complex physical processes, including accumulated energy in dynamical systems, quantiles of aerodynamic responses, and maximum stress in crash processes, while achieving up to a 100$\times$ reduction in model evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents neural statistical functions as a novel approach to estimating statistical properties of physical processes over ranges of operating conditions. By introducing prefix statistics, the authors transform integrals, quantiles, and maxima into an interval-conditional regression task. A key 'principled identity' between these prefix statistics and standard single-sample regression is used as the training objective, allowing the model to be learned from pre-trained point predictors and scattered samples. Experiments on accumulated energy in dynamical systems, aerodynamic response quantiles, and maximum stress in crash simulations demonstrate strong performance with up to a 100-fold reduction in required model evaluations.
Significance. If the central identity holds under the reported conditions, this method could provide a significant efficiency gain for tasks requiring statistical estimation in complex simulations, reducing the need for repeated inferences. The framework's ability to handle diverse statistics in a unified way has potential for broad impact in fields like engineering and physics, where computational resources for uncertainty analysis are often limiting.
major comments (2)
- [§3] §3: The principled identity between prefix statistics and individual-case regression is the load-bearing element of the learning objective, yet the manuscript provides no derivation, proof, or analysis of its validity for non-smooth statistics (e.g., maxima) or sparse data regimes. This directly impacts the reliability of the claimed performance on crash processes and aerodynamic quantiles.
- [§5] §5, experiments: The reported results claim strong performance and up to 100× reduction, but without explicit details on sample density, baseline Monte Carlo comparisons at matched compute, or error bars on the non-smooth targets, the evidence does not yet substantiate the central efficiency claim.
minor comments (2)
- [Abstract] Abstract: The introduction of 'neural statistical functions' would benefit from a brief contrast with related concepts such as conditional neural processes or quantile regression networks to clarify novelty.
- [§2] §2: The definition of prefix statistics could include an explicit small-scale example with equations to illustrate the transformation from standard statistics.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of the principled identity and experimental validation. We address each major comment below and will incorporate revisions to strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3: The principled identity between prefix statistics and individual-case regression is the load-bearing element of the learning objective, yet the manuscript provides no derivation, proof, or analysis of its validity for non-smooth statistics (e.g., maxima) or sparse data regimes. This directly impacts the reliability of the claimed performance on crash processes and aerodynamic quantiles.
Authors: We agree that a formal derivation and analysis of the identity is necessary for rigor, particularly for non-smooth cases. In the revised manuscript, we will add a dedicated subsection in §3 deriving the identity from first principles for integrals and quantiles, and extend the analysis to maxima by showing that the prefix formulation corresponds to an expectation over indicator functions under the appropriate measure. We will also include a brief discussion of conditions for validity in sparse regimes, supported by additional synthetic experiments demonstrating convergence rates. This will directly support the reliability of results on crash simulations and aerodynamics. revision: yes
-
Referee: [§5] §5, experiments: The reported results claim strong performance and up to 100× reduction, but without explicit details on sample density, baseline Monte Carlo comparisons at matched compute, or error bars on the non-smooth targets, the evidence does not yet substantiate the central efficiency claim.
Authors: We acknowledge that the current experimental section would benefit from greater transparency to fully substantiate the efficiency claims. In the revision, we will expand §5 with tables detailing training sample densities for each task, direct wall-clock and evaluation-count comparisons against Monte Carlo baselines at matched computational budgets, and error bars (or quantile ranges) for non-smooth targets such as maximum stress. These additions will provide clearer evidence for the reported performance gains while preserving the existing experimental setup. revision: yes
Circularity Check
No circularity: prefix statistics identity is a definitional transformation, not a self-referential fit
full rationale
The paper introduces prefix statistics as a new unifying concept that recasts integrals, quantiles, and maxima as interval-conditional regression problems. The learning objective is then supplied by an asserted mathematical identity linking these prefix quantities to ordinary single-sample regression. This identity is presented as a direct consequence of the definitions rather than a fitted parameter, a self-citation, or an ansatz imported from prior work. No equations in the abstract or description reduce a claimed prediction back to a fitted input by construction, and no load-bearing uniqueness theorem or self-citation chain is invoked. Empirical performance claims (100× speedup, accuracy on crash maxima, etc.) are therefore external to the derivation itself and can be evaluated independently.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper A principled identity exists between prefix statistics and individual-case regression that can serve as the learning objective.
invented entities (2)
-
prefix statistics
no independent evidence
-
neural statistical functions
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Benedikt Alkin, Maurits Bleeker, Richard Kurle, Tobias Kronlachner, Reinhard Sonnleitner, Matthias Dorfer, and Johannes Brandstetter. AB-UPT: Scaling neural CFD surrogates for high- fidelity automotive aerodynamics simulations via anchored- branched universal physics transformers.TMLR, 2025
work page 2025
-
[3]
Altair Engineering Inc. Altair physicsai. https://www.altair.com/physicsai, 2026. Accessed: 2026-01-06
work page 2026
-
[4]
Altair Engineering Inc. Altair radioss. https://www.openradioss.org, 2026. Accessed: 2026-01-06
work page 2026
-
[5]
Ansys Inc. Ansys simai. https://www.ansys.com/products/simai, 2026. Accessed: 2026-01-06
work page 2026
-
[6]
Neural operators for accelerating scientific simulations and design
Kamyar Azizzadenesheli, Nikola Kovachki, Zongyi Li, Miguel Liu-Schiaffini, Jean Kossaifi, and Anima Anandkumar. Neural operators for accelerating scientific simulations and design. Nature Reviews Physics, 2024
work page 2024
-
[7]
Introduction of applied aerodynamics surrogate modeling benchmark cases
Philipp Bekemeyer, Nathan Hariharan, Andrew M Wissink, and Jason Cornelius. Introduction of applied aerodynamics surrogate modeling benchmark cases. InAIAA SCITECH 2025 Forum, 2025
work page 2025
-
[8]
Accurate medium-range global weather forecasting with 3d neural networks.Nature, 2023
Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. Accurate medium-range global weather forecasting with 3d neural networks.Nature, 2023
work page 2023
-
[9]
Monte carlo and quasi-monte carlo methods.Acta numerica, 1998
Russel E Caflisch. Monte carlo and quasi-monte carlo methods.Acta numerica, 1998
work page 1998
-
[10]
Neural ordinary differential equations.NeurIPS, 2018
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations.NeurIPS, 2018
work page 2018
-
[11]
Augmented neural odes.NeurIPS, 2019
Emilien Dupont, Arnaud Doucet, and Yee Whye Teh. Augmented neural odes.NeurIPS, 2019
work page 2019
-
[12]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. InICML, 2016
work page 2016
-
[13]
Mean flows for one-step generative modeling.NeurIPS, 2025
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.NeurIPS, 2025
work page 2025
-
[14]
Denoising diffusion probabilistic models.NeurIPS, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.NeurIPS, 2020
work page 2020
-
[15]
Highly accurate protein structure prediction with alphafold.Nature, 2021
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ron- neberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, et al. Highly accurate protein structure prediction with alphafold.Nature, 2021
work page 2021
-
[16]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics
Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. InCVPR, 2018
work page 2018
-
[17]
Neural operator: Learning maps between function spaces with applications to pdes.JMLR, 2023
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to pdes.JMLR, 2023
work page 2023
-
[18]
Timothy Langlois, Ariel Shamir, Daniel Dror, Wojciech Matusik, and David IW Levin. Stochas- tic structural analysis for context-aware design and fabrication.ACM Transactions on Graphics (TOG), 2016
work page 2016
-
[19]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Burigede liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. InICLR, 2021. 10
work page 2021
-
[20]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019
work page 2019
-
[21]
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.NeurIPS, 2022
work page 2022
-
[22]
Transolver++: An accurate neural solver for pdes on million-scale geometries
Huakun Luo, Haixu Wu, Hang Zhou, Lanxiang Xing, Yichen Di, Jianmin Wang, and Mingsheng Long. Transolver++: An accurate neural solver for pdes on million-scale geometries. InICML, 2025
work page 2025
-
[23]
Automotive crash dynamics modeling accelerated with machine learning
Mohammad Amin Nabian, Sudeep Chavare, Deepak Akhare, Rishikesh Ranade, Ram Cherukuri, and Srinivas Tadepalli. Automotive crash dynamics modeling accelerated with machine learning. arXiv preprint arXiv:2510.15201, 2025
-
[24]
Smooth minimization of non-smooth functions.Mathematical Programming, 2005
Yurii Nesterov. Smooth minimization of non-smooth functions.Mathematical Programming, 2005
work page 2005
-
[25]
Robert Nowak. Generalized binary search. InAnnu. Allert. Conf. Commun. Control Comput., 2008
work page 2008
-
[26]
Adam Paszke, S. Gross, Francisco Massa, A. Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Z. Lin, N. Gimelshein, L. Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learn...
work page 2019
-
[27]
Searching for Activation Functions
Prajit Ramachandran, Barret Zoph, and Quoc V Le. Searching for activation functions.arXiv preprint arXiv:1710.05941, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Christian P Robert, George Casella, and George Casella.Monte Carlo statistical methods, volume 2. Springer, 2004
work page 2004
-
[29]
Latent ordinary differential equations for irregularly-sampled time series.NeurIPS, 2019
Yulia Rubanova, Ricky TQ Chen, and David K Duvenaud. Latent ordinary differential equations for irregularly-sampled time series.NeurIPS, 2019
work page 2019
-
[30]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[31]
Super-convergence: Very fast training of neural networks using large learning rates
Leslie N Smith and Nicholay Topin. Super-convergence: Very fast training of neural networks using large learning rates. InArtificial intelligence and machine learning for multi-domain operations applications. SPIE, 2019
work page 2019
-
[32]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models.ICML, 2023
work page 2023
-
[33]
The stochastic finite element method: past, present and future.CMAME, 2009
George Stefanou. The stochastic finite element method: past, present and future.CMAME, 2009
work page 2009
-
[34]
Scientific discovery in the age of artificial intelligence.Nature, 2023
Hanchen Wang, Tianfan Fu, Yuanqi Du, Wenhao Gao, Kexin Huang, Ziming Liu, Payal Chandak, Shengchao Liu, Peter Van Katwyk, Andreea Deac, et al. Scientific discovery in the age of artificial intelligence.Nature, 2023
work page 2023
-
[35]
Transolver: A fast transformer solver for pdes on general geometries
Haixu Wu, Huakun Luo, Haowen Wang, Jianmin Wang, and Mingsheng Long. Transolver: A fast transformer solver for pdes on general geometries. InICML, 2024
work page 2024
-
[36]
Geopt: Scaling physics simulation via lifted geometric pre-training
Haixu Wu, Minghao Guo, Zongyi Li, Zhiyang Dou, Mingsheng Long, Kaiming He, and Wojciech Matusik. Geopt: Scaling physics simulation via lifted geometric pre-training. In ICML, 2026
work page 2026
-
[37]
Transolver-3: Scaling Up Transformer Solvers to Industrial-Scale Geometries,
Hang Zhou, Haixu Wu, Haonan Shangguan, Yuezhou Ma, Huikun Weng, Jianmin Wang, and Mingsheng Long. Transolver-3: Scaling up transformer solvers to industrial-scale geometries. arXiv preprint arXiv:2602.04940, 2026. 11 A Proof of Main Text This section provides proofs for propositions and theorems in the main text. A.1 Proof of Proposition 2 Proof.We fixxth...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.