Recognition: 1 theorem link
· Lean TheoremMuonQ: Enhancing Low-Bit Muon Quantization via Directional Fidelity Optimization
Pith reviewed 2026-05-13 02:07 UTC · model grok-4.3
The pith
MuonQ enables stable 4-bit quantization of the Muon optimizer by optimizing directional fidelity to match full-precision performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
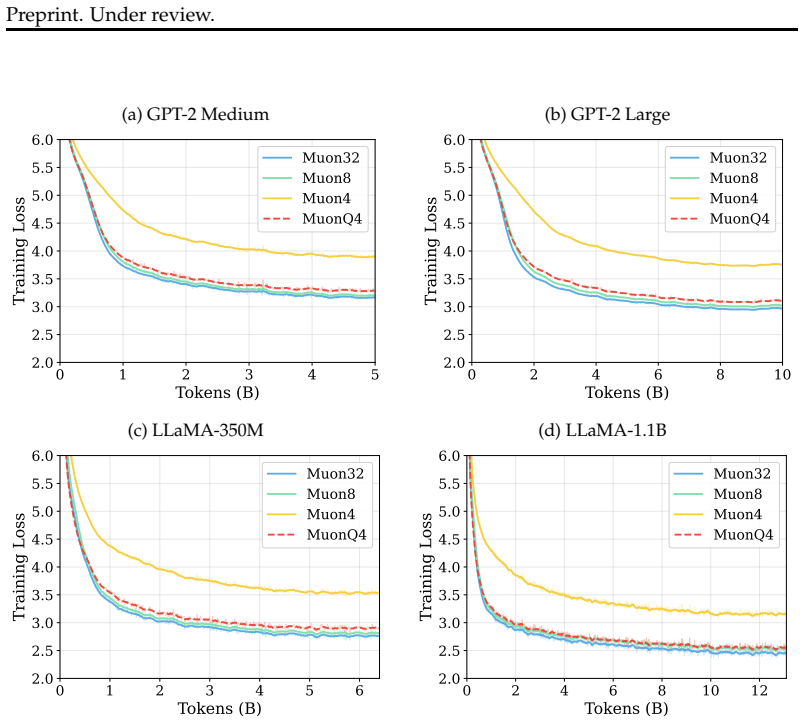
By applying directional fidelity optimization consisting of pre-quantization normalization, power iteration decomposition, and μ-law companding quantization, Muon optimizer states can be quantized to 4 bits while preserving the directional information required for effective updates. Pre-training experiments on GPT-style and LLaMA-style models confirm that this yields training loss and downstream task accuracy comparable to full-precision Muon, with optimizer state memory reduced by up to 7.3 times.
What carries the argument
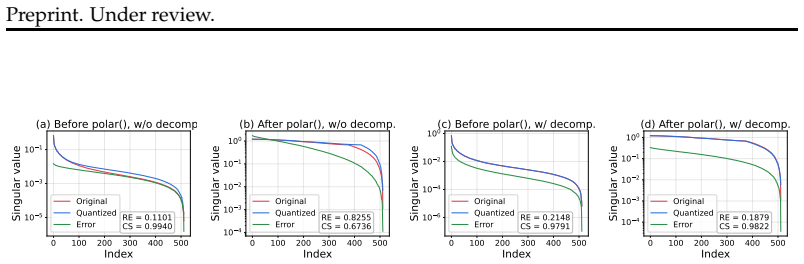
Directional fidelity optimization, which protects singular vector directions during quantization by normalizing error magnitudes, decomposing via power iteration, and using μ-law companding for dense-value resolution.
If this is right
- 4-bit Muon training becomes viable for GPT-style and LLaMA-style pre-training with no measurable degradation in loss or task accuracy.
- Optimizer state memory usage drops by a factor of up to 7.3 times compared with full-precision storage.
- Large language models can be trained under tighter GPU memory limits while retaining the computational advantages of Muon.
- The quantization approach maintains the orthogonalization benefits of Muon without amplifying directional errors.
Where Pith is reading between the lines
- The same directional preservation tactics could be tested on other optimizers that rely on orthogonalization or direction-only updates.
- Further scaling experiments would be needed to check whether accumulated quantization effects remain negligible beyond the tested model sizes.
- Combining MuonQ with gradient or weight quantization schemes could produce additional memory savings in end-to-end low-bit pipelines.
Load-bearing premise
The three directional fidelity techniques preserve Muon's original training dynamics without introducing instabilities or biases that would only appear at larger scales or on untested model architectures.
What would settle it
If 4-bit MuonQ training on a model substantially larger than those tested produces noticeably higher loss or lower downstream accuracy than full-precision Muon, the claim of close matching would be falsified.
Figures










read the original abstract
The Muon optimizer has emerged as a compelling alternative to Adam for training large language models, achieving remarkable computational savings through gradient orthogonalization. However, Muon's optimizer state is more sensitive to quantization errors: because the orthogonalization discards the magnitudes of singular values and retains only directional information, even small quantization errors in singular vector directions are amplified in the update. In this work, we propose MuonQ, a low-bit Muon training framework built on the principle of directional fidelity optimization. First, we apply a pre-quantization normalization so that each step introduces quantization errors of the same magnitude, preventing the accumulated error from developing a preferred direction. Second, we introduce a structural decomposition that separately quantizes the dominant singular components via power iteration, ensuring that quantization errors perturb only singular value magnitudes rather than rotating singular vector directions. Third, we adopt $\mu$-law companding quantization to allocate higher resolution to densely packed momentum values, shifting the quantization objective from outlier preservation to dense-region distinguishability. Together, these techniques enable stable 4-bit quantization of Muon's optimizer states. Pre-training experiments on GPT-style and LLaMA-style models demonstrate that MuonQ at 4-bit precision closely matches full-precision Muon in both training loss and downstream task accuracy, while reducing optimizer state memory by up to 7.3 $\times$. Our code is available at https://github.com/YupengSu/MuonQ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MuonQ, a 4-bit quantization framework for the Muon optimizer based on directional fidelity optimization. It introduces three techniques: pre-quantization normalization to equalize per-step error magnitudes, power-iteration decomposition to quantize dominant singular components separately (preserving vector directions), and μ-law companding to allocate bits to dense momentum regions. Pre-training results on GPT-style and LLaMA-style models are reported to show that 4-bit MuonQ matches full-precision Muon in training loss and downstream accuracy while cutting optimizer-state memory by up to 7.3×. Code is released.
Significance. If the matching performance holds under rigorous controls, the work would be significant for memory-constrained training of large models, as Muon’s orthogonalization makes its state unusually sensitive to directional quantization noise. The open-source code is a clear strength that aids verification. The result is currently limited by the absence of scale, horizon, and ablation details needed to confirm that the techniques prevent compounding directional errors.
major comments (2)
- [Abstract] Abstract: the claim that 4-bit MuonQ “closely matches” full-precision Muon in loss and accuracy provides no model sizes, training-step counts, number of runs, or quantitative deltas; without these, it is impossible to assess whether the three directional-fidelity techniques actually keep per-step perturbations small enough that Muon’s orthogonalization does not amplify them over realistic horizons.
- [Abstract] Abstract: no ablation or scaling analysis is described that isolates the contribution of pre-quantization normalization, power-iteration decomposition, or μ-law companding, nor tests whether residual directional bias remains non-compounding at larger widths, depths, or step counts; this directly bears on the central assertion that the techniques preserve training dynamics.
minor comments (1)
- [Abstract] The abstract states a 7.3× memory reduction but does not explicitly tie the factor to the 4-bit setting or report the precise baseline (e.g., FP16 vs. FP32 optimizer state).
Simulated Author's Rebuttal
We appreciate the referee's feedback highlighting the need for greater specificity in the abstract and additional analysis to support our claims. We provide point-by-point responses below and will make revisions to the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 4-bit MuonQ “closely matches” full-precision Muon in loss and accuracy provides no model sizes, training-step counts, number of runs, or quantitative deltas; without these, it is impossible to assess whether the three directional-fidelity techniques actually keep per-step perturbations small enough that Muon’s orthogonalization does not amplify them over realistic horizons.
Authors: We agree that the abstract would be strengthened by including more concrete experimental details. While the abstract provides a high-level overview, the full manuscript in Section 4 details the model architectures (GPT-style and LLaMA-style), training durations, run counts, and quantitative results including loss values and accuracy metrics that demonstrate the close matching. We will revise the abstract to incorporate model sizes, training step counts, number of runs, and example quantitative deltas to better allow assessment of the directional fidelity techniques. revision: yes
-
Referee: [Abstract] Abstract: no ablation or scaling analysis is described that isolates the contribution of pre-quantization normalization, power-iteration decomposition, or μ-law companding, nor tests whether residual directional bias remains non-compounding at larger widths, depths, or step counts; this directly bears on the central assertion that the techniques preserve training dynamics.
Authors: We acknowledge that the abstract does not explicitly describe ablations or scaling analyses. The manuscript motivates each technique and presents overall results showing stable training dynamics. To directly address the isolation of contributions from pre-quantization normalization, power-iteration decomposition, and μ-law companding, as well as to test for non-compounding directional bias at larger scales, we will include a new ablation study and scaling experiments in the revised version. This will provide evidence that the techniques preserve training dynamics over extended horizons. revision: yes
Circularity Check
No circularity; empirical validation of proposed quantization techniques
full rationale
The paper proposes three practical techniques (pre-quantization normalization to equalize error magnitudes, power-iteration decomposition to protect singular-vector directions, and μ-law companding to improve dense-region resolution) for 4-bit Muon optimizer states. These are introduced as engineering choices motivated by the sensitivity of Muon's orthogonalization to directional errors, then validated directly via pre-training runs on GPT-style and LLaMA-style models that report matching loss curves and downstream accuracy. No equations, first-principles derivations, or parameter-fitting steps are presented that reduce to self-definitions, fitted inputs renamed as predictions, or self-citation chains. The central claim therefore rests on external experimental evidence rather than any internal reduction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Singular value decomposition and its approximation via power iteration are valid for decomposing optimizer states.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearpre-quantization normalization so that each step introduces quantization errors of the same magnitude... structural decomposition that separately quantizes the dominant singular components via power iteration... μ-law companding quantization
Reference graph
Works this paper leans on
-
[1]
Dion: Distributed orthonormalized updates.arXiv preprint arXiv:2504.05295, 2025
Kwangjun Ahn, Byron Xu, Natalie Abreu, Ying Fan, Gagik Magakyan, Pratyusha Sharma, Zheng Zhan, and John Langford. Dion: Distributed orthonormalized updates.arXiv preprint arXiv:2504.05295,
-
[2]
Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325,
-
[3]
Thibaut Boissin, Thomas Massena, Franck Mamalet, and Mathieu Serrurier. Turbo-muon: Accelerating orthogonality-based optimization with pre-conditioning.arXiv preprint arXiv:2512.04632,
-
[4]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), ...
work page 2019
-
[5]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Association for Computational Linguistics. Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
Scaling Laws for Neural Language Models
URL https://kellerjordan.github.io/posts/muon/. Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[8]
Normuon: Making muon more efficient and scalable.arXiv preprint arXiv:2510.05491, 2025
Zichong Li, Liming Liu, Chen Liang, Weizhu Chen, and Tuo Zhao. NorMuon: Making muon more efficient and scalable.arXiv preprint arXiv:2510.05491,
-
[9]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, et al. Muon is scalable for LLM training.arXiv preprint arXiv:2502.16982,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2381–2391, Brussels, Belgium,
work page 2018
-
[11]
Association for Computational Linguistics. doi: 10.18653/v1/ D18-1260. Guilherme Penedo, Hynek Kydl´ıˇcek, Loubna Ben Allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro von Werra, and Thomas Wolf. The FineWeb datasets: Decanting the web for the finest text data at scale.arXiv preprint arXiv:2406.17557,
-
[12]
Noam Shazeer and Mitchell Stern
doi: 10.1145/3474381. Noam Shazeer and Mitchell Stern. Adafactor: Adaptive learning rates with sublinear memory cost. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pp. 4596–4604. PMLR,
-
[13]
Pushing the limits of low-bit optimizers: A focus on EMA dynamics.arXiv preprint arXiv:2505.00347,
Cong Xu, Wenbin Liang, Mo Yu, et al. Pushing the limits of low-bit optimizers: A focus on EMA dynamics.arXiv preprint arXiv:2505.00347,
-
[14]
HellaSwag: Can a Machine Really Finish Your Sentence?
Association for Computational Linguistics. doi: 10.18653/v1/P19-1472. Ruijie Zhang, Yequan Zhao, Ziyue Liu, Zhengyang Wang, and Zheng Zhang. Muon+: To- wards better muon via one additional normalization step.arXiv preprint arXiv:2602.21545,
-
[15]
12 Preprint. Under review. A Training Details A.1 Model Architectures We evaluate on two model families. Table 5 summarizes the architecture configurations. Family Modeld model nlayer nhead dffn Vocab Context GPT-2 Small 768 12 12 3072 50257 1024 Medium 1024 24 16 4096 50257 4096 Large 1280 36 20 5120 50257 8192 LLaMA 350M 1024 24 16 2736 32000 4096 1.1B ...
work page 2048
-
[16]
con- tains a single hyperparameter µ that controls the degree of nonlinear compression. Following the convention in signal processing, we search over values of the form 2 n − 1 (i.e., 15, 63, 127, 255, 511, 1023), which correspond to the maximum representable integer under n-bit encoding and are the standard choices in ITU-T companding specifications (ITU...
work page 1988
-
[17]
that replaces the deterministic round(·) oper- ator with a randomized variant: for a value z, it rounds down to ⌊z⌋ with probability ⌈z⌉ −z and up to ⌈z⌉ with probability z− ⌊z⌋ . Un- like deterministic rounding, stochastic round- ing is unbiased in expectation, which has been shown to prevent systematic error accumula- tion in gradient-based optimization...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.