Recognition: 2 theorem links
· Lean TheoremOn the Approximation Complexity of Matrix Product Operator Born Machines
Pith reviewed 2026-05-13 01:52 UTC · model grok-4.3
The pith
Matrix product operator Born machines cannot efficiently approximate arbitrary continuous distributions because KL minimization is NP-hard, yet they succeed with polynomial resources for structured targets under suitable conditions on the诱导
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KL approximation is NP-hard for MPO-BMs in the continuous setting, ruling out universal efficient approximation in the worst case. Under locality and spectral-gap conditions on the loss-induced Hamiltonian, structured targets admit MPO-BM approximations with polynomial bond dimension and provable KL guarantees. Under the same locality structure, polynomially many score queries suffice to estimate the induced Hamiltonian and obtain such guarantees.
What carries the argument
The loss-induced Hamiltonian together with its locality and spectral-gap properties, which determine whether an MPO-BM of polynomial bond dimension can achieve a provable KL bound for a given target.
If this is right
- Path-graph Markov random fields and similar structured distributions admit MPO-BM approximations whose bond dimension scales only polynomially with system size.
- The resulting approximations come with explicit, non-vacuous bounds on the Kullback-Leibler divergence.
- The loss-induced Hamiltonian can be estimated to sufficient accuracy using only polynomially many evaluations of the score function.
- Score-based variational inference therefore inherits efficient learnability whenever the target satisfies the stated locality structure.
Where Pith is reading between the lines
- The hardness result implies that MPO-BMs are unlikely to serve as black-box approximators for generic high-dimensional continuous data without additional structural assumptions.
- In applied settings one could first test whether a candidate loss produces a local gapped Hamiltonian before committing to an MPO-BM architecture.
- Analogous complexity separations may exist for other tensor-network architectures used in probabilistic modeling.
Load-bearing premise
The positive approximation results require that the loss-induced Hamiltonian is both local and has a spectral gap.
What would settle it
An explicit family of continuous targets whose loss-induced Hamiltonians are local and gapped yet require super-polynomial bond dimension for any fixed KL error would falsify the positive claim; a polynomial-time algorithm that finds near-optimal MPO-BMs for arbitrary continuous targets would falsify the hardness claim.
Figures

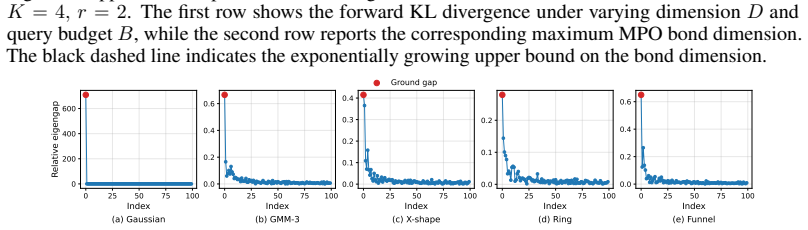






read the original abstract
Matrix product operator Born machines (MPO-BMs) are tractable tensor-network models for probabilistic modeling, but their efficient approximation capability remains unclear. We characterize this boundary from both negative and positive perspectives. First, we prove that KL approximation is NP-hard for MPO-BMs in the continuous setting, ruling out universal efficient approximation in the worst case. Second, for score-based variational inference, we show that, under a locality and spectral-gap conditions on the loss-induced Hamiltonian, structured targets (e.g., path-graph Markov random fields) admit MPO-BM approximations with polynomial bond dimension and provable KL guarantees. Third, under the same locality structure, we prove that polynomially many score queries suffice to estimate the induced Hamiltonian and obtain such guarantees. Our results provide a theoretical characterization of when MPO-BMs are fundamentally hard to approximate and when they become efficiently learnable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper characterizes the approximation complexity of Matrix Product Operator Born Machines (MPO-BMs) for probabilistic modeling. It proves that KL approximation is NP-hard in the continuous setting. For score-based variational inference, under locality and spectral-gap conditions on the loss-induced Hamiltonian, structured targets (e.g., path-graph MRFs) admit MPO-BM approximations with polynomial bond dimension and provable KL guarantees. It further shows that polynomially many score queries suffice to estimate the induced Hamiltonian under the same locality structure.
Significance. If the central claims hold, the work provides a useful theoretical boundary between worst-case hardness and conditional tractability for MPO-BMs, which is significant for tensor-network approaches to density estimation and variational inference. The combination of an unconditional NP-hardness result with conditional positive guarantees (including query complexity) offers a balanced characterization that could guide future model design.
major comments (2)
- [Positive results on structured targets] Positive results section (abstract and main theorem on structured targets): The polynomial bond dimension and KL guarantees for targets such as path-graph MRFs are conditioned on the loss-induced Hamiltonian satisfying both locality and a spectral gap. The manuscript does not derive or verify that these conditions hold for the claimed examples; without this step the positive claims are unsupported and the approximation bounds become uncontrolled.
- [Hamiltonian estimation] Section on Hamiltonian estimation from score queries: The claim that polynomially many score queries suffice to recover the induced Hamiltonian (and thereby the KL guarantees) is stated under the same locality structure, but the precise dependence of the sample complexity on the bond dimension and gap parameters is not made explicit, making it difficult to assess whether the overall procedure remains polynomial for the targeted structured distributions.
minor comments (2)
- [Abstract] Abstract: 'a locality and spectral-gap conditions' should read 'locality and spectral-gap conditions' for grammatical consistency.
- [Notation] Notation for the loss-induced Hamiltonian should be introduced with a clear equation reference when first used in the positive-results section to improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading of our manuscript and for the constructive feedback. We appreciate the positive assessment of the overall contribution and the balanced view of the hardness and tractability results. We address each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Positive results on structured targets] Positive results section (abstract and main theorem on structured targets): The polynomial bond dimension and KL guarantees for targets such as path-graph MRFs are conditioned on the loss-induced Hamiltonian satisfying both locality and a spectral gap. The manuscript does not derive or verify that these conditions hold for the claimed examples; without this step the positive claims are unsupported and the approximation bounds become uncontrolled.
Authors: We agree that an explicit verification strengthens the positive results. The main theorem is stated conditionally on locality and a spectral gap of the loss-induced Hamiltonian. For the illustrative example of path-graph MRFs, locality follows directly from the underlying Markov random field structure (nearest-neighbor interactions induce a local Hamiltonian). In the revision we will add a short derivation showing that, for bounded pairwise potentials on a path graph, the induced Hamiltonian remains local with interaction range independent of system size. We will also note that a uniform spectral gap can be guaranteed under standard assumptions (e.g., ferromagnetic or weakly interacting regimes) by appealing to known results on one-dimensional Ising-type models; when the gap is bounded away from zero the polynomial bond-dimension bound remains controlled. This addition will make the concrete applicability to path-graph MRFs fully rigorous. revision: yes
-
Referee: [Hamiltonian estimation] Section on Hamiltonian estimation from score queries: The claim that polynomially many score queries suffice to recover the induced Hamiltonian (and thereby the KL guarantees) is stated under the same locality structure, but the precise dependence of the sample complexity on the bond dimension and gap parameters is not made explicit, making it difficult to assess whether the overall procedure remains polynomial for the targeted structured distributions.
Authors: We thank the referee for highlighting the need for explicit dependence. The current argument shows that, under locality, the number of score queries needed to estimate the Hamiltonian to sufficient accuracy is polynomial in the system size. In the revision we will insert the precise scaling: the query complexity is O(n^3 D^2 / (γ^2 ε^2)) (up to logarithmic factors), where n is the number of sites, D the bond dimension, γ the spectral gap, and ε the target accuracy. For the structured targets where D and 1/γ are polynomial in n (or constant), the overall procedure therefore remains polynomial. This explicit bound will allow readers to verify that the end-to-end learning pipeline stays efficient precisely when the locality and gap conditions hold. revision: yes
Circularity Check
No significant circularity; results are conditional proofs under explicit assumptions
full rationale
The paper establishes NP-hardness of KL approximation for MPO-BMs in the continuous case via direct proof, then gives conditional positive results (polynomial bond dimension and KL bounds) only when locality and spectral-gap conditions hold on the loss-induced Hamiltonian. These conditions are stated as assumptions rather than derived from the target result or fitted to data. No self-definitional loops, no parameters fitted on a subset and renamed as predictions, and no load-bearing self-citations that reduce the central claim to prior unverified work by the same authors. The derivation chain remains self-contained against external mathematical benchmarks once the stated assumptions are granted; the fact that the paper does not prove the assumptions hold for every example (e.g., path-graph MRFs) is a limitation on applicability, not a circularity in the logic itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Locality condition on the loss-induced Hamiltonian
- domain assumption Spectral-gap condition on the loss-induced Hamiltonian
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
under a locality and spectral-gap conditions on the loss-induced Hamiltonian, structured targets admit MPO-BM approximations with polynomial bond dimension
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KL approximation is NP-hard for MPO-BMs in the continuous setting
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Uncertainty in artificial intelligence , pages=
Tensor-train density estimation , author=. Uncertainty in artificial intelligence , pages=. 2021 , organization=
work page 2021
-
[2]
International Conference on Artificial Intelligence and Statistics , pages=
Tensor networks for probabilistic sequence modeling , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
work page 2021
-
[3]
Journal of Machine Learning Research , volume=
Matrix product states for inference in discrete probabilistic models , author=. Journal of Machine Learning Research , volume=
-
[4]
2009 17th European Signal Processing Conference , pages=
Probabilistic non-negative tensor factorization using Markov chain Monte Carlo , author=. 2009 17th European Signal Processing Conference , pages=. 2009 , organization=
work page 2009
-
[5]
The rotation of eigenvectors by a perturbation. III , author=. SIAM Journal on Numerical Analysis , volume=. 1970 , publisher=
work page 1970
-
[6]
American Journal of Mathematics , volume=
Logarithmic sobolev inequalities , author=. American Journal of Mathematics , volume=. 1975 , publisher=
work page 1975
-
[7]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[8]
Batch and match: black-box variational inference with a score-based divergence , author=
-
[9]
Advances in Neural Information Processing Systems , volume=
Variational inference with Gaussian score matching , author=. Advances in Neural Information Processing Systems , volume=
- [10]
-
[11]
From probabilistic graphical models to generalized tensor networks for supervised learning , author=. IEEE Access , volume=. 2020 , publisher=
work page 2020
-
[12]
Advances in neural information processing systems , volume=
A tensorized transformer for language modeling , author=. Advances in neural information processing systems , volume=
-
[13]
Generative learning of continuous data by tensor networks , author=. SciPost Physics , volume=
-
[14]
arXiv preprint arXiv:2304.05305 , year=
Generative modeling via hierarchical tensor sketching , author=. arXiv preprint arXiv:2304.05305 , year=
-
[15]
Applied and Computational Harmonic Analysis , volume=
Generative modeling via tensor train sketching , author=. Applied and Computational Harmonic Analysis , volume=. 2023 , publisher=
work page 2023
-
[16]
Generative tensor network classification model for supervised machine learning , author=. Physical Review B , volume=. 2020 , publisher=
work page 2020
-
[17]
Information perspective to probabilistic modeling: Boltzmann machines versus born machines , author=. Entropy , volume=. 2018 , publisher=
work page 2018
-
[18]
International Workshop on Active Inference , pages=
Learning generative models for active inference using tensor networks , author=. International Workshop on Active Inference , pages=. 2022 , organization=
work page 2022
-
[19]
Machine Learning: Science and Technology , volume=
Plastic tensor networks for interpretable generative modeling , author=. Machine Learning: Science and Technology , volume=. 2026 , publisher=
work page 2026
-
[20]
Probabilistic modeling with matrix product states , author=. Entropy , volume=. 2019 , publisher=
work page 2019
-
[21]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Recent advances for quantum neural networks in generative learning , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2023 , publisher=
work page 2023
-
[22]
arXiv preprint arXiv:2501.18691 , year=
Regularized second-order optimization of tensor-network Born machines , author=. arXiv preprint arXiv:2501.18691 , year=
-
[23]
Sequence processing with quantum-inspired tensor networks , author=. Scientific Reports , volume=. 2025 , publisher=
work page 2025
-
[24]
Supervised learning with projected entangled pair states , author=. Physical Review B , volume=. 2021 , publisher=
work page 2021
-
[25]
Tensor networks for unsupervised machine learning , author=. Physical Review E , volume=. 2023 , publisher=
work page 2023
-
[26]
2019 International Joint Conference on Neural Networks (IJCNN) , pages=
Tensor ring restricted Boltzmann machines , author=. 2019 International Joint Conference on Neural Networks (IJCNN) , pages=. 2019 , organization=
work page 2019
-
[27]
IEEE Transactions on Big Data , year=
Term model: Tensor ring mixture model for density estimation , author=. IEEE Transactions on Big Data , year=
-
[28]
Tree tensor networks for generative modeling , author=. Physical Review B , volume=. 2019 , publisher=
work page 2019
-
[29]
Unsupervised generative modeling using matrix product states , author=. Physical Review X , volume=. 2018 , publisher=
work page 2018
-
[30]
Physical Review Research , volume=
Using matrix-product states for time-series machine learning , author=. Physical Review Research , volume=. 2025 , publisher=
work page 2025
-
[31]
TRANSACTIONS ON MACHINE LEARNING RESEARCH , year=
What is the Relationship between Tensor Factorizations and Circuits (and How Can We Exploit it)? , author=. TRANSACTIONS ON MACHINE LEARNING RESEARCH , year=
-
[32]
Advances in neural information processing systems , volume=
Expressive power of tensor-network factorizations for probabilistic modeling , author=. Advances in neural information processing systems , volume=
-
[33]
arXiv preprint arXiv:2510.22138 , year=
Tractable Shapley Values and Interactions via Tensor Networks , author=. arXiv preprint arXiv:2510.22138 , year=
-
[34]
Advances in Neural Information Processing Systems , volume=
Chen, Zhuo and Dangovski, Rumen and Loh, Charlotte and Dugan, Owen and Luo, Di and Solja. Advances in Neural Information Processing Systems , volume=
-
[35]
Journal of Machine Learning Research , volume=
Tensor regression networks , author=. Journal of Machine Learning Research , volume=. 2020 , publisher=
work page 2020
-
[36]
Advances in Neural Information Processing Systems , pages=
Tensorizing neural networks , author=. Advances in Neural Information Processing Systems , pages=
-
[37]
SIAM Journal on Scientific Computing , volume=
Tensor-train decomposition , author=. SIAM Journal on Scientific Computing , volume=. 2011 , publisher=
work page 2011
-
[38]
Matrix Product State Representations
Matrix product state representations , author=. arXiv preprint quant-ph/0608197 , year=
-
[39]
Tensor networks for dimensionality reduction and large-scale optimization: Part 2 applications and future perspectives , author=. Foundations and Trends. 2017 , publisher=
work page 2017
-
[40]
Tensor decompositions and applications , author=. SIAM review , volume=. 2009 , publisher=
work page 2009
-
[41]
An introduction to matrix concentration inequalities , author=. Foundations and trends. 2015 , publisher=
work page 2015
-
[42]
Area Laws and Tensor Networks for Maximally Mixed Ground States: I. Arad, R. Firanko, R. Jain , author=. Communications in Mathematical Physics , volume=. 2026 , publisher=
work page 2026
-
[43]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
On the Hardness of Approximating Distributions with Tractable Probabilistic Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[44]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Sum of squares circuits , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[45]
Advances in Neural Information Processing Systems , volume=
EigenVI: score-based variational inference with orthogonal function expansions , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.