Recognition: 2 theorem links
· Lean TheoremEfficient Adjoint Matching for Fine-tuning Diffusion Models
Pith reviewed 2026-05-13 01:48 UTC · model grok-4.3
The pith
By reformulating the stochastic optimal control problem with linear base drift, Efficient Adjoint Matching speeds up reward fine-tuning of diffusion models up to 4x while matching performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EAM reformulates the stochastic optimal control problem for reward fine-tuning by replacing the pretrained model's non-trivial base drift with linear base drift and introducing a correspondingly modified terminal cost. The new formulation supports training-time sampling with a few-step deterministic ODE solver and supplies a closed-form adjoint solution that removes the need for backward simulation along each trajectory.
What carries the argument
Reformulation of the SOC problem to linear base drift with modified terminal cost, which removes full stochastic trajectory sampling and backward adjoint ODE integration.
Load-bearing premise
That replacing the pretrained model's non-trivial drift with linear base drift plus a modified terminal cost still solves the original alignment objective without adding bias or losing solution quality.
What would settle it
A side-by-side run on the same text-to-image reward benchmarks where EAM reaches lower final scores on PickScore, ImageReward, or HPSv2.1 than standard Adjoint Matching after the same number of steps.
Figures




read the original abstract
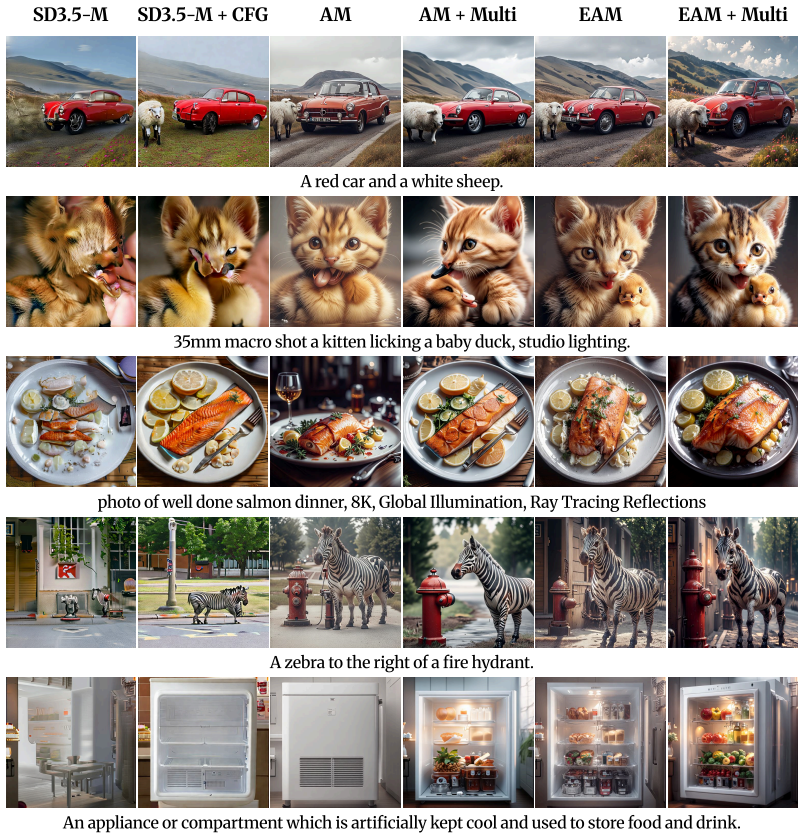
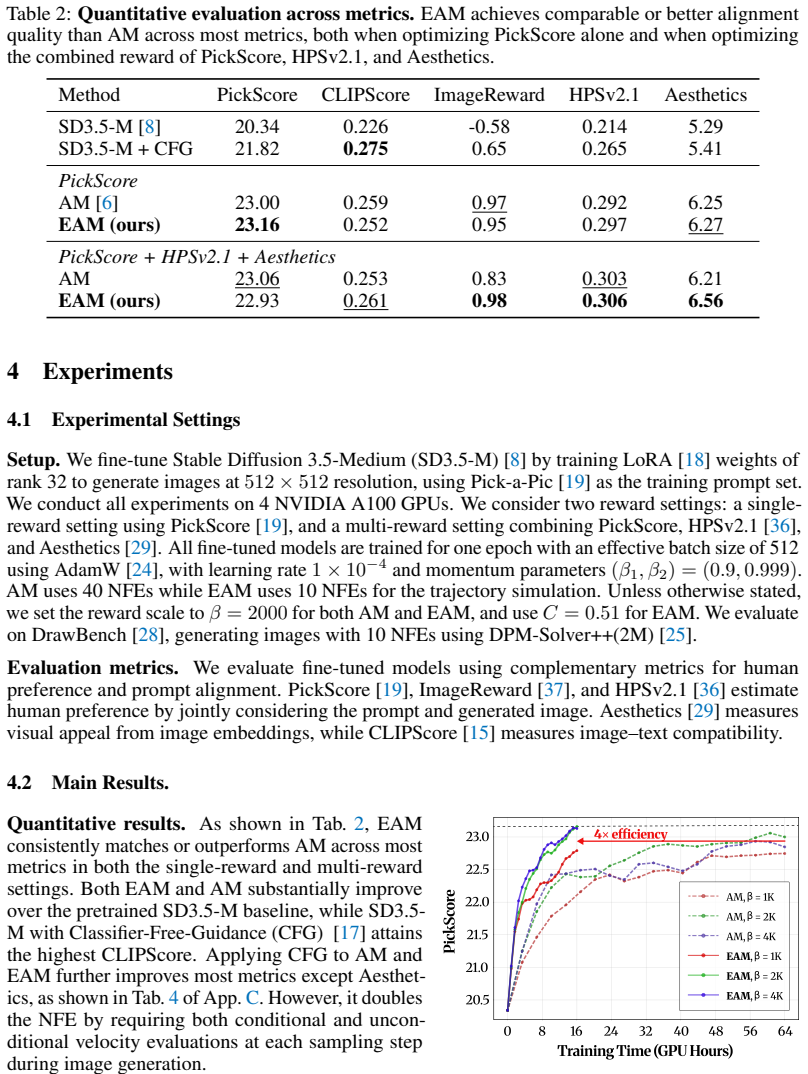
Reward fine-tuning has become a common approach for aligning pretrained diffusion and flow models with human preferences in text-to-image generation. Among reward-gradient-based methods, Adjoint Matching (AM) provides a principled formulation by casting reward fine-tuning as a stochastic optimal control (SOC) problem. However, AM inevitably requires a substantial computational cost: it requires (i) stochastic simulation of full generative trajectories under memoryless dynamics, resulting in a large number of function evaluations, and (ii) backward ODE simulation of the adjoint state along each sampled trajectory. In this work, we observe that both bottlenecks are closely tied to the \textit{non-trivial base drift} inherited from the pretrained model. Motivated by this observation, we propose \textbf{Efficient Adjoint Matching (EAM)}, which substantially improves training efficiency by reformulating the SOC problem with a \textit{linear base drift} and a correspondingly modified \textit{terminal cost}. This reformulation removes both sources of inefficiency; it enables training-time sampling with a few-step deterministic ODE solver and yields a closed-form adjoint solution that eliminates backward adjoint simulation. On standard text-to-image reward fine-tuning benchmarks, EAM converges up to 4x faster than AM and matches or surpasses it across various metrics including PickScore, ImageReward, HPSv2.1, CLIPScore and Aesthetics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Efficient Adjoint Matching (EAM) for reward fine-tuning of pretrained diffusion and flow models. It reformulates the stochastic optimal control (SOC) problem underlying Adjoint Matching (AM) by replacing the pretrained model's non-linear base drift with a linear one and adjusting the terminal cost accordingly. This enables few-step deterministic ODE sampling at training time and a closed-form adjoint solution, removing the need for stochastic trajectory simulation and backward adjoint ODE integration. On standard text-to-image benchmarks, EAM is reported to converge up to 4x faster than AM while matching or exceeding it on PickScore, ImageReward, HPSv2.1, CLIPScore, and Aesthetics.
Significance. If the reformulation is mathematically equivalent to the original AM objective, the work would offer a practical advance in computational efficiency for preference alignment of generative models, addressing the high cost of full-trajectory stochastic simulation and adjoint integration that currently limits adjoint-based fine-tuning methods.
major comments (2)
- [§3] §3 (reformulation of the SOC problem): The central claim that switching to linear base drift plus modified terminal cost preserves the original alignment objective and solution quality is not supported by a derivation showing exact compensation for the drift change under the pretrained noise schedule and score function. Without this, the observed metric parity could arise from optimization on a surrogate rather than faithful recovery of AM's optimum.
- [§4.2, Table 2] §4.2 and Table 2 (experimental results): The ablation on sampling steps and convergence speed does not include a direct comparison (e.g., KL divergence or reward distribution distance) between the EAM-learned policy and the original AM solution; this measurement is necessary to confirm that the 4x speedup does not come at the cost of a different alignment distribution.
minor comments (2)
- [§3.1] Notation for the linear drift term is introduced without explicit connection to standard linear SDE forms (e.g., Ornstein-Uhlenbeck), which may reduce accessibility for readers familiar with diffusion literature.
- [Figure 4] The convergence curves in Figure 4 would be clearer with shaded variance bands from multiple random seeds to substantiate the robustness of the reported speedups.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we respond point-by-point to the major comments, clarifying the mathematical basis of the reformulation and addressing the experimental validation. We indicate where revisions will be incorporated.
read point-by-point responses
-
Referee: [§3] §3 (reformulation of the SOC problem): The central claim that switching to linear base drift plus modified terminal cost preserves the original alignment objective and solution quality is not supported by a derivation showing exact compensation for the drift change under the pretrained noise schedule and score function. Without this, the observed metric parity could arise from optimization on a surrogate rather than faithful recovery of AM's optimum.
Authors: We thank the referee for this important point. In §3 the reformulation is obtained by substituting the linear base drift into the SOC objective and deriving the compensating adjustment to the terminal cost so that the resulting value function (and therefore the optimal policy) remains identical to that of the original AM problem. The compensation is exact because the difference in the controlled probability paths induced by the drift change is fully absorbed into the modified terminal cost under the fixed pretrained noise schedule; the score function of the pretrained model enters only through the original dynamics and is unchanged. To eliminate any ambiguity we will expand the derivation in the revised §3 with an explicit step-by-step expansion showing the cancellation of the drift-induced terms, thereby confirming that EAM recovers the same alignment objective. revision: yes
-
Referee: [§4.2, Table 2] §4.2 and Table 2 (experimental results): The ablation on sampling steps and convergence speed does not include a direct comparison (e.g., KL divergence or reward distribution distance) between the EAM-learned policy and the original AM solution; this measurement is necessary to confirm that the 4x speedup does not come at the cost of a different alignment distribution.
Authors: We agree that an explicit distributional comparison would be desirable. Direct KL divergence between the two policies is computationally intractable in the high-dimensional image space. Nevertheless, the reported metrics already demonstrate that EAM achieves parity or better performance than AM on the same reward functions that define the alignment objective. In the revised manuscript we will add, in the appendix, a side-by-side comparison of reward histograms and a few additional proxy statistics (e.g., mean and variance of the reward under both policies) on the same set of prompts to further support distributional similarity. revision: partial
Circularity Check
No significant circularity; reformulation is an explicit modeling choice with independent empirical validation
full rationale
The paper's central derivation consists of an explicit reformulation of the SOC objective that replaces the pretrained model's non-linear base drift with a linear one and adjusts the terminal cost to enable closed-form adjoint and few-step ODE sampling. This change is presented as a deliberate modeling decision motivated by computational bottlenecks, not as a derivation that reduces to its own inputs by construction. No parameters are fitted to a subset and then relabeled as predictions, no self-citations are load-bearing for uniqueness or ansatz, and the final performance claims rest on standard benchmark comparisons rather than tautological equivalence. The derivation chain therefore remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Adjoint Matching can be cast as a stochastic optimal control problem with non-trivial base drift from the pretrained model.
Reference graph
Works this paper leans on
-
[1]
M. Albergo, N. M. Boffi, and E. Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 2025
work page 2025
- [2]
-
[3]
D. Blessing, J. Berner, L. Richter, C. Domingo-Enrich, Y . Du, A. Vahdat, and G. Neumann. Trust region constrained measure transport in path space for stochastic optimal control and inference. InNeurIPS, 2025
work page 2025
-
[4]
J. Choi, Y . Zhu, W. Guo, P. Molodyk, B. Yuan, J. Bai, Y . Xin, M. Tao, and Y . Chen. Rethinking the design space of reinforcement learning for diffusion models: On the importance of likelihood estimation beyond loss design. InICML, 2026
work page 2026
- [5]
-
[6]
C. Domingo-Enrich, M. Drozdzal, B. Karrer, and R. T. Q. Chen. Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control. InICLR, 2025
work page 2025
-
[7]
B. Efron. Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602–1614, 2011
work page 2011
- [8]
- [9]
-
[10]
Y . Fan, O. Watkins, Y . Du, H. Liu, M. Ryu, C. Boutilier, P. Abbeel, M. Ghavamzadeh, K. Lee, and K. Lee. DPOK: Reinforcement learning for fine-tuning text-to-image diffusion models. InNeurIPS, 2023
work page 2023
-
[11]
W. Guo, J. Choi, Y . Zhu, M. Tao, and Y . Chen. Proximal diffusion neural sampler. InICML, 2026
work page 2026
-
[12]
X. Guo, M. Cui, L. Bo, and D. Huang. ShortFT: Diffusion model alignment via shortcut-based fine-tuning. InICCV, 2025
work page 2025
- [13]
-
[14]
X. He, S. Fu, Y . Zhao, W. Li, J. Yang, D. Yin, F. Rao, and B. Zhang. TempFlow-GRPO: When timing matters for grpo in flow models. InICLR, 2026
work page 2026
- [15]
-
[16]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InNeurIPS, 2020
work page 2020
-
[17]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans. Classifier-free diffusion guidance.arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InICLR, 2022
work page 2022
-
[19]
Y . Kirstain, A. Polyak, U. Singer, S. Matiana, J. Penna, and O. Levy. Pick-a-Pic: An open dataset of user preferences for text-to-image generation. InNeurIPS, 2023
work page 2023
- [20]
-
[21]
G.-H. Liu, J. Choi, Y . Chen, B. K. Miller, and R. T. Q. Chen. Adjoint schrödinger bridge sampler. In NeurIPS, 2025
work page 2025
-
[22]
J. Liu, G. Liu, J. Liang, Y . Li, J. Liu, X. Wang, P. Wan, D. Zhang, and W. Ouyang. Flow-GRPO: Training flow matching models via online rl. InNeurIPS, 2025
work page 2025
-
[23]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023. 10
work page 2023
-
[24]
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InICLR, 2019
work page 2019
-
[25]
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, and J. Zhu. DPM-Solver++: Fast solver for guided sampling of diffusion probabilistic models.Machine Intelligence Research, 2025
work page 2025
-
[26]
M. Prabhudesai, A. Goyal, D. Pathak, and K. Fragkiadaki. Aligning text-to-image diffusion models with reward backpropagation.arXiv:2310.03739, 2024
-
[27]
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
work page 2022
-
[28]
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans, J. Ho, D. Fleet, and M. Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. InNeurIPS, 2022
work page 2022
- [29]
-
[30]
Y . Shi, V . De Bortoli, A. Campbell, and A. Doucet. Diffusion schrödinger bridge matching. InNeurIPS, 2023
work page 2023
-
[31]
J. Shin, J. Sul, J. Lee, J. Choi, and J. Choi. Efficient generative modeling beyond memoryless diffusion via adjoint schrödinger bridge matching. InICML, 2026
work page 2026
-
[32]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations. InICLR, 2021
work page 2021
- [33]
-
[34]
Y . Wang, Z. Li, Y . Zang, Y . Zhou, J. Bu, C. Wang, Q. Lu, C. Jin, and J. Wang. Pref-GRPO: Pairwise preference reward-based grpo for stable text-to-image reinforcement learning.arXiv:2508.20751, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
X. Wu, Y . Hao, M. Zhang, K. Sun, Z. Huang, G. Song, Y . Liu, and H. Li. Deep reward supervisions for tuning text-to-image diffusion models. InECCV, 2024
work page 2024
-
[36]
X. Wu, K. Sun, F. Zhu, R. Zhao, and H. Li. Human preference score: Better aligning text-to-image models with human preference. InICCV, 2023
work page 2023
-
[37]
J. Xu, X. Liu, Y . Wu, Y . Tong, Q. Li, M. Ding, J. Tang, and Y . Dong. ImageReward: Learning and evaluating human preferences for text-to-image generation. InNeurIPS, 2023
work page 2023
- [38]
-
[39]
Z. Xue, J. Wu, Y . Gao, F. Kong, L. Zhu, M. Chen, Z. Liu, W. Liu, Q. Guo, W. Huang, and P. Luo. DanceGRPO: Unleashing grpo on visual generation.arXiv:2505.07818, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [40]
-
[41]
H. Zhao, H. Chen, J. Zhang, D. D. Yao, and W. Tang. Score as action: Fine-tuning diffusion generative models by continuous-time reinforcement learning. InICML, 2025
work page 2025
-
[42]
K. Zheng, H. Chen, H. Ye, H. Wang, Q. Zhang, K. Jiang, H. Su, S. Ermon, J. Zhu, and M.-Y . Liu. DiffusionNFT: Online diffusion reinforcement with forward process. InICLR, 2026. 11 Appendix A Impact Satement This work develops computational methods for reward-based fine-tuning of diffusion models. Our study is theoretical and computational in nature and us...
work page 2026
-
[43]
(41) yields the announced family D(t) = 2Ct2 −1 t(2Ct 2 −2t+ 1) , C > 1 2 ,(44) which is Eq
Substituting this It into Eq. (41) yields the announced family D(t) = 2Ct2 −1 t(2Ct 2 −2t+ 1) , C > 1 2 ,(44) which is Eq. (15). Step 5: the second constraint is automatic.Using the explicit forms of It, Φt = (2C− 1)t/(2Ct 2 −2t+ 1) , and Jt =I 1 −I t Φ2 t , a direct computation (using ¯αt = Φ0Jt/(ΦtI1) and γ2 t = 2I tJt/I1) verifies that ¯α2 t +γ 2 t = (...
-
[44]
(39) therefore imposes no additional restriction onD(t)
The second constraint in Eq. (39) therefore imposes no additional restriction onD(t). ii Step 6: terminal distribution.At t= 1 , Φ0 is the value of Φ at t= 0 , which evaluates to Φ0 = 0 (since the numerator (2C−1)t vanishes at t= 0 ). Hence ¯α1 = 0, and X1 = ¯β1X1 +γ 1 ε marginalizes (usingX 0 ∼ N(0, I)and ¯β1 = 1) to pbase 1 =N 0,(2C−1)I ,(45) sinceI 1 =...
-
[45]
Exact adjoint calculation.Plugging the linear base drift in Eq
The family is therefore unique up to the single scalarC. Exact adjoint calculation.Plugging the linear base drift in Eq. (15) into Eq. (10) yields a(t;X t) = (2C−1)t 2Ct2 −2t+ 1 a(1;X 1), a(1;X 1) =∇g(X 1).(46) B.4 Proof of Proposition 3.2 We use the standard SOC reduction for reward-tilted sampling [6, 13]: under the SOC problem (4)– (5) with terminal co...
work page 2000
-
[46]
in this section. CFG is known to improve alignment between the generated image and the text prompt, but this comes at the cost of doubled NFEs required to compute the unconditional prediction. As shown in Tab. 4, applying CFG improves improves all the metrics except Aesthetics. D Additional Qualitative Examples iv S D 3 . 5 S D 3 . 5 + C F G A M A M + M u...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.