Recognition: no theorem link
Multi-Narrow Transformation as a Single-Model Ensemble: Boundary Conditions, Mechanisms, and Failure Modes
Pith reviewed 2026-05-13 01:11 UTC · model grok-4.3
The pith
Converting CNN capacity into many narrow independent branches improves accuracy in low-data settings but reverses when data is abundant.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
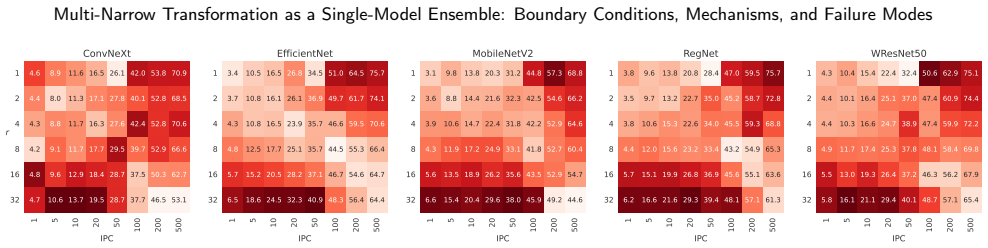
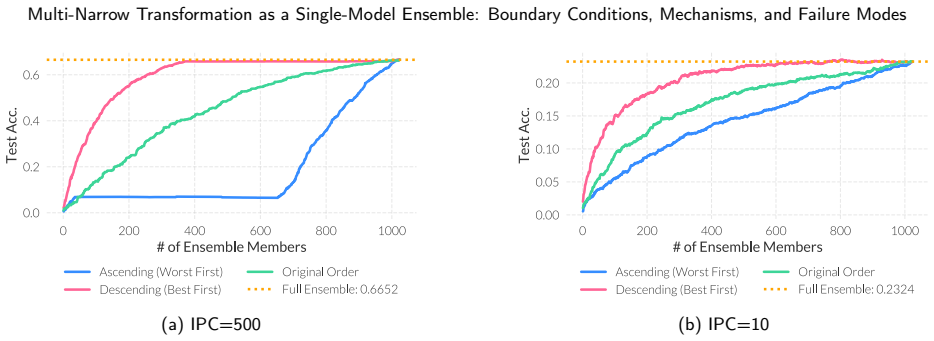
The Multi-Narrow transformation restructures a baseline CNN into an SME consisting of narrow, path-wise independent branches while keeping the dominant parameter count approximately constant. Direct comparisons across training-data regimes demonstrate that effectiveness is strongly data-dependent: weakly partitioned or baseline-wide models are preferable with abundant data, whereas highly partitioned MN models consistently outperform the baseline under low-data conditions. This advantage is reproduced across multiple CNN architectures and image-classification datasets. Representation analysis shows that high-MN models learn more diverse and less redundant path-wise features; in low-data the全
What carries the argument
Multi-Narrow (MN) transformation: the operation that converts a baseline CNN into multiple narrow, path-wise independent branches while preserving the overall parameter budget.
If this is right
- Highly partitioned MN configurations are preferable for image-classification tasks with limited training data.
- Increased diversity among path-wise representations is utilized broadly in low-data regimes to improve generalization.
- In data-rich regimes, prediction collapses to a small subset of paths, rendering extra partitioning counterproductive.
- The data-dependent preference for width versus multiplicity holds across multiple CNN architectures and standard image datasets.
- Model-capacity allocation should therefore be chosen according to the size of the training set under a fixed parameter budget.
Where Pith is reading between the lines
- Routine application of MN partitioning could be a low-cost way to boost performance on small or imbalanced datasets without adding parameters.
- Techniques that encourage uniform path utilization, such as auxiliary losses, might remove the performance reversal observed in high-data regimes.
- Testing whether the same width-versus-multiplicity trade-off appears in non-vision domains such as language or audio models would clarify how general the mechanism is.
Load-bearing premise
That greater measured diversity among the independent paths is the direct cause of better generalization in low-data regimes rather than a side effect of the partitioning procedure itself.
What would settle it
Train an MN model on a low-data image benchmark, then force all paths to share the same weights after the first layer and verify whether accuracy falls back to the level of the single-wide baseline.
Figures




read the original abstract
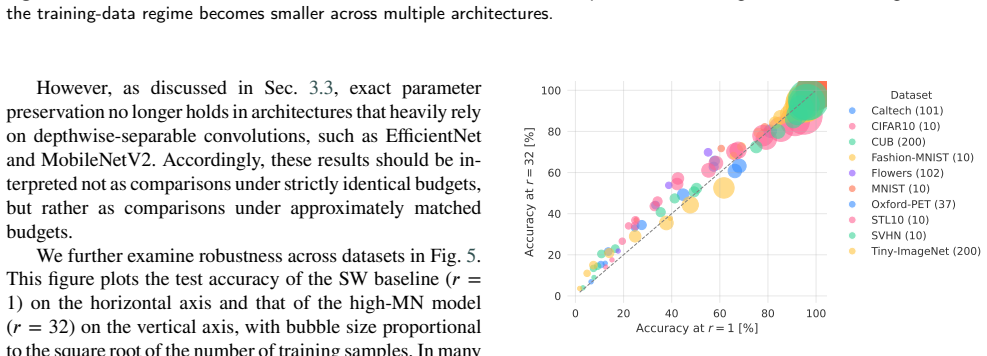
Single-model ensembles (SMEs) have attracted attention as a way to approximate some of the benefits of deep ensembles within a single network. However, under an approximately matched parameter budget, it remains unclear whether model capacity should be concentrated in a single wide pathway or redistributed into many narrow and independent members. We investigate this question through the Multi-Narrow (MN) transformation, which converts a baseline CNN into an SME of narrow, path-wise independent branches while approximately preserving the dominant parameter budget. We systematically compare Single-Wide and Multi-Narrow configurations across different training-data regimes, architectures, and datasets. The results show that the effectiveness of MN is strongly data-dependent: weakly partitioned or baseline-wide models are preferable in data-rich settings, whereas highly partitioned MN models consistently outperform the baseline in low-data settings. This tendency is reproduced across multiple CNN architectures and image-classification datasets, suggesting that it is not specific to a single benchmark or model family. Analysis of internal representations shows that high-MN models learn more diverse and less redundant path-wise features. In low-data regimes, this diversity is broadly utilized and improves generalization, whereas in data-rich regimes, training becomes imbalanced and prediction is dominated by a small subset of paths. These findings clarify when and why Multi-Narrow transformation is effective, and provide practical guidance for allocating model capacity between width and member multiplicity under a limited budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Multi-Narrow (MN) transformation, which converts a baseline CNN into a single-model ensemble of narrow, path-wise independent branches while approximately preserving the parameter budget. Systematic comparisons of Single-Wide versus Multi-Narrow configurations across training-data regimes, architectures, and image-classification datasets show that highly partitioned MN models outperform the baseline in low-data settings, whereas weakly partitioned or baseline-wide models are preferable in data-rich settings. Representation analysis indicates that MN models learn more diverse path-wise features; this diversity is broadly utilized in low-data regimes to improve generalization but leads to imbalanced training and dominance by few paths in high-data regimes.
Significance. If the empirical trends hold under more rigorous quantification, the work offers practical guidance for allocating model capacity between width and multiplicity under fixed budgets, particularly favoring MN in low-data regimes. The reproduction across multiple CNN families and datasets is a strength, as is the attempt to link observed diversity patterns to data-dependent performance.
major comments (2)
- [Experimental results and abstract] The central empirical claim of consistent MN outperformance in low-data regimes lacks quantitative effect sizes, statistical tests, exact partitioning details, or diversity quantification methods. This is load-bearing for the data-dependent boundary conditions asserted in the abstract and results.
- [Mechanism and failure modes analysis] The mechanism analysis reports higher path-wise diversity and its utilization in low-data settings but provides only correlational evidence from representation analysis. No ablation or intervention holds MN topology fixed while modulating diversity (or vice versa), so it remains unclear whether diversity, rather than incidental effects of partitioning such as regularization or gradient flow, drives the gains.
minor comments (2)
- Clarify the precise definition of 'low-data' versus 'high-data' regimes, including specific sample counts or fractions used in the experiments.
- Provide more explicit details on how the dominant parameter budget is matched between Single-Wide and Multi-Narrow configurations, including any approximations or adjustments made.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our empirical claims and the strength of our mechanistic analysis. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Experimental results and abstract] The central empirical claim of consistent MN outperformance in low-data regimes lacks quantitative effect sizes, statistical tests, exact partitioning details, or diversity quantification methods. This is load-bearing for the data-dependent boundary conditions asserted in the abstract and results.
Authors: We agree that the results section would benefit from more precise quantification. In the revised manuscript we will add: (i) effect sizes reported as mean accuracy differences with standard deviations across at least five random seeds; (ii) statistical significance tests (paired t-tests or Wilcoxon signed-rank tests) comparing MN and baseline configurations in each data regime; (iii) explicit statements of the partitioning scheme (number of paths and per-path width multiplier) for every architecture and dataset; and (iv) the exact diversity metric (average pairwise cosine similarity of path-wise activation vectors) together with its computation details. These additions will be placed in the main results tables and a new subsection on quantification methods. The abstract’s high-level claims will remain unchanged because the underlying trends are robust, but the supporting numbers will now be directly visible. revision: yes
-
Referee: [Mechanism and failure modes analysis] The mechanism analysis reports higher path-wise diversity and its utilization in low-data settings but provides only correlational evidence from representation analysis. No ablation or intervention holds MN topology fixed while modulating diversity (or vice versa), so it remains unclear whether diversity, rather than incidental effects of partitioning such as regularization or gradient flow, drives the gains.
Authors: We acknowledge that the current evidence linking path-wise diversity to performance is correlational. The representation analysis shows systematically higher diversity in high-MN models, broad utilization of that diversity under low-data regimes, and the complementary failure mode of path dominance under high-data regimes. These patterns are reproducible across architectures and datasets, which we view as supporting (though not causal) evidence for the claimed boundary conditions. We will expand the discussion to explicitly list alternative explanations (regularization, gradient flow, effective depth) and to state the correlational limitation. However, performing new interventions that hold topology fixed while independently controlling diversity would require additional experimental designs and compute that exceed the scope of the present study; we therefore propose such ablations as future work rather than part of the revision. revision: partial
- Performing controlled ablations that hold MN topology fixed while modulating diversity independently to establish causality.
Circularity Check
No circularity: purely empirical comparisons with no derivations or fitted predictions
full rationale
The paper conducts systematic empirical comparisons of Single-Wide vs. Multi-Narrow CNN configurations across data regimes, architectures, and datasets, reporting performance differences and correlational observations from representation analysis. No equations, first-principles derivations, parameter fits presented as predictions, or self-citation chains are present in the abstract or described claims. All results are externally falsifiable via replication on the stated benchmarks, with no reduction of outputs to inputs by construction. The central findings remain independent of any internal definitional loops.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard CNN training with SGD and data augmentation produces comparable optimization dynamics across wide and partitioned configurations.
Reference graph
Works this paper leans on
-
[1]
Ashukha,A.,Lyzhov,A.,Molchanov,D.,Vetrov,D.,2020. Pitfallsof in-domain uncertainty estimation and ensembling in deep learning, in: International Conference on Learning Representations. URL: https://openreview.net/forum?id=BJxI5gHKDr
work page 2020
-
[2]
Group ensemble: Learning an ensemble of convnets in a single convnet
Chen, H., Shrivastava, A., 2020. Group ensemble: Learning an ensemble of convnets in a single convnet. URL:https://arxiv.org/ abs/2007.00649,arXiv:2007.00649
-
[3]
Chen, H., Yao, X., 2009. Regularized negative correlation learning forneuralnetworkensembles.IEEETransactionsonNeuralNetworks 20, 1962–1979. doi:10.1109/TNN.2009.2034144
-
[4]
Chirkova, N., Lobacheva, E., Vetrov, D., 2020. Deep ensembles on a fixed memory budget: One wide network or several thinner ones? URL:https://arxiv.org/abs/2005.07292,arXiv:2005.07292
-
[5]
Ensemblingwithafixedparameterbudget: When does it help and why?, in: Balasubramanian, V.N., Tsang, I
Deng,D.,Shi,E.B.,2021. Ensemblingwithafixedparameterbudget: When does it help and why?, in: Balasubramanian, V.N., Tsang, I. (Eds.), Proceedings of The 13th Asian Conference on Machine Learning, PMLR. pp. 1176–1191. URL:https://proceedings.mlr. press/v157/deng21a.html
work page 2021
-
[6]
Dutt,A.,Pellerin,D.,Quénot,G.,2018. Coupledensemblesofneural networks, in: 2018 International Conference on Content-Based Mul- timedia Indexing (CBMI), pp. 1–6. doi:10.1109/CBMI.2018.8516453
-
[7]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Goyal, P., Dollár, P., Girshick, R., Noordhuis, P., Wesolowski, L., Kyrola, A., Tulloch, A., Jia, Y., He, K., 2018. Accurate, large minibatch sgd: Training imagenet in 1 hour. URL:https://arxiv. org/abs/1706.02677,arXiv:1706.02677
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Easy Ensemble: Simple Deep Ensemble Learning for Sensor-Based Human Activity Recognition
Hasegawa, T., Kondo, K., 2023. Easy Ensemble: Simple Deep Ensemble Learning for Sensor-Based Human Activity Recognition. IEEE Internet of Things Journal 10, 5506–5518
work page 2023
-
[9]
Deep Residual Learning for Image Recognition , isbn =
He, K., Zhang, X., Ren, S., Sun, J., 2016. Deep Residual Learning for Image Recognition, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778. doi:10.1109/CVPR.2016.90
-
[10]
Jeffares, A., Liu, T., Crabbé, J., van der Schaar, M., 2023. Joint training of deep ensembles fails due to learner collusion, in: Thirty- seventhConferenceonNeuralInformationProcessingSystems.URL: https://openreview.net/forum?id=WpGLxnOWhn
work page 2023
-
[11]
Similarity of Neural Network Representations Revisited
Kornblith, S., Norouzi, M., Lee, H., Hinton, G., 2019. Similarity of Neural Network Representations Revisited, in: Proceedings of the 36th International Conference on Machine Learning (ICML), pp. 3519–3529. doi:10.48550/arXiv.1905.00414
-
[12]
Lakshminarayanan, B., Pritzel, A., Blundell, C., 2017. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles, in: Advances in Neural Information Processing Systems (NeurIPS), pp. 6402–6413
work page 2017
-
[13]
Lan,X.,Zhu,X.,Gong,S.,2018.Knowledgedistillationbyon-the-fly nativeensemble,in:Proceedingsofthe32ndInternationalConference on Neural Information Processing Systems, Curran Associates Inc., Red Hook, NY, USA. p. 7528–7538
work page 2018
-
[14]
Laurent, O., Lafage, A., Tartaglione, E., Daniel, G., marc Martinez, J., Bursuc, A., Franchi, G., 2023. Packed ensembles for efficient uncertainty estimation, in: The Eleventh International Conference on Learning Representations. URL:https://openreview.net/forum?id= XXTyv1zD9zD
work page 2023
-
[15]
Lin, Z.S., Tseng, L.Y., Lai, W.S., 2024. Toward Better Accuracy- EfficiencyTrade-Offs:DivideandCo-Training,in:Proceedingsofthe IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp. 1898–1908. doi:10.1109/WACV57701.2024.00188. Tatsuhito Hasegawa and Taisei Tanaka:Preprint submitted to ElsevierPage 11 of 12 Multi-Narrow Transformation as...
-
[16]
Ensemble learning via negative correlation
Liu, Y., Yao, X., 1999. Ensemble learning via negative correlation. Neural Networks 12, 1399–1404. URL:https://www.sciencedirect. com/science/article/pii/S0893608099000738,doi:https://doi.org/10. 1016/S0893-6080(99)00073-8
work page 1999
-
[17]
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.,
-
[18]
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection , isbn =
A ConvNet for the 2020s, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11976–11986. doi:10.1109/CVPR52688.2022.01167
-
[19]
Loshchilov, I., Hutter, F., 2017. SGDR: Stochastic gradient descent with warm restarts, in: International Conference on Learning Repre- sentations. URL:https://openreview.net/forum?id=Skq89Scxx
work page 2017
-
[20]
Decoupled weight decay regulariza- tion,in:InternationalConferenceonLearningRepresentations
Loshchilov, I., Hutter, F., 2019. Decoupled weight decay regulariza- tion,in:InternationalConferenceonLearningRepresentations. URL: https://openreview.net/forum?id=Bkg6RiCqY7
work page 2019
-
[21]
Dying relu and initialization: Theory and numerical examples
Lu, L., Shin, Y., Su, Y., Em Karniadakis, G., 2020. Dying relu and initialization: Theory and numerical examples. Communications in Computational Physics 28, 1671–1706. URL:http://dx.doi.org/10. 4208/cicp.OA-2020-0165, doi:10.4208/cicp.oa-2020-0165
-
[22]
Ortega, L.A., Cabañas, R., Masegosa, A., 2022. Diversity and gen- eralization in neural network ensembles, in: Camps-Valls, G., Ruiz, F.J.R., Valera, I. (Eds.), Proceedings of The 25th International Con- ference on Artificial Intelligence and Statistics, PMLR. pp. 11720– 11743. URL:https://proceedings.mlr.press/v151/ortega22a.html
work page 2022
-
[23]
Radosavovic,I.,Kosaraju,R.P.,Girshick,R.,He,K.,Dollár,P.,2020. DesigningNetworkDesignSpaces,in:ProceedingsoftheIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10428–10436. doi:10.1109/CVPR42600.2020.01044
-
[24]
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C.,
-
[25]
In: CVPR (2018),https://doi.org/10.1109/CVPR.2018
MobileNetV2: Inverted Residuals and Linear Bottlenecks, in: Proceedings of the IEEE/CVF Conference on Computer Vision and PatternRecognition(CVPR),pp.4510–4520. doi:10.1109/CVPR.2018. 00474
-
[26]
Smith, S.L., Kindermans, P.J., Le, Q.V., 2018. Don’t decay the learning rate, increase the batch size, in: International Conference on Learning Representations. URL:https://openreview.net/forum?id= B1Yy1BxCZ
work page 2018
-
[27]
Tan, M., Le, Q.V., 2019. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, in: Proceedings of the 36th International Conference on Machine Learning (ICML), pp. 6105– 6114
work page 2019
-
[28]
Wang, S., Chen, H., Yao, X., 2010. Negative correlation learning for classificationensembles,in:The2010InternationalJointConference on Neural Networks (IJCNN), pp. 1–8. doi:10.1109/IJCNN.2010. 5596702
-
[29]
Webb, A., Reynolds, C., Chen, W., Reeve, H., Iliescu, D., Luján, M., Brown, G., 2020. To ensemble or not ensemble: When does end-to- end training fail?, in: Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2020, Ghent, Belgium, September 14–18, 2020, Proceedings, Part III, Springer- Verlag, Berlin, Heidelberg. p. 109–1...
-
[30]
Wood,D.,Mu,T.,Webb,A.M.,Reeve,H.W.J.,Luján,M.,Brown,G.,
-
[31]
Journal of MachineLearningResearch24,1–49
A unified theory of diversity in ensemble learning. Journal of MachineLearningResearch24,1–49. URL:http://jmlr.org/papers/ v24/23-0041.html
-
[32]
Peer collaborative learning for online knowledge distillation
Wu, G., Gong, S., 2021. Peer collaborative learning for online knowledge distillation. Proceedings of the AAAI Conference on ArtificialIntelligence35,10302–10310.URL:https://ojs.aaai.org/ index.php/AAAI/article/view/17234, doi:10.1609/aaai.v35i12.17234
-
[33]
In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pp
Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K., 2017. Aggregated ResidualTransformationsforDeepNeuralNetworks,in:Proceedings oftheIEEEConferenceonComputerVisionandPatternRecognition (CVPR), pp. 5987–5995. doi:10.1109/CVPR.2017.634
-
[34]
Wide Residual Networks, in: Proceedings of the British Machine Vision Conference (BMVC), pp
Zagoruyko, S., Komodakis, N., 2016. Wide Residual Networks, in: Proceedings of the British Machine Vision Conference (BMVC), pp. 87.1–87.12. doi:10.5244/C.30.87
-
[35]
Deep negative correlation classification
Zhang, L., Hou, Q., Liu, Y., Bian, J.W., Xu, X., Zhou, J.T., Zhu, C., 2024. Deep negative correlation classification. Ma- chine Learning 113, 7223–7241. URL:https://doi.org/10.1007/ s10994-024-06604-0, doi:10.1007/s10994-024-06604-0
-
[36]
Nonlinear regression via deep negative correlation learning
Zhang, L., Shi, Z., Cheng, M.M., Liu, Y., Bian, J.W., Zhou, J.T., Zheng, G., Zeng, Z., 2021. Nonlinear regression via deep negative correlation learning. IEEE Transactions on Pattern Analysis and Machine Intelligence 43, 982–998. doi:10.1109/TPAMI.2019.2943860
-
[37]
Zhang, Y., Xiang, T., Hospedales, T.M., Lu, H., 2018. Deep mutual learning,in:ProceedingsoftheIEEEConferenceonComputerVision and Pattern Recognition (CVPR). Tatsuhito Hasegawareceived the Ph.D. de- gree in engineering from Kanazawa University, Kanazawa, in 2015. From 2011 to 2013, he was a System Engineer with Fujitsu Hokuriku Systems Ltd. From 2014 to 20...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.