Recognition: no theorem link
Fast MoE Inference via Predictive Prefetching and Expert Replication
Pith reviewed 2026-05-13 02:20 UTC · model grok-4.3
The pith
Predicting overloaded experts and replicating them lets MoE models run tokens in parallel and reach near-full GPU use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that a dynamic expert replication strategy, driven by predictions of which experts will be overloaded, allows replicated experts to handle batch tokens concurrently across layers. This produces near-complete GPU utilization, up to 3x faster inference, and retention of 90-95 percent of baseline performance on Switch-base-128 and Switch-base-256 models.
What carries the argument
Dynamic expert replication strategy that predicts overloaded experts and duplicates them for concurrent processing.
If this is right
- GPU utilization reaches approximately 100 percent.
- Inference speed increases by up to 3 times over the baseline.
- Model performance remains at 90-95 percent of the unreplicated version.
- Replicated experts process tokens concurrently to shorten idle periods.
- The method scales to large MoE models such as Switch-base-128 and Switch-base-256.
Where Pith is reading between the lines
- The same prediction-plus-replication pattern might reduce latency in other sparse-activation networks that suffer load imbalance.
- Combining the replication decisions with hardware-aware scheduling could further cut memory overhead on specific GPUs.
- Over time, accurate expert-usage predictors may become a standard runtime component rather than a training-time concern.
- The approach leaves open whether replication decisions can be learned jointly with the base model to improve both accuracy and speed.
Load-bearing premise
The prediction model must be accurate enough on real workloads that the cost of creating and running replicated experts stays smaller than the gains from extra parallelism.
What would settle it
Measure inference time and GPU utilization on a new MoE model and workload where the overload predictor is replaced with random guesses; if speed falls below the unreplicated baseline, the claim does not hold.
Figures





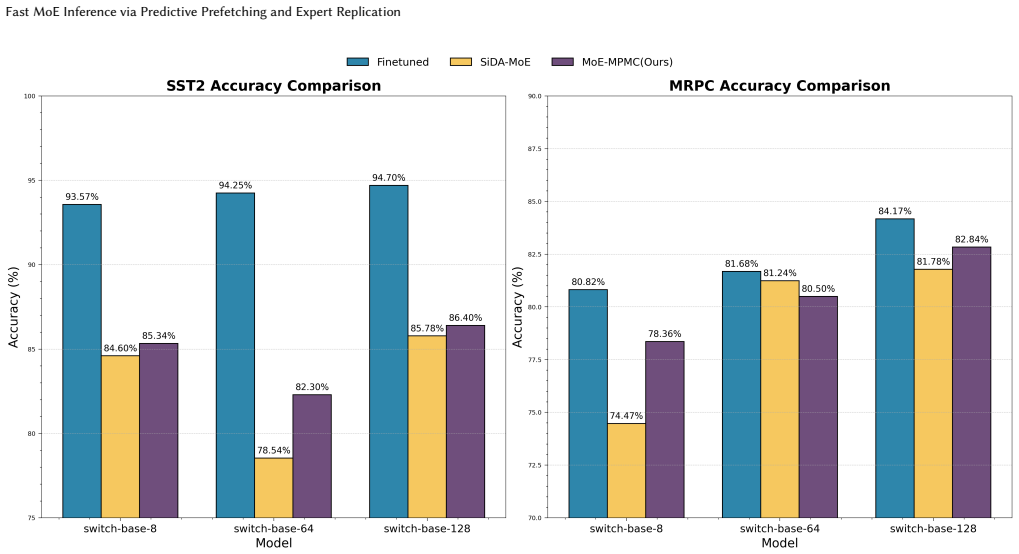


read the original abstract
The Mixture of Experts (MoE) architecture has become a fundamental building block in state-of-the-art large language models (LLMs), improving domain-specific expertise in LLMs and scaling model capacity without proportionally increasing their computational overhead. However, MoE inference often suffers from suboptimal GPU utilization, load imbalance, and elevated latency arising from multiple tokens waiting on the same experts for their computation which arises from sparsity of expert activation. To address these challenges, we propose a dynamic expert replication strategy that predicts which experts are likely to be overloaded and replicates them for upcoming batches of tokens. The replicated experts process batch tokens concurrently across layers, which leads to improved parallelism, shorter GPU idle time, and significantly faster inference. Experimental evaluations conducted on large-scale MoE models, including Switch-base-128 and Switch-base-256, demonstrate that our method achieves near-complete GPU utilization (approx 100%), leading to upto 3x improvement in inference speed while preserving approximately 90-95% of the performance of baseline architectures
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a dynamic expert replication strategy for Mixture of Experts (MoE) inference that predicts overloaded experts and replicates them to enable concurrent processing across layers. It reports experimental results on Switch-base-128 and Switch-base-256 models claiming near-100% GPU utilization, up to 3x inference speedup, and preservation of 90-95% of baseline performance.
Significance. If the empirical claims are substantiated with detailed measurements, the technique could provide a practical systems optimization for reducing latency and improving utilization in large MoE deployments without requiring architectural changes to the models.
major comments (2)
- [Abstract] Abstract: the central claims of near-complete GPU utilization and up to 3x speedup are stated without any reported metrics on prediction accuracy, false-positive rates for replication decisions, or quantitative replication overhead (extra memory, communication, cache effects), which are required to confirm that overhead remains smaller than parallelism gains.
- [Abstract] Abstract: no details are provided on baseline implementations, how replication decisions are made per layer or batch, the replication decision threshold (listed as a free parameter), or statistical significance of the reported speedups, leaving the robustness of the 3x claim and 90-95% performance preservation unclear.
Simulated Author's Rebuttal
We thank the referee for their valuable feedback. We provide point-by-point responses to the major comments and will make revisions to the abstract as appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of near-complete GPU utilization and up to 3x speedup are stated without any reported metrics on prediction accuracy, false-positive rates for replication decisions, or quantitative replication overhead (extra memory, communication, cache effects), which are required to confirm that overhead remains smaller than parallelism gains.
Authors: We agree that the abstract does not include these specific supporting metrics. The manuscript body provides analysis of the prediction model, replication decisions, and associated overheads. We will revise the abstract to incorporate key quantitative results on prediction accuracy, false-positive rates, and replication overhead to better substantiate the central claims. revision: yes
-
Referee: [Abstract] Abstract: no details are provided on baseline implementations, how replication decisions are made per layer or batch, the replication decision threshold (listed as a free parameter), or statistical significance of the reported speedups, leaving the robustness of the 3x claim and 90-95% performance preservation unclear.
Authors: The baseline implementation is the standard inference procedure for the Switch Transformer models, as described in the methods section. Replication decisions are made on a per-layer and per-batch basis using the predictive model with a tunable threshold parameter. Statistical significance is addressed through multiple experimental runs. We will update the abstract to include brief descriptions of the baseline, decision-making process, and robustness measures. revision: yes
Circularity Check
No significant circularity in empirical systems technique
full rationale
The paper describes an empirical dynamic expert replication strategy for MoE inference optimization, validated experimentally on external checkpoints such as Switch-base-128 and Switch-base-256. No equations, derivations, or first-principles results are presented that reduce the claimed GPU utilization or speedups to fitted parameters or self-referential definitions by construction. The approach relies on practical prediction of overloaded experts and replication decisions, with performance claims grounded in measured outcomes rather than tautological inputs. This matches the default expectation for non-circular empirical systems work.
Axiom & Free-Parameter Ledger
free parameters (1)
- replication decision threshold
axioms (1)
- domain assumption Sparse expert activation in MoE leads to load imbalance and GPU idle time
Reference graph
Works this paper leans on
-
[1]
William B. Dolan and Chris Brockett. 2005. Automatically Constructing a Corpus of Sentential Paraphrases. InProceedings of the Third International Workshop on Paraphrasing (IWP2005). https://aclanthology.org/I05-5002/
work page 2005
-
[2]
Zhixu Du, Shiyu Li, Yuhao Wu, Xiangyu Jiang, Jingwei Sun, Qilin Zheng, Yongkai Wu, Ang Li, Hai Helen Li, and Yiran Chen. 2024. SiDA: Sparsity-Inspired Data- Aware Serving for Efficient and Scalable Large Mixture-of-Experts Models. In Proceedings of Machine Learning and Systems, P. Gibbons, G. Pekhimenko, and C. De Sa (Eds.), Vol. 6. 224–238. https://proce...
work page 2024
- [3]
-
[4]
Yongxin Guo, Zhenglin Cheng, Xiaoying Tang, Zhaopeng Tu, and Tao Lin. 2025. Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Trans- former Models. InThe Thirteenth International Conference on Learning Represen- tations. https://openreview.net/forum?id=T26f9z2rEe
work page 2025
- [5]
- [6]
-
[7]
Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long Short-Term Memory. Neural Comput.9, 8 (Nov. 1997), 1735–1780. doi:10.1162/neco.1997.9.8.1735
-
[8]
Changho Hwang, Wei Cui, Yifan Xiong, Ziyue Yang, Ze Liu, Han Hu, Zilong Wang, Rafael Salas, Jithin Jose, Prabhat Ram, HoYuen Chau, Peng Cheng, Fan Yang, Mao Yang, and Yongqiang Xiong. 2023. Tutel: Adaptive Mixture-of-Experts at Scale. InProceedings of Machine Learning and Systems, D. Song, M. Carbin, and T. Chen (Eds.), Vol. 5. Curan, 269–287. https://pro...
work page 2023
-
[9]
Ranggi Hwang, Jianyu Wei, Shijie Cao, Changho Hwang, Xiaohu Tang, Ting Cao, and Mao Yang. 2024. Pre-gated MoE: An Algorithm-System Co-Design for Fast and Scalable Mixture-of-Expert Inference . In2024 ACM/IEEE 51st An- nual International Symposium on Computer Architecture (ISCA). IEEE Computer Society, Los Alamitos, CA, USA, 1018–1031. doi:10.1109/ISCA5907...
-
[10]
Peng Jin, Bo Zhu, Li Yuan, and Shuicheng YAN. 2025. MoH: Multi-Head Attention as Mixture-of-Head Attention. https://openreview.net/forum?id=VOVFvaxgD0
work page 2025
-
[11]
Tao Lei, Yu Zhang, Sida I. Wang, Hui Dai, and Yoav Artzi. 2018. Simple Recurrent Units for Highly Parallelizable Recurrence. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii (Eds.). Association for Computational Linguistics, Brussels, Belgium, 4470–...
-
[12]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2021. {GS}hard: Scaling Giant Models with Conditional Computation and Automatic Sharding. InInternational Conference on Learning Representations. https://openreview.net/ forum?id=qrwe7XHTmYb
work page 2021
- [13]
-
[14]
Xin Lu, Yanyan Zhao, Bing Qin, Liangyu Huo, Qing Yang, and Dongliang Xu
-
[15]
InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
How does Architecture Influence the Base Capabilities of Pre-trained Language Models? A Case Study Based on FFN-Wider and MoE Transformers. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=67tRrjgzsh
- [16]
-
[17]
Xiaonan Nie, Xupeng Miao, Zilong Wang, Zichao Yang, Jilong Xue, Lingxiao Ma, Gang Cao, and Bin Cui. 2023. FlexMoE: Scaling Large-scale Sparse Pre-trained Model Training via Dynamic Device Placement.Proc. ACM Manag. Data1, 1, Article 110 (May 2023), 19 pages. doi:10.1145/3588964
-
[18]
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. 2022. DeepSpeed- MoE: Advancing Mixture-of-Experts Inference and Training to Power Next- Generation AI Scale. InProceedings of the 39th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol...
work page 2022
-
[19]
Noam Shazeer, *Azalia Mirhoseini, *Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. InInternational Conference on Learning Representations. https://openreview.net/forum?id=B1ckMDqlg
work page 2017
- [20]
-
[21]
Manning, Andrew Ng, and Christopher Potts
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. 2013. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. InProceedings of the 2013 Con- ference on Empirical Methods in Natural Language Processing, David Yarowsky, Timothy Baldwin, Anna Korhonen, Karen Livescu, and ...
work page 2013
- [22]
-
[23]
Yuanxin Wei, Jiangsu Du, Jiazhi Jiang, Xiao Shi, Xianwei Zhang, Dan Huang, Nong Xiao, and Yutong Lu. 2024. APTMoE: Affinity-Aware Pipeline Tuning for MoE Models on Bandwidth-Constrained GPU Nodes. InProceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis(Atlanta, GA, USA)(SC ’24). IEEE Press, Article 9...
- [24]
-
[25]
Yuping Yuan, Zhao You, Shulin Feng, Dan Su, Yanchun Liang, Xiaohu Shi, and Dong Yu. 2023. Compressed MoE ASR Model Based on Knowledge Distillation and Quantization. InInterspeech 2023. 3337–3341. doi:10.21437/Interspeech.2023- 2544
-
[26]
Ted Zadouri, Ahmet Üstün, Arash Ahmadian, Beyza Ermis, Acyr Locatelli, and Sara Hooker. 2024. Pushing Mixture of Experts to the Limit: Extremely Parameter Efficient MoE for Instruction Tuning. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=EvDeiLv7qc
work page 2024
-
[27]
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yan- ping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P. Xing, Joseph E. Gonzalez, and Ion Stoica. 2022. Alpa: Automating Inter- and Intra-Operator Par- allelism for Distributed Deep Learning. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX ...
work page 2022
-
[28]
Shuzhang Zhong, Ling Liang, Yuan Wang, Runsheng Wang, Ru Huang, and Meng Li. 2024. AdapMoE: Adaptive Sensitivity-based Expert Gating and Management for Efficient MoE Inference. InProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design (ICCAD ’24). ACM, 1–9. doi:10.1145/ 3676536.3676741
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.