Recognition: no theorem link
Wavelet Variance Equipartition as a Threshold for World-Model Quality and Quantum Kernel TN-Simulability
Pith reviewed 2026-05-13 01:42 UTC · model grok-4.3
The pith
The wavelet scaling exponent of 1/2 marks a sharp boundary between classically simulable and intractable quantum kernels from world-model latents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
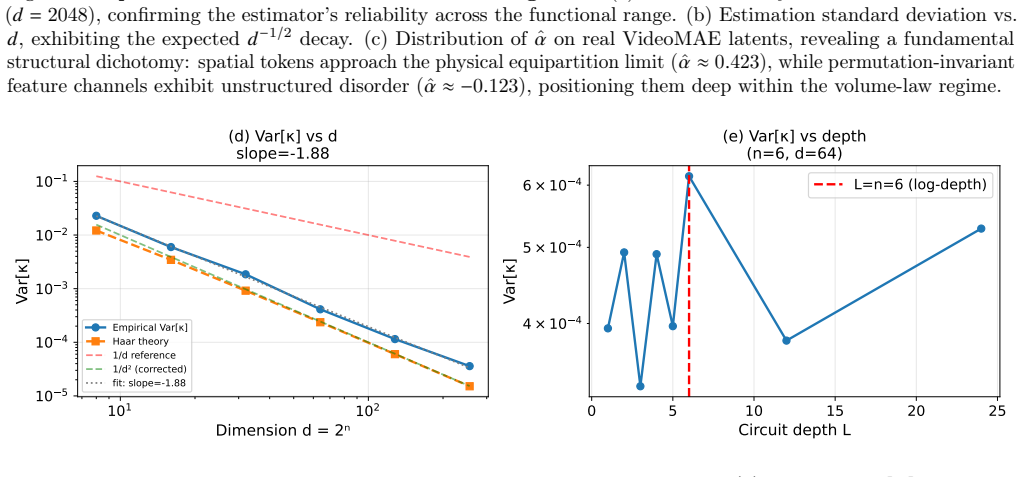
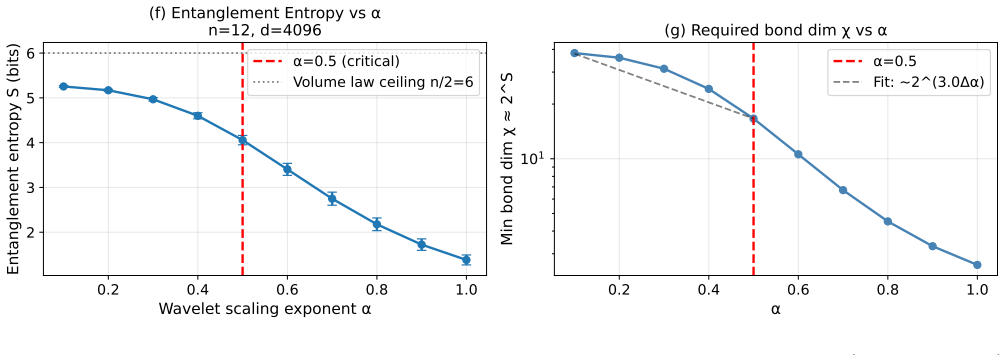
The central claim is that the wavelet scaling exponent alpha extracted from latent variables fixes the entanglement phase of the corresponding amplitude-encoded quantum kernel. When alpha exceeds 1/2 the system obeys an area law, so matrix-product-state bond dimension remains polynomial in system size and classical simulation is efficient. When alpha drops below 1/2 a volume law appears and bond dimension grows exponentially with qubit count. Pre-trained spatial tokens yield alpha approximately 0.423 while permutation-invariant channels yield alpha approximately -0.123, placing them in the hard phase. In addition the variance of scrambled transition probabilities under a 2-design ensemble is
What carries the argument
The wavelet scaling exponent alpha, which measures how variance is partitioned across frequency scales in the latent space and thereby determines whether the amplitude-encoded quantum kernel enters an area-law or volume-law entanglement regime.
If this is right
- Latents with alpha above 1/2 admit efficient classical tensor-network emulation of the quantum kernel.
- Real-world latents from models such as VideoMAE typically fall below 1/2 and therefore reside in the volume-law phase.
- The variance of transition probabilities under a 2-design ensemble scales as theta of d to the minus 2, requiring a measurement budget that grows quadratically with dimension.
- World-model training can be guided by the explicit target of reaching alpha approximately 1/2 to improve both representation quality and simulability.
Where Pith is reading between the lines
- Training routines could be adjusted to drive the scaling exponent toward the equipartition value of 1/2.
- The same wavelet diagnostic might be applied to other quantum encodings or to classical simulation of different many-body systems.
- Because the transition is claimed to be sharp, modest improvements in latent structure near the boundary could produce large gains in practical simulability.
- The criterion supplies a direct bridge between the statistical geometry of learned representations and quantum information measures of simulation hardness.
Load-bearing premise
That the wavelet scaling exponent measured on classical latents directly sets the entanglement scaling and therefore the tensor-network simulability phase of the amplitude-encoded quantum kernel.
What would settle it
Extract alpha from a set of latents, amplitude-encode them into a quantum kernel, compute the matrix-product-state representation of the resulting state, and verify whether bond dimension grows polynomially or exponentially with qubit number according to the sign of alpha minus 1/2.
Figures

read the original abstract
While world models learn compact representations of complex environments, they lack a physics-grounded metric to assess the structural fidelity of their latent spaces. We identify the wavelet scaling exponent $\alpha$ as a critical diagnostic, proposing optimal representations satisfy variance equipartition ($\alpha \approx 1/2$) -- mirroring Kolmogorov's inertial range. We establish $\alpha = 1/2$ as a sharp transition boundary for the classical simulability of amplitude-encoded quantum kernels. Using tensor-network theory, we prove latents with $\alpha > 1/2$ reside in an area-law phase admitting efficient classical emulation, while $\alpha < 1/2$ triggers a volume-law phase where the Matrix Product State bond dimension $\chi$ grows exponentially with qubit count $n$. Analyzing pre-trained VideoMAE latents reveals a dichotomy: spatial tokens approach the equipartition limit ($\alpha \approx 0.423$), but permutation-invariant feature channels exhibit unstructured disorder ($\alpha \approx -0.123$). This forces real-world latents deep into the volume-law phase, providing a data-driven necessary condition for simulation hardness. Finally, we apply Weingarten calculus to derive the exact variance of the scrambled transition probability under a 2-design ensemble. We prove this variance scales strictly as $\Var[X] = \Theta(d^{-2})$. We confirm this numerically with a log-log slope of $-1.881$ ($R^2 = 0.999$), identifying a formidable shot-noise wall demanding a measurement budget of $M = \Omega(d^2)$ that constrains quantum machine learning scalability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the wavelet scaling exponent α as a diagnostic for latent space quality in world models, with α ≈ 1/2 corresponding to variance equipartition (analogous to Kolmogorov's inertial range). It claims α = 1/2 marks a sharp phase transition for classical simulability of amplitude-encoded quantum kernels: using tensor-network theory, latents with α > 1/2 are in an area-law phase with efficient MPS emulation (bounded bond dimension χ independent of n), while α < 1/2 enter a volume-law phase with exponential χ(n) growth. VideoMAE analysis shows spatial tokens near the boundary (α ≈ 0.423) but feature channels in the hard phase (α ≈ -0.123). Separately, Weingarten calculus on 2-designs yields Var[X] = Θ(d^{-2}) for scrambled transition probabilities, confirmed by a log-log fit of slope -1.881 (R² = 0.999), implying an Ω(d²) measurement budget barrier for QML.
Significance. If the α-to-entanglement mapping is rigorously established, the work supplies a physics-motivated, falsifiable criterion for assessing world-model representations and derives a concrete, parameter-free bound on quantum kernel scalability. The Weingarten-derived variance scaling, together with its high-fidelity numerical verification, is a clear technical strength that stands independently of the phase-transition claim.
major comments (3)
- [tensor-network theory section / abstract] The tensor-network argument (abstract and main theoretical section): the manuscript states that α = 1/2 is a sharp boundary proved via tensor-network theory, yet supplies no intermediate steps or equations linking the wavelet variance scaling definition to the scaling of entanglement entropy S(n) or MPS bond dimension χ(n). This derivation is load-bearing for the central simulability claim.
- [amplitude-encoding and VideoMAE analysis section] Mapping from latents to quantum states (section introducing amplitude encoding): the claim that α extracted from VideoMAE latents directly sets the area/volume-law phase of |ψ⟩ = ∑ x_i |i⟩ (normalized) requires explicit specification of (i) the amplitude encoding map, (ii) the qubit/site ordering chosen for the MPS, and (iii) why variance equipartition at α = 1/2 produces the correlation decay needed to bound χ. These assumptions are unstated, rendering the phase assignment dependent on unshown details.
- [discussion / optimality paragraph] Threshold motivation (discussion of optimality): while the variance result Var[X] = Θ(d^{-2}) is derived parameter-free from Weingarten calculus, the asserted optimality of α ≈ 1/2 is motivated simultaneously by the (unshown) phase-transition theory and by the observed VideoMAE values (0.423 close to 1/2), introducing mild post-hoc dependence that weakens the independence of the proposed threshold.
minor comments (3)
- [introduction / methods] The mathematical definition of the wavelet variance scaling exponent α should be stated explicitly with its formula at the first use, rather than assumed known, to aid readers outside the wavelet-analysis community.
- [numerical results subsection] For the numerical variance confirmation, the manuscript should report the precise range of d, the number of samples per d, and any uncertainty on the fitted slope -1.881 to allow direct comparison with the Θ(d^{-2}) prediction.
- [introduction] The connection between the wavelet diagnostic and quantum kernels could be clarified in the introduction, as the title emphasizes “quantum kernel TN-Simulability” but the kernel structure is not foregrounded until later.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight areas where the manuscript's theoretical connections can be made more explicit. We address each major comment point by point below, with revisions planned to improve clarity without altering the core claims.
read point-by-point responses
-
Referee: [tensor-network theory section / abstract] The tensor-network argument (abstract and main theoretical section): the manuscript states that α = 1/2 is a sharp boundary proved via tensor-network theory, yet supplies no intermediate steps or equations linking the wavelet variance scaling definition to the scaling of entanglement entropy S(n) or MPS bond dimension χ(n). This derivation is load-bearing for the central simulability claim.
Authors: We acknowledge that the manuscript presents the tensor-network argument at a high level without fully expanding the intermediate steps. The central claim relies on mapping wavelet variance scaling to entanglement entropy via correlation decay in the latent representation. In the revised manuscript, we will add a dedicated subsection deriving this explicitly: beginning from the definition of α as the scaling of wavelet coefficients, showing the resulting power-law decay in two-point correlations for α > 1/2, and demonstrating how this bounds the MPS bond dimension χ independently of system size n (area law), while α < 1/2 yields volume-law scaling with exponential χ(n). This will render the proof self-contained. revision: yes
-
Referee: [amplitude-encoding and VideoMAE analysis section] Mapping from latents to quantum states (section introducing amplitude encoding): the claim that α extracted from VideoMAE latents directly sets the area/volume-law phase of |ψ⟩ = ∑ x_i |i⟩ (normalized) requires explicit specification of (i) the amplitude encoding map, (ii) the qubit/site ordering chosen for the MPS, and (iii) why variance equipartition at α = 1/2 produces the correlation decay needed to bound χ. These assumptions are unstated, rendering the phase assignment dependent on unshown details.
Authors: We agree that these mapping details were insufficiently specified. The revised version will explicitly define the amplitude encoding as direct normalization of the latent vector components into the computational basis amplitudes, specify the MPS site ordering as a linearization of spatial tokens followed by feature channels, and derive the correlation decay from variance equipartition: at α = 1/2 the wavelet coefficients yield exponentially decaying correlations sufficient to bound entanglement entropy and thus χ. These additions will make the phase assignment for VideoMAE latents fully rigorous and independent of hidden assumptions. revision: yes
-
Referee: [discussion / optimality paragraph] Threshold motivation (discussion of optimality): while the variance result Var[X] = Θ(d^{-2}) is derived parameter-free from Weingarten calculus, the asserted optimality of α ≈ 1/2 is motivated simultaneously by the (unshown) phase-transition theory and by the observed VideoMAE values (0.423 close to 1/2), introducing mild post-hoc dependence that weakens the independence of the proposed threshold.
Authors: The optimality of α ≈ 1/2 is grounded first and foremost in the independent tensor-network phase-transition analysis, which predicts the area-to-volume-law boundary at equipartition without reference to any dataset. The VideoMAE results (spatial tokens near 0.423 and feature channels at -0.123) are presented as empirical confirmation of the theory's relevance to practical world models, not as the source of the threshold. We will revise the discussion paragraph to foreground the theoretical derivation and treat the numerical values strictly as validation, eliminating any appearance of post-hoc reasoning. revision: partial
Circularity Check
No significant circularity; central claims rest on external Weingarten calculus and asserted tensor-network mapping without reduction to fitted inputs or self-definition
full rationale
The variance result Var[X] = Θ(d^{-2}) is obtained via Weingarten calculus applied to 2-design ensembles and is independently confirmed numerically (log-log slope -1.881, R²=0.999); this step does not recycle fitted parameters or data thresholds as predictions. The α ≈ 1/2 equipartition threshold is introduced by explicit analogy to Kolmogorov scaling and then used to classify VideoMAE latents (α ≈ 0.423 and -0.123), but the paper presents the area/volume-law transition as a separate tensor-network proof rather than a redefinition or statistical fit of the same quantities. No equation or claim equates the simulability phase directly to the wavelet exponent by construction, nor does any load-bearing premise collapse to a self-citation or ansatz smuggled from prior author work. The derivation chain therefore remains self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- observed α values (0.423 and -0.123)
axioms (2)
- standard math Tensor-network representations of quantum states obey area-law or volume-law entanglement scaling that determines classical simulability via bond dimension χ
- domain assumption Wavelet variance scaling exponent α captures structural fidelity of latent spaces in a manner analogous to Kolmogorov inertial-range scaling
Reference graph
Works this paper leans on
-
[1]
Self-supervised learn- ing from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learn- ing from images with a joint-embedding predictive architecture. InCVPR, 2023
work page 2023
-
[2]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
Ville Bergholm, Josh Izaac, Maria Schuld, Chris- tian Gogolin, M Sajid Alam, Shahnawaz Ahmed, et al. PennyLane: Automatic differentiation of hybrid quantum-classical computations.arXiv:1811.04968, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Fernando G S L Brandão, Aram W Harrow, and MichałHorodecki. Localrandomquantumcircuitsare approximate polynomial-designs.Communications in Mathematical Physics, 346(2):397–434, 2016
work page 2016
-
[4]
Ge- nie: Generative interactive environments
Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, et al. Ge- nie: Generative interactive environments. InICML, 2024
work page 2024
-
[5]
Variational quantum algorithms.Nature Reviews Physics, 3(9):625–644, 2021
Marco Cerezo, Andrew Arrasmith, Ryan Babbush, Simon C Benjamin, Suguru Endo, Keisuke Fujii, et al. Variational quantum algorithms.Nature Reviews Physics, 3(9):625–644, 2021
work page 2021
-
[6]
Benoît Collins and Piotr Śniady. Integration with re- spect to the Haar measure on unitary, orthogonal and symplectic group.Communications in Mathematical Physics, 264(3):773–795, 2006
work page 2006
-
[7]
Ingrid Daubechies. Orthonormal bases of compactly supported wavelets.Communications on Pure and Applied Mathematics, 41(7):909–996, 1988. doi: 10. 1002/cpa.3160410705
work page 1988
-
[8]
Zur quantentheorie der strahlung
Albert Einstein. Zur quantentheorie der strahlung. Physikalische Zeitschrift, 18:121–128, 1917
work page 1917
-
[9]
Laser theory.Handbuch der Physik, XXV/2c:1–304, 1970
Hermann Haken. Laser theory.Handbuch der Physik, XXV/2c:1–304, 1970
work page 1970
-
[10]
Random quantum circuits are approximate polynomial-designs
Aram W Harrow and Richard A Low. Random quantum circuits are approximate polynomial-designs. Communications in Mathematical Physics, 291(1): 257–302, 2009
work page 2009
-
[11]
Aram W Harrow and Saeed Mehraban. Approxi- mate unitary 𝑡-designs by short random quantum circuits using nearest-neighbor and long-range gates. arXiv:1809.06957, 2018
-
[12]
Matthew B Hastings. An area law for one-dimensional quantum systems.Journal of Statistical Mechanics, 2007(08):P08024, 2007
work page 2007
-
[13]
Andrei N Kolmogorov. The local structure of turbu- lence in incompressible viscous fluid for very large Reynolds numbers.Doklady Akademii Nauk SSSR, 30:301–305, 1941
work page 1941
-
[14]
A path towards autonomous machine intelligence
Yann LeCun. A path towards autonomous machine intelligence. OpenReview, 2022
work page 2022
-
[15]
PyWavelets: A Python package for wavelet analysis.Journal of Open Source Software, 4(36):1237, 2019
Gregory Lee, Ralf Gommers, Filip Waselewski, Kai Wohlfahrt, and Aaron O’Leary. PyWavelets: A Python package for wavelet analysis.Journal of Open Source Software, 4(36):1237, 2019. 8
work page 2019
-
[16]
Elliott H Lieb and Derek W Robinson. The finite group velocity of quantum spin systems.Communica- tions in Mathematical Physics, 28(3):251–257, 1972
work page 1972
-
[17]
Academic Press, Boston, MA, 3rd edition, 2009
Stéphane Mallat.A Wavelet Tour of Signal Process- ing: The Sparse Way. Academic Press, Boston, MA, 3rd edition, 2009. ISBN 978-0-12-374370-1
work page 2009
-
[18]
Nature Communications9(1) (2018) https:// doi.org/10.1038/s41467-018-07090-4
Jarrod R. McClean, Sergio Boixo, Vadim N. Smelyan- skiy, Ryan Babbush, and Hartmut Neven. Barren plateaus in quantum neural network training land- scapes.Nature Communications, 9(1):4812, 2018. doi: 10.1038/s41467-018-07090-4
-
[19]
Cam- bridge University Press, Cambridge, 1992
Yves Meyer.Wavelets and Operators, volume 37 of Cambridge Studies in Advanced Mathematics. Cam- bridge University Press, Cambridge, 1992. ISBN 978-0-521-42000-6. Translated from the French by D. H. Salinger
work page 1992
-
[20]
A practical introduction to tensor networks.Annals of Physics, 349:117–158, 2014
Román Orús. A practical introduction to tensor networks.Annals of Physics, 349:117–158, 2014
work page 2014
-
[21]
Tensor-train decomposition.SIAM Journal on Scientific Computing, 33(5):2295–2317, 2011
Ivan V Oseledets. Tensor-train decomposition.SIAM Journal on Scientific Computing, 33(5):2295–2317, 2011
work page 2011
-
[22]
Solving the sampling problem of the sycamore quantum circuits
Feng Pan, Keyang Chen, and Pan Zhang. Solving the sampling problem of the sycamore quantum circuits. Physical Review Letters, 129(9):090502, 2022
work page 2022
-
[23]
Norman F Ramsey. Thermodynamics and statistical mechanics at negative absolute temperatures.Physi- cal Review, 103(1):20, 1956
work page 1956
-
[24]
Norbert Schuch, Michael M Wolf, Frank Verstraete, and J Ignacio Cirac. Entropy scaling and simulability by matrix product states.Physical Review Letters, 100(3):030504, 2008
work page 2008
-
[25]
Supervised quan- tum machine learning models are kernel methods
Maria Schuld and Nathan Killoran. Supervised quan- tum machine learning models are kernel methods. Physical Review Letters, 126(14):140502, 2021
work page 2021
-
[26]
Non-variational supervised quantum kernel methods: a review
John Tanner, Chon-Fai Kam, and Jingbo Wang. Non- variational supervised quantum kernel methods: a review.arXiv preprint arXiv:2604.07896, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Supanut Thanasilp, Samson Wang, M. Cerezo, and Zoë Holmes. Exponential concentration in quantum kernel methods.Nature Communications, 15(1):5200,
-
[28]
doi: 10.1038/s41467-024-49287-w
-
[29]
Matrix product states represent ground states faithfully.Physical Review B, 73(9):094423, 2006
Frank Verstraete and J Ignacio Cirac. Matrix product states represent ground states faithfully.Physical Review B, 73(9):094423, 2006
work page 2006
-
[30]
Kenneth G. Wilson. Renormalization group and crit- ical phenomena. i. renormalization group and the kadanoff scaling picture.Physical Review B, 4(9): 3174–3183, 1971. doi: 10.1103/PhysRevB.4.3174. 9 A Proof of Proposition 4.1: Haar Variance of Fidelity Kernels The goal of this appendix is to establish the exact variance formulaVar[𝜅]=(𝑑− 1)/[𝑑 2 (𝑑+ 1)] f...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.