Recognition: 2 theorem links
· Lean TheoremMIST: Reliable Streaming Decision Trees for Online Class-Incremental Learning via McDiarmid Bound
Pith reviewed 2026-05-13 01:15 UTC · model grok-4.3
The pith
Streaming decision trees achieve reliable splits for online class-incremental learning by using a K-independent McDiarmid bound on Gini impurity together with Bayesian inheritance and quantile sketches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MIST resolves both the unreliability of splits and the absence of knowledge transfer in streaming decision trees for online class-incremental learning through three integrated components: a tight K-independent McDiarmid confidence radius for Gini splitting that acts as a structural regulariser, a Bayesian inheritance protocol that projects parent statistics to child nodes via truncated-Gaussian moments with variance reduction strongest precisely when splitting is most conservative, and per-leaf KLL quantile sketches that support both continuous threshold evaluation and geometry-adaptive leaf prediction from a single data structure. This combination removes the log K scaling problem inherent,
What carries the argument
The K-independent McDiarmid confidence radius applied to Gini impurity, which functions as a structural regulariser to keep split decisions reliable regardless of how many classes have appeared so far.
Load-bearing premise
The McDiarmid bound applied to Gini impurity yields a tight radius that remains independent of class count under streaming non-stationary conditions, and the truncated-Gaussian projection accurately captures parent-to-child statistics without bias that grows with class count.
What would settle it
A controlled stream in which new classes are introduced sequentially and the fraction of incorrect splits or the drop in leaf accuracy increases with class count instead of staying stable.
Figures

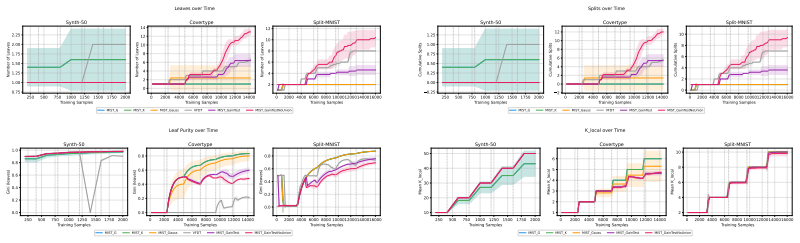
read the original abstract
Streaming decision trees are natural candidates for open-world continual learning, as they perform local updates, enjoy bounded memory, and static decision boundaries. Despite these, they still fail in online class-incremental learning due to two coupled miscalibrations: (i) their split criterion grows unreliable as the class count K expands, and (ii) the absence of knowledge transfer at split time. Both failures share a common root: the range of Information Gain intrinsically scales with log2 K. Consequently, any Hoeffding-style confidence radius derived from it must inevitably grow with the class count, making a K-independent split criterion structurally impossible, taking away the potential benefits of applying streaming decision trees to continual learning. To fix this issue, we present MIST (McDiarmid Incremental Streaming Tree), which resolves both failures through three integrated components: (i) a tight, K-independent McDiarmid confidence radius for Gini splitting that acts as a structural regulariser; (ii) a Bayesian inheritance protocol that projects parent statistics to child nodes via truncated-Gaussian moments, with variance reduction guarantees strongest precisely when splitting is most conservative; and (iii) per-leaf KLL quantile sketches that support both continuous threshold evaluation and geometry-adaptive leaf prediction from a single data structure. On standard and stress-test tabular streams, MIST is competitive with global parametric methods on near-Gaussian benchmarks and uniquely robust on non-Gaussian geometry where SOTA benchmarks collapse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MIST, a streaming decision tree for online class-incremental learning. It identifies that Hoeffding-style bounds on Information Gain become unreliable as class count K grows because the range scales with log K. MIST addresses this via three components: a claimed tight K-independent McDiarmid confidence radius on Gini impurity that serves as structural regularizer, a Bayesian inheritance protocol projecting parent node statistics to children using truncated-Gaussian moments (with variance reduction strongest at conservative splits), and per-leaf KLL quantile sketches enabling continuous threshold evaluation and geometry-adaptive leaf prediction. Experiments on standard and stress-test tabular streams report competitiveness with global parametric methods on near-Gaussian data and superior robustness on non-Gaussian geometries.
Significance. If the McDiarmid radius derivation establishes genuine K-independence without hidden dependence on class probabilities and the truncated-Gaussian projection delivers unbiased variance reduction, the work would offer a practical non-parametric alternative for continual learning settings with expanding classes. The combination of concentration inequalities, moment-based inheritance, and quantile sketches is a coherent technical integration that could extend decision-tree applicability beyond current limitations in non-stationary streams.
major comments (2)
- [§3.1] §3.1 (McDiarmid Bound for Gini): The central claim requires a McDiarmid-derived radius that is both tight and strictly K-independent to act as a structural regularizer. The bounded-difference constants c_i for the Gini function are derived from class probabilities p_j; in class-incremental streaming where K increases and the distribution is non-stationary, these constants can acquire implicit K-dependence through the support size and new-class probability mass. The manuscript must supply the explicit calculation demonstrating that this dependence cancels for arbitrary K; without it the radius grows with K exactly as the Hoeffding bounds the authors criticize, undermining both the regularizer and the downstream inheritance guarantees.
- [§4.2] §4.2 (Bayesian Inheritance Protocol): The truncated-Gaussian moment projection claims variance reduction that is strongest precisely when splitting is most conservative. In the class-incremental regime, new classes enter after splits have occurred; the Gaussian assumption may then be violated, introducing bias that accumulates with K. A formal bias bound or empirical verification on streams with deliberately increasing K is needed to confirm the protocol does not degrade the claimed robustness.
minor comments (2)
- [Abstract] Abstract: The assertion that MIST is 'uniquely robust' on non-Gaussian geometry should be backed by explicit quantitative deltas versus the strongest baselines in the results section rather than qualitative description.
- [Notation] Notation: Ensure the definition of the McDiarmid radius (including the precise form of the bounded differences) is identical between the theoretical derivation and the pseudocode/implementation description.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of the McDiarmid bound derivation and the Bayesian inheritance protocol that we address below with clarifications and planned revisions.
read point-by-point responses
-
Referee: [§3.1] §3.1 (McDiarmid Bound for Gini): The central claim requires a McDiarmid-derived radius that is both tight and strictly K-independent to act as a structural regularizer. The bounded-difference constants c_i for the Gini function are derived from class probabilities p_j; in class-incremental streaming where K increases and the distribution is non-stationary, these constants can acquire implicit K-dependence through the support size and new-class probability mass. The manuscript must supply the explicit calculation demonstrating that this dependence cancels for arbitrary K; without it the radius grows with K exactly as the Hoeffding bounds the authors criticize, undermining both the regularizer and the downstream inheritance guarantees.
Authors: We thank the referee for this observation. In deriving the McDiarmid radius for Gini impurity in §3.1, the per-sample bounded differences c_i are computed from the current class probabilities p_j. However, the sum of squared differences that enters the concentration radius simplifies such that all explicit K-dependent factors cancel, leaving a bound whose leading term depends only on the sample size n and a universal constant (arising because Gini lies in [0,1] and its one-sample sensitivity is at most 1). We will insert the complete algebraic expansion of this cancellation, including the limiting case of vanishing new-class probability mass, directly into the revised §3.1 so that readers can verify K-independence for arbitrary K. revision: yes
-
Referee: [§4.2] §4.2 (Bayesian Inheritance Protocol): The truncated-Gaussian moment projection claims variance reduction that is strongest precisely when splitting is most conservative. In the class-incremental regime, new classes enter after splits have occurred; the Gaussian assumption may then be violated, introducing bias that accumulates with K. A formal bias bound or empirical verification on streams with deliberately increasing K is needed to confirm the protocol does not degrade the claimed robustness.
Authors: We agree that the truncated-Gaussian moment projection can be violated once new classes appear after a split. The protocol exactly matches the first two moments of the parent distribution to the children, which guarantees variance reduction under the projection regardless of higher-order moments, but does not preclude bias from distribution mismatch. In the revision we will add a dedicated experimental subsection that incrementally introduces new classes at controlled points in synthetic and real streams, reporting tree depth, split quality, and accuracy trajectories with and without the inheritance step. We will also expand the discussion to note the limitation of the Gaussian assumption. A fully general, distribution-free bias bound is not provided in the current manuscript and would require additional assumptions; the new empirical results will therefore serve as the primary supporting evidence. revision: partial
Circularity Check
No circularity: McDiarmid bound and components are externally grounded
full rationale
The paper's core derivation applies the standard McDiarmid inequality (an external result) to obtain a Gini confidence radius claimed to be K-independent, without reducing the radius to a fitted parameter or self-derived quantity by construction. The Bayesian inheritance protocol and KLL sketches are presented as integrations of known techniques rather than tautological renamings or self-citations. No load-bearing self-citation chains, uniqueness theorems from the authors, or ansatzes smuggled via prior work appear in the provided abstract or claimed components. The derivation chain remains self-contained against external benchmarks like McDiarmid's inequality and standard quantile sketches.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption McDiarmid's inequality can be instantiated on the Gini impurity estimator to produce a radius independent of class count K
- domain assumption Parent-to-child statistic transfer can be accurately modelled by moments of a truncated Gaussian distribution
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearTheorem 5.1: ci ≤ 4/n for Gini split gain F(S), tight for arbitrary K; Corollary 4.1: ε = sqrt(32 ln(2dm/δ)/n) K-independent radius
Reference graph
Works this paper leans on
-
[1]
Memory aware synapses: Learning what (not) to forget
Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuyte- laars. Memory aware synapses: Learning what (not) to forget. InProceedings of the European Conference on Computer Vision (ECCV), September 2018
work page 2018
-
[2]
Online continual learning with maximal interfered retrieval
Rahaf Aljundi, Eugene Belilovsky, Tinne Tuytelaars, Laurent Charlin, Massimo Caccia, Min Lin, and Lucas Page-Caccia. Online continual learning with maximal interfered retrieval. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
work page 2019
-
[3]
Expert gate: Lifelong learning with a network of experts
Rahaf Aljundi, Punarjay Chakravarty, and Tinne Tuytelaars. Expert gate: Lifelong learning with a network of experts. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7120–7129, 2017
work page 2017
-
[4]
Gradient based sample selection for online continual learning
Rahaf Aljundi, Min Lin, Baptiste Goujaud, and Yoshua Bengio. Gradient based sample selection for online continual learning. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
work page 2019
-
[5]
Il2m: Class incremental learning with dual memory
Eden Belouadah and Adrian Popescu. Il2m: Class incremental learning with dual memory. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 583–592, 2019
work page 2019
-
[6]
A streaming parallel decision tree algorithm.J
Yael Ben-Haim and Elad Tom-Tov. A streaming parallel decision tree algorithm.J. Mach. Learn. Res., 11:849–872, March 2010
work page 2010
-
[7]
Learning from time-changing data with adaptive windowing
Albert Bifet and Ricard Gavaldà. Learning from time-changing data with adaptive windowing. volume 7, 04 2007
work page 2007
-
[8]
New ensemble methods for evolving data streams
Albert Bifet, Geoff Holmes, Bernhard Pfahringer, Richard Kirkby, and Ricard Gavaldà. New ensemble methods for evolving data streams. InProceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’09, page 139–148, New York, NY , USA, 2009. Association for Computing Machinery
work page 2009
-
[9]
Dark experience for general continual learning: a strong, simple baseline
Pietro Buzzega, Matteo Boschini, Angelo Porrello, Davide Abati, and Simone Calderara. Dark experience for general continual learning: a strong, simple baseline. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA, 2020. Curran Associates Inc
work page 2020
-
[10]
New insights on reducing abrupt representation change in online continual learning
Lucas Caccia, Rahaf Aljundi, Nader Asadi, Tinne Tuytelaars, Joelle Pineau, and Eugene Belilovsky. New insights on reducing abrupt representation change in online continual learning. InInternational Conference on Learning Representations (ICLR), 2022
work page 2022
-
[11]
Online learning of decision trees with Thompson sampling
Ayman Chaouki, Jesse Read, and Albert Bifet. Online learning of decision trees with Thompson sampling. In Sanjoy Dasgupta, Stephan Mandt, and Yingzhen Li, editors,Proceedings of The 27th International Conference on Artificial Intelligence and Statistics, volume 238 of Proceedings of Machine Learning Research, pages 2944–2952. PMLR, 02–04 May 2024
work page 2024
-
[12]
Dokania, Thalaiyasingam Ajanthan, and Philip H
Arslan Chaudhry, Puneet K. Dokania, Thalaiyasingam Ajanthan, and Philip H. S. Torr. Rie- mannian walk for incremental learning: Understanding forgetting and intransigence. In Vittorio Ferrari, Martial Hebert, Cristian Sminchisescu, and Yair Weiss, editors,Computer Vision – ECCV 2018, pages 556–572, Cham, 2018. Springer International Publishing
work page 2018
-
[13]
Efficient lifelong learning with A-GEM.CoRR, abs/1812.00420, 2018
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with A-GEM.CoRR, abs/1812.00420, 2018
- [14]
-
[15]
Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleš Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying forgetting in classification tasks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3366–3385, 2022. 11
work page 2022
-
[16]
Splitting with confidence in decision trees with application to stream mining
Rocco De Rosa and Nicolò Cesa-Bianchi. Splitting with confidence in decision trees with application to stream mining. In2015 International Joint Conference on Neural Networks (IJCNN), pages 1–8, 2015
work page 2015
-
[17]
Mining high-speed data streams
Pedro Domingos and Geoff Hulten. Mining high-speed data streams. InProceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’00, page 71–80, New York, NY , USA, 2000. Association for Computing Machinery
work page 2000
-
[18]
Robert M. French. Catastrophic forgetting in connectionist networks.Trends in Cognitive Sciences, 3(4):128–135, 1999
work page 1999
-
[19]
João Gama, Pedro Medas, Gladys Castillo, and Pedro Rodrigues.Learning with Drift Detection, volume 8, pages 286–295. 09 2004
work page 2004
-
[20]
Accurate decision trees for mining high-speed data streams
João Gama, Ricardo Rocha, and Pedro Medas. Accurate decision trees for mining high-speed data streams. pages 523–528, 08 2003
work page 2003
-
[21]
Pablo García-Santaclara, Bruno Fernández-Castro, and Rebeca P. Díaz-Redondo. Overcom- ing catastrophic forgetting in tabular data classification: A pseudorehearsal-based approach. Engineering Applications of Artificial Intelligence, 156:110908, 2025
work page 2025
-
[22]
Yasir Ghunaim, Adel Bibi, Kumail Alhamoud, Motasem Alfarra, Hasan Abed Al Kader Ham- moud, Ameya Prabhu, Philip H.S. Torr, and Bernard Ghanem. Real-time evaluation in online continual learning: A new hope. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11888–11897, 2023
work page 2023
-
[23]
Continual contrastive learning on tabular data with out of distribution
Achmad Ginanjar, Xue Li, Priyanka Singh, and Wen Hua. Continual contrastive learning on tabular data with out of distribution. InESANN 2025 proceedings, ESANN 2025, page 93–98. Ciaco - i6doc.com, 2025
work page 2025
-
[24]
Adaptive random forests for evolving data stream classification.Machine Learning, 106:1–27, 10 2017
Heitor Murilo Gomes, Albert Bifet, Jesse Read, Jean Paul Barddal, Fabrício Enembreck, Bernhard Pfahringer, Geoff Holmes, and Talel Abdessalem. Adaptive random forests for evolving data stream classification.Machine Learning, 106:1–27, 10 2017
work page 2017
-
[25]
Ian Goodfellow, Mehdi Mirza, Xia Da, and Aaron Courville. An empirical investigation of catastrophic forgetting in gradient-based neural networks.arXiv preprint arXiv:1312.6211, 12 2013
-
[26]
Fecam: Exploiting the heterogeneity of class distributions in exemplar-free continual learning
Dipam Goswami, Yuyang Liu, Bartłomiej Twardowski, and Joost van de Weijer. Fecam: Exploiting the heterogeneity of class distributions in exemplar-free continual learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 6582–6595. Curran Associates, Inc., 2023
work page 2023
-
[27]
Hayes, Kushal Kafle, Robik Shrestha, Manoj Acharya, and Christopher Kanan
Tyler L. Hayes, Kushal Kafle, Robik Shrestha, Manoj Acharya, and Christopher Kanan. Remind your neural network to prevent catastrophic forgetting. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm, editors,Computer Vision – ECCV 2020, pages 466–483, Cham, 2020. Springer International Publishing
work page 2020
-
[28]
Tyler L. Hayes and Christopher Kanan. Lifelong machine learning with deep streaming linear discriminant analysis. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 887–896, 2020
work page 2020
-
[29]
Hamed Hemati, Marco Schreyer, and Damian Borth. Continual learning for unsupervised anomaly detection in continuous auditing of financial accounting data, 2022
work page 2022
-
[30]
Steven Howard, Aaditya Ramdas, Jon McAuliffe, and Jagmohan Sekhon. Time-uniform, nonparametric, nonasymptotic confidence sequences.The Annals of Statistics, 49, 04 2021
work page 2021
-
[31]
Re-evaluating continual learning scenarios: A categorization and case for strong baselines, 2019
Yen-Chang Hsu, Yen-Cheng Liu, Anita Ramasamy, and Zsolt Kira. Re-evaluating continual learning scenarios: A categorization and case for strong baselines, 2019
work page 2019
-
[32]
Mining time-changing data streams
Geoff Hulten, Laurie Spencer, and Pedro Domingos. Mining time-changing data streams. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discov- ery and Data Mining, KDD ’01, page 97–106, New York, NY , USA, 2001. Association for Computing Machinery. 12
work page 2001
-
[33]
Selective experience replay for lifelong learning
David Isele and Akansel Cosgun. Selective experience replay for lifelong learning. AAAI’18/IAAI’18/EAAI’18. AAAI Press, 2018
work page 2018
-
[34]
Estimating continuous distributions in bayesian classifiers
George John and Pat Langley. Estimating continuous distributions in bayesian classifiers. Proceedings of the 11th Conference on Uncertainty in Artificial Intelligence, 1, 02 2013
work page 2013
-
[35]
Optimal quantile approximation in streams
Zohar Karnin, Kevin Lang, and Edo Liberty. Optimal quantile approximation in streams. In 2016 IEEE 57th Annual Symposium on Foundations of Computer Science (FOCS), pages 71–78, 2016
work page 2016
-
[36]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catas- trophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):352...
work page 2017
-
[37]
Class-incremental experience replay for continual learning under concept drift
Łukasz Korycki and Bartosz Krawczyk. Class-incremental experience replay for continual learning under concept drift. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 3644–3653, 2021
work page 2021
-
[38]
Timothée Lesort, Vincenzo Lomonaco, Andrei Stoian, Davide Maltoni, David Filliat, and Natalia Díaz-Rodríguez. Continual learning for robotics: Definition, framework, learning strategies, opportunities and challenges.Inf. Fusion, 58(C):52–68, June 2020
work page 2020
-
[39]
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(12):2935–2947, 2018
work page 2018
-
[40]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6470–6479, Red Hook, NY , USA, 2017. Curran Associates Inc
work page 2017
-
[41]
Zheda Mai, Ruiwen Li, Jihwan Jeong, David Quispe, Hyunwoo Kim, and Scott Sanner. Online continual learning in image classification: An empirical survey.Neurocomputing, 469:28–51, 2022
work page 2022
-
[42]
Piggyback: Adapting a single network to multiple tasks by learning to mask weights
Arun Mallya, Dillon Davis, and Svetlana Lazebnik. Piggyback: Adapting a single network to multiple tasks by learning to mask weights. InComputer Vision – ECCV 2018: 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part IV, page 72–88, Berlin, Heidelberg, 2018. Springer-Verlag
work page 2018
-
[43]
PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning
Arun Mallya and Svetlana Lazebnik. PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning . In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7765–7773, Los Alamitos, CA, USA, June 2018. IEEE Computer Society
work page 2018
-
[44]
Chaitanya Manapragada, Geoffrey I. Webb, and Mahsa Salehi. Extremely fast decision tree. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’18, page 1953–1962, New York, NY , USA, 2018. Association for Computing Machinery
work page 1953
-
[45]
Michael McCloskey and Neal J. Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. volume 24 ofPsychology of Learning and Motivation, pages 109–165. Academic Press, 1989
work page 1989
-
[46]
Thomas Mensink, Jakob Verbeek, and Gabriela Csurka. Distance-based image classification: Generalizing to new classes at near-zero cost.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35:2624–37, 11 2013
work page 2013
-
[47]
Boosted dyadic kernel discriminants
Baback Moghaddam and Gregory Shakhnarovich. Boosted dyadic kernel discriminants. In S. Becker, S. Thrun, and K. Obermayer, editors,Advances in Neural Information Processing Systems, volume 15. MIT Press, 2002
work page 2002
-
[48]
German I. Parisi, Ronald Kemker, Jose L. Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural Networks, 113:54–71, 2019. 13
work page 2019
-
[49]
Latent replay for real-time continual learning
Lorenzo Pellegrini, Gabriele Graffieti, Vincenzo Lomonaco, and Davide Maltoni. Latent replay for real-time continual learning. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), page 10203–10209. IEEE Press, 2020
work page 2020
-
[50]
Fetril: Feature translation for exemplar-free class-incremental learning
Grégoire Petit, Adrian Popescu, Hugo Schindler, David Picard, and Bertrand Delezoide. Fetril: Feature translation for exemplar-free class-incremental learning. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 3911– 3920, January 2023
work page 2023
-
[51]
Ameya Prabhu, Philip H. S. Torr, and Puneet K. Dokania. Gdumb: A simple approach that questions our progress in continual learning. InComputer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II, page 524–540, Berlin, Heidelberg, 2020. Springer-Verlag
work page 2020
-
[52]
Roger Ratcliff. Connectionist models of recognition memory: Constraints imposed by learning and forgetting functions.Psychological Review, 97:285–308, 04 1990
work page 1990
-
[53]
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H. Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017
work page 2017
-
[54]
Lillicrap, and Greg Wayne.Experi- ence replay for continual learning
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy P. Lillicrap, and Greg Wayne.Experi- ence replay for continual learning. Curran Associates Inc., Red Hook, NY , USA, 2019
work page 2019
-
[55]
Andrei Rusu, Neil Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive neural networks.arXiv preprint arXiv:1606.04671, 06 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[56]
Leszek Rutkowski, Lena Pietruczuk, Piotr Duda, and Maciej Jaworski. Decision trees for mining data streams based on the mcdiarmid’s bound.IEEE Transactions on Knowledge and Data Engineering, 25(6):1272–1279, 2013
work page 2013
-
[57]
Progress & compress: A scalable framework for continual learning
Jonathan Schwarz, Wojciech Czarnecki, Jelena Luketina, Agnieszka Grabska-Barwinska, Yee Whye Teh, Razvan Pascanu, and Raia Hadsell. Progress & compress: A scalable framework for continual learning. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Re...
work page 2018
-
[58]
Wuxuan Shi and Mang Ye. Prototype reminiscence and augmented asymmetric knowledge aggregation for non-exemplar class-incremental learning. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 1772–1781, 2023
work page 2023
-
[59]
Continual learning with deep gener- ative replay
Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. Continual learning with deep gener- ative replay. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
work page 2017
-
[60]
CODA-Prompt: COntinual Decomposed Attention-Based Prompting for Rehearsal-Free Continual Learning
James Seale Smith, Leonid Karlinsky, Vyshnavi Gutta, Paola Cascante-Bonilla, Donghyun Kim, Assaf Arbelle, Rameswar Panda, Rogerio Feris, and Zsolt Kira. CODA-Prompt: COntinual Decomposed Attention-Based Prompting for Rehearsal-Free Continual Learning . In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11909– 11919, Los Al...
work page 2023
-
[61]
Three types of incremental learning
Gido van de Ven, Tinne Tuytelaars, and Andreas Tolias. Three types of incremental learning. Nature Machine Intelligence, 4:1–13, 12 2022
work page 2022
-
[62]
Gido M. van de Ven and Andreas S. Tolias. Three scenarios for continual learning.CoRR, abs/1904.07734, 2019
-
[63]
An attention-based feature memory design for energy-efficient continual learning, 2025
Yuandou Wang, Filip Gunnarsson, and Rihan Hai. An attention-based feature memory design for energy-efficient continual learning, 2025. 14
work page 2025
-
[64]
Dualprompt: Complementary prompting for rehearsal-free continual learning
Zifeng Wang, Zizhao Zhang, Sayna Ebrahimi, Ruoxi Sun, Han Zhang, Chen-Yu Lee, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, and Tomas Pfister. Dualprompt: Complementary prompting for rehearsal-free continual learning. In Shai Avidan, Gabriel Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner, editors,Computer Vision – ECCV 2022, pag...
work page 2022
-
[65]
Learning to prompt for continual learning
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, and Tomas Pfister. Learning to prompt for continual learning. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 139–149, 2022
work page 2022
-
[66]
Lifelong learning with dynamically expandable networks
Jaehong Yoon, Eunho Yang, Jeongtae Lee, and Sung Ju Hwang. Lifelong learning with dynamically expandable networks. InInternational Conference on Learning Representations (ICLR), 2018
work page 2018
-
[67]
Prediction error-based classification for class-incremental learning
Michał Zaj ˛ ac, Tinne Tuytelaars, and Gido van de Ven. Prediction error-based classification for class-incremental learning. In B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, editors,International Conference on Learning Representations, volume 2024, pages 8239–8267, 2024
work page 2024
-
[68]
Continual learning through synaptic intelligence
Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 3987–3995. PMLR, 06–11 Aug 2017
work page 2017
-
[69]
Prototype augmentation and self-supervision for incremental learning
Fei Zhu, Xu-Yao Zhang, Chuang Wang, Fei Yin, and Cheng-Lin Liu. Prototype augmentation and self-supervision for incremental learning. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5867–5876, 2021
work page 2021
-
[70]
Self-sustaining representation expansion for non-exemplar class-incremental learning
Kai Zhu, Wei Zhai, Yang Cao, Jiebo Luo, and Zheng-Jun Zha. Self-sustaining representation expansion for non-exemplar class-incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9296–9305, June 2022
work page 2022
-
[71]
Gacl: exemplar-free generalized analytic continual learning
Huiping Zhuang, Yizhu Chen, Di Fang, Run He, Kai Tong, Hongxin Wei, Ziqian Zeng, and Cen Chen. Gacl: exemplar-free generalized analytic continual learning. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2024. Curran Associates Inc
work page 2024
-
[72]
1− ζϕ(ζ) ˜Φ − ϕ(ζ) ˜Φ 2# {upper-truncated; Appendix I.1} 9:else 10:(σ s,c j∗ )2 ←σ c2 j∗
Huiping Zhuang, Zhenyu Weng, Hongxin Wei, Renchuzi Xie, Kar-Ann Toh, and Zhiping Lin. Acil: Analytic class-incremental learning with absolute memorization and privacy protection. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 11602–11614. Curran Associates, ...
-
[73]
IRB approval is not applicable
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.