Recognition: 1 theorem link
· Lean TheoremSTA-FEM: Exact Streaming Assembly for Preplanned Dynamic Tetrahedral Topology Edits
Pith reviewed 2026-05-13 00:57 UTC · model grok-4.3
The pith
Dynamic tetrahedral simulations can replace full mesh rebuilds with exact incremental assembly on a preallocated superset mesh while leaving solver layers unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When the candidate element pool is preallocated and the per-frame edit stream is exposed, the per-frame assembly step can be replaced with persistent incremental updates that match a full-rebuild approach exactly at every frame, leaving the surrounding solver, preconditioner, and time-stepping layers unchanged.
What carries the argument
Streaming assembly via persistent incremental updates on a fixed superset tetrahedral mesh that uses the exposed per-frame edit stream to maintain exact matrix parity with full rebuilds.
If this is right
- End-to-end speedups of 1.37x to 1.61x over full-rebuild approaches across tested three-dimensional examples.
- Orders-of-magnitude reductions in matrix update cost while preserving exact matrix parity in all frames.
- Up to 76 percent speedups in fracture frame time with exact equivalence to ground-truth full-rebuild results.
- The solver, preconditioner, and time-stepping layers require no modifications.
- The method works for realistic fracture simulation pipelines with up to 460k elements.
Where Pith is reading between the lines
- If edit streams can be generated in advance for other adaptive-mesh domains such as cloth or fluid dynamics, the same exact-incremental pattern could apply without altering core solvers.
- Exposing edit streams as a standard interface in FEM libraries would let users adopt this optimization for preplanned topology changes.
- Long-running simulations that currently avoid remeshing due to cost might become feasible once incremental assembly is available.
Load-bearing premise
A fixed superset mesh can be preallocated in advance to cover every element that will ever become active during the entire simulation run.
What would settle it
Any simulation frame in which the matrix assembled via streaming incremental updates differs from the matrix produced by a full rebuild on the identical active elements and topology.
Figures


read the original abstract
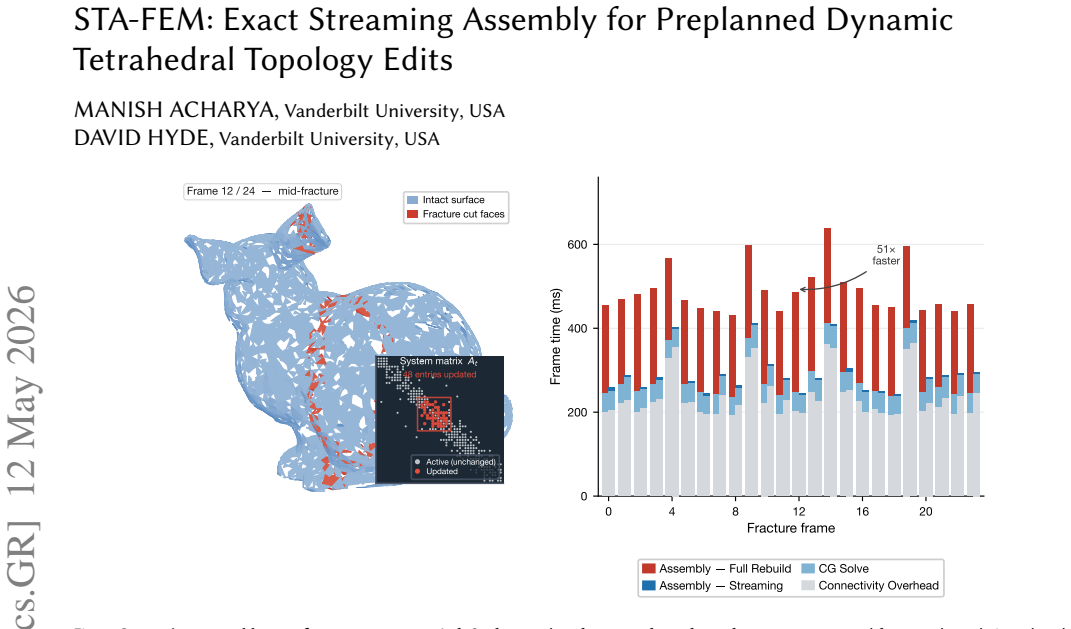
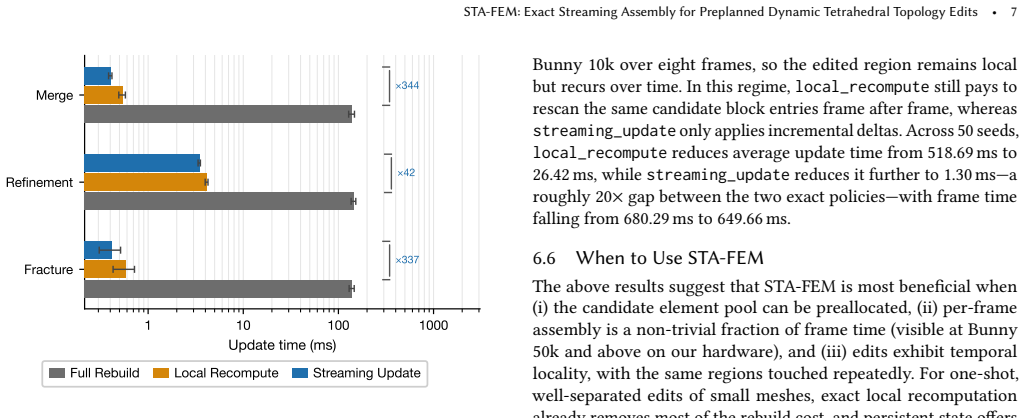
Dynamic tetrahedral simulation pipelines rebuild topology-dependent solver state after every fracture, refinement, or merge event - discarding structural continuity that survives each edit and spending global work on what are often local changes. We present STA-FEM, a streaming assembly method for simulations with topologically-dynamic tetrahedral meshes operating on a fixed superset mesh: when the candidate element pool is preallocated and the per-frame edit stream is exposed, the surrounding solver, preconditioner, and time-stepping layers stay unchanged while the per-frame assembly step is replaced with persistent incremental updates that match a full-rebuild approach exactly at every frame. Across various three-dimensional examples with up to 460k elements, the method delivers end-to-end speedups of 1.37x to 1.61x over full-rebuild with orders-of-magnitude reductions in matrix update cost, preserving exact matrix parity in all tested frames against a stronger exact local recomputation baseline. We test our algorithm in realistic fracture simulation pipelines and observe up to 76% speedups in fracture frame time with exact equivalence to a ground-truth full-rebuild algorithm. These results establish exact streaming assembly as a potentially practical approach for simulating tetrahedral meshes with dynamic topology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces STA-FEM, a streaming assembly method for finite-element simulations on dynamically changing tetrahedral meshes. It operates on a fixed superset mesh with a preallocated candidate element pool and an exposed per-frame edit stream, replacing full matrix assembly with persistent incremental updates that are asserted to produce exact parity with a complete rebuild at every frame while leaving the solver, preconditioner, and time-stepping layers unchanged. Experiments on 3D examples up to 460k elements report end-to-end speedups of 1.37×–1.61× over full-rebuild baselines, orders-of-magnitude reductions in matrix update cost, exact matrix parity against both full-rebuild and local-recomputation baselines, and up to 76% speedups on fracture frames.
Significance. If the exact equivalence holds, the work provides a practical, non-intrusive optimization for dynamic-topology tetrahedral simulations common in fracture, cutting, and adaptive refinement pipelines. By preserving structural continuity across edits and avoiding unnecessary global work, it could improve performance in graphics and physics-based animation without requiring changes to established solver stacks. The reported scale (460k elements) and concrete speedups on realistic fracture scenarios indicate potential for immediate adoption in production pipelines.
minor comments (2)
- [Abstract] Abstract and §1: the scope condition (fixed superset mesh, preallocated pool, exposed edit stream) is stated clearly but could be reiterated in the conclusion or limitations section to prevent over-generalization by readers.
- [Experimental results] The experimental section would benefit from an explicit table or paragraph listing the exact edit types (fracture, refinement, merge), their frequencies, and the DOF counts per frame to strengthen reproducibility of the parity and timing claims.
Simulated Author's Rebuttal
We thank the referee for the positive and constructive review of our manuscript. We are encouraged by the acknowledgment of STA-FEM's exact equivalence to full-rebuild approaches, the reported performance gains in realistic fracture scenarios, and the potential for non-intrusive adoption in existing solver stacks for graphics and physics-based animation. We will incorporate any minor revisions as appropriate in the next version.
Circularity Check
No significant circularity
full rationale
The paper describes an algorithmic construction for streaming assembly on a preallocated superset mesh with an exposed edit stream, asserting that incremental updates produce exact matrix parity with full rebuild by direct design of the update rules. This claim is validated through explicit empirical checks against independent full-rebuild and local-recomputation baselines rather than any fitted parameter or self-referential definition. No load-bearing step reduces to a self-citation chain, an ansatz smuggled via prior work, or a prediction that is statistically forced by construction; the surrounding solver layers remain untouched precisely because the method operates within the stated scoping assumptions. The derivation is therefore self-contained as a practical engineering improvement.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The edit stream is preplanned and exposed to the assembly process
- domain assumption A fixed superset mesh with preallocated candidate element pool is used
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearSTA-FEM maintains a topology-dependent sparse operator under a stream of tetrahedral edits... updates only touched matrix entries... exact equivalence to a full-rebuild approach
Reference graph
Works this paper leans on
-
[1]
O'Brien, James F. and Hodgins, Jessica K. , title =. 1999 , publisher =. doi:10.1145/311535.311550 , booktitle =
-
[2]
ACM Transactions on Graphics , pages =
Molino, Neil and Bao, Zhaosheng and Fedkiw, Ronald , title =. ACM Transactions on Graphics , pages =. 2004 , issue_date =
work page 2004
-
[3]
and Burke, Sebastian and Shewchuk, Jonathan R
Wicke, Martin and Ritchie, Daniel and Klingner, Bryan M. and Burke, Sebastian and Shewchuk, Jonathan R. and O'Brien, James F. , title =. ACM Transactions on Graphics , articleno =. 2010 , issue_date =
work page 2010
-
[4]
Tarjan, Robert Endre , title =. Journal of the ACM , pages =. 1975 , issue_date =
work page 1975
-
[5]
Holm, Jacob and de Lichtenberg, Kristian and Thorup, Mikkel , title =. Journal of the ACM , pages =. 2001 , issue_date =
work page 2001
-
[6]
Davis, Timothy A. and Hager, William W. , title =. SIAM Journal on Matrix Analysis and Applications , volume =. 1999 , doi =
work page 1999
-
[7]
Chen, Yanqing and Davis, Timothy A. and Hager, William W. and Rajamanickam, Sivasankaran , title =. ACM Transactions on Mathematical Software , articleno =. 2008 , issue_date =
work page 2008
-
[8]
Van. Algebraic Multigrid by Smoothed Aggregation for Second and Fourth Order Elliptic Problems , journal =. 1996 , doi =
work page 1996
-
[9]
A Review of Algebraic Multigrid , journal =
St. A Review of Algebraic Multigrid , journal =. 2001 , doi =
work page 2001
-
[10]
Zarebavani, Behrooz and Kaufman, Danny M. and Levin, David I. W. and Dehnavi, Maryam Mehri , journal=. 2025 , doi=
work page 2025
-
[11]
and Panozzo, Daniele , journal=
Ferguson, Zachary and Schneider, Teseo and Kaufman, Danny M. and Panozzo, Daniele , journal=. 2023 , doi=
work page 2023
-
[12]
Fan, Linxu and Chitalu, Floyd M. and Komura, Taku , journal=. 2022 , doi=
work page 2022
- [13]
-
[14]
Concurrency and Computation: Practice and Experience , volume =
Yeung, Yu-Hong and Pothen, Alex and Crouch, Jessica , title =. Concurrency and Computation: Practice and Experience , volume =. 2020 , publisher =
work page 2020
-
[15]
Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation , series =
Koschier, Dan and Lipponer, Sebastian and Bender, Jan , title =. Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation , series =. 2014 , pages =
work page 2014
-
[16]
ACM SIGGRAPH 2012 Courses , series =
Sifakis, Eftychios and Barbi. ACM SIGGRAPH 2012 Courses , series =. 2012 , articleno =
work page 2012
-
[17]
ACM Transactions on Graphics , volume =
Hahn, David and Wojtan, Chris , title =. ACM Transactions on Graphics , volume =. 2015 , publisher =
work page 2015
-
[18]
2023 IEEE Conference on Virtual Reality and 3D User Interfaces (VR) , year =
Berndt, Iago and Torchelsen, Rafael and Maciel, Anderson , title =. 2023 IEEE Conference on Virtual Reality and 3D User Interfaces (VR) , year =
work page 2023
-
[19]
Nesme, Matthieu and Kry, Paul G. and Je. Preserving Topology and Elasticity for Embedded Deformable Models , journal =. 2009 , publisher =
work page 2009
-
[20]
and Wojtan, Chris and Hodgins, Jessica K
Bargteil, Adam W. and Wojtan, Chris and Hodgins, Jessica K. and Turk, Greg , title =. ACM Transactions on Graphics , volume =. 2007 , publisher =
work page 2007
-
[21]
Proceedings of the 2004 Eurographics/ACM SIGGRAPH Symposium on Geometry Processing , pages=
Simplification and Improvement of Tetrahedral Models for Simulation , author=. Proceedings of the 2004 Eurographics/ACM SIGGRAPH Symposium on Geometry Processing , pages=
work page 2004
-
[22]
Bell, Nathan and Olson, Luke N and Schroder, Jacob and Southworth, Ben , journal=
-
[23]
A Recursive Approach to Local Mesh Refinement in Two and Three Dimensions , journal =
Igor Kossaczký , keywords =. A Recursive Approach to Local Mesh Refinement in Two and Three Dimensions , journal =. 1994 , issn =. doi:https://doi.org/10.1016/0377-0427(94)90034-5 , url =
-
[24]
SIAM Journal on Scientific Computing , volume=
Local Bisection Refinement for n -Simplicial Grids Generated by Reflection , author=. SIAM Journal on Scientific Computing , volume=. 1995 , publisher=
work page 1995
-
[25]
SIAM Journal on Scientific Computing , volume=
Locally Adapted Tetrahedral Meshes Using Bisection , author=. SIAM Journal on Scientific Computing , volume=. 2000 , publisher=
work page 2000
-
[26]
AIP Conference Proceedings , volume=
30 Years of Newest Vertex Bisection , author=. AIP Conference Proceedings , volume=. 2016 , organization=
work page 2016
-
[27]
11th Pacific Conference onComputer Graphics and Applications, 2003
A State Machine for Real-Time Cutting of Tetrahedral Meshes , author=. 11th Pacific Conference onComputer Graphics and Applications, 2003. Proceedings. , pages=. 2003 , organization=
work page 2003
-
[28]
ACM Transactions on Graphics , volume=
Breaking Good: Fracture Modes for Realtime Destruction , author=. ACM Transactions on Graphics , volume=. 2023 , publisher=
work page 2023
-
[29]
ACM Transactions on Graphics , volume=
Real Time Dynamic Fracture with Volumetric Approximate Convex Decompositions , author=. ACM Transactions on Graphics , volume=. 2013 , publisher=
work page 2013
-
[30]
McGregor, Andrew , title =. ACM SIGMOD Record , volume =. 2014 , publisher =
work page 2014
-
[31]
External Memory Algorithms: DIMACS Workshop External Memory and Visualization , year =
Monika Henzinger and Prabhakar Raghavan and Sridhar Rajagopalan , title =. External Memory Algorithms: DIMACS Workshop External Memory and Visualization , year =
-
[32]
Proceedings of the Twenty-Third Annual ACM-SIAM Symposium on Discrete Algorithms , series =
Ahn, Kook and Guha, Sudipto and McGregor, Andrew , title =. Proceedings of the Twenty-Third Annual ACM-SIAM Symposium on Discrete Algorithms , series =. 2012 , pages =
work page 2012
-
[33]
On Graph Problems in a Semi-Streaming Model , journal =
Joan Feigenbaum and Sampath Kannan and Andrew McGregor and Siddharth Suri and Jian Zhang , keywords =. On Graph Problems in a Semi-Streaming Model , journal =. 2005 , note =. doi:https://doi.org/10.1016/j.tcs.2005.09.013 , url =
-
[34]
Muthukrishnan, Shan , title =. 2005 , issue_date =. doi:10.1561/0400000002 , journal =
-
[35]
Single Pass Spectral Sparsification in Dynamic Streams , author=. 2015 , eprint=
work page 2015
-
[36]
Proceedings of the Twenty-Seventh Annual ACM-SIAM Symposium on Discrete Algorithms , series =
Rajesh Chitnis and Graham Cormode and Hossein Esfandiari and MohammadTaghi Hajiaghayi and Andrew McGregor and Morteza Monemizadeh and Sofya Vorotnikova , title =. Proceedings of the Twenty-Seventh Annual ACM-SIAM Symposium on Discrete Algorithms , series =. 2016 , pages =
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.