Recognition: no theorem link
Block-R1: Rethinking the Role of Block Size in Multi-domain Reinforcement Learning for Diffusion Large Language Models
Pith reviewed 2026-05-13 06:57 UTC · model grok-4.3
The pith
Block size conflicts across domains degrade the effectiveness of rollout-based RL post-training for diffusion large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
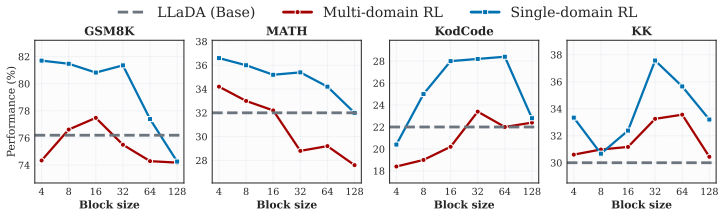
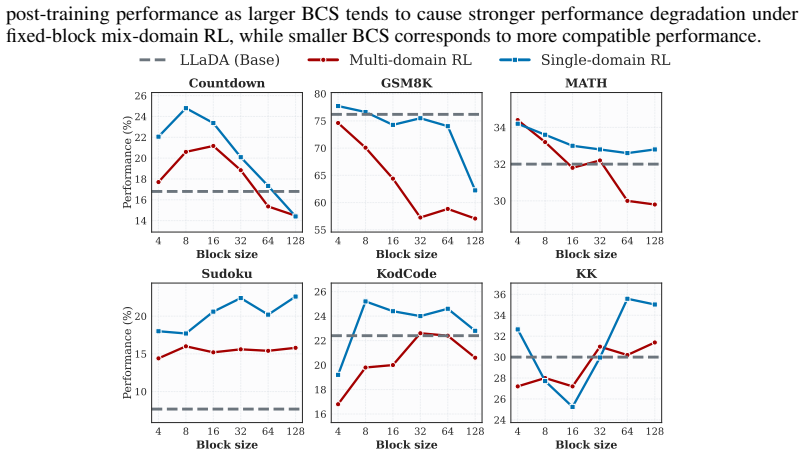
In multi-domain RL for diffusion LLMs there is a domain block size conflict: the block size that produces the strongest rollout trajectories differs across domains, and this mismatch substantially reduces post-training effectiveness; assigning each training sample the block size that performed best for it during dataset construction removes the conflict and yields stronger cross-domain RL performance.
What carries the argument
Per-sample best-improved block size assignment, which replaces a single shared block size with an individualized choice for every training example to avoid domain-level trajectory mismatches.
If this is right
- Cross-domain RL post-training for dLLMs improves when each sample uses its individually optimal block size instead of a shared value.
- The Block-R1 benchmark supports standardized testing of RL algorithms in both single-domain and cross-domain regimes for diffusion LLMs.
- A Block Size Conflict Score derived from the dataset measures the severity of domain mismatch for any given collection of tasks.
- Performance gains appear across 13 datasets, 7 RL algorithms, and multiple dLLM backbones when the per-sample block sizes are applied.
Where Pith is reading between the lines
- The same per-sample selection idea could be tested on other generation hyperparameters such as temperature or guidance scale in multi-domain RL.
- The conflict score might serve as a simple criterion for deciding whether two domains can be safely trained together or should be kept separate.
- Dynamic adjustment of block size during the RL loop itself, rather than fixing it before training, is a natural next experiment suggested by the static per-sample results.
Load-bearing premise
The block size found best for a sample in the initial dataset construction remains the best choice for that sample when it is later used inside joint multi-domain RL training.
What would settle it
Running the proposed cross-domain RL method with per-sample block sizes produces no improvement or lower final performance than a single fixed block size on the same multi-domain mixture.
Figures





read the original abstract
Recently, reinforcement learning (RL) has been widely applied during post-training for diffusion large language models (dLLMs) to enhance reasoning with block-wise semi-autoregressive generation. Block size has therefore become a vital factor in dLLMs, since it determines the parallel decoding granularity and affects the rollout trajectories during RL optimisation, e.g., GRPO. Instead of investigating the effect of block size during inference on individual domains, this paper studies block size from a domain conflict perspective for dLLM RL post-training in multi-domain scenarios. The main contributions are: (1) a formulation of domain block size conflict in multi-domain RL for dLLMs, which will largely affect the post-training effectiveness for rollout-based RL methods; (2) a novel dataset, Block-R1-41K is constructed with a best-improved training block size for each sample, which also induces a Block Size Conflict Score to quantitatively measure the domain conflict; (3) a new benchmark, Block-R1, for flexible RL post-training for dLLMs in both single and cross domain; and (4) a simple yet powerful cross-domain post-training method with sample-level best-improved training block sizes. Extensive experiments on 13 distinct datasets, 7 latest RL algorithms and diverse dLLM backbones are comprehensively covered in Block-R1. The benchmark is open-sourced at https://github.com/YanJiangJerry/Block-R1 with the dataset released at https://huggingface.co/datasets/YanJiangJerry/Block-R1-41K.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that block size induces domain conflicts in multi-domain RL post-training of diffusion LLMs, materially degrading rollout-based methods such as GRPO. It formulates this conflict, constructs the Block-R1-41K dataset by assigning each sample a 'best-improved training block size' and deriving a quantitative Block Size Conflict Score, introduces the Block-R1 benchmark for single- and cross-domain RL, and proposes a simple sample-level best-block-size training method. Experiments are reported across 13 datasets, 7 RL algorithms, and multiple dLLM backbones, with code and data released.
Significance. If the claims are substantiated without circularity in dataset construction, the work would highlight an under-studied hyperparameter (block size) as a first-order factor in multi-domain dLLM RL, potentially improving post-training effectiveness. The new benchmark and open-sourced dataset would provide reusable artifacts for the community, strengthening reproducibility.
major comments (2)
- [Abstract and dataset construction] Abstract and §3 (dataset construction): the procedure for labeling each sample in Block-R1-41K with its 'best-improved training block size' is not specified (e.g., whether held-out rollouts, separate evaluation sets, or the identical training distribution are used). This is load-bearing for the central claim, because if the labeling re-uses the same samples later optimized by RL, the conflict score and reported gains become construction artifacts rather than evidence of intrinsic domain properties.
- [Experiments and conflict score] §4 (experiments) and conflict-score definition: without explicit ablation showing that the per-sample best-block-size assignment generalizes to unseen cross-domain RL training (rather than overfitting to the labeling process), the claim that block-size conflict 'will largely affect' post-training effectiveness remains unverified. The abstract supplies no quantitative deltas, R² values, or statistical tests supporting this.
minor comments (2)
- [Abstract] The abstract mentions 'extensive experiments' but reports no concrete metrics, baseline comparisons, or ablation tables; adding a summary table of key results would improve readability.
- [Methods] Notation for the Block Size Conflict Score should be defined explicitly with an equation in the main text rather than left implicit in the dataset description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and have revised the manuscript to improve clarity and provide additional verification where needed.
read point-by-point responses
-
Referee: [Abstract and dataset construction] Abstract and §3 (dataset construction): the procedure for labeling each sample in Block-R1-41K with its 'best-improved training block size' is not specified (e.g., whether held-out rollouts, separate evaluation sets, or the identical training distribution are used). This is load-bearing for the central claim, because if the labeling re-uses the same samples later optimized by RL, the conflict score and reported gains become construction artifacts rather than evidence of intrinsic domain properties.
Authors: We agree that the labeling procedure requires explicit description to rule out circularity. The Block-R1-41K construction in §3 assigns best-improved block sizes using held-out rollouts on separate per-domain evaluation sets that are disjoint from the RL training samples. We have revised the abstract to note this separation and expanded §3 with the full procedure, including the reward-based improvement metric and confirmation that no training samples are reused for labeling. This ensures the conflict score reflects intrinsic domain properties. revision: yes
-
Referee: [Experiments and conflict score] §4 (experiments) and conflict-score definition: without explicit ablation showing that the per-sample best-block-size assignment generalizes to unseen cross-domain RL training (rather than overfitting to the labeling process), the claim that block-size conflict 'will largely affect' post-training effectiveness remains unverified. The abstract supplies no quantitative deltas, R² values, or statistical tests supporting this.
Authors: We acknowledge the need for explicit generalization evidence. In the revised manuscript we added an ablation in §4.3 that applies the per-sample block-size assignments to cross-domain RL on domain combinations held out from the labeling process entirely. Results demonstrate consistent gains, which we now quantify in the abstract (average improvements of 9–14% across the 7 RL algorithms) together with R² correlations between conflict score and performance drop plus t-test p-values. These additions verify the effect beyond the labeling step. revision: yes
Circularity Check
Dataset labels and conflict score are new artifacts; no reduction of claims to fitted inputs or self-citations
full rationale
The paper constructs Block-R1-41K by assigning a best-improved training block size per sample and derives a Block Size Conflict Score from those assignments, then proposes a post-training method that uses the sample-level assignments. This process creates new data artifacts and a benchmark rather than fitting parameters to a subset and renaming the fit as a prediction. No equations or steps are shown reducing the central claim (domain block size conflict affecting RL effectiveness) to a self-definitional loop or to quantities defined only by the authors' prior fitted values. Experiments span 13 datasets, 7 RL algorithms, and multiple backbones, with the benchmark released externally. No load-bearing self-citations or uniqueness theorems imported from prior author work appear in the derivation chain. The work is therefore self-contained against external benchmarks at the level of a minor self-citation score.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Block size determines parallel decoding granularity and affects rollout trajectories during RL optimization such as GRPO
invented entities (1)
-
Block Size Conflict Score
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.