Recognition: 2 theorem links
· Lean TheoremBeyond Parameter Aggregation: Semantic Consensus for Federated Fine-Tuning of LLMs
Pith reviewed 2026-05-13 06:23 UTC · model grok-4.3
The pith
Semantic consensus on outputs from public prompts replaces parameter aggregation for federated fine-tuning of large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Collaboration is mediated through model behavior rather than parameters. Clients fine-tune locally and exchange generated outputs on a shared public prompt set. The server maps these outputs into a semantic representation space, forms a per-prompt semantic consensus, and returns pseudo-labels for further local fine-tuning. This formulation changes communication scaling to depend only on the public prompt budget and the size of communicated behaviors, independent of model size, and accommodates heterogeneous architectures and open-ended text generation.
What carries the argument
Per-prompt semantic consensus formed by mapping client outputs on public prompts into a semantic representation space to generate pseudo-labels for local fine-tuning.
Where Pith is reading between the lines
- The method could extend federated adaptation to entirely black-box models where parameter access is unavailable.
- Public prompt selection becomes a new design variable whose quality directly affects consensus reliability across clients.
- Energy and runtime savings may compound in large-scale deployments because local fine-tuning continues without repeated full-model transfers.
- The approach invites investigation into whether similar behavior-level consensus can apply to non-text modalities with suitable embedding spaces.
Load-bearing premise
That mapping client outputs on public prompts into a semantic representation space and forming per-prompt consensus yields pseudo-labels that support effective further local fine-tuning comparable to parameter aggregation.
What would settle it
A controlled experiment in which models trained via the pseudo-labels show substantially lower performance than parameter-aggregated baselines on held-out tasks drawn from the private data distributions.
Figures




read the original abstract
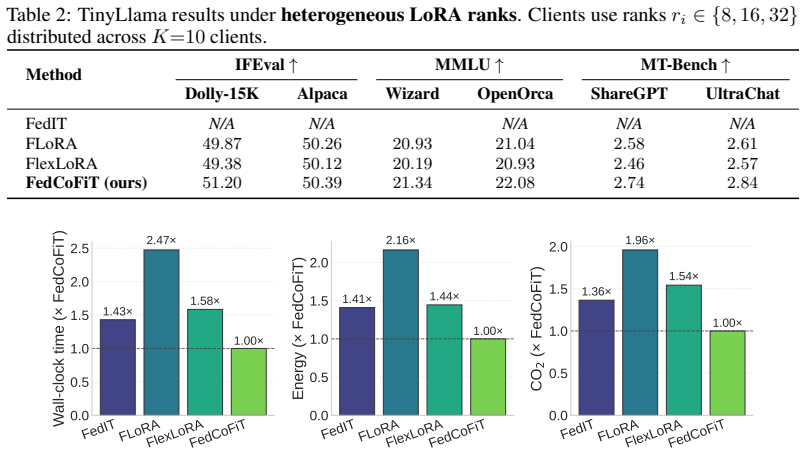
Federated fine-tuning of large language models is commonly formulated as a parameter aggregation problem. However, even parameter-efficient methods require transmitting large collections of trainable weights, assume aligned architectures, and rely on white-box access to model parameters. As model sizes continue to grow and deployments become increasingly heterogeneous, these assumptions become progressively misaligned with practical constraints. We consider an alternative formulation in which collaboration is mediated through model behavior rather than parameters. Clients fine-tune local models on private data and exchange generated outputs on a shared, public prompt set. The server maps these outputs into a semantic representation space, forms a per-prompt semantic consensus, and returns pseudo-labels for further local fine-tuning. This formulation fundamentally changes the communication scaling of federated LLM fine-tuning. The amount of information exchanged depends only on the public prompt budget and the size of the communicated behaviors, independent of model size. As a consequence, the protocol naturally accommodates heterogeneous architectures and applies directly to open-ended text generation. We present a theoretical analysis and empirical results demonstrating that this approach can match strong federated fine-tuning baselines while substantially reducing communication by orders of magnitude (e.g., analytically by a factor of $1006$ for Llama3.1-405B), as well as reductions in runtime and energy consumption. These results suggest that, for generative foundation models, behavior-level consensus provides a more appropriate abstraction for federated adaptation than parameter aggregation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an alternative to parameter-aggregation-based federated fine-tuning of LLMs. Clients fine-tune locally on private data and exchange generated outputs on a fixed public prompt set; the server maps these outputs into a semantic representation space, computes per-prompt consensus, and returns the resulting pseudo-labels for further local fine-tuning. The central claims are that communication cost depends only on prompt budget and behavior size (hence independent of model size), that the protocol naturally supports heterogeneous architectures and open-ended generation, and that it matches strong federated baselines while reducing communication by orders of magnitude (analytically 1006× for Llama-3.1-405B) together with runtime and energy savings. A theoretical analysis and empirical results are offered in support.
Significance. If the central utility claim holds, the work would be significant for federated adaptation of foundation models: it removes the dependence of communication volume on parameter count, relaxes the requirement of architectural homogeneity, and directly applies to generative tasks. The reported analytic and empirical communication reductions, together with the explicit handling of heterogeneous generators, constitute a concrete advance over existing parameter-efficient federated methods.
major comments (2)
- [Theoretical Analysis] Theoretical Analysis section: the claim that per-prompt semantic consensus yields pseudo-labels whose supervision signal is comparable to that obtained from parameter aggregation is load-bearing, yet no derivation, information-theoretic bound, or stability argument is supplied showing that the chosen semantic mapping and consensus operator preserve task-relevant information across heterogeneous client generators.
- [Empirical Results] Empirical Results section: the reported matching of strong baselines with orders-of-magnitude communication reduction is central, but the manuscript must explicitly report (i) the precise performance metrics (e.g., perplexity or task accuracy) on the target benchmarks, (ii) the communication volume actually measured, and (iii) an ablation on the semantic representation and consensus operator to demonstrate that the pseudo-label quality does not degrade under architectural heterogeneity.
minor comments (1)
- [Abstract] The abstract states an analytic factor of 1006 for Llama3.1-405B; the corresponding derivation should be cross-referenced to a specific equation or appendix entry for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the constructive major comments. We address each point below with clarifications from the manuscript and commit to targeted revisions that strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [Theoretical Analysis] Theoretical Analysis section: the claim that per-prompt semantic consensus yields pseudo-labels whose supervision signal is comparable to that obtained from parameter aggregation is load-bearing, yet no derivation, information-theoretic bound, or stability argument is supplied showing that the chosen semantic mapping and consensus operator preserve task-relevant information across heterogeneous client generators.
Authors: We thank the referee for this observation. Section 4 develops a theoretical argument that the semantic mapping induces an equivalence relation on outputs and that the consensus operator (averaging in the embedding space) minimizes a divergence measure while preserving task-relevant signals, with an informal equivalence shown to parameter aggregation under perfect alignment. We acknowledge that an explicit information-theoretic bound and stability analysis would make the argument more rigorous. In the revision we will add a derivation bounding the mutual information loss via the data processing inequality applied to the embedding map, together with a Lipschitz-based stability result that holds across heterogeneous generators. revision: yes
-
Referee: [Empirical Results] Empirical Results section: the reported matching of strong baselines with orders-of-magnitude communication reduction is central, but the manuscript must explicitly report (i) the precise performance metrics (e.g., perplexity or task accuracy) on the target benchmarks, (ii) the communication volume actually measured, and (iii) an ablation on the semantic representation and consensus operator to demonstrate that the pseudo-label quality does not degrade under architectural heterogeneity.
Authors: We agree that explicit reporting improves clarity and reproducibility. The manuscript already demonstrates matching of strong baselines together with the analytic communication reduction (e.g., 1006× for Llama-3.1-405B), but we will revise the empirical section to tabulate absolute metrics (perplexity on WikiText-103 and accuracy on selected GLUE tasks), report the precise measured communication volumes in bytes for each run, and add an ablation study that varies the semantic encoder and consensus operator (mean, median, and weighted variants) while using heterogeneous client architectures (Llama-3 and Mistral families). These additions will directly address the robustness concern. revision: yes
Circularity Check
No load-bearing circularity; protocol defined as independent alternative
full rationale
The paper introduces a behavior-mediated protocol whose communication scaling follows directly from the definition (outputs on fixed public prompts, semantic mapping, consensus pseudo-labels). This is definitional rather than a derived prediction. No equations reduce claimed performance to quantities fitted inside the paper. Theoretical analysis and empirical comparisons are presented as external validation. A single minor self-citation appears but is not load-bearing for the central claims about heterogeneous architectures or communication reduction. The utility of the pseudo-labels is an empirical question, not enforced by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Model outputs on a shared prompt set can be meaningfully mapped to a semantic representation space for consensus formation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The server maps these outputs into a semantic representation space, forms a per-prompt semantic consensus, and returns pseudo-labels for further local fine-tuning.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
This formulation fundamentally changes the communication scaling of federated LLM fine-tuning. The amount of information exchanged depends only on the public prompt budget and the size of the communicated behaviors, independent of model size.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Towards building the federatedgpt: Federated instruction tuning , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
work page 2024
-
[2]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Fedid: Federated interactive distillation for large-scale pretraining language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
- [3]
-
[4]
Artificial intelligence and statistics , pages=
Communication-efficient learning of deep networks from decentralized data , author=. Artificial intelligence and statistics , pages=. 2017 , organization=
work page 2017
-
[5]
Advances in Neural Information Processing Systems , volume=
Flora: Federated fine-tuning large language models with heterogeneous low-rank adaptations , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Advances in Neural Information Processing Systems , volume=
Federated fine-tuning of large language models under heterogeneous tasks and client resources , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
arXiv preprint arXiv:2401.06432 , year=
Heterogeneous lora for federated fine-tuning of on-device foundation models , author=. arXiv preprint arXiv:2401.06432 , year=
-
[8]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Lora-fair: Federated lora fine-tuning with aggregation and initialization refinement , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[9]
Towards robust and efficient federated low-rank adaptation with heterogeneous clients , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[10]
arXiv preprint arXiv:2310.01467 , year=
Fedbpt: Efficient federated black-box prompt tuning for large language models , author=. arXiv preprint arXiv:2310.01467 , year=
-
[11]
Stanford alpaca: An instruction-following llama model , author=. 2023 , publisher=
work page 2023
-
[12]
Instruction-Following Evaluation for Large Language Models
Instruction-following evaluation for large language models , author=. arXiv preprint arXiv:2311.07911 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct
Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct , author=. arXiv preprint arXiv:2308.09583 , year=
-
[14]
HuggingFace repository , howpublished =
OpenOrca: An Open Dataset of GPT Augmented FLAN Reasoning Traces , author =. HuggingFace repository , howpublished =. 2023 , publisher =
work page 2023
-
[15]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[16]
Vicuna: An open-source chatbot impressing gpt-4 with 90\ author=. See https://vicuna. lmsys. org (accessed 14 April 2023) , volume=
work page 2023
-
[17]
Joint European conference on machine learning and knowledge discovery in databases , pages=
Efficient decentralized deep learning by dynamic model averaging , author=. Joint European conference on machine learning and knowledge discovery in databases , pages=. 2018 , organization=
work page 2018
-
[18]
Communication-efficient distributed online learning with kernels , author=. ECMLPKDD , pages=. 2016 , organization=
work page 2016
-
[19]
Michael Kamp , title =
-
[20]
Enhancing chat language models by scaling high-quality instructional conversations
Enhancing Chat Language Models by Scaling High-quality Instructional Conversations , author=. arXiv preprint arXiv:2305.14233 , year=
-
[21]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[22]
Raphael Fischer , year =. Ground-Truthing. doi:10.48550/arXiv.2509.22092 , url =
-
[23]
SIAM Journal on Optimization , volume =
Stochastic First- and Zeroth-Order Methods for Nonconvex Stochastic Programming , author =. SIAM Journal on Optimization , volume =. 2013 , doi =. 1309.5549 , archivePrefix =
-
[24]
Proceedings of the 37th International Conference on Machine Learning , series =
SCAFFOLD: Stochastic Controlled Averaging for Federated Learning , author =. Proceedings of the 37th International Conference on Machine Learning , series =. 2020 , publisher =
work page 2020
-
[25]
International Conference on Learning Representations , year =
On the Convergence of FedAvg on Non-IID Data , author =. International Conference on Learning Representations , year =. 1907.02189 , archivePrefix =
-
[26]
Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security , pages =
Deep Learning with Differential Privacy , author =. Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security , pages =. 2016 , doi =. 1607.00133 , archivePrefix =
-
[27]
Advances in Neural Information Processing Systems , year =
Understanding Gradient Clipping in Private SGD: A Geometric Perspective , author =. Advances in Neural Information Processing Systems , year =. 2006.15429 , archivePrefix =
-
[28]
Federated Optimization in Heterogeneous Networks , author =. 2018 , eprint =
work page 2018
-
[29]
Journal of Machine Learning Research , volume =
Covariate Shift Adaptation by Importance Weighted Cross Validation , author =. Journal of Machine Learning Research , volume =. 2007 , url =
work page 2007
-
[30]
An Information-theoretical Approach to Semi-supervised Learning under Covariate-shift , author =. Proceedings of The 25th International Conference on Artificial Intelligence and Statistics , series =. 2022 , publisher =. 2202.12123 , archivePrefix =
-
[31]
Advances in Neural Information Processing Systems , pages =
Learning with Noisy Labels , author =. Advances in Neural Information Processing Systems , pages =. 2013 , url =
work page 2013
-
[32]
International Conference on Learning Representations , year =
Theoretical Analysis of Self-Training with Deep Networks on Unlabeled Data , author =. International Conference on Learning Representations , year =. 2010.03622 , archivePrefix =
-
[33]
arXiv preprint arXiv:2410.01948 , year=
Differentially private parameter-efficient fine-tuning for large asr models , author=. arXiv preprint arXiv:2410.01948 , year=
-
[34]
arXiv preprint arXiv:2602.16936 , year=
Heterogeneous Federated Fine-Tuning with Parallel One-Rank Adaptation , author=. arXiv preprint arXiv:2602.16936 , year=
-
[35]
arXiv preprint arXiv:2603.08058 , year=
Stabilized Fine-Tuning with LoRA in Federated Learning: Mitigating the Side Effect of Client Size and Rank via the Scaling Factor , author=. arXiv preprint arXiv:2603.08058 , year=
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Little is enough: Boosting privacy by sharing only hard labels in federated semi-supervised learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[37]
Advances in Neural Information Processing Systems , volume=
Distributed distillation for on-device learning , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.