Recognition: no theorem link
Sobolev Regularized MMD Gradient Flow
Pith reviewed 2026-05-13 05:53 UTC · model grok-4.3
The pith
Sobolev regularization on the MMD witness function yields global convergence guarantees for the gradient flow without isoperimetric assumptions on the target.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Sobolev-regularized MMD gradient flow converges globally because the added gradient penalty enforces a regularity condition on the difference between kernel mean embeddings; this condition directly controls the flow dynamics and replaces the need for isoperimetric inequalities on the target distribution. The same construction applies to both sampling and generative modeling.
What carries the argument
The Sobolev gradient penalty applied to the MMD witness function, which regularizes the objective to enforce the kernel-mean-embedding regularity condition that drives global convergence.
If this is right
- Global convergence holds in continuous time under the regularity condition on kernel mean embeddings.
- Global convergence also holds for the discrete-time implementation of the flow.
- The same flow can be used for both Stein-kernel sampling from unnormalized targets and for generative modeling.
- Convergence proofs no longer require isoperimetric assumptions on the target distribution.
Where Pith is reading between the lines
- The regularity condition may be easier to verify or enforce for common kernels such as the Gaussian kernel in practice.
- Similar gradient penalties could be applied to other discrepancy measures to obtain global convergence results.
- The approach may stabilize training in high-dimensional generative models where geometric assumptions are difficult to check.
Load-bearing premise
The difference between kernel mean embeddings of the current distribution and the target must satisfy a regularity condition that controls the flow dynamics.
What would settle it
Construct a simple low-dimensional example with a standard kernel where the regularity condition on the kernel mean embedding difference is violated, then run the flow and check whether it fails to converge globally.
Figures





read the original abstract
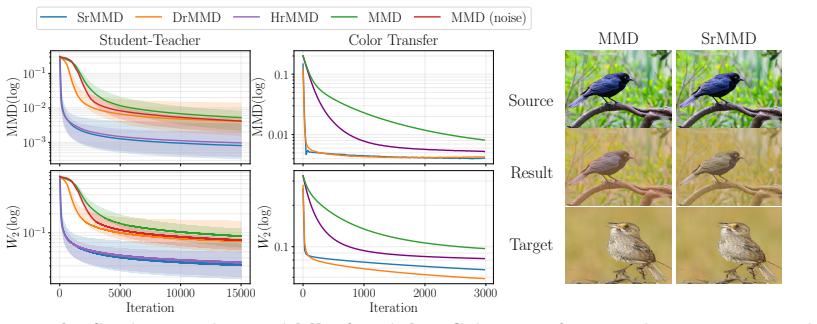
We propose Sobolev-regularized Maximum Mean Discrepancy (SrMMD) gradient flow, a regularized variant of maximum mean discrepancy (MMD) gradient flow based on a gradient penalty on the witness function. The proposed regularization mitigates the non-convexity of the MMD objective and yields provable \emph{global} convergence guarantees in MMD in both continuous and discrete time. A more surprising appeal is that our convergence analysis does not rely on isoperimetric assumptions on the target distribution. Instead, it is based on a regularity condition on the difference between kernel mean embeddings. A key highlight of the proposed flow is that it is applicable in both sampling (from an unnormalized target distribution) -- using Stein kernels -- and generative modeling settings, unlike previous works, where a gradient flow is suitable for only generative modeling or sampling but not both. The effectiveness of the proposed flow is empirically verified on a broad range of tasks in both generative modelling and sampling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Sobolev-regularized MMD (SrMMD) gradient flow, obtained by adding a Sobolev-norm penalty on the gradient of the witness function to the standard MMD objective. It claims that this regularization yields provable global convergence to the minimizer of the MMD in both continuous-time and discrete-time settings, with the analysis resting on a regularity condition on the difference of kernel mean embeddings rather than isoperimetric inequalities on the target. The method is presented as applicable to both Stein-kernel sampling from unnormalized densities and to generative modeling, with empirical results on a range of tasks in each regime.
Significance. If the regularity condition holds for the kernels and target distributions used in the sampling and generative-modeling experiments, the work would supply a single gradient-flow framework with global convergence guarantees that covers both settings, which is a notable technical contribution to kernel-based sampling and generative modeling. The avoidance of isoperimetric assumptions and the provision of both continuous- and discrete-time analyses are positive features.
major comments (3)
- [§4, Theorem 4.1] §4, Theorem 4.1 (continuous-time convergence): the global convergence statement is conditioned on the regularity assumption (Assumption 4.1) that bounds the difference of kernel mean embeddings in the Sobolev norm; the paper does not derive sufficient conditions under which this assumption holds for the Stein kernel or for the unnormalized target distributions appearing in the sampling experiments, so the claimed guarantees do not automatically transfer to those settings.
- [§5, Theorem 5.2] §5, Theorem 5.2 (discrete-time convergence): the same regularity condition is invoked to control the discretization error; without verification that the condition is satisfied by the kernels and distributions used in the generative-modeling and sampling tasks, the discrete-time global convergence claim remains conditional rather than unconditional.
- [§6] §6 (experiments): the empirical results on sampling and generative modeling are presented as verification of the method, yet no diagnostic is reported that checks whether the regularity condition on kernel-mean-embedding differences holds for the chosen kernels and targets; this leaves open the possibility that the observed performance is not explained by the proved convergence regime.
minor comments (2)
- [§3] The notation for the Sobolev-regularized witness function and its gradient penalty is introduced without an explicit equation reference in the main text; adding a numbered display equation would improve readability.
- [§1] Several citations to prior MMD gradient-flow works are given in the introduction but lack page or theorem numbers when specific claims are contrasted; adding these would help readers locate the precise points of difference.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We appreciate the recognition of our framework's ability to provide global convergence guarantees for MMD gradient flows in both sampling and generative modeling without isoperimetric assumptions. We address each major comment below and commit to revisions that strengthen the presentation of the regularity condition.
read point-by-point responses
-
Referee: [§4, Theorem 4.1] §4, Theorem 4.1 (continuous-time convergence): the global convergence statement is conditioned on the regularity assumption (Assumption 4.1) that bounds the difference of kernel mean embeddings in the Sobolev norm; the paper does not derive sufficient conditions under which this assumption holds for the Stein kernel or for the unnormalized target distributions appearing in the sampling experiments, so the claimed guarantees do not automatically transfer to those settings.
Authors: We agree that the paper would benefit from explicit sufficient conditions for Assumption 4.1 in the Stein-kernel sampling setting. In the revision we will add a new proposition deriving sufficient conditions on the target density (smoothness and moment bounds) under which the Sobolev-norm difference of kernel mean embeddings remains controlled for standard Stein kernels. This will make the transfer of the continuous-time guarantees to the sampling experiments explicit rather than implicit. revision: yes
-
Referee: [§5, Theorem 5.2] §5, Theorem 5.2 (discrete-time convergence): the same regularity condition is invoked to control the discretization error; without verification that the condition is satisfied by the kernels and distributions used in the generative-modeling and sampling tasks, the discrete-time global convergence claim remains conditional rather than unconditional.
Authors: We acknowledge the same point applies to the discrete-time result. The revision will extend the new proposition on sufficient conditions to also bound the discretization error term, thereby rendering the discrete-time global convergence statement applicable to the kernels and distributions appearing in both the generative-modeling and sampling experiments. revision: yes
-
Referee: [§6] §6 (experiments): the empirical results on sampling and generative modeling are presented as verification of the method, yet no diagnostic is reported that checks whether the regularity condition on kernel-mean-embedding differences holds for the chosen kernels and targets; this leaves open the possibility that the observed performance is not explained by the proved convergence regime.
Authors: We agree that an empirical check of the regularity condition would strengthen the link between theory and experiments. In the revised manuscript we will add a diagnostic subsection (or appendix) that numerically evaluates the Sobolev norm of the difference of kernel mean embeddings on the specific kernels and target distributions used in the sampling and generative-modeling tasks, confirming that the observed performance occurs inside the regime covered by our convergence theorems. revision: yes
Circularity Check
No significant circularity; convergence is conditional on an external regularity assumption
full rationale
The paper states that global convergence of the Sobolev-regularized MMD flow holds under a regularity condition on the difference between kernel mean embeddings, explicitly presented as an alternative to isoperimetric assumptions on the target. This condition is not defined in terms of the flow itself, nor is any prediction or result fitted to data and then renamed as a derived guarantee. No self-citations are invoked as load-bearing uniqueness theorems, and the analysis does not reduce any claimed result to its own inputs by construction. The derivation chain remains self-contained as a conditional theorem under the stated regularity, with no evidence of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bonnet, Beno. Differential inclusions in. Journal of Differential Equations , volume=. 2021 , publisher=
work page 2021
-
[2]
Journal of Machine Learning Research , volume=
Targeted separation and convergence with kernel discrepancies , author=. Journal of Machine Learning Research , volume=
-
[3]
Liu, Qiang and Lee, Jason and Jordan, Michael , booktitle=. A kernelized. 2016 , organization=
work page 2016
-
[4]
International conference on machine learning , pages=
A kernel test of goodness of fit , author=. International conference on machine learning , pages=. 2016 , organization=
work page 2016
-
[5]
Sutherland and Michael Arbel and Arthur Gretton , booktitle=
Mikołaj Bińkowski and Dougal J. Sutherland and Michael Arbel and Arthur Gretton , booktitle=. Demystifying. 2018 , url=
work page 2018
-
[6]
Gulrajani, Ishaan and Ahmed, Faruk and Arjovsky, Martin and Dumoulin, Vincent and Courville, Aaron , journal=. Improved training of
-
[7]
Advances in applied probability , volume=
Integral probability metrics and their generating classes of functions , author=. Advances in applied probability , volume=. 1997 , publisher=
work page 1997
-
[8]
Chen, Zonghao and Mustafi, Aratrika and Glaser, Pierre and Korba, Anna and Gretton, Arthur and Sriperumbudur, Bharath K , journal=. (
-
[9]
Foundations and Trends in Machine Learning , volume=
Kernel mean embedding of distributions: A review and beyond , author=. Foundations and Trends in Machine Learning , volume=. 2017 , publisher=
work page 2017
- [10]
-
[11]
Advances in neural information processing systems , volume=
Random features for large-scale kernel machines , author=. Advances in neural information processing systems , volume=
- [12]
-
[13]
International Conference on Machine Learning , pages=
Measuring sample quality with kernels , author=. International Conference on Machine Learning , pages=. 2017 , organization=
work page 2017
-
[14]
Scattered Data Approximation , publisher=
Wendland, Holger , year=. Scattered Data Approximation , publisher=
-
[15]
Perturbation Theory for Linear Operators , author=. 2013 , publisher=
work page 2013
-
[16]
Mirror and preconditioned gradient descent in
Bonet, Cl. Mirror and preconditioned gradient descent in. Advances in Neural Information Processing Systems , volume=. 2024 , editor=
work page 2024
-
[17]
Improved Finite-Particle Convergence Rates for
Sayan Banerjee and Krishna Balasubramanian and Promit Ghosal , booktitle=. Improved Finite-Particle Convergence Rates for. 2025 , url=
work page 2025
-
[18]
Annals of Mathematics , volume=
Note on the derivatives with respect to a parameter of the solutions of a system of differential equations , author=. Annals of Mathematics , volume=. 1919 , publisher=
work page 1919
-
[19]
Convex analysis of the mean field
Nitanda, Atsushi and Wu, Denny and Suzuki, Taiji , booktitle=. Convex analysis of the mean field. 2022 , editor =
work page 2022
-
[20]
Analysis and Geometry of Markov Diffusion Operators , author=. 2014 , publisher=
work page 2014
-
[21]
Li, Chun-Liang and Chang, Wei-Cheng and Cheng, Yu and Yang, Yiming and Poczos, Barnabas , booktitle=. 2017 , editor=
work page 2017
-
[22]
Arbel, Michael and Sutherland, Danica J and Bi\'. On gradient regularizers for. Advances in Neural Information Processing Systems , volume=. 2018 , publisher=
work page 2018
- [23]
-
[24]
SIAM Journal on Mathematics of Data Science , volume=
Lipschitz-regularized gradient flows and generative particle algorithms for high-dimensional scarce data , author=. SIAM Journal on Mathematics of Data Science , volume=. 2024 , publisher=
work page 2024
-
[25]
arXiv preprint arXiv:2410.20622 , year=
Kernel approximation of Fisher-Rao gradient flows , author=. arXiv preprint arXiv:2410.20622 , year=
-
[26]
arXiv preprint arXiv:2411.00214 , year=
Inclusive KL Minimization: A Wasserstein-Fisher-Rao Gradient Flow Perspective , author=. arXiv preprint arXiv:2411.00214 , year=
-
[27]
User-friendly guarantees for the
Dalalyan, Arnak S and Karagulyan, Avetik , journal=. User-friendly guarantees for the. 2019 , publisher=
work page 2019
-
[28]
Bounding the error of discretized
Dalalyan, Arnak S and Karagulyan, Avetik and Riou-Durand, Lionel , journal=. Bounding the error of discretized
-
[29]
Further and stronger analogy between sampling and optimization: Langevin
Dalalyan, Arnak , booktitle=. Further and stronger analogy between sampling and optimization: Langevin. 2017 , organization=
work page 2017
-
[30]
Wasserstein gradient flows for
Stein, Viktor and Neumayer, Sebastian and Rux, Nicolaj and Steidl, Gabriele , journal=. Wasserstein gradient flows for. 2025 , publisher=
work page 2025
-
[31]
Denoising Diffusion Probabilistic Models , volume =
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , booktitle =. Denoising Diffusion Probabilistic Models , volume =. 2020 , editor=
work page 2020
-
[32]
The Annals of Statistics , number =
Dino Sejdinovic and Bharath Sriperumbudur and Arthur Gretton and Kenji Fukumizu , title =. The Annals of Statistics , number =
-
[33]
Sebastian Mika and Gunnar R. Neural Networks for Signal Processing IX: Proceedings of the 1999 IEEE Signal Processing Society Workshop (Cat. No.98TH8468) , title=. 1999 , pages=
work page 1999
-
[34]
Journal of Machine Learning Research , volume=
A kernel two-sample test , author=. Journal of Machine Learning Research , volume=. 2012 , publisher=
work page 2012
-
[35]
Siwan Boufadène and François-Xavier Vialard , journal =. On the global convergence of. 2025 , doi =
work page 2025
-
[36]
Wasserstein steepest descent flows of discrepancies with
Hertrich, Johannes and Gr. Wasserstein steepest descent flows of discrepancies with. Journal of Mathematical Analysis and Applications , volume=. 2024 , publisher=
work page 2024
-
[37]
International Conference on Learning Representations , year=
Refining Deep Generative Models via Discriminator Gradient Flow , author=. International Conference on Learning Representations , year=
-
[38]
Fourth Symposium on Advances in Approximate Bayesian Inference , year=
Variational Likelihood-Free Gradient Descent , author=. Fourth Symposium on Advances in Approximate Bayesian Inference , year=
-
[39]
International Conference on Machine Learning , pages=
Deep generative learning via variational gradient flow , author=. International Conference on Machine Learning , pages=. 2019 , publisher=
work page 2019
-
[40]
An almost constant lower bound of the isoperimetric coefficient in the
Chen, Yuansi , journal=. An almost constant lower bound of the isoperimetric coefficient in the. 2021 , publisher=
work page 2021
-
[41]
Journal of Machine Learning Research , volume=
Sobolev norm learning rates for regularized least-squares algorithms , author=. Journal of Machine Learning Research , volume=
-
[42]
Transactions of the American Mathematical Society , volume=
Theory of reproducing kernels , author=. Transactions of the American Mathematical Society , volume=
-
[43]
General state space Markov chains and MCMC algorithms , author=. 2004 , journal=
work page 2004
-
[44]
and Salim, Adil and Zhang, Shunshi , booktitle=
Balasubramanian, Krishna and Chewi, Sinho and Erdogdu, Murat A. and Salim, Adil and Zhang, Shunshi , booktitle=. Towards a theory of non-log-concave sampling:. 2022 , organization=
work page 2022
-
[45]
The 22nd International Conference on Artificial Intelligence and Statistics , pages=
Sobolev descent , author=. The 22nd International Conference on Artificial Intelligence and Statistics , pages=. 2019 , organization=
work page 2019
-
[46]
Kelly, Markelle and Longjohn, Rachel and Nottingham, Kolby , title =. 2024 , howpublished =
work page 2024
-
[47]
Proceedings of the Twenty-Sixth Conference on Uncertainty in Artificial Intelligence , pages=
Super-samples from kernel herding , author=. Proceedings of the Twenty-Sixth Conference on Uncertainty in Artificial Intelligence , pages=
-
[48]
Chen, Zonghao and Naslidnyk, Masha and Gretton, Arthur and Briol, Francois-Xavier , booktitle=. Conditional. 2024 , organization=
work page 2024
- [49]
-
[50]
Philosophical Transactions of the Royal Society A , volume =
Duong, Richard and Rux, Nicolaj and Stein, Viktor and Steidl, Gabriele , title =. Philosophical Transactions of the Royal Society A , volume =. 2025 , doi =
work page 2025
-
[51]
Lecture Notes of the 18th International Internet seminar, version , volume=
Form methods for evolution equations , author=. Lecture Notes of the 18th International Internet seminar, version , volume=
-
[52]
Douglas, Ronald G. , journal=. On majorization, factorization, and range inclusion of operators on. 1966 , publisher=
work page 1966
-
[53]
Ordinary differential equations and dynamical systems , author=. 2012 , publisher=
work page 2012
-
[54]
Chizat, L. Quantitative Convergence of. arXiv preprint arXiv:2603.01977 , year=
-
[55]
Altekr. Neural. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[56]
Duong, Richard and Stein, Viktor and Beinert, Robert and Hertrich, Johannes and Steidl, Gabriele , journal=. Wasserstein gradient flows of. 2026 , publisher=
work page 2026
-
[57]
Posterior Sampling Based on Gradient Flows of the
Hagemann, Paul and Hertrich, Johannes and Altekr. Posterior Sampling Based on Gradient Flows of the. The Twelfth International Conference on Learning Representations , year=
-
[58]
Controlling moments with kernel
Kanagawa, Heishiro and Barp, Alessandro and Gretton, Arthur and Mackey, Lester , journal=. Controlling moments with kernel. 2025 , publisher=
work page 2025
-
[59]
Heusel, Martin and Ramsauer, Hubert and Unterthiner, Thomas and Nessler, Bernhard and Hochreiter, Sepp , journal=
-
[60]
Finlay, Chris and Jacobsen, J. How to train your neural. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[61]
Minimax optimal goodness-of-fit testing with kernel
Hagrass, Omar and Sriperumbudur, Bharath and Balasubramanian, Krishnakumar , journal=. Minimax optimal goodness-of-fit testing with kernel. 2026 , publisher=
work page 2026
-
[62]
Advances in neural information processing systems , volume=
Stabilizing training of generative adversarial networks through regularization , author=. Advances in neural information processing systems , volume=
-
[63]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Sampling from multi-modal distributions with polynomial query complexity in fixed dimension via reverse diffusion , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[64]
Huang, Xunpeng and Dong, Hanze and Hao, Yifan and Ma, Yi-An and Zhang, Tong , booktitle=. REVERSE DIFFUSION
-
[65]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[66]
Forty-second International Conference on Machine Learning , year=
Nested Expectations with Kernel Quadrature , author=. Forty-second International Conference on Machine Learning , year=
-
[67]
Li, Zhu and Meunier, Dimitri and Mollenhauer, Mattes and Gretton, Arthur , journal=. Towards optimal
-
[68]
Advances in Neural Information Processing Systems , volume=
Optimal rates for vector-valued spectral regularization learning algorithms , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
On converse and saturation results for
Neubauer, Andreas , journal=. On converse and saturation results for. 1997 , publisher=
work page 1997
- [70]
-
[71]
Menz, Georg and Schlichting, Andr. POINCAR. The Annals of Probability , volume=
-
[72]
On the convergence of gradient descent in
Mroueh, Youssef and Nguyen, Truyen , booktitle=. On the convergence of gradient descent in. 2021 , organization=
work page 2021
- [73]
-
[74]
Towards a complete analysis of
Mousavi-Hosseini, Alireza and Farghly, Tyler K and He, Ye and Balasubramanian, Krishna and Erdogdu, Murat A , booktitle=. Towards a complete analysis of. 2023 , organization=
work page 2023
-
[75]
Van Erven, Tim and Harremos, Peter , journal=. R. 2014 , publisher=
work page 2014
-
[76]
Birrell, Jeremiah and Dupuis, Paul and Katsoulakis, Markos A and Pantazis, Yannis and Rey-Bellet, Luc , journal=. (f,
-
[77]
Rapid convergence of the unadjusted
Vempala, Santosh and Wibisono, Andre , booktitle=. Rapid convergence of the unadjusted. 2019 , editor=
work page 2019
- [78]
-
[79]
Brenier, Yann , journal=. D
-
[80]
Probability Theory: A Comprehensive Course , author=. 2013 , publisher=
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.