Recognition: no theorem link
Procedural-skill SFT across capacity tiers: A W-Shaped pre-SFT Trajectory and Regime-Asymmetric Mechanism on 0.8B-4B Qwen3.5 Models
Pith reviewed 2026-05-13 05:40 UTC · model grok-4.3
The pith
SFT provides roughly uniform procedural skill gains across 0.8B to 4B models, but pre-SFT performance follows a W-shaped pattern that shapes final outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
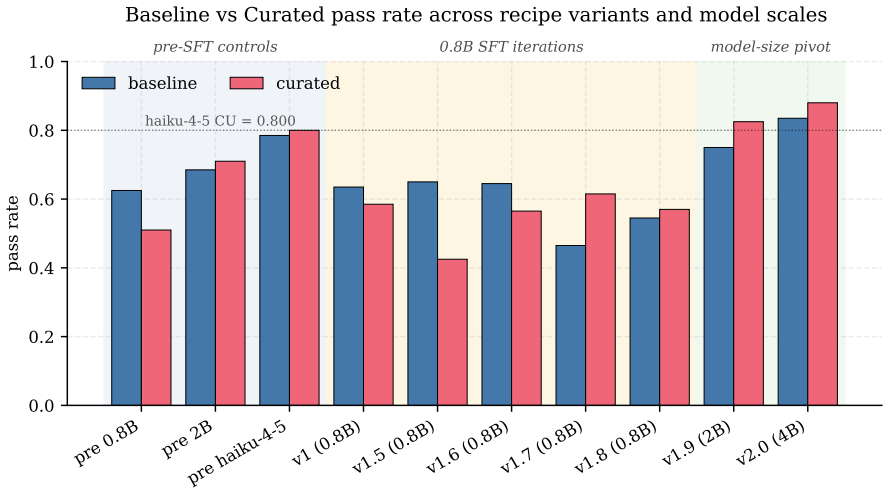
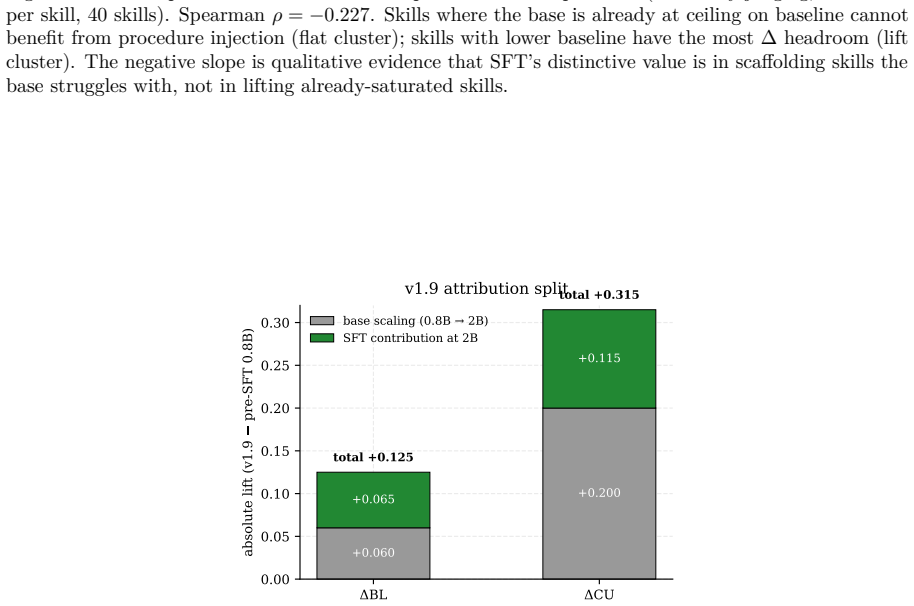
Under matched-path LLM-only scoring, the SFT-attributable procedural-Δ lift is roughly uniform across sizes: +0.070 / +0.040 / +0.075 at 0.8B / 2B / 4B. Variation in post-SFT Δ (−0.005, +0.100, +0.065) is dominated by a W-shaped pre-SFT base trajectory (−0.075, +0.060, −0.010, Haiku-4-5 at +0.030): the 5-step procedure hurts 0.8B and 4B, helps 2B, and helps frontier Haiku modestly. SFT works hardest in absolute terms where the base struggles with the procedure.
What carries the argument
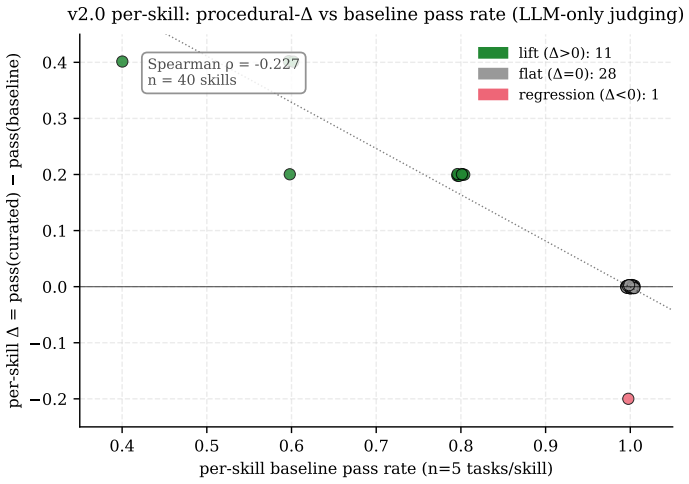
The W-shaped pre-SFT base trajectory across capacity tiers that creates a regime-asymmetric compensation pattern under SFT.
Load-bearing premise
The 200-task holdout and LLM judge-pass metric measure true procedural skill without residual bias from format-compliance artifacts or single-seed variability.
What would settle it
Measuring the same procedural-Δ lifts and pre-SFT trajectory on 8B and 14B models would confirm or refute the claim of uniform SFT gains paired with continuing W-shaped base variation.
Figures


read the original abstract
We measure procedural-skill SFT contribution across three Qwen3.5 dense scales (0.8B, 2B, 4B) on a 200-task / 40-skill holdout, with Claude Haiku 4.5 as a frontier reference. The corpus is 353 rows of (task + procedural-skill block, Opus chain-of-thought, judge-pass) demonstrations. \textbf{Main finding.} Under matched-path LLM-only scoring, the SFT-attributable procedural-$\Delta$ lift is roughly uniform across sizes: $+0.070$ / $+0.040$ / $+0.075$ at 0.8B / 2B / 4B. Variation in post-SFT $\Delta$ ($-0.005$, $+0.100$, $+0.065$) is dominated by a W-shaped pre-SFT base trajectory ($-0.075$, $+0.060$, $-0.010$, Haiku-4-5 at $+0.030$): the 5-step procedure hurts 0.8B and 4B, helps 2B, and helps frontier Haiku modestly. SFT works hardest in absolute terms where the base struggles with the procedure -- a regime-asymmetric pattern with a falsifiable prediction at 8B/14B. \textbf{Methodology.} (i) A bench format-compliance artifact: 83.5\% of the holdout uses a deterministic \texttt{ANSWER}-line extractor that under-counts free-form conclusions; an LLM-only re-judge reveals it was systematically biased against \CU. (ii) A negative-iteration sequence at 0.8B: five recipe variants cluster post-SFT \CU{} pass-rate within a 2\,pp band, constraining the absolute-pass-rate ceiling to base capacity rather than recipe. \textbf{Cross-family validation.} GPT-5.4 via OpenRouter on all 7 configurations (2800 paired episodes) agrees on the direction of every per-student finding: Cohen's $\kappa \geq 0.754$, agreement $\geq 93.25\%$. Earlier ``format-only at 0.8B'' and ``shrinking SFT at 4B'' framings were path-mismatch artifacts; this paper supersedes both (Appendix~\ref{sec:appendix-path}). Single-seed; threats in \S\ref{sec:threats}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically measures the contribution of procedural-skill supervised fine-tuning (SFT) across Qwen3.5 dense models at 0.8B, 2B, and 4B scales on a 200-task/40-skill holdout set. Under matched-path LLM-only scoring with Claude Haiku 4.5 (and GPT-5.4 cross-validation), it reports roughly uniform SFT-attributable procedural-Δ lifts of +0.070 / +0.040 / +0.075, with post-SFT variation dominated by a W-shaped pre-SFT base trajectory (-0.075 / +0.060 / -0.010). This supports a regime-asymmetric mechanism in which SFT provides the largest absolute benefit where the base model struggles with the 5-step procedure, along with a falsifiable prediction for 8B/14B scales. The work also documents and mitigates an 83.5% format-compliance artifact from a deterministic extractor and supersedes prior path-mismatch framings.
Significance. If the reported deltas and W-shaped trajectory prove robust, the results would provide a capacity-tiered view of SFT effects on procedural skills, showing that SFT compensates most where base performance is weakest rather than exhibiting uniform shrinkage or format-only gains. The cross-family validation (Cohen's κ ≥ 0.754, ≥93.25% agreement across 2800 episodes) and explicit artifact analysis are strengths that improve upon earlier mismatched-path comparisons. The falsifiable prediction at larger scales adds testability to the regime-asymmetric claim.
major comments (2)
- [§ref{sec:threats} and experimental methodology] §ref{sec:threats} and experimental setup: The central claims rest on small numerical deltas (SFT lifts of +0.070/+0.040/+0.075 and pre-SFT W-trajectory values of -0.075/+0.060/-0.010) obtained from single-seed training and single-run evaluation on the 200-task holdout. No standard errors, confidence intervals, or multi-seed statistics are provided, so it is impossible to determine whether the observed uniformity of lifts or the dominance of the pre-SFT trajectory exceeds run-to-run variance in training stochasticity and LLM-judge noise. This is load-bearing for the regime-asymmetric mechanism and the 8B/14B prediction.
- [Methodology on format-compliance artifact] Methodology paragraph on format-compliance artifact: Although the 83.5% deterministic ANSWER-line extractor bias is identified and addressed via LLM-only re-judge plus GPT-5.4 cross-validation, the manuscript does not report a sensitivity analysis quantifying how much the original bias (or the mitigation) shifts the per-size procedural-Δ values. Without this, residual bias cannot be ruled out as a contributor to the reported uniformity or W-shape.
minor comments (2)
- [Abstract and §1] The abbreviation CU (presumably 'correct under judge') and the exact definition of 'procedural-Δ' should be introduced with an explicit equation or formula on first use in the main text for reader clarity.
- [Results section] Table or figure presenting the per-size deltas would benefit from an additional column or row showing the raw pre-SFT and post-SFT pass rates alongside the Δ values to allow direct verification of the W-shape arithmetic.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We appreciate the emphasis on statistical robustness of the reported deltas and the need for sensitivity analysis on the format artifact. We address each major comment below and commit to revisions where feasible with existing data.
read point-by-point responses
-
Referee: [§ref{sec:threats} and experimental methodology] §ref{sec:threats} and experimental setup: The central claims rest on small numerical deltas (SFT lifts of +0.070/+0.040/+0.075 and pre-SFT W-trajectory values of -0.075/+0.060/-0.010) obtained from single-seed training and single-run evaluation on the 200-task holdout. No standard errors, confidence intervals, or multi-seed statistics are provided, so it is impossible to determine whether the observed uniformity of lifts or the dominance of the pre-SFT trajectory exceeds run-to-run variance in training stochasticity and LLM-judge noise. This is load-bearing for the regime-asymmetric mechanism and the 8B/14B prediction.
Authors: We acknowledge that all results are from single-seed training and single-run evaluation, as stated in the manuscript. Section §ref{sec:threats} already identifies training stochasticity and LLM-judge noise as limitations. The GPT-5.4 cross-validation (κ ≥ 0.754 across 2800 episodes) shows consistent directionality for every per-size finding, offering some robustness against judge noise. However, we lack multi-seed runs and cannot compute standard errors or confidence intervals without new experiments. We will expand the threats section to discuss run-to-run variance more explicitly and qualify the uniformity claim and 8B/14B prediction with this caveat. revision: partial
-
Referee: [Methodology on format-compliance artifact] Methodology paragraph on format-compliance artifact: Although the 83.5% deterministic ANSWER-line extractor bias is identified and addressed via LLM-only re-judge plus GPT-5.4 cross-validation, the manuscript does not report a sensitivity analysis quantifying how much the original bias (or the mitigation) shifts the per-size procedural-Δ values. Without this, residual bias cannot be ruled out as a contributor to the reported uniformity or W-shape.
Authors: We agree a quantitative sensitivity analysis is needed. While the LLM-only re-judge and GPT-5.4 validation mitigate the 83.5% extractor bias, we did not report how much the original versus mitigated scoring shifts the per-size SFT lifts or pre-SFT W-trajectory. In revision we will add this by recomputing the procedural-Δ values under both methods for each scale and tabulating the differences, directly testing whether residual bias could drive the uniformity or W-shape. revision: yes
- The request for standard errors, confidence intervals, and multi-seed statistics to assess whether deltas exceed run-to-run variance, as these require new training runs not present in the current single-seed experiments.
Circularity Check
No significant circularity
full rationale
The paper consists entirely of direct empirical measurements: procedural-Δ lifts are computed from pass-rate differences on a 200-task holdout using LLM judges (Claude Haiku 4.5 and GPT-5.4 cross-validation). No equations, fitted parameters, ansatzes, or derivations are presented; the W-shaped trajectory and regime-asymmetric claim are simply descriptive summaries of the observed deltas. No self-citations are invoked as load-bearing uniqueness theorems or to justify any modeling choice. The single-seed limitation and format-compliance artifact are acknowledged as threats to validity but do not create circular reduction of any result to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM judges (Claude Haiku 4.5 and GPT-5.4) provide reliable procedural-skill scores that match human judgment.
Reference graph
Works this paper leans on
-
[1]
D. Yu, S. Kaur, A. Gupta, J. Brown-Cohen, A. Goyal, S. Arora.Skill-Mix: A Flexible and Expandable Family of Evaluations for AI Models. NeurIPS 2024
work page 2024
- [2]
-
[3]
Li et al.SkillsBench: Benchmarking the Effectiveness of Skill Injection on LLMs. 2026
work page 2026
-
[4]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen.LoRA: Low-Rank Adaptation of Large Language Models. ICLR 2022
work page 2022
-
[5]
T. Dettmers, A. Pagnoni, A. Holtzman, L. Zettlemoyer.QLoRA: Efficient Finetuning of Quantized LLMs. NeurIPS 2023
work page 2023
-
[6]
L. Tunstall, E. Beeching, et al.TRL: Transformer Reinforcement Learning library, version≥0.18
-
[7]
L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, I. Stoica.Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. NeurIPS Datasets and Benchmarks 2023
work page 2023
-
[8]
S. Biderman, H. Schoelkopf, et al.Lessons from the Trenches on Reproducible Evaluation of Language Models. arXiv:2405.14782, 2024
-
[9]
A. Yang, A. Li, B. Yang, et al.Qwen3 Technical Report. arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Qwen Team.Qwen3.5: Accelerating Productivity with Native Multimodal Agents. Release blog and model cards, 2026.https://huggingface.co/Qwen/Qwen3.5-4B-Base. 12 A Path-mismatch resolution for pre-SFT 0.8B The original pre-SFT 0.8B baseline (baseline0.510/curated0 .565/∆+0 .055) was run via Ollama, not the same HuggingFace transformers path used for 2B/4B. Q...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.