Recognition: 1 theorem link
· Lean TheoremUnderstanding Sample Efficiency in Predictive Coding
Pith reviewed 2026-05-13 07:43 UTC · model grok-4.3
The pith
Predictive coding produces weight updates that align more closely with output errors than backpropagation, yielding higher sample efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
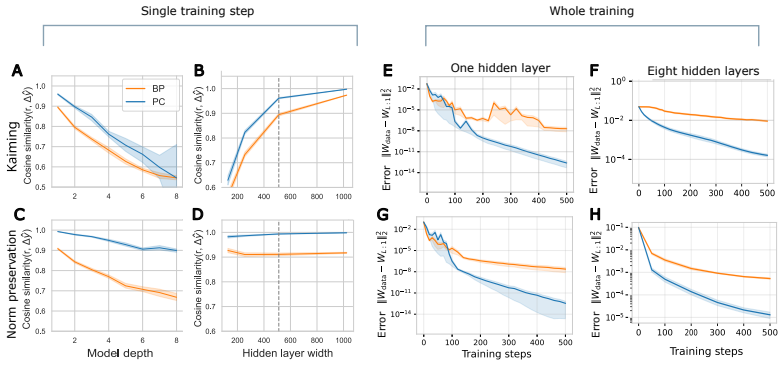
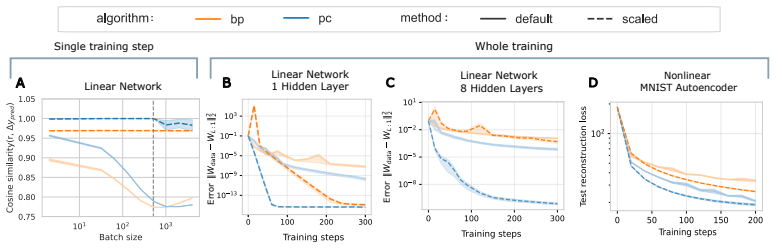
In deep linear networks the change in output produced by a predictive-coding update lies closer to the output prediction error than the change produced by a backpropagation update. Closed-form expressions for the alignment angle are obtained by tracking the forward and backward signals through the layers; these expressions show that predictive coding reaches the maximum possible alignment when its learning rates satisfy a simple ratio condition derived from the network's singular values.
What carries the argument
Target alignment, the cosine of the angle between the output change induced by a weight update and the output prediction error.
If this is right
- Fewer training samples are needed to reach a given performance level when using predictive coding instead of backpropagation.
- The efficiency gap widens as depth increases and narrows as width increases.
- Pre-training further increases the relative advantage of predictive coding.
- Optimal alignment in predictive coding occurs only when layer-wise learning rates obey a specific ratio determined by the singular values of the weight matrices.
Where Pith is reading between the lines
- The same alignment analysis could be applied to other local learning rules that avoid a global backward pass.
- In settings where data are scarce, such as continual learning or few-shot adaptation, predictive coding may reduce the number of required examples.
- Hardware implementations that support only local updates could exploit the higher alignment to reach target performance with lower energy cost.
Load-bearing premise
The exact formulas assume a deep linear network; the advantage in nonlinear networks rests on empirical observation rather than proof.
What would settle it
Train a deep linear network of depth 10 and width 5 with both methods on a regression task and measure whether predictive coding's target alignment remains higher than backpropagation's throughout training.
Figures








read the original abstract
Predictive Coding (PC) is an influential account of cortical learning. Much of recent work has focused on comparing PC to Backpropagation (BP) to find whether PC offers any advantages. Small scale experiments show that PC enables learning that is more sample efficient and effective in many contexts, though a thorough theoretical understanding of the phenomena remains elusive. To address this, we quantify the efficiency of learning in BP and PC through a metric called ``target alignment'', which measures how closely the change in the output of the network is aligned to the output prediction error. We then derive and empirically validate analytical expressions for target alignment in Deep Linear Networks. We show that learning in PC is more efficient than BP, which is especially pronounced in deep, narrow and pre-trained networks. We also derive exact conditions for guaranteed optimal target alignment in PC and validate our findings through experiments. We study full training trajectories of linear and non-linear models, and find the predicted benefits of PC persist in practice even when some assumptions are violated. Overall, this work provides a mechanistic understanding of the higher learning efficiency observed for PC over BP in previous works, and can guide how PC should be parametrised to learn most effectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces target alignment as a metric for sample efficiency and derives closed-form analytical expressions for it in deep linear networks under both backpropagation (BP) and predictive coding (PC). It shows that PC yields higher target alignment than BP, with the advantage most pronounced in deep, narrow, and pre-trained networks, and provides exact conditions guaranteeing optimal alignment in PC. These derivations are empirically validated on linear models; full training trajectories are then studied for both linear and nonlinear networks, where the efficiency benefits of PC are reported to persist even when linearity assumptions are violated.
Significance. If the results hold, the work supplies a mechanistic account of PC's sample-efficiency advantage over BP that is grounded in explicit derivations rather than post-hoc fitting. The closed-form expressions and exact optimality conditions for the linear case constitute a clear strength, as they yield falsifiable predictions about network depth, width, and initialization. The empirical demonstration that benefits survive in nonlinear regimes broadens the practical relevance for biologically inspired learning algorithms.
minor comments (3)
- [§3.2] §3.2: The transition from the linear-network derivation to the nonlinear experiments would benefit from an explicit statement of which quantities (e.g., the alignment metric itself) remain unchanged versus which are only observed empirically.
- [Figure 3] Figure 3 caption: the legend does not indicate whether the pre-trained curves start from the same initialization distribution as the from-scratch curves; this affects interpretation of the depth and width effects.
- [Table 2] Table 2: the reported R² values for the PC alignment fit lack confidence intervals or degrees of freedom, making it difficult to judge how tightly the closed-form expression matches the simulated trajectories.
Simulated Author's Rebuttal
We are grateful to the referee for the positive and accurate summary of our work, as well as the recommendation for minor revision. We note that no specific major comments were provided in the report. Accordingly, our point-by-point responses are not applicable, and we have no standing objections. We will proceed with minor revisions to the manuscript as appropriate.
Circularity Check
Derivations of target alignment in deep linear networks are first-principles calculations with no reduction to inputs by construction.
full rationale
The paper defines target alignment as a metric measuring alignment between output change and prediction error, then derives closed-form analytical expressions for this quantity specifically in deep linear networks. These steps are presented as direct calculations on network dynamics and learning rules rather than any fitted parameter being renamed as a prediction, self-definitional loop, or load-bearing self-citation. No equations reduce the claimed PC > BP efficiency advantage to the same quantities used to define alignment. The persistence of benefits in nonlinear cases is noted only empirically without a claimed derivation, but this does not create circularity in the linear analysis itself. The work therefore remains self-contained against external benchmarks with independent analytical content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Deep linear networks admit closed-form expressions for weight-update effects on output alignment
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We derive closed-form expressions for the change in prediction induced by PC and BP updates in DLNs and compare their target alignment.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
R. P. N. Rao and D. H. Ballard. Predictive coding in the visual cortex: A functional interpretation of some extra-classical receptive-field effects.Nature Neuroscience, 2(1):79–87, 1999
work page 1999
-
[2]
K. Friston. Learning and inference in the brain.Neural Networks, 16(9):1325–1352, 2003
work page 2003
-
[3]
R. Bogacz. A tutorial on the free-energy framework for modelling perception and learning. Journal of Mathematical Psychology, 76(Part B):198–211, 2017
work page 2017
-
[4]
D. E. Rumelhart, G. E. Hinton, and R. J. Williams. Learning representations by back-propagating errors.Nature, 323:533–536, 1986
work page 1986
-
[5]
I. Goodfellow, Y . Bengio, and A. Courville.Deep learning. MIT Press, Cambridge, MA, 2016
work page 2016
-
[6]
A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C. J. Burges, L. Bottou, and K. Q. Weinberger, editors,Advances in Neural Information Processing Systems, volume 25. Curran Associates, Inc., 2012
work page 2012
-
[7]
Y . Song, B. Millidge, T. Salvatori, T. Lukasiewicz, Z. Xu, and R. Bogacz. Inferring neural activ- ity before plasticity as a foundation for learning beyond backpropagation.Nature Neuroscience, 27(2):348–358, 2024
work page 2024
-
[8]
S. Amari. Natural gradient works efficiently in learning.Neural Computation, 10(2):251–276, 1998
work page 1998
-
[9]
A. Bernacchia, M. Lengyel, and G. Hennequin. Exact natural gradient in deep linear networks and its application to the nonlinear case. InAdvances in Neural Information Processing Systems, volume 31, 2018
work page 2018
-
[10]
D. Huh. Curvature-corrected learning dynamics in deep neural networks. InProceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020
work page 2020
-
[11]
Optimizing neural networks with kronecker-factored approx- imate curvature
James Martens and Roger Grosse. Optimizing neural networks with kronecker-factored approx- imate curvature. InInternational conference on machine learning, pages 2408–2417. PMLR, 2015
work page 2015
-
[12]
J. Martens. New insights and perspectives on the natural gradient method.Journal of Machine Learning Research, 21(146):1–76, 2020
work page 2020
-
[13]
A. Jnini and F. Vella. Dual natural gradient descent for scalable training of physics-informed neural networks, 2025
work page 2025
-
[14]
J. Müller and M. Zeinhofer. Achieving high accuracy with pinns via energy natural gradients, 2023
work page 2023
-
[15]
A. Saxe, J. McClelland, and S. Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. InInternational Conference on Learning Representations, 2014
work page 2014
- [16]
-
[17]
From lazy to rich: Exact learning dynamics in deep linear networks
Clementine Domine, Nicolas Anguita, Alexandra M Proca, Lukas Braun, Daniel Kunin, Pedro Mediano, and Andrew Saxe. From lazy to rich: Exact learning dynamics in deep linear networks. InInternational Conference on Learning Representations, volume 2025, pages 102485–102536, 2025
work page 2025
-
[18]
A theoretical framework for inference and learning in predictive coding networks
Beren Millidge, Yuhang Song, Tommaso Salvatori, Thomas Lukasiewicz, and Rafal Bogacz. A theoretical framework for inference and learning in predictive coding networks. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[19]
F. Innocenti, E. M. Achour, R. Singh, and C. L. Buckley. Only strict saddles in the energy landscape of predictive coding networks? InAdvances in Neural Information Processing Systems, volume 37, pages 53649–53683, 2024. 10
work page 2024
-
[20]
Ta-Chu Kao, Kristopher Jensen, Gido Van De Ven, Alberto Bernacchia, and Guillaume Hen- nequin. Natural continual learning: success is a journey, not (just) a destination.Advances in neural information processing systems, 34:28067–28079, 2021
work page 2021
- [21]
-
[22]
Alexander Meulemans, Francesco Carzaniga, Johan Suykens, João Sacramento, and Benjamin F. Grewe. A theoretical framework for target propagation. In H. Larochelle, M. Ranzato, R. Had- sell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 20024–20036. Curran Associates, Inc., 2020
work page 2020
- [23]
-
[24]
Normalization as a canonical neural computation.Nature reviews neuroscience, 13(1):51–62, 2012
Matteo Carandini and David J Heeger. Normalization as a canonical neural computation.Nature reviews neuroscience, 13(1):51–62, 2012
work page 2012
-
[25]
C. Goemaere, G. Oliviers, R. Bogacz, and T. Demeester. Error optimization: Overcoming expo- nential signal decay in deep predictive coding networks, 2025. arXiv preprint arXiv:2505.20137
-
[26]
Satoki Ishikawa, Rio Yokota, and Ryo Karakida. Local loss optimization in the infinite width: Stable parameterization of predictive coding networks and target propagation. InInternational Conference on Learning Representations, volume 2025, pages 49143–49182, 2025. 11 Appendix Table of Contents A Experimental Configurations 12 A.1 Training data . . . . . ...
work page 2025
-
[27]
Training Curves for Varying Widths
At inference equilibrium (with x1 and xL =y clamped), stationarity with respect to hidden activities gives the recursion ϵl = (I+W l+1)⊤ϵl+1, l= 1, . . . , L−2,(57) which implies ϵl = ∼ W ⊤ L−1:l+1 ϵL−1.(58) The output residual can be written as r:=y− ∼ W L−1:1 x1 =ϵ L−1+ L−2X l=1 ∼ W L−1:l+1 ϵl = I+ L−2X l=1 ∼ W L−1:l+1 ∼ W ⊤ L−1:l+1 ϵL−1 = ˜S ϵL−1, (59)...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.