Recognition: 2 theorem links
· Lean TheoremSTAGE: Tackling Semantic Drift in Multimodal Federated Graph Learning
Pith reviewed 2026-05-13 07:38 UTC · model grok-4.3
The pith
STAGE translates heterogeneous multimodal features into a shared semantic space and regulates their propagation over local graphs to reduce inconsistency in federated learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
STAGE is a protocol-first framework that first translates heterogeneous multimodal features into comparable representations and then regulates how these representations propagate over local graph structures, thereby improving cross-client semantic calibration and reducing the risk of inconsistency amplification during graph learning.
What carries the argument
The translation step that maps heterogeneous multimodal features into a comparable semantic space, combined with subsequent regulation of graph message passing on local structures.
If this is right
- Cross-client semantic calibration improves because representations start in an aligned space rather than being forced together after the fact.
- Inconsistency amplification is limited because regulation controls how aligned vectors spread through graph neighborhoods.
- State-of-the-art accuracy holds across both graph-centric tasks such as node classification and modality-centric tasks such as cross-modal retrieval.
- Per-round communication payload drops because the protocol avoids exchanging raw high-dimensional multimodal parameters.
- The same protocol works on eight different multimodal-attributed graphs without task-specific redesign.
Where Pith is reading between the lines
- The translation-plus-regulation pattern could be tested in non-graph federated settings where clients hold mismatched data modalities.
- If residual inconsistencies remain after translation, adaptive regulation weights might further reduce error spread on sparse graphs.
- Privacy budgets could be tightened because less raw multimodal data needs to be exchanged once semantic alignment is in place.
- The approach suggests semantic alignment is a reusable primitive for any distributed multimodal system that must avoid drift.
Load-bearing premise
A translation step can reliably map heterogeneous multimodal features into a comparable semantic space without introducing false agreements or losing task-relevant information, and regulating graph propagation will prevent amplification of any residual inconsistency.
What would settle it
Running STAGE on a new multimodal-attributed graph where accuracy stays below standard federated averaging baselines or per-round communication payload does not decrease would falsify the central performance claim.
Figures








read the original abstract
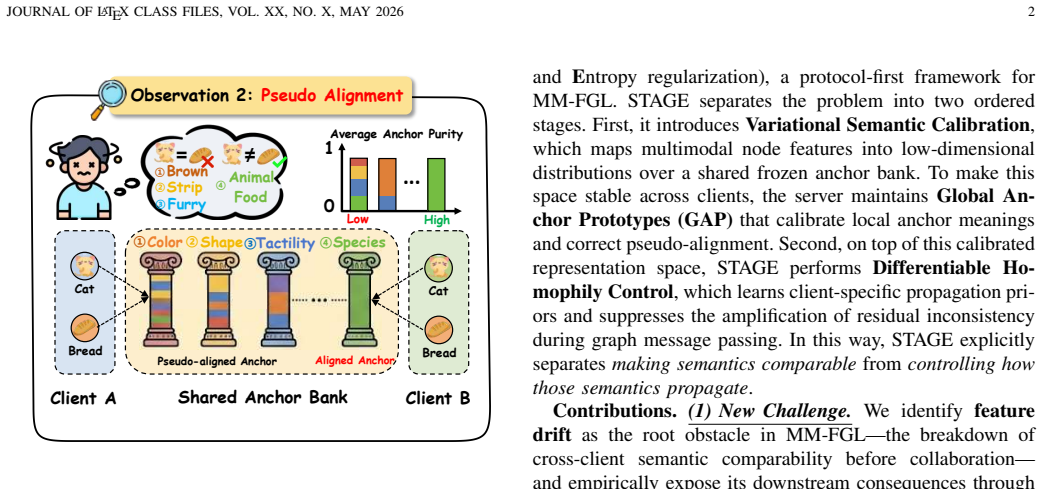
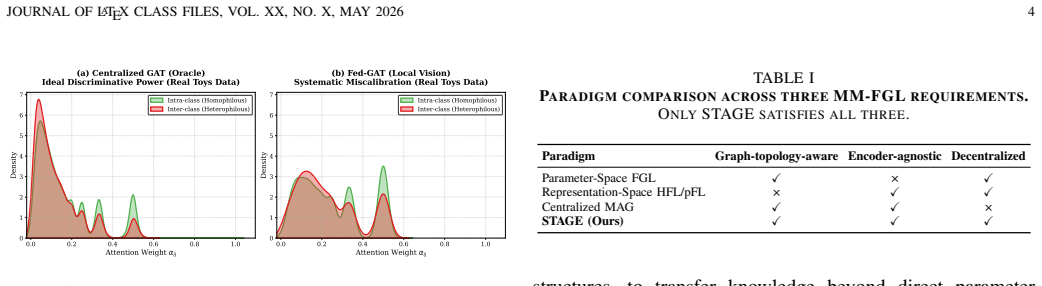
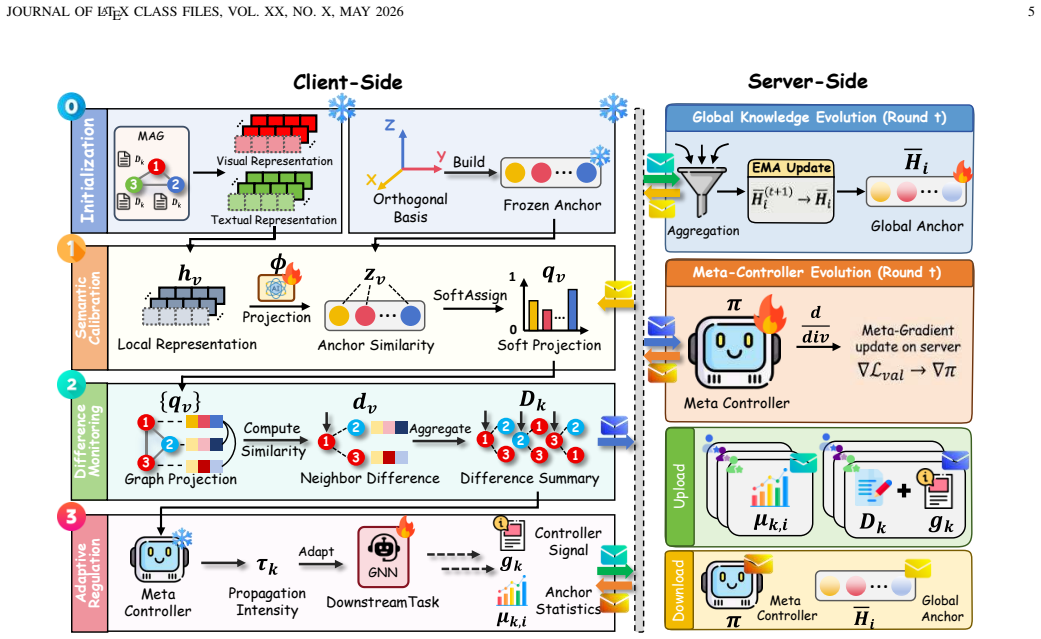
Federated graph learning (FGL) enables collaborative training on graph data across multiple clients. As graph data increasingly contain multimodal node attributes such as text and images, multimodal federated graph learning (MM-FGL) has become an important yet substantially harder setting. The key challenge is that clients from different modality domains may not share a common semantic space: even for the same concept, their local encoders can produce inconsistent representations before collaboration begins. This makes direct parameter coordination unreliable and further causes two downstream problems: forcing heterogeneous client representations into a naively shared semantic space may create false semantic agreement, and graph message passing may amplify residual inconsistency across neighborhoods. To address this issue, we propose \textbf{STAGE}, a protocol-first framework for MM-FGL. Instead of relying on direct parameter averaging, STAGE builds a shared semantic space that first translates heterogeneous multimodal features into comparable representations and then regulates how these representations propagate over local graph structures. In this way, STAGE not only improves cross-client semantic calibration, but also reduces the risk of inconsistency amplification during graph learning. Extensive experiments on 8 multimodal-attributed graphs across 5 graph-centric and modality-centric tasks show that STAGE consistently achieves state-of-the-art performance while reducing per-round communication payload.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STAGE, a protocol-first framework for multimodal federated graph learning (MM-FGL) that tackles semantic drift by first translating heterogeneous multimodal node features (e.g., text and images) from different clients into a shared semantic space and then regulating how these representations propagate over local graph structures, rather than relying on direct parameter averaging. It claims this improves cross-client semantic calibration, reduces inconsistency amplification during graph message passing, and yields state-of-the-art performance on 8 multimodal-attributed graphs across 5 graph-centric and modality-centric tasks while also lowering per-round communication payload.
Significance. If the central claims hold after proper validation, the work would be significant for the growing area of multimodal federated graph learning, as it directly targets the mismatch in semantic spaces across modality-specific encoders and the risk of error amplification in graph propagation, potentially enabling more reliable collaborative training with reduced communication overhead.
major comments (2)
- [Abstract] Abstract: The central performance claims (SOTA results and communication savings across 8 graphs and 5 tasks) are asserted without any quantitative metrics, baseline details, ablation studies, or statistical significance tests. This absence prevents verification of whether the reported gains are attributable to the proposed translation-plus-regulation mechanism or to other factors such as regularization effects or dataset biases.
- [Method] Method section (translation and regulation components): The manuscript provides no direct diagnostics for the translation step's fidelity, such as cross-modal retrieval accuracy, mutual information between original and translated embeddings on matched concepts, or measures of false semantic agreement. Without these, it is impossible to confirm that the shared semantic space avoids information loss or spurious alignments, which is load-bearing for the claim that subsequent graph regulation prevents inconsistency amplification.
minor comments (1)
- [Abstract] The abstract and introduction could more explicitly define the five tasks and the precise communication payload metric (e.g., bytes per round or number of parameters exchanged) to allow readers to assess the savings claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each point below and have revised the manuscript to strengthen the presentation of results and validation of the translation component.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (SOTA results and communication savings across 8 graphs and 5 tasks) are asserted without any quantitative metrics, baseline details, ablation studies, or statistical significance tests. This absence prevents verification of whether the reported gains are attributable to the proposed translation-plus-regulation mechanism or to other factors such as regularization effects or dataset biases.
Authors: The abstract serves as a concise overview, while the full manuscript details all quantitative metrics, baselines, ablations, and statistical tests in the Experiments section. To address the concern, we will revise the abstract to include key numerical results (e.g., average accuracy gains and communication reductions) along with references to the supporting tables and significance tests. This change will make the claims immediately verifiable without altering the underlying evidence that the gains stem from the proposed mechanisms rather than regularization or biases. revision: yes
-
Referee: [Method] Method section (translation and regulation components): The manuscript provides no direct diagnostics for the translation step's fidelity, such as cross-modal retrieval accuracy, mutual information between original and translated embeddings on matched concepts, or measures of false semantic agreement. Without these, it is impossible to confirm that the shared semantic space avoids information loss or spurious alignments, which is load-bearing for the claim that subsequent graph regulation prevents inconsistency amplification.
Authors: We agree that explicit diagnostics would strengthen validation of the translation step. In the revised manuscript we will add cross-modal retrieval accuracy and mutual information analyses between original and translated embeddings, reported in the Experiments section. These will demonstrate fidelity of the shared space and support that regulation addresses residual inconsistencies rather than relying on potentially spurious alignments. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper introduces STAGE as a protocol-first framework that translates heterogeneous multimodal features into a shared semantic space and then regulates their propagation over local graphs to mitigate semantic drift in MM-FGL. No equations, fitted parameters, or self-referential definitions are described that would reduce the claimed improvements to redefinitions of the inputs by construction. The central mechanisms are presented as novel additions rather than tautological mappings, and performance is asserted via experiments on external benchmarks rather than internal consistency alone. Any self-citations are not load-bearing for the core claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clients from different modality domains produce inconsistent representations for the same concept before collaboration.
invented entities (1)
-
Shared semantic space constructed via translation
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearVariational semantic translation... qv = arg min ... + τs DKL(q∥u) ... max-entropy L(k)ent ... Global Anchor Prototypes ... meta-controller πθπ(Dk)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearSTAGE consistently achieves state-of-the-art performance while reducing per-round communication payload
Reference graph
Works this paper leans on
-
[1]
Fedgraphnn: A federated learning system and benchmark for graph neural networks,
C. He, K. Balasubramanian, E. Ceyani, C. Yang, H. Xie, L. Sun, L. He, L. Yang, P. S. Yu, Y . Ronget al., “Fedgraphnn: A federated learning system and benchmark for graph neural networks,”arXiv preprint arXiv:2104.07145, 2021
-
[2]
A comprehensive data-centric overview of federated graph learning,
Z. Wu, X. Li, Y . Zhu, Z. Chen, G. Yan, Y . Yan, H. Zhang, Y . Ai, X. Jin, R.-H. Liet al., “A comprehensive data-centric overview of federated graph learning,”arXiv preprint arXiv:2507.16541, 2025
-
[3]
Mm-openfgl: A comprehensive benchmark for multimodal federated graph learning,
X. Li, Y . Ai, Y . Zhu, H. Lu, Y . Zhang, G. Fu, B. Fan, Q. Dai, R.- H. Li, and G. Wang, “Mm-openfgl: A comprehensive benchmark for multimodal federated graph learning,”arXiv preprint arXiv:2601.22416, 2026
-
[4]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inArtificial intelligence and statistics. Pmlr, 2017, pp. 1273– 1282
work page 2017
-
[5]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,”Proceedings of Machine learning and systems, vol. 2, pp. 429–450, 2020
work page 2020
-
[6]
Scaffold: Stochastic controlled averaging for federated learn- ing,
S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “Scaffold: Stochastic controlled averaging for federated learn- ing,” inInternational conference on machine learning. PMLR, 2020, pp. 5132–5143
work page 2020
-
[7]
Fedproto: Federated prototype learning across heterogeneous clients,
Y . Tan, G. Long, L. Liu, T. Zhou, Q. Lu, J. Jiang, and C. Zhang, “Fedproto: Federated prototype learning across heterogeneous clients,” inProceedings of the AAAI conference on artificial intelligence, vol. 36, no. 8, 2022, pp. 8432–8440
work page 2022
-
[8]
J. Zhang, Y . Liu, Y . Hua, and J. Cao, “Fedtgp: Trainable global prototypes with adaptive-margin-enhanced contrastive learning for data and model heterogeneity in federated learning,” inProceedings of the AAAI conference on artificial intelligence, vol. 38, no. 15, 2024, pp. 16 768–16 776
work page 2024
-
[9]
Multimodal feder- ated learning via contrastive representation ensemble,
Q. Yu, Y . Liu, Y . Wang, K. Xu, and J. Liu, “Multimodal feder- ated learning via contrastive representation ensemble,”arXiv preprint arXiv:2302.08888, 2023
-
[10]
Federated graph classification over non-iid graphs,
H. Xie, J. Ma, L. Xiong, and C. Yang, “Federated graph classification over non-iid graphs,”Advances in neural information processing sys- tems, vol. 34, pp. 18 839–18 852, 2021. JOURNAL OF LATEX CLASS FILES, VOL. XX, NO. X, MAY 2026 10
work page 2021
-
[11]
Personalized subgraph federated learning,
J. Baek, W. Jeong, J. Jin, J. Yoon, and S. J. Hwang, “Personalized subgraph federated learning,” inInternational conference on machine learning. PMLR, 2023, pp. 1396–1415
work page 2023
-
[12]
Fedgta: Topology-aware averaging for federated graph learning,
X. Li, Z. Wu, W. Zhang, Y . Zhu, R.-H. Li, and G. Wang, “Fedgta: Topology-aware averaging for federated graph learning,”arXiv preprint arXiv:2401.11755, 2024
-
[13]
Fedtad: Topology- aware data-free knowledge distillation for subgraph federated learning,
Y . Zhu, X. Li, Z. Wu, D. Wu, M. Hu, and R.-H. Li, “Fedtad: Topology- aware data-free knowledge distillation for subgraph federated learning,” arXiv preprint arXiv:2404.14061, 2024
-
[14]
A meta-computing framework for collaborative federated graph learning in industrial iots,
X. Zheng, X. Hu, T. Wang, Q. Huang, and L. Zhang, “A meta-computing framework for collaborative federated graph learning in industrial iots,” IEEE Internet of Things Journal, 2025
work page 2025
-
[15]
Rethinking client- oriented federated graph learning,
Z. Chen, X. Li, Y . Zhu, R.-H. Li, and G. Wang, “Rethinking client- oriented federated graph learning,” inProceedings of the 34th ACM International Conference on Information and Knowledge Management, 2025, pp. 393–402
work page 2025
-
[16]
Ensemble distillation for robust model fusion in federated learning,
T. Lin, L. Kong, S. U. Stich, and M. Jaggi, “Ensemble distillation for robust model fusion in federated learning,”Advances in neural information processing systems, vol. 33, pp. 2351–2363, 2020
work page 2020
-
[17]
T. Shen, J. Zhang, X. Jia, F. Zhang, G. Huang, P. Zhou, K. Kuang, F. Wu, and C. Wu, “Federated mutual learning,”arXiv preprint arXiv:2006.16765, 2020
-
[18]
Fedmultimodal: A bench- mark for multimodal federated learning,
T. Feng, D. Bose, T. Zhang, R. Hebbar, A. Ramakrishna, R. Gupta, M. Zhang, S. Avestimehr, and S. Narayanan, “Fedmultimodal: A bench- mark for multimodal federated learning,” inProceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining, 2023, pp. 4035–4045
work page 2023
-
[19]
Semi- supervised graph classification: A hierarchical graph perspective,
J. Li, Y . Rong, H. Cheng, H. Meng, W. Huang, and J. Huang, “Semi- supervised graph classification: A hierarchical graph perspective,” inThe World Wide Web Conference, 2019, pp. 972–982
work page 2019
-
[20]
Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks,
J. Lu, D. Batra, D. Parikh, and S. Lee, “Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks,”Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[21]
Lion: Empowering multimodal large language model with dual-level visual knowledge,
G. Chen, L. Shen, R. Shao, X. Deng, and L. Nie, “Lion: Empowering multimodal large language model with dual-level visual knowledge,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 540–26 550
work page 2024
-
[22]
Higpt: Heterogeneous graph language model,
J. Tang, Y . Yang, W. Wei, L. Shi, L. Xia, D. Yin, and C. Huang, “Higpt: Heterogeneous graph language model,” inProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining, 2024, pp. 2842–2853
work page 2024
-
[23]
Unigraph2: Learning a unified embedding space to bind multimodal graphs,
Y . He, Y . Sui, X. He, Y . Liu, Y . Sun, and B. Hooi, “Unigraph2: Learning a unified embedding space to bind multimodal graphs,” inProceedings of the ACM on Web Conference 2025, 2025, pp. 1759–1770
work page 2025
-
[24]
Justifying recommendations using distantly-labeled reviews and fine-grained aspects,
J. Ni, J. Li, and J. McAuley, “Justifying recommendations using distantly-labeled reviews and fine-grained aspects,” inProceedings of the 2019 conference on empirical methods in natural language pro- cessing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), 2019, pp. 188–197
work page 2019
-
[25]
Ninerec: A benchmark dataset suite for evaluating transferable recommendation,
J. Zhang, Y . Cheng, Y . Ni, Y . Pan, Z. Yuan, J. Fu, Y . Li, J. Wang, and F. Yuan, “Ninerec: A benchmark dataset suite for evaluating transferable recommendation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[26]
Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models,
B. A. Plummer, L. Wang, C. M. Cervantes, J. C. Caicedo, J. Hocken- maier, and S. Lazebnik, “Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models,” inProceedings of the IEEE international conference on computer vision, 2015, pp. 2641– 2649
work page 2015
-
[27]
How to read paintings: semantic art un- derstanding with multi-modal retrieval,
N. Garcia and G. V ogiatzis, “How to read paintings: semantic art un- derstanding with multi-modal retrieval,” inProceedings of the European Conference on Computer Vision (ECCV) Workshops, 2018, pp. 0–0
work page 2018
-
[28]
Fast unfolding of communities in large networks,
V . D. Blondel, J.-L. Guillaume, R. Lambiotte, and E. Lefebvre, “Fast unfolding of communities in large networks,”Journal of statistical mechanics: theory and experiment, vol. 2008, no. 10, p. P10008, 2008
work page 2008
-
[29]
A fast and high quality multilevel scheme for partitioning irregular graphs,
G. Karypis and V . Kumar, “A fast and high quality multilevel scheme for partitioning irregular graphs,”SIAM Journal on scientific Computing, vol. 20, no. 1, pp. 359–392, 1998
work page 1998
-
[30]
Inductive representation learning on large graphs,
W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[31]
P. Veli ˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Lio, Y . Bengio et al., “Graph attention networks,” inInternational conference on learning representations, vol. 6, no. 2. Ithaca, 2018
work page 2018
-
[32]
Leveraging foundation models for multi-modal federated learning with incomplete modality,
L. Che, J. Wang, X. Liu, and F. Ma, “Leveraging foundation models for multi-modal federated learning with incomplete modality,” inJoint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 2024, pp. 401–417
work page 2024
-
[33]
M. D. Nguyen, T. T. Nguyen, H. H. Pham, T. N. Hoang, P. Le Nguyen, and T. T. Huynh, “Fedmac: Tackling partial-modality missing in feder- ated learning with cross-modal aggregation and contrastive regulariza- tion,” in2024 22nd International Symposium on Network Computing and Applications (NCA). IEEE, 2024, pp. 278–285
work page 2024
-
[34]
Subgraph federated learning via spectral methods,
J. Aliakbari, J. ¨Ostman, A. Panahiet al., “Subgraph federated learning via spectral methods,”arXiv preprint arXiv:2510.25657, 2025
-
[35]
S2fgl: Spatial spectral federated graph learning,
Z. Tan, S. Huang, G. Wan, W. Huang, H. Li, and M. Ye, “S2fgl: Spatial spectral federated graph learning,”arXiv preprint arXiv:2507.02409, 2025
-
[36]
Fedspa: Generalizable federated graph learning under homophily het- erogeneity,
Z. Tan, G. Wan, W. Huang, H. Li, G. Zhang, C. Yang, and M. Ye, “Fedspa: Generalizable federated graph learning under homophily het- erogeneity,” inProceedings of the Computer Vision and Pattern Recog- nition Conference, 2025, pp. 15 464–15 475
work page 2025
-
[37]
Modeling inter-intra heterogeneity for graph federated learning,
W. Yu, S. Chen, Y . Tong, T. Gu, and C. Gong, “Modeling inter-intra heterogeneity for graph federated learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 21, 2025, pp. 22 236– 22 244. Zekai Chenis currently pursuing his Master’s degree in Computer Science at Beijing Institute of Technology under the supervision of Prof...
work page 2025
-
[38]
Her research interests include computer science and technology
She is currently a second-year undergraduate student majoring in Computer Science and Technol- ogy at Minzu University of China, Beijing, China. Her research interests include computer science and technology. Rong-Hua Lireceived the PhD degree from the Chinese University of Hong Kong, in 2013. He is currently a professor with the Beijing Institute of Tech...
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.