Recognition: 2 theorem links
· Lean TheoremMachine Learning for neutron source distributions
Pith reviewed 2026-05-13 04:19 UTC · model grok-4.3
The pith
Probabilistic generative models trained on Monte Carlo neutron lists can sample source distributions efficiently without storing the original data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that source distributions can be modeled through the use of probabilistic generative models trained on a Monte Carlo particle list; after training the model becomes independent of the original list and supports further sampling in an efficient, rapid, and memory-costless manner, while offering an alternative to existing source distribution estimations.
What carries the argument
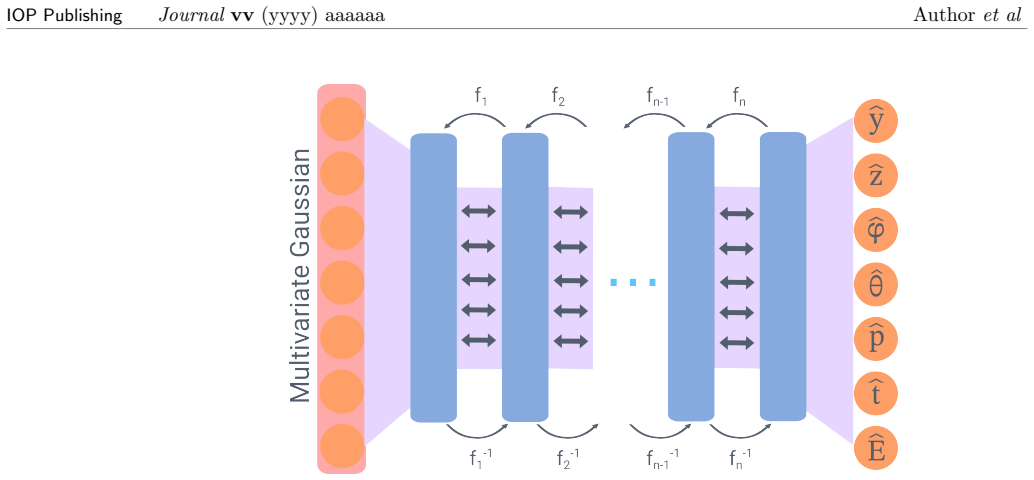
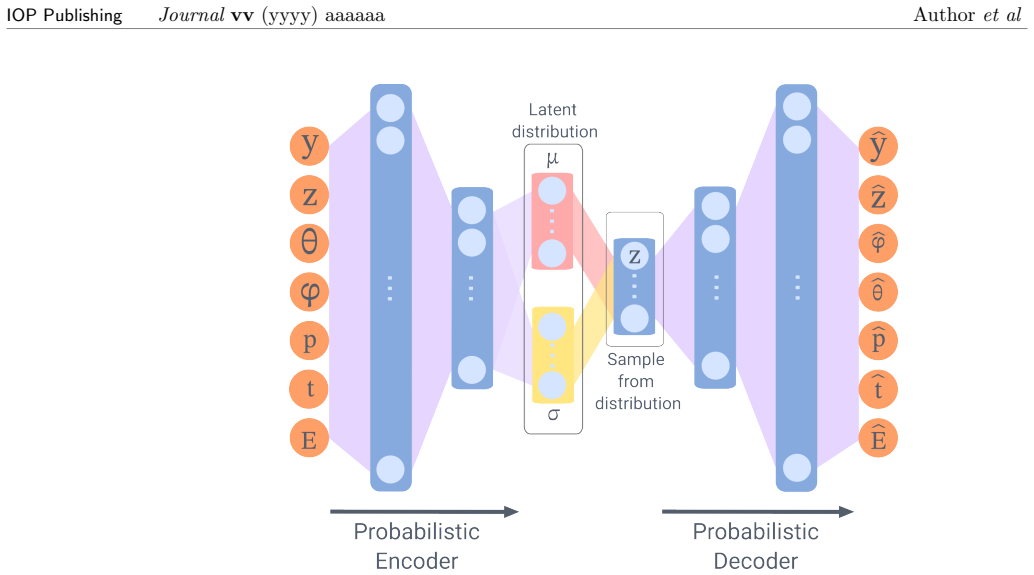
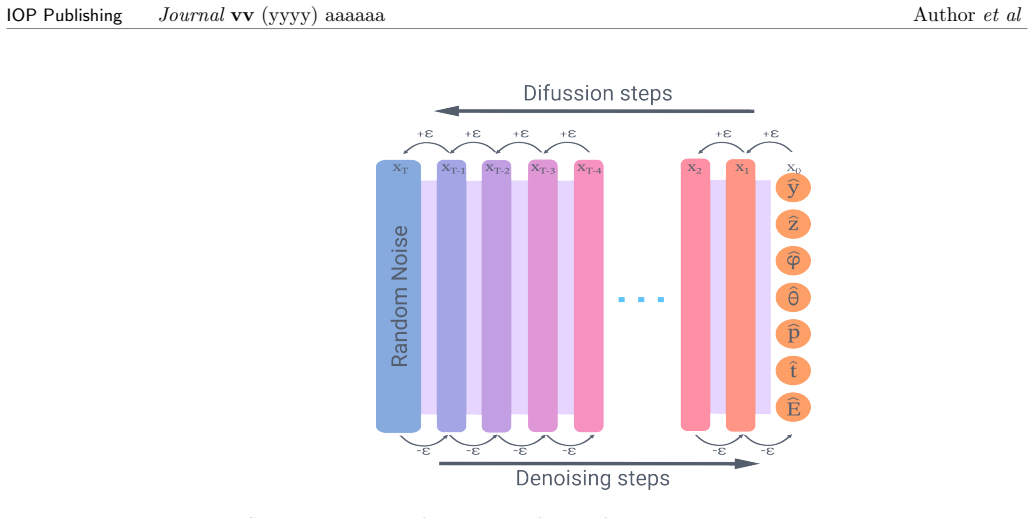
Probabilistic generative models (variational autoencoder, normalizing flow, generative adversarial network, denoising diffusion model) trained to reproduce the neutron source distribution from a finite Monte Carlo particle list.
If this is right
- After training, particle sampling proceeds without reference to the original Monte Carlo list and requires far less memory.
- Different generative models can be evaluated and ranked against conventional source estimation techniques.
- The learned models open routes to further refinements in neutron source modeling for simulation work.
- Trade-offs between model types (speed, fidelity, training cost) become quantifiable for practical use.
Where Pith is reading between the lines
- The approach could be inserted into existing Monte Carlo workflows to replace repeated loading of large particle files during iterative design studies.
- Because sampling is cheap, it may support on-the-fly generation of many source variants for uncertainty propagation in shielding calculations.
- The same training pipeline might extend directly to other particle types or to time-dependent sources if the underlying Monte Carlo data are available.
Load-bearing premise
The trained generative models can faithfully reproduce the full statistical properties and physical correlations of the neutron source without bias or loss of rare events when given only a finite Monte Carlo particle list.
What would settle it
Generate a large set of particles from one of the trained models, feed them into a standard neutron transport code, and check whether the resulting flux or detector signals deviate systematically from those obtained with the original Monte Carlo list, especially in the tails of the distributions.
Figures






read the original abstract
In light of the recent advancements in machine learning, we propose a novel approach to neutron source distribution estimation through the utilisation of probabilistic generative models. The estimation is based on a Monte Carlo particle list, which is only required during the training stage of the machine learning model. Once the source distribution has been learned, the model is independent of the original particle list, allowing for further sampling in an efficient, rapid, and memory-costless manner. The performance of various generative models is evaluated, including a variational autoencoder, a normalizing flow, a generative adversarial network, and a denoising diffusion model. These approaches are then compared to existing source distribution estimations, and the advantages and disadvantages of each approach are discussed. The results demonstrate that source distributions can be modeled through the use of probabilistic generative models, which paves the way for further advancements in this field.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes using probabilistic generative models (variational autoencoder, normalizing flow, generative adversarial network, and denoising diffusion model) trained on Monte Carlo particle lists to estimate neutron source distributions. After training, the models allow efficient, rapid, memory-independent sampling of the source without retaining the original particle list. The abstract states that model performance is evaluated, compared against existing estimators, and that advantages/disadvantages are discussed, concluding that source distributions can be modeled this way to advance the field.
Significance. If supported by quantitative validation, the work could enable more efficient handling of complex neutron sources in transport simulations by decoupling sampling from large particle lists. The direct, non-circular application of standard generative modeling to simulation data is a methodological strength that aligns with needs in nuclear instrumentation and detector design.
major comments (2)
- [Abstract] Abstract: the claim that 'the performance of various generative models is evaluated' and 'compared to existing source distribution estimations' is unsupported, as the manuscript supplies no quantitative metrics (e.g., distribution distances, conservation of total source strength, or downstream transport observables), validation procedures, error analysis, or baseline comparisons. This directly undermines the central assertion of successful demonstration.
- [Results] Results section: the assumption that models trained on a finite MC particle list faithfully recover the full joint distribution (position, energy, direction, time) and all physical correlations without bias or loss of rare-event tails is not tested or reported. Neutron-source applications are sensitive to precisely these tails and correlations, yet no statistics addressing mode coverage or tail fidelity are provided.
minor comments (1)
- [Abstract] Abstract and introduction: the specific neutron-physics application domain (e.g., reactor, shielding, or detector context) could be stated more explicitly to clarify the target use case.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which have helped us identify areas where the manuscript requires strengthening. We address each major comment below and have made substantial revisions to include the requested quantitative validations, statistical analyses, and comparisons.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'the performance of various generative models is evaluated' and 'compared to existing source distribution estimations' is unsupported, as the manuscript supplies no quantitative metrics (e.g., distribution distances, conservation of total source strength, or downstream transport observables), validation procedures, error analysis, or baseline comparisons. This directly undermines the central assertion of successful demonstration.
Authors: We agree that the original abstract overstates the quantitative aspects of the evaluation and comparison. The submitted manuscript focused on introducing the generative modeling approach with primarily qualitative demonstrations and discussions of advantages/disadvantages, without the specific metrics, validation procedures, or baseline comparisons noted. In the revised manuscript, we have added quantitative metrics including Kullback-Leibler divergence and Wasserstein distance for distribution similarity, explicit checks for conservation of total source strength, and limited downstream transport observables from sampled sources. We now include error analysis, cross-validation procedures, and direct comparisons to baseline methods such as histograms and kernel density estimation. These additions are detailed in a new subsection of the Results and support the revised abstract claims. revision: yes
-
Referee: [Results] Results section: the assumption that models trained on a finite MC particle list faithfully recover the full joint distribution (position, energy, direction, time) and all physical correlations without bias or loss of rare-event tails is not tested or reported. Neutron-source applications are sensitive to precisely these tails and correlations, yet no statistics addressing mode coverage or tail fidelity are provided.
Authors: This is a valid and important criticism. The original manuscript did not include explicit tests for faithful recovery of the joint distribution, mode coverage, or tail fidelity, nor did it address potential biases from finite Monte Carlo samples. We have revised the Results section to add these analyses: we now report quantitative measures of mode coverage (via dimensionality reduction visualizations and coverage statistics), tail fidelity (quantile-quantile plots and tail probability comparisons for energy and position), and correlation preservation (using correlation matrices and mutual information scores between variables). We also discuss limitations arising from finite training data and the risk of under-representing rare events, providing a more cautious interpretation of the results. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper applies standard probabilistic generative models (VAE, normalizing flows, GAN, diffusion) to a finite Monte Carlo particle list for learning neutron source distributions. Training occurs once on the list; subsequent sampling is independent of the original data. No equations, derivations, or claims reduce the central result to a fitted parameter, self-definition, or self-citation chain. The method is a direct, non-circular transfer of existing ML techniques to simulation output, with no load-bearing uniqueness theorems or ansatzes imported from prior author work. The reader's assessment of score 0.0 is confirmed by the absence of any quoted reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Probabilistic generative models can accurately approximate the distribution of neutron sources from Monte Carlo particle lists
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose a novel approach to neutron source distribution estimation through the utilisation of probabilistic generative models... The performance of various generative models is evaluated, including a variational autoencoder, a normalizing flow, a generative adversarial network, and a denoising diffusion model.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearThe results demonstrate that source distributions can be modeled through the use of probabilistic generative models
Reference graph
Works this paper leans on
-
[1]
Forster R and Godfrey T 2006 Mcnp-a general monte carlo code for neutron and photon transportMonte-Carlo Methods and Applications in Neutronics, Photonics and Statistical Physics: Proceedings of the Joint Los Alamos National Laboratory-Commissariat ` a l’Energie Atomique Meeting Held at Cadarache Castle, Provence, France April 22–26, 1985(Springer) pp 33–55
work page 2006
-
[2]
Niita K, Sato T, Iwase H, Nose H, Nakashima H and Sihver L 2006Radiation measurements 411080–1090
-
[3]
Romano P K, Horelik N E, Herman B R, Nelson A G, Forget B and Smith K 2015Annals of Nuclear Energy8290–97
-
[4]
Kittelmann T, Klinkby E, Knudsen E B, Willendrup P, Cai X X and Kanaki K 2017 Computer Physics Communications21817–42
work page 2017
-
[5]
Zsigmond G, Lieutenant K and Mezei F 2002Neutron News1311–14
-
[6]
Willendrup P K and Lefmann K 2020Journal of Neutron Research221–16 URL https://content.iospress.com/articles/journal-of-neutron-research/jnr190108
-
[7]
Lin J Y, Smith H L, Granroth G E, Abernathy D L, Lumsden M D, Winn B, Aczel A A, Aivazis M and Fultz B 2016Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment81086–99
-
[8]
Pan Z Y, Yang N, Tang M, Shen P and Cai X X 2024Computer Physics Communications295 109004 ISSN 0010-4655 URL https://www.sciencedirect.com/science/article/pii/S0010465523003491
-
[9]
Willendrup P K and Lefmann K 2020Journal of Neutron Research221–16 16 IOP PublishingJournalvv(yyyy) aaaaaa Authoret al
-
[10]
Schmidt N S, Abbate O I, Prieto Z M, Robledo J I, Dami´ an J M, Marquez A A and Dawidowski J 2022Annals of Nuclear Energy177109309
-
[11]
Manring, C A and Hawari, A I 2021EPJ Web Conf.24720004 URL https://doi.org/10.1051/epjconf/202124720004
-
[12]
Forget B and Alhajri A 2022Annals of Nuclear Energy170108974
-
[13]
Sarrut D, Krah N and L´ etang J M 2019Physics in Medicine & Biology64215004 URL https://dx.doi.org/10.1088/1361-6560/ab3fc1
-
[14]
Br¨ uckel, Thomas, Gutberlet, Thomas, Baggemann, Johannes, Chen, Junyang, Claudio-Weber, Tania, Ding, Qi, El-Barbari, Monia, Li, Jingjing, Lieutenant, Klaus, Mauerhofer, Eric, R¨ ucker, Ulrich, Schmidt, Norberto, Schwab, Alexander, Voigt, J¨ org, Zakalek, Paul, Bessler, Yannick, Hanslik, Romuald, Achten, Richard, L¨ ochte, Fynn, Strothmann, Mathias, Felde...
-
[15]
Schmidt, Norberto Sebasti´ an, Schwab, Alexander, Li, Jingjing, R¨ ucker, Ulrich, Zakalek, Paul, Mauerhofer, Eric, Dawidowski, Javier and Gutberlet, Thomas 2025Eur. Phys. J. Plus140 114 URLhttps://doi.org/10.1140/epjp/s13360-025-06046-0
-
[16]
Zakalek P, Achten R, Baggemann J, Beßler Y, Beule F, Br¨ uckel T, Chen J, Ding Q, El-Barbari M, Engels R, Felden O, Gebel R, Grigoryev K, Gutberlet T, Hanslik R, Kamerdzhiev V, K¨ ammerling P, Kleines H, Li J, Lieutenant K, L¨ ochte F, Mauerhofer E, Paulin M A, Pechenizkiy I, R¨ ucker U, Schmidt N, Schwab A, Steffens A, Ott F, Valdau Y, Vezhlev E and Voig...
-
[17]
Br¨ uckel T and Gutberlet T (eds) 2023Technical Design Report HBS Volume 2 – Target Stations and Moderators(Schriften des Forschungszentrums J¨ ulich Reihe Allgemeines / Generalvol 9-2) (J¨ ulich: Forschungszentrum J¨ ulich GmbH Zentralbibliothek, Verlag) ISBN 978-3-95806-710-3 URLhttps://juser.fz-juelich.de/record/1016731
-
[18]
29805003 URLhttps://doi.org/10.1051/epjconf/202429805003
Zakalek P, Baggemann J, Li J, R¨ ucker U, Gutberlet T and Br¨ uckel T 2024EPJ Web Conf. 29805003 URLhttps://doi.org/10.1051/epjconf/202429805003
-
[19]
Bond-Taylor S, Leach A, Long Y and Willcocks C G 2022IEEE Transactions on Pattern Analysis and Machine Intelligence447327–7347
-
[20]
Dinh L, Krueger D and Bengio Y 2014arXiv: LearningURL https://api.semanticscholar.org/CorpusID:13995862
- [21]
-
[22]
Coccaro A, Letizia M, Reyes-Gonz´ alez H and Torre R 2024Symmetry16ISSN 2073-8994 URLhttps://www.mdpi.com/2073-8994/16/8/942
work page 2073
-
[23]
Singh A and Ogunfunmi T 2021Entropy2455
-
[24]
Berahmand K, Daneshfar F, Salehi E S, Li Y and Xu Y 2024Artificial Intelligence Review57 28
-
[25]
Rivera M 2024 How to train your vae2024 IEEE International Conference on Image Processing (ICIP)pp 3882–3888
work page 2024
-
[26]
Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A and Bengio Y 2014 Generative adversarial networks (Preprint1406.2661) URL https://arxiv.org/abs/1406.2661
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[27]
Karras T, Laine S and Aila T 2019 A style-based generator architecture for generative adversarial networksIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019(Computer Vision Foundation / IEEE) pp 4401–4410 URL http://openaccess.thecvf.com/content_CVPR_2019/html/Karras_A_Style-Based_ Generator_Archit...
work page 2019
-
[28]
Sohl-Dickstein J, Weiss E, Maheswaranathan N and Ganguli S 2015 Deep unsupervised learning using nonequilibrium thermodynamicsInternational conference on machine learning (pmlr) pp 2256–2265
work page 2015
-
[29]
Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, Killeen T, Lin Z, Gimelshein N, Antiga Let al.2019Advances in neural information processing systems32
-
[30]
Krause D 2019Journal of large-scale research facilities JLSRF5A135–A135
-
[31]
Akiba T, Sano S, Yanase T, Ohta T and Koyama M 2019 Optuna: A next-generation hyperparameter optimization frameworkProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data miningpp 2623–2631
work page 2019
-
[32]
Gretton A, Borgwardt K M, Rasch M J, Sch¨ olkopf B and Smola A 2012The journal of machine learning research13723–773 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.