Recognition: no theorem link
Intrinsic Vicarious Conditioning for Deep Reinforcement Learning
Pith reviewed 2026-05-13 05:57 UTC · model grok-4.3
The pith
Vicarious conditioning supplies intrinsic rewards in deep reinforcement learning without requiring demonstrators' policies or reward functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By implementing the four psychological steps of vicarious conditioning through memory-based mechanisms, reinforcement learning agents receive intrinsic rewards that discourage non-descriptive terminal conditions and guide behavior toward desirable states, all without access to the demonstrating agent's policy or reward function.
What carries the argument
Memory-based implementation of vicarious conditioning's four steps (attention, retention, reproduction, reinforcement) that generates intrinsic rewards from observed demonstrations.
Load-bearing premise
Memory-based versions of attention, retention, reproduction, and reinforcement can produce useful intrinsic rewards even with no access to the demonstrator agent's policy or reward function.
What would settle it
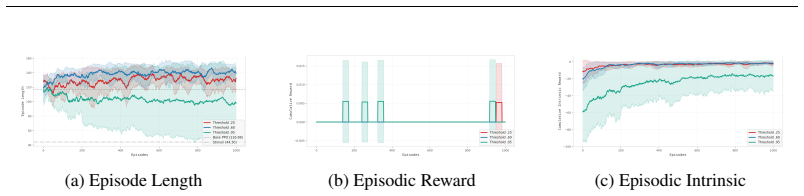
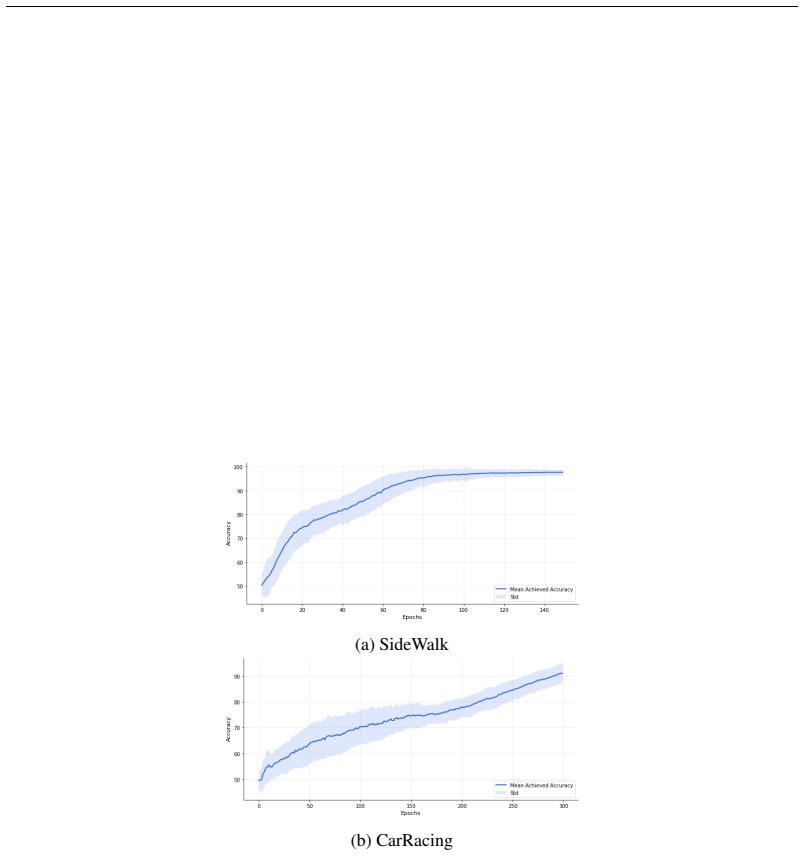
A controlled comparison in the Sidewalk environment in which agents using the vicarious conditioning module fail to achieve reliably longer episodes than standard reinforcement learning baselines that lack any demonstrator input.
Figures











read the original abstract
Advancements in reinforcement learning have produced a variety of complex and useful intrinsic driving forces; crucially, these drivers operate under a direct conditioning paradigm. This form of conditioning limits our agents' capacity by restricting how they learn from the environment as well as from others. Off-policy or learn-by-example methods can learn from demonstrators' representations, but they require access to the demonstrating agent's policies or their reward functions. Our work overcomes this direct sampling limitation by introducing vicarious conditioning as an intrinsic reward mechanism. We draw from psychological and biological literature to provide a foundation for vicarious conditioning and use memory-based methods to implement its four steps: attention, retention, reproduction, and reinforcement. Crucially, our vicarious conditioning paradigms support low-shot learning and do not require the demonstrator agent's policy nor its reward functions. We evaluate our approach in the MiniWorld Sidewalk environment, one of the few public environments that features a non-descriptive terminal condition (no reward provided upon agent death), and extend it to Box2D's CarRacing environment. Our results across both environments demonstrate that vicarious conditioning enables longer episode lengths by discouraging the agent from non-descriptive terminal conditions and guiding the agent toward desirable states. Overall, this work emulates a cognitively-plausible learning paradigm better suited to problems such as single-life learning or continual learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes vicarious conditioning as a new intrinsic reward mechanism for deep RL. It draws on psychological literature to define four steps (attention, retention, reproduction, reinforcement) realized via memory-based methods; the resulting intrinsic reward is claimed to let agents learn from demonstrators without access to the demonstrator's policy or reward function. The approach is evaluated in MiniWorld Sidewalk (chosen for its non-descriptive terminal condition) and Box2D CarRacing, with the central empirical claim that it produces longer episodes by discouraging non-descriptive terminals and guiding agents toward desirable states. The work is positioned as more cognitively plausible for single-life and continual learning settings.
Significance. If the memory-based implementation can be shown to generate useful intrinsic rewards from raw observations alone, the result would offer a novel route to vicarious learning in RL that avoids the usual requirement for demonstrator internals. This could be relevant for sparse-reward or non-descriptive-terminal environments and for paradigms that aim to emulate human-like observational learning. No machine-checked proofs, reproducible code releases, or parameter-free derivations are described, so the significance rests entirely on whether the empirical gains are reproducible and mechanistically grounded.
major comments (2)
- [Abstract / Methods] Abstract and Methods: the manuscript states that memory-based methods realize the four psychological steps and produce an intrinsic reward, yet supplies neither the memory architecture, state encoding, reward formula, nor update rule. This is load-bearing for the central claim that the mechanism infers desirable states from raw observations without demonstrator policy or reward access; without the concrete realization it is impossible to determine whether reported episode-length gains are artifacts of an implicit channel or genuine vicarious conditioning.
- [Results] Results: the abstract asserts that vicarious conditioning enables longer episode lengths in both MiniWorld Sidewalk and CarRacing, but the provided text contains no quantitative metrics, error bars, ablation studies, or comparison against baselines that isolate the contribution of the four-step memory implementation. This undermines the empirical support for the claim that the method discourages non-descriptive terminals.
minor comments (2)
- [Introduction] The psychological literature citations that ground the four steps are referenced but not listed with specific sources or page numbers in the abstract; adding them would improve traceability.
- [Methods] Notation for the intrinsic reward and memory components is not introduced, making it difficult to follow how attention, retention, reproduction, and reinforcement map onto RL primitives.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and commit to revisions that will strengthen the manuscript's clarity and empirical grounding.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: the manuscript states that memory-based methods realize the four psychological steps and produce an intrinsic reward, yet supplies neither the memory architecture, state encoding, reward formula, nor update rule. This is load-bearing for the central claim that the mechanism infers desirable states from raw observations without demonstrator policy or reward access; without the concrete realization it is impossible to determine whether reported episode-length gains are artifacts of an implicit channel or genuine vicarious conditioning.
Authors: We agree that the current manuscript presents the four steps at a conceptual level without the concrete implementation details. The Methods section does not specify the memory architecture, state encoding from raw observations, the exact intrinsic reward formula, or the update rules. This omission limits the ability to evaluate whether the reported gains arise from genuine vicarious conditioning. In the revised manuscript we will add a dedicated subsection detailing the memory architecture (including its structure and capacity), the state encoding process, the mathematical formulation of the intrinsic reward derived from attention, retention, reproduction, and reinforcement, and the corresponding update rules. These additions will make the mechanism fully specified and allow readers to assess its validity independent of any implicit channels. revision: yes
-
Referee: [Results] Results: the abstract asserts that vicarious conditioning enables longer episode lengths in both MiniWorld Sidewalk and CarRacing, but the provided text contains no quantitative metrics, error bars, ablation studies, or comparison against baselines that isolate the contribution of the four-step memory implementation. This undermines the empirical support for the claim that the method discourages non-descriptive terminals.
Authors: We acknowledge that the current manuscript text provides only a qualitative description of longer episode lengths without supporting quantitative data. No specific metrics, error bars, ablation studies, or baseline comparisons are included to isolate the contribution of the four-step implementation. In the revised version we will expand the Results section to report mean episode lengths with standard errors across multiple random seeds for both environments, include ablation studies that remove or modify individual steps of the vicarious conditioning process, and add comparisons against relevant baselines (standard PPO, other intrinsic reward methods, and random exploration). These quantitative results and analyses will directly support the claim that the mechanism discourages non-descriptive terminals. revision: yes
Circularity Check
No significant circularity; claims rest on external psychological literature and empirical evaluation
full rationale
The paper grounds vicarious conditioning in external psychological and biological literature, then implements the four steps (attention, retention, reproduction, reinforcement) via memory-based methods without providing equations that reduce the intrinsic reward to a fitted parameter or self-referential definition. The central result—longer episodes via avoidance of non-descriptive terminals—is presented as an empirical outcome across MiniWorld and CarRacing environments rather than a derivation that collapses to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results is shown to substitute for independent derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Psychological and biological literature on vicarious conditioning provides a valid and transferable foundation for designing intrinsic rewards in artificial agents.
invented entities (1)
-
Vicarious conditioning intrinsic reward
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Observational learning of fear in real time procedure
Szczepanik, Micha and Ka \'z mierowska, Anna M and Micha owski, Jaros aw M and Wypych, Marek and Olsson, Andreas and Knapska, Ewelina. Observational learning of fear in real time procedure. Scientific Reports
-
[2]
Fear Potentiation and Fear Inhibition in a Human Fear-Potentiated Startle Paradigm , journal =. 2005 , issn =. doi:10.1016/j.biopsych.2005.02.025 , author =
-
[3]
Extinction in Human Fear Conditioning , journal =. 2006 , issn =. doi:10.1016/j.biopsych.2005.10.006 , author =
-
[4]
Recall of Fear Extinction in Humans Activates the Ventromedial Prefrontal Cortex and Hippocampus in Concert , journal =. 2007 , issn =. doi:10.1016/j.biopsych.2006.10.011 , author =
-
[5]
Phobias and preparedness: the selective, automatic, and encapsulated nature of fear , journal =. 2002 , issn =. doi:10.1016/S0006-3223(02)01669-4 , author =
-
[6]
Behavioral and Neural Mechanisms of Overgeneralization in Anxiety
Laufer, Offir and Israeli, David and Paz, Rony. Behavioral and Neural Mechanisms of Overgeneralization in Anxiety. Current Biology
-
[7]
Sullivan, Regina M and Opendak, Maya. Neurobiology of Infant Fear and Anxiety: Impacts of Delayed Amygdala Development and Attachment Figure Quality. Biol Psychiatry
-
[8]
The neurobiology of anxiety disorders: brain imaging, genetics, and psychoneuroendocrinology
Martin, Elizabeth I and Ressler, Kerry J and Binder, Elisabeth and Nemeroff, Charles B. The neurobiology of anxiety disorders: brain imaging, genetics, and psychoneuroendocrinology. Psychiatr Clin North Am
-
[9]
The fear-defense system, emotions, and oxidative stress , journal =. 2020 , issn =. doi:10.1016/j.redox.2020.101588 , author =
-
[10]
Philosophical Transactions of the Royal Society B: Biological Sciences , volume =
Suvrathan, Aparna and Bennur, Sharath and Ghosh, Supriya and Tomar, Anupratap and Anilkumar, Shobha and Chattarji, Sumantra , title =. Philosophical Transactions of the Royal Society B: Biological Sciences , volume =. 2014 , doi =
work page 2014
-
[11]
Abnormal Fear Memory as a Model for Posttraumatic Stress Disorder , journal =. 2015 , issn =. doi:10.1016/j.biopsych.2015.06.017 , author =
-
[12]
Extending animal models of fear conditioning to humans , journal =. 2006 , issn =. doi:10.1016/j.biopsycho.2006.01.006 , author =
- [13]
-
[14]
and Hermans, Dirk and Vervliet, Bram , title =
Craske, Michelle G. and Hermans, Dirk and Vervliet, Bram , title =. Philosophical Transactions of the Royal Society B: Biological Sciences , volume =. 2018 , doi =
work page 2018
-
[15]
Jack M. Gorman and Steven P. Roose , title =. Journal of the American Psychoanalytic Association , volume =. 2011 , doi =
work page 2011
-
[16]
Marin, Marie France and Bilodeau-Houle, Alexe and Morand-Beaulieu, Simon and Brouillard, Alexandra and Herringa, Ryan J. and Milad, Mohammed R. , number =. 2020 , journal =. doi:10.1038/S41598-020-74170-1 , issn =
-
[17]
Role of amygdala in drug memory , journal =. 2013 , issn =. doi:10.1016/j.nlm.2013.06.017 , author =
-
[18]
European conference on computer vision , pages=
A siamese long short-term memory architecture for human re-identification , author=. European conference on computer vision , pages=. 2016 , organization=
work page 2016
-
[19]
Long short-term memory , author=. Neural computation , volume=. 1997 , publisher=
work page 1997
-
[20]
Neurobiology of addiction: a neurocircuitry analysis
Koob, George F and Volkow, Nora D. Neurobiology of addiction: a neurocircuitry analysis. Lancet Psychiatry
-
[21]
The amygdala and the pursuit of future rewards
Johnson, S Tobias and Grabenhorst, Fabian. The amygdala and the pursuit of future rewards. Front Neurosci
-
[22]
Learning to fear novel stimuli by observing others in the social affordance framework , journal =. 2025 , issn =. doi:10.1016/j.neubiorev.2025.106006 , author =
-
[23]
Hostinar, Camelia E and Sullivan, Regina M and Gunnar, Megan R. Psychobiological mechanisms underlying the social buffering of the hypothalamic-pituitary-adrenocortical axis: a review of animal models and human studies across development. Psychol Bull
-
[24]
Sutton, Richard S. and Barto, Andrew G. , publisher =. Reinforcement Learning:. 1998 , address =
work page 1998
-
[25]
R. S. Sutton and D. McAllester and S. Singh and Y. Mansour. Policy Gradient Methods for Reinforcement Learning with Function Approximation. Advances in Neural Information Processing Systems 12. 2000
work page 2000
-
[26]
R. J. Williams. Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. Machine Learning. 1992
work page 1992
-
[27]
Neural Turing Machines , author =. arXiv preprint arXiv:1410.5401 , year =
work page internal anchor Pith review arXiv
-
[28]
Advances in Neural Information Processing Systems , volume =
You only live once: Single-life reinforcement learning , author =. Advances in Neural Information Processing Systems , volume =
-
[29]
International Conference on Learning Representations , year =
Hopfield Networks is All You Need , author =. International Conference on Learning Representations , year =
-
[30]
Neural networks and physical systems with emergent collective computational abilities
Hopfield, J J. Neural networks and physical systems with emergent collective computational abilities. Proc Natl Acad Sci U S A
-
[31]
Nature Communications , volume =
Experimentally validated memristive memory augmented neural network with efficient hashing and similarity search , author =. Nature Communications , volume =. 2022 , doi =
work page 2022
-
[32]
XMem : Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
Cheng, Ho Kei and Schwing, Alexander G. XMem : Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model. Computer Vision -- ECCV 2022. 2022
work page 2022
-
[33]
Proceedings of the 39th International Conference on Machine Learning , pages =
Learning from Demonstration: Provably Efficient Adversarial Policy Imitation with Linear Function Approximation , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , volume =
work page 2022
-
[34]
2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , title =
Correia, Andr. 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , title =. 2023 , pages =
work page 2023
-
[35]
Proceedings of the 38th International Conference on Machine Learning , pages =
Reinforcement Learning with Prototypical Representations , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , volume =
work page 2021
-
[36]
Proceedings of the 39th International Conference on Machine Learning , pages =
Bisimulation Makes Analogies in Goal-Conditioned Reinforcement Learning , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , volume =
work page 2022
-
[37]
Proceedings of the 39th International Conference on Machine Learning , pages =
Discriminator-Weighted Offline Imitation Learning from Suboptimal Demonstrations , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , volume =
work page 2022
-
[38]
Generative Adversarial Imitation Learning , volume =
Ho, Jonathan and Ermon, Stefano , booktitle =. Generative Adversarial Imitation Learning , volume =
-
[39]
Wu, Bohan and Xu, Feng and He, Zhanpeng and Gupta, Abhi and Allen, Peter K. , booktitle =. 2020 , pages =
work page 2020
-
[40]
Proceedings of The 6th Conference on Robot Learning , pages =
Reinforcement learning with Demonstrations from Mismatched Task under Sparse Reward , author =. Proceedings of The 6th Conference on Robot Learning , pages =. 2023 , volume =
work page 2023
-
[41]
Kang, Katie and Gradu, Paula and Choi, Jason J and Janner, Michael and Tomlin, Claire and Levine, Sergey , booktitle =. 2022 , volume =
work page 2022
-
[42]
Proceedings of the AAAI Conference on Artificial Intelligence , author =
Deep Q-learning From Demonstrations , volume =. Proceedings of the AAAI Conference on Artificial Intelligence , author =. 2018 , month =. doi:10.1609/aaai.v32i1.11757 , number =
-
[43]
Highway Exiting Planner for Automated Vehicles Using Reinforcement Learning , year =
Cao, Zhong and Yang, Diange and Xu, Shaobing and Peng, Huei and Li, Boqi and Feng, Shuo and Zhao, Ding , journal =. Highway Exiting Planner for Automated Vehicles Using Reinforcement Learning , year =
-
[44]
Bouton, Maxime and Nakhaei, Alireza and Isele, David and Fujimura, Kikuo and Kochenderfer, Mykel J. , booktitle =. Reinforcement Learning with Iterative Reasoning for Merging in Dense Traffic , year =
-
[45]
Interaction-aware Decision Making with Adaptive Strategies under Merging Scenarios , year =
Hu, Yeping and Nakhaei, Alireza and Tomizuka, Masayoshi and Fujimura, Kikuo , booktitle =. Interaction-aware Decision Making with Adaptive Strategies under Merging Scenarios , year =
-
[46]
IEEE Transactions on Robotics , title =
Eteke, Cem and Keb. IEEE Transactions on Robotics , title =. 2021 , volume =
work page 2021
-
[47]
Efficient training of artificial neural networks for autonomous navigation , author =. Neural Computation , volume =. 1991 , publisher =
work page 1991
-
[48]
A reduction of imitation learning and structured prediction to no-regret online learning , author =. Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , pages =. 2011 , organization =
work page 2011
-
[49]
Proceedings of the Twenty-First International Conference on Machine Learning , pages =
Apprenticeship learning via inverse reinforcement learning , author =. Proceedings of the Twenty-First International Conference on Machine Learning , pages =. 2004 , organization =
work page 2004
-
[50]
Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence , pages =
Maximum entropy inverse reinforcement learning , author =. Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence , pages =
-
[51]
International Conference on Learning Representations , year =
Learning robust rewards with adversarial inverse reinforcement learning , author =. International Conference on Learning Representations , year =
-
[52]
Proceedings of the 28th International Joint Conference on Artificial Intelligence , pages =
Recent Advances in Imitation Learning from Observation , author =. Proceedings of the 28th International Joint Conference on Artificial Intelligence , pages =. 2019 , doi =
work page 2019
-
[53]
Behavioral cloning from observation , author =. Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence , pages =
-
[54]
2018 IEEE International Conference on Robotics and Automation , pages =
Imitation from observation: Learning to imitate behaviors from raw video via context translation , author =. 2018 IEEE International Conference on Robotics and Automation , pages =. 2018 , organization =
work page 2018
-
[55]
International Conference on Learning Representations , year =
Third-person imitation learning , author =. International Conference on Learning Representations , year =
-
[56]
Proceedings of the 33rd International Conference on Machine Learning , pages =
Meta-Learning with Memory-Augmented Neural Networks , author =. Proceedings of the 33rd International Conference on Machine Learning , pages =. 2016 , volume =
work page 2016
-
[57]
2024 19th Annual System of Systems Engineering Conference (SoSE) , pages =
Fear based intrinsic reward as a barrier function for continuous reinforcement learning , author =. 2024 19th Annual System of Systems Engineering Conference (SoSE) , pages =. 2024 , organization =
work page 2024
-
[58]
Jinwei Xing and Takashi Nagata and Kexin Chen and Xinyun Zou and Emre Neftci and Jeffrey L. Krichmar , doi =. Domain Adaptation In Reinforcement Learning Via Latent Unified State Representation , volume =. Proceedings of the 35th AAAI Conference on Artificial Intelligence , pages =
-
[59]
arXiv preprint arXiv:2305.04412 , year =
Efficient reinforcement learning for autonomous driving with parameterized skills and priors , author =. arXiv preprint arXiv:2305.04412 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.