Recognition: 2 theorem links
· Lean TheoremInstruction Lens Score: Your Instruction Contributes a Powerful Object Hallucination Detector for Multimodal Large Language Models
Pith reviewed 2026-05-13 05:47 UTC · model grok-4.3
The pith
Instruction token embeddings can detect object hallucinations in multimodal LLMs without extra models or training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Instruction token embeddings implicitly encode visual information while filtering erroneous signals from misleading visual embeddings. The Instruction Lens Score formed by a Calibrated Local Score and a Context Consistency Score applied to object tokens therefore serves as an effective plug-and-play detector of object hallucinations.
What carries the argument
The Instruction Lens Score (InsLen), which measures hallucination risk directly from instruction token embeddings using calibrated local similarity and context-consistency checks on generated object tokens.
If this is right
- The detector applies to many different MLLM architectures with no architecture-specific changes.
- No auxiliary models or retraining are needed at deployment.
- Both local embedding calibration and global context consistency contribute to the final score.
- The approach improves detection accuracy over prior methods on standard hallucination benchmarks.
Where Pith is reading between the lines
- Prompt design that strengthens instruction tokens could further reduce hallucinations at the source.
- The same embedding lens might be tested on attribute or relation hallucinations beyond objects.
- Real-time application of InsLen could enable on-the-fly output correction during generation.
Load-bearing premise
Instruction token embeddings encode enough visual information to filter errors introduced by the visual stream, and the two proposed scores reliably indicate whether an object name is hallucinated.
What would settle it
If InsLen scores fail to correlate with human-verified object presence on a new image-prompt dataset where ground-truth objects are exhaustively labeled, the detection method does not work.
Figures















read the original abstract
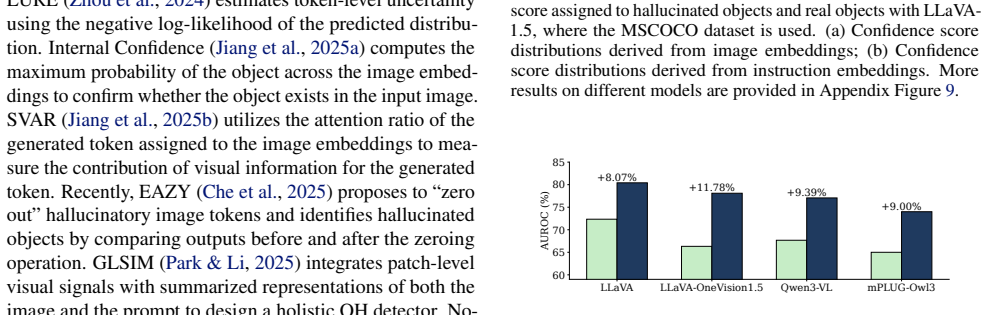
Multimodal large language models (MLLMs) have achieved remarkable progress, yet the object hallucination remains a critical challenge for reliable deployment. In this paper, we present an in-depth analysis of instruction token embeddings and reveal that they implicitly encode visual information while effectively filtering erroneous information introduced by misleading visual embeddings. Building on this insight, we propose the Instruction Lens Score (InsLen), which combines a Calibrated Local Score with a Context Consistency Score that measures context consistency of the object tokens. The proposed approach serves as a plug-and-play object hallucination detector without relying on auxiliary models or additional training. Extensive experiments across multiple benchmarks and diverse MLLM architectures demonstrate that InsLen consistently outperforms existing hallucination detection methods, highlighting its effectiveness and robustness. The code is available at https://github.com/Fraserlairh/Instruction-Lens-Score.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes instruction token embeddings in multimodal large language models (MLLMs), claiming they implicitly encode visual information while filtering erroneous details from misleading visual embeddings. It proposes the Instruction Lens Score (InsLen) as the sum of a Calibrated Local Score and a Context Consistency Score for object hallucination detection. The approach is presented as plug-and-play, requiring no auxiliary models or training, and is reported to outperform prior methods across multiple benchmarks and diverse MLLM architectures, with code released publicly.
Significance. If the empirical claims hold after addressing the definitional and validation gaps, this would represent a useful contribution by providing a lightweight, training-free detector that leverages existing model internals to improve MLLM reliability. The public code release is a clear strength supporting reproducibility.
major comments (3)
- [§3] §3 (Method): The central claim that instruction token embeddings 'implicitly encode visual information while effectively filtering erroneous information' is load-bearing for the entire InsLen construction, yet no derivation, visualization, or ablation is provided to show that the Calibrated Local Score plus Context Consistency Score isolates object hallucination rather than other inconsistencies (e.g., syntactic or factual). Without this, the plug-and-play claim across architectures cannot be evaluated.
- [§3.2] §3.2 (Calibrated Local Score definition): The term 'Calibrated' suggests a data-dependent step; explicit equations are needed to confirm whether any parameters or thresholds are fitted to the evaluation benchmarks or remain fixed and architecture-independent. If the former, it contradicts the 'no additional training' and 'plug-and-play' assertions.
- [§5] §5 (Experiments): No ablation or sensitivity analysis is reported on the Context Consistency Score's dependence on context window size, tokenizer choice, or prompt length. Such tests are required to substantiate robustness across the claimed 'diverse MLLM architectures,' as tokenizer differences could introduce confounds that undermine cross-model outperformance.
minor comments (2)
- [Abstract] The abstract would be clearer if it named the specific benchmarks and MLLM families used in the 'extensive experiments.'
- [Abstract] Ensure the GitHub link in the abstract points to a repository containing the exact code and hyperparameters used for the reported results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below with clarifications and commit to revisions that strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [§3] §3 (Method): The central claim that instruction token embeddings 'implicitly encode visual information while effectively filtering erroneous information' is load-bearing for the entire InsLen construction, yet no derivation, visualization, or ablation is provided to show that the Calibrated Local Score plus Context Consistency Score isolates object hallucination rather than other inconsistencies (e.g., syntactic or factual). Without this, the plug-and-play claim across architectures cannot be evaluated.
Authors: We acknowledge that the supporting evidence for the central claim in §3 can be strengthened. The manuscript includes an analysis of instruction token embeddings, but we agree that explicit visualizations and targeted ablations are needed to demonstrate isolation of object hallucinations. In the revised manuscript we will add t-SNE projections of instruction embeddings for hallucinated versus non-hallucinated cases and an ablation that removes the filtering component of the Calibrated Local Score, showing that performance drops specifically on object hallucination benchmarks while remaining stable on syntactic or factual inconsistency tasks. revision: yes
-
Referee: [§3.2] §3.2 (Calibrated Local Score definition): The term 'Calibrated' suggests a data-dependent step; explicit equations are needed to confirm whether any parameters or thresholds are fitted to the evaluation benchmarks or remain fixed and architecture-independent. If the former, it contradicts the 'no additional training' and 'plug-and-play' assertions.
Authors: The calibration step normalizes using fixed, pre-computed statistics (mean and standard deviation) of instruction token embeddings drawn from the model's original training distribution; no parameters are fitted to any evaluation benchmark. We will insert the full mathematical definition of the Calibrated Local Score in the revised §3.2, explicitly stating that the normalization constants are architecture-specific but benchmark-independent and require no training or tuning on test data. revision: yes
-
Referee: [§5] §5 (Experiments): No ablation or sensitivity analysis is reported on the Context Consistency Score's dependence on context window size, tokenizer choice, or prompt length. Such tests are required to substantiate robustness across the claimed 'diverse MLLM architectures,' as tokenizer differences could introduce confounds that undermine cross-model outperformance.
Authors: We agree that additional sensitivity analyses would better substantiate the robustness claims. In the revised experiments section we will report results for the Context Consistency Score under varied context window sizes, across the tokenizers native to each evaluated MLLM, and with prompt lengths ranging from short to extended. These ablations will confirm that the reported outperformance remains consistent and is not driven by tokenizer-specific artifacts. revision: yes
Circularity Check
No circularity: derivation is self-contained from embedding analysis to defined scores
full rationale
The paper begins with an empirical observation on instruction token embeddings (that they encode visual information and filter errors), then directly defines InsLen as the sum of a Calibrated Local Score and Context Consistency Score. No equations or definitions reduce the final detector to a fitted parameter on the evaluation benchmarks, a self-citation chain, or a tautological renaming. The plug-and-play claim rests on the stated construction rather than on any input that is itself derived from the output metric. Experiments across architectures serve as external validation rather than circular confirmation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearInsLen score S_Ins(o) = ω·S_cls(o) + (1−ω)·S_ccs(o) where S_cls fuses max instruction-embedding confidence with cosine similarity of object and image embeddings, and S_ccs uses ℓ2 distance to averaged high-confidence instruction embeddings.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearLogit Lens projection of instruction embeddings yields higher AUROC separation of hallucinated vs. real objects than image embeddings; no derivation from a single distinction or reciprocal cost.
Reference graph
Works this paper leans on
- [1]
-
[2]
Deyao Zhu and Jun Chen and Xiaoqian Shen and Xiang Li and Mohamed Elhoseiny , title =. ICLR , year =
-
[3]
Wenliang Dai and Junnan Li and Dongxu Li and Anthony Meng Huat Tiong and Junqi Zhao and Weisheng Wang and Boyang Li and Pascale Fung and Steven C. H. Hoi , title =. NeurIPS , year =
-
[4]
Learning to instruct for visual instruction tuning , author=. NeurIPS , year =
-
[5]
Generative Multimodal Pretraining with Discrete Diffusion Timestep Tokens , author=. CVPR , pages=
-
[6]
Run Luo and Yunshui Li and Longze Chen and Wanwei He and Ting. ICLR , year =
-
[7]
Fuxiao Liu and Kevin Lin and Linjie Li and Jianfeng Wang and Yaser Yacoob and Lijuan Wang , title =. ICLR , year =
-
[8]
Devils in middle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens , author=. CVPR , pages=
- [9]
- [10]
-
[11]
Interpreting and editing vision-language representations to mitigate hallucinations , author=. ICLR , year =
-
[12]
Yiyang Zhou and Chenhang Cui and Jaehong Yoon and Linjun Zhang and Zhun Deng and Chelsea Finn and Mohit Bansal and Huaxiu Yao , title =. ICLR , year =
-
[13]
Detecting hallucinations in large language models using semantic entropy , author=. Nature , volume=
-
[14]
Can we trust AI doctors? a survey of medical hallucination in large language and large vision-language models , author=. ACL, Findings , pages=
-
[15]
Hallucination of Multimodal Large Language Models: A Survey
Hallucination of multimodal large language models: A survey , author=. arXiv preprint arXiv:2404.18930 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =. ICLR, , year =
-
[17]
Justin Johnson and Bharath Hariharan and Laurens van der Maaten and Li Fei. CVPR , pages =
-
[18]
Evaluating Object Hallucination in Large Vision-Language Models , booktitle =
Yifan Li and Yifan Du and Kun Zhou and Jinpeng Wang and Wayne Xin Zhao and Ji. Evaluating Object Hallucination in Large Vision-Language Models , booktitle =
-
[19]
Clement Neo and Luke Ong and Philip Torr and Mor Geva and David Krueger and Fazl Barez , title =. ICLR , year =
- [20]
- [21]
-
[22]
Liqiang Jing and Ruosen Li and Yunmo Chen and Xinya Du , title =. EMNLP, Findings , pages =
-
[23]
Hallucinatory Image Tokens: A Training-free EAZY Approach to Detecting and Mitigating Object Hallucinations in LVLMs , author=. ICCV , pages=
-
[24]
Haotian Liu and Chunyuan Li and Yuheng Li and Yong Jae Lee , title =. CVPR , pages =
-
[25]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
Llava-onevision-1.5: Fully open framework for democratized multimodal training , author=. arXiv preprint arXiv:2509.23661 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [26]
-
[27]
Jiabo Ye and Haiyang Xu and Haowei Liu and Anwen Hu and Ming Yan and Qi Qian and Ji Zhang and Fei Huang and Jingren Zhou , title =. ICLR , year =
-
[28]
DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs , booktitle =
Lingchen Meng and Jianwei Yang and Rui Tian and Xiyang Dai and Zuxuan Wu and Jianfeng Gao and Yu. DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs , booktitle =
-
[29]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Beyond logit lens: Contextual embeddings for robust hallucination detection & grounding in vlms , author=. ACL , pages=
-
[31]
Andrey Malinin and Mark J. F. Gales , title =. ICLR , year =
-
[32]
Pixtral 12B , author=. arXiv preprint arXiv:2410.07073 , year=
work page internal anchor Pith review arXiv
-
[33]
Object Hallucination in Image Captioning , booktitle =
Anna Rohrbach and Lisa Anne Hendricks and Kaylee Burns and Trevor Darrell and Kate Saenko , editor =. Object Hallucination in Image Captioning , booktitle =
-
[34]
Visual instruction tuning towards general-purpose multimodal large language model: A survey , author=. IJCV , volume=
-
[35]
Aligning large multimodal models with factually augmented rlhf , author=. ACL, Findings , pages=
-
[36]
RLAIF-V: Open-source ai feedback leads to super gpt-4v trustworthiness , author=. CVPR , pages=
-
[37]
Microsoft coco: Common objects in context , author=. ECCV , pages=. 2014 , organization=
work page 2014
-
[38]
Objects365: A large-scale, high-quality dataset for object detection , author=. ICCV , pages=
-
[39]
Xuan Gong and Tianshi Ming and Xinpeng Wang and Zhihua Wei , title =. EMNLP , pages =
-
[40]
Hoigi Seo and Dong Un Kang and Hyunjin Cho and Joohoon Lee and Se Young Chun , title =. NeurIPS , year =
-
[41]
LLaMA: Open and Efficient Foundation Language Models , journal =
Hugo Touvron and Thibaut Lavril and Gautier Izacard and Xavier Martinet and Marie. LLaMA: Open and Efficient Foundation Language Models , journal =. 2023 , eprinttype =
work page 2023
-
[42]
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Learning transferable visual models from natural language supervision , author=. ICML , pages=
- [44]
-
[45]
Convis: Contrastive decoding with hallucination visualization for mitigating hallucinations in multimodal large language models , author=. AAAI , year=
-
[46]
Octopus: Alleviating hallucination via dynamic contrastive decoding , author=. CVPR , year=
-
[47]
Seeing is believing: Mitigating hallucination in large vision-language models via clip-guided decoding , author=. ICLRW , year=
-
[48]
Mitigating object hallucinations in large vision-language models through visual contrastive decoding , author=. CVPR , year=
-
[49]
Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback , author=. CVPR , year=
-
[50]
Halc: Object hallucination reduction via adaptive focal-contrast decoding , author=. ICML , year=
-
[51]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting latent predictions from transformers with the tuned lens , author=. arXiv preprint arXiv:2303.08112 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.