Recognition: no theorem link
Hypernetworks for Dynamic Feature Selection
Pith reviewed 2026-05-13 05:27 UTC · model grok-4.3
The pith
Hypernetworks generate on-demand classifier parameters for any chosen feature subset in dynamic selection tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hyper-DFS replaces mask-embedding DFS with a hypernetwork that receives a Set-Transformer encoding of the current feature subset and outputs the complete parameter vector of a classifier specific to that subset. This construction yields a strictly smaller structural complexity bound than mask-based methods while producing a smooth geometry over the space of possible subsets, allowing the model to handle arbitrary acquisition paths without enumerating them.
What carries the argument
A hypernetwork that takes a Set Transformer embedding of a feature subset and emits the full weight vector of a classifier tuned to that subset.
If this is right
- The method scales to larger feature spaces because it never stores a separate model per subset.
- Zero-shot performance on unseen subsets improves because similar subsets produce nearby conditioning vectors and therefore similar parameters.
- Training stability benefits from the lower structural complexity bound compared with mask-embedding baselines.
- The same hypernetwork can serve both training and inference without retraining when the available feature set changes.
Where Pith is reading between the lines
- The approach could support real-time feature acquisition policies that adapt budgets per sample without precomputing all paths.
- Because the conditioning space is geometric, one could interpolate between nearby subsets to create soft or ensemble classifiers.
- The same hypernetwork pattern might transfer to other combinatorial selection problems such as dynamic sensor placement or active learning query strategies.
Load-bearing premise
The hypernetwork can map every possible feature-subset encoding to a set of classifier parameters that perform well on the underlying data distribution.
What would settle it
A controlled experiment in which the hypernetwork-generated classifiers for held-out subsets consistently achieve higher error than a separately trained classifier for the same subsets.
Figures








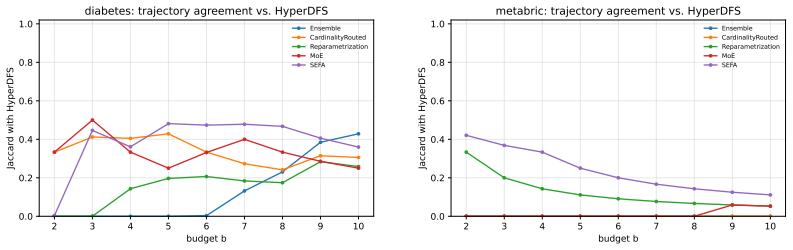



read the original abstract
Dynamic feature selection (DFS) is a machine learning framework in which features are acquired sequentially for individual samples under budget constraints. The exponential growth in the number of possible feature acquisition paths forces a DFS model to balance fitting specific scenarios against maintaining general performance, even when the feature space is moderate in size. In this paper, we study the structural limitations of existing DFS approaches to achieve an optimal solution. Then, we propose \textsc{Hyper-DFS}, a hypernetwork-based DFS approach that generates feature subset-specific classifier parameters on demand. We show that the use of hypernetworks compared to mask-embedding methods results in a smaller structural complexity bound. We also use a Set Transformer encoding to create a smooth conditioning space for the hypernetwork, so that functionally similar tasks are also geometrically close. In our benchmarks, \textsc{Hyper-DFS} outperforms all state-of-the-art approaches on synthetic and real-life tabular data. It is also competitive or superior across all image datasets tested, and shows substantially stronger zero-shot generalisation to feature subsets never seen during training than existing DFS approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Hyper-DFS, a hypernetwork-based method for dynamic feature selection (DFS). It generates classifier parameters on demand for specific feature subsets using a hypernetwork conditioned by a Set Transformer encoding of the subset. The approach is motivated by the exponential growth of feature acquisition paths in DFS and claims a smaller structural complexity bound than mask-embedding baselines. Empirical results are reported showing outperformance on synthetic and real tabular data, competitive or superior results on image datasets, and substantially stronger zero-shot generalization to unseen feature subsets.
Significance. If the empirical results and complexity analysis hold, the work could meaningfully advance DFS by offering a parameterization that scales better with the combinatorial space of feature subsets. The hypernetwork + Set Transformer design provides a concrete mechanism for smooth conditioning across tasks, which may translate to practical gains in generalization under feature budgets. The explicit comparison of structural complexity bounds is a positive theoretical element.
minor comments (2)
- The abstract states outperformance and generalization gains but does not reference specific datasets, baselines, or metrics; adding one sentence with these details would improve readability without altering the technical content.
- Notation for the hypernetwork output and the Set Transformer conditioning could be introduced earlier with a small diagram to clarify how subset encodings map to classifier weights.
Simulated Author's Rebuttal
We thank the referee for the positive and insightful review of our manuscript on Hyper-DFS. We appreciate the recognition of the method's potential to advance dynamic feature selection through hypernetworks and Set Transformers, as well as the acknowledgment of the structural complexity analysis and empirical results on generalization. No specific major comments were raised in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes Hyper-DFS as an architectural solution to DFS path-space explosion, compares structural complexity bounds to mask-embedding baselines, and reports empirical outperformance plus zero-shot generalization. No equations, parameter-fitting steps, or self-citations are presented in the provided text that reduce any claimed prediction or uniqueness result to a redefinition or input fit. The complexity-bound comparison is stated as a derived property of the hypernetwork design rather than an unexamined premise, and all performance claims rest on external benchmarks. This is the common case of a self-contained empirical architecture paper with no load-bearing self-referential reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Spectrally-Normalized Margin Bounds for Neural Networks , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Beck, Jacob and Jackson, Matthew Thomas and Vuorio, Risto and Whiteson, Shimon , booktitle =. Hypernetworks in. 2023 , publisher =
work page 2023
- [3]
- [4]
-
[5]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Hyperfast: Instant classification for tabular data , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
- [6]
-
[7]
Chattopadhyay, Aditya and Chan, Kwan Ho Ryan and Haeffele, Benjamin David and Geman, Donald and Vidal, Rene , booktitle=. Variational
-
[8]
Artificial Intelligence Review , volume=
A brief review of hypernetworks in deep learning , author=. Artificial Intelligence Review , volume=
- [9]
-
[10]
Proceedings of the 40th International Conference on Machine Learning , pages=
Learning to maximize mutual information for dynamic feature selection , author=. Proceedings of the 40th International Conference on Machine Learning , pages=. 2023 , publisher =
work page 2023
-
[11]
The genomic and transcriptomic architecture of 2,000 breast tumours reveals novel subgroups , author=. Nature , volume=
-
[12]
The American Journal of Cardiology , volume=
International application of a new probability algorithm for the diagnosis of coronary artery disease , author=. The American Journal of Cardiology , volume=
-
[13]
A cost-aware framework for the development of
Erion, Gabriel and Janizek, Joseph D and Hudelson, Carly and Utarnachitt, Richard B and McCoy, Andrew M and Sayre, Michael R and White, Nathan J and Lee, Su-In , journal=. A cost-aware framework for the development of
-
[14]
Counting processes and survival analysis , author=. 2013 , publisher=
work page 2013
-
[15]
arXiv preprint arXiv:2502.01375 , year=
Model-Agnostic Dynamic Feature Selection with Uncertainty Quantification , author=. arXiv preprint arXiv:2502.01375 , year=
- [16]
-
[17]
Galanti, Tomer and Wolf, Lior , booktitle =. On the
-
[18]
Understanding the difficulty of training deep feedforward neural networks , author=. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , pages=. 2010 , publisher =
work page 2010
-
[19]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Goyal, Priya and Doll. Accurate,. arXiv preprint arXiv:1706.02677 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Ha, David and Dai, Andrew and Le, Quoc V , booktitle=. Hyper
-
[21]
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , booktitle=. Deep
- [22]
-
[23]
Proceedings of the AAAI conference on Artificial Intelligence , volume=
Classification with costly features using deep reinforcement learning , author =. Proceedings of the AAAI conference on Artificial Intelligence , volume=
-
[24]
Karayev, Sergey and Fritz, Mario J and Darrell, Trevor , booktitle=. Dynamic
-
[25]
Kompella, Varun Raj and Luciw, Matthew and Stollenga, Marijn Frederik and Schmidhuber, Juergen , journal=. Optimal
- [26]
-
[27]
International Conference on Learning Representations , year=
Imputation for prediction: beware of diminishing returns , author=. International Conference on Learning Representations , year=
-
[28]
Advances in Neural Information Processing Systems , volume=
Le Morvan, Marine and Josse, Julie and Moreau, Thomas and Scornet, Erwan and Varoquaux, Ga. Advances in Neural Information Processing Systems , volume=
- [29]
-
[30]
Lee, Juho and Lee, Yoonho and Kim, Jungtaek and Kosiorek, Adam and Choi, Seungjin and Teh, Yee Whye , booktitle=. Set. 2019 , publisher=
work page 2019
-
[31]
Liu, Bo and Liu, Xingchao and Jin, Xiaojie and Stone, Peter and Liu, Qiang , booktitle=. Conflict-Averse
- [32]
-
[33]
A primer on linear classification with missing data , author=. Proceedings of The 28th International Conference on Artificial Intelligence and Statistics , volume =. 2025 , publisher=
work page 2025
-
[34]
Proceedings of the 36th International Conference on Machine Learning , pages=
Ma, Chao and Tschiatschek, Sebastian and Palla, Konstantina and Hern. Proceedings of the 36th International Conference on Machine Learning , pages=. 2019 , publisher=
work page 2019
-
[35]
Maddison, Chris and Mnih, Andriy and Teh, Yee Whye , booktitle=. The
-
[36]
Decision Support Systems , volume=
A data-driven approach to predict the success of bank telemarketing , author=. Decision Support Systems , volume=
-
[37]
Muller, Christophe and Scornet, Erwan and Josse, Julie , journal=. When
-
[38]
Reading Digits in Natural Images with Unsupervised Feature Learning , author=. Neural Information Processing Systems Workshop on Deep Learning and Unsupervised Feature Learning , year=
-
[39]
Norcliffe, Alexander Luke Ian and Lee, Changhee and Imrie, Fergus and Van Der Schaar, Mihaela and Lio, Pietro , booktitle=. Stochastic. 2025 , publisher=
work page 2025
- [40]
-
[41]
Statistics & Probability Letters , volume=
Sparse spatial autoregressions , author=. Statistics & Probability Letters , volume=
-
[42]
Paleyes, Andrei and Urma, Raoul-Gabriel and Lawrence, Neil D , journal=. Challenges in
-
[43]
Przewi. Hyper. Neurocomputing , volume=
-
[44]
Rifai, Salah and Vincent, Pascal and Muller, Xavier and Glorot, Xavier and Bengio, Yoshua , booktitle=. Contractive
-
[45]
Roe, Byron P and Yang, Hai-Jun and Zhu, Ji and Liu, Yong and Stancu, Ion and McGregor, Gordon , journal=. Boosted
- [46]
-
[47]
The Annals of Statistics , volume=
Nonparametric classification with missing data , author=. The Annals of Statistics , volume=
- [48]
-
[49]
Sristi, Ram Dyuthi and Lindenbaum, Ofir and Lifshitz, Shira and Lavzin, Maria and Schiller, Jackie and Mishne, Gal and Benisty, Hadas , booktitle=. Contextual. 2024 , publisher=
work page 2024
-
[50]
Stempfle, Lena and Panahi, Ashkan and Johansson, Fredrik D , journal=. Sharing
- [51]
-
[52]
Valancius, Michael and Lennon, Maxwell and Oliva, Junier , booktitle=. Acquisition. 2024 , publisher=
work page 2024
- [53]
-
[54]
International Conference on Learning Representations , year=
Continual learning with hypernetworks , author=. International Conference on Learning Representations , year=
- [55]
-
[56]
Yoon, Jinsung and Jordon, James and Van der Schaar, Mihaela , booktitle=
- [57]
-
[58]
Zaheer, Manzil and Kottur, Satwik and Ravanbakhsh, Siamak and Poczos, Barnabas and Salakhutdinov, Russ R and Smola, Alexander J , booktitle=. Deep
-
[59]
International Conference on Machine Learning Real-world Sequential Decision Making Workshop , year=
Zannone, Sara and Hern. International Conference on Machine Learning Real-world Sequential Decision Making Workshop , year=
-
[60]
Zhao, Dominic and Kobayashi, Seijin and Sacramento, Jo. Meta-. Neural Information Processing Systems Workshop on Meta-Learning , year=
- [61]
- [62]
- [63]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.