Recognition: no theorem link
Neural-Schwarz Tiling for Geometry-Universal PDE Solving at Scale
Pith reviewed 2026-05-13 06:17 UTC · model grok-4.3
The pith
Local neural operators on 3x3x3 patches compose into accurate global solutions for large nonlinear PDEs via iterative Schwarz coupling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NEST trains a neural operator on minimal 3x3x3 voxel patches that contain diverse local geometries and interface data. At inference an unseen large voxelized domain is partitioned into overlapping patches; the learned local solver is applied to each patch; and global consistency is recovered by iterative Schwarz domain decomposition combined with partition-of-unity assembly. The framework is demonstrated on nonlinear static equilibrium problems for compressible neo-Hookean solids, producing accurate solutions on domains far larger and more geometrically complex than any training example.
What carries the argument
Neural-Schwarz Tiling (NEST): a local-to-global composition that applies a learned operator patchwise and enforces consistency through iterative Schwarz coupling plus partition-of-unity weighting.
If this is right
- The identical locally trained model applies without modification to domains of any size or shape.
- Generalization to new boundary conditions and material parameters occurs through the domain-decomposition algorithm rather than the neural network.
- Training data generation is confined to small patches, eliminating the need for full-domain problem-specific datasets.
- The same local solver can be deployed on multiple unrelated large-scale problems after a single training run.
Where Pith is reading between the lines
- The approach could be tested on time-dependent or coupled multiphysics problems if the local patches are shown to capture the relevant local dynamics.
- Parallel implementation is straightforward because each patch solve is independent until the Schwarz updates are exchanged.
- Accuracy may degrade when patch size is too small to contain essential nonlocal effects, suggesting a need to characterize the minimal patch size for a given PDE.
- Hybrid use with traditional numerical methods inside selected patches could further reduce training cost while preserving global consistency.
Load-bearing premise
The local physics captured inside a single 3x3x3 patch together with classical Schwarz iteration is enough to restore global consistency and accuracy for nonlinear problems on arbitrarily large domains.
What would settle it
On a large domain containing strong nonlinear interactions that cross many patch boundaries, the Schwarz-coupled local solutions either fail to converge or deviate from a reference global solver by more than the reported error tolerance.
Figures
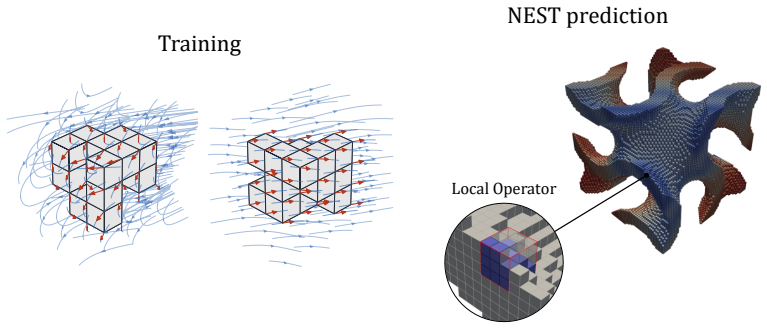
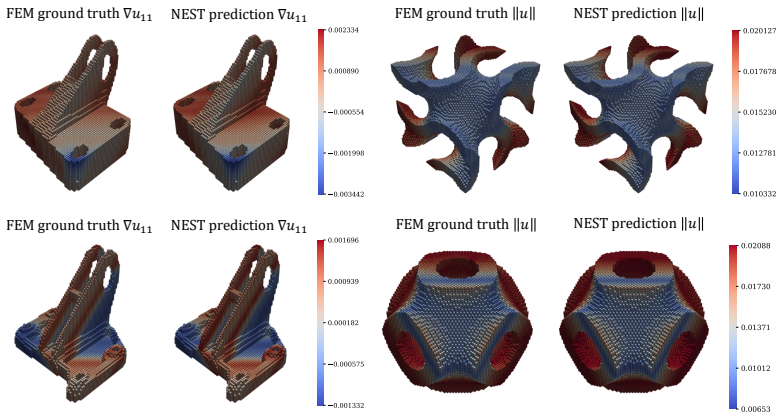
read the original abstract
Most learned PDE solvers follow a global-surrogate paradigm: a neural operator is trained to map full problem descriptions to full solution fields for a prescribed distribution of geometries, boundary conditions, and coefficients. This has enabled fast inference within fixed problem families, but limits reuse across new domains and makes large-scale deployment dependent on expensive problem-specific data generation. We introduce $\textbf{NEST}$ ($\textbf{Ne}$ural-$\textbf{S}$chwarz $\textbf{T}$iling), a local-to-global framework that shifts learning from full-domain solution operators to reusable local physical solvers. The central premise is that, although global PDE solutions depend on geometry, scale, and boundary conditions, the physical response on small neighborhoods can be learned locally and composed into global solutions through classical domain decomposition. NEST learns a neural operator on minimal voxel patches ($3 \times 3 \times 3$) with diverse local geometries and boundary/interface data. At inference time, an unseen voxelized domain is tiled into overlapping patches, the learned local solver is applied patchwise, and global consistency is enforced through iterative Schwarz coupling with partition-of-unity assembly. In this way, generalization is shifted from a monolithic neural model to the combination of local physics learning and algorithmic global assembly. We instantiate NEST on nonlinear static equilibrium in compressible neo-Hookean solids and evaluate it on large, geometrically complex 3D domains far outside the scale of the training patches. Our results show that local neural building blocks, coupled through Schwarz iteration, offer a reusable local-training path toward scalable learned PDE solvers that generalize across domain size, shape, and boundary-condition configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Neural-Schwarz Tiling (NEST), a local-to-global framework that trains a neural operator on minimal 3x3x3 voxel patches with diverse local geometries and interface data, then assembles global solutions for nonlinear static equilibrium in compressible neo-Hookean solids on large, complex 3D domains via iterative Schwarz domain decomposition and partition-of-unity weighting. The central claim is that this combination shifts generalization from monolithic global training to reusable local physics learning plus classical algorithmic coupling, enabling accurate solutions far outside the training scale and distribution.
Significance. If the quantitative results and convergence properties hold, the work would be significant for scalable learned PDE solvers: it offers a reusable local-training path that decouples learning from global domain size and geometry, potentially reducing data-generation costs for large-scale nonlinear problems. The explicit integration of classical Schwarz theory with learned local maps is a concrete strength, as is the focus on nonlinear constitutive response rather than linear cases.
major comments (2)
- [Abstract and §3] Abstract and §3 (Method): the central claim that local 3x3x3 neural operators plus Schwarz iteration recover accurate global solutions for nonlinear problems on arbitrary large domains lacks any reported quantitative error metrics, convergence rates, residual bounds, or interface consistency analysis. Without these, the sufficiency of small patches for capturing solution-dependent stiffness and long-range effects cannot be assessed.
- [§4] §4 (Experiments): the evaluation on large domains far outside training scale is described only qualitatively in the abstract; the absence of ablation studies on patch size, overlap, relaxation parameters, or nonlinear solver iterations leaves the load-bearing assumption—that local physics plus classical coupling suffices—unverified.
minor comments (2)
- [§3] Notation for the partition-of-unity weights and the Schwarz iteration operator should be defined explicitly with an equation number in §3 to avoid ambiguity when describing the assembly step.
- [Figures] Figure captions for the large-domain examples should include the specific error norms used and the number of Schwarz iterations required for convergence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript introducing Neural-Schwarz Tiling (NEST). The comments correctly identify areas where additional quantitative rigor will strengthen the presentation of our local-to-global framework for nonlinear elasticity. We address each major comment below and will incorporate the suggested analyses in the revised version.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): the central claim that local 3x3x3 neural operators plus Schwarz iteration recover accurate global solutions for nonlinear problems on arbitrary large domains lacks any reported quantitative error metrics, convergence rates, residual bounds, or interface consistency analysis. Without these, the sufficiency of small patches for capturing solution-dependent stiffness and long-range effects cannot be assessed.
Authors: We agree that the abstract and method section would benefit from explicit quantitative support for the central claim. In the revised manuscript we will add, in §4, relative L2 and H1 error norms of the assembled global solutions against reference finite-element solutions on the large-scale test domains. In §3 we will include Schwarz iteration convergence plots (residual decay per iteration) together with interface jump norms to quantify consistency across patch boundaries. These additions will directly address the sufficiency of 3x3x3 patches for local stiffness and the propagation of long-range effects through the iterative coupling. revision: yes
-
Referee: [§4] §4 (Experiments): the evaluation on large domains far outside training scale is described only qualitatively in the abstract; the absence of ablation studies on patch size, overlap, relaxation parameters, or nonlinear solver iterations leaves the load-bearing assumption—that local physics plus classical coupling suffices—unverified.
Authors: We acknowledge the value of systematic ablations for verifying the core assumption. The revised §4 will contain ablation tables and figures examining (i) patch size (3×3×3 versus 5×5×5), (ii) overlap width, (iii) Schwarz relaxation parameter, and (iv) the number of local nonlinear Newton iterations. These studies will quantify how each factor affects global accuracy and iteration count on domains far larger than the training patches, thereby confirming that the learned local operators plus classical coupling are sufficient. revision: yes
Circularity Check
No significant circularity in NEST derivation chain
full rationale
The paper trains a neural operator exclusively on 3x3x3 local patches with diverse geometries and interface data, then assembles global solutions at inference via iterative Schwarz domain decomposition and partition-of-unity weighting. This separation keeps the learned local map independent of the target global fields; the assembly step invokes classical Schwarz theory rather than any fitted parameter or self-referential definition. No equation or claim reduces a global prediction to the training inputs by construction, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The framework therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Schwarz alternating procedure converges for the nonlinear elasticity problem when local solvers are sufficiently accurate.
- domain assumption Local 3x3x3 patches contain enough information to represent the constitutive response of compressible neo-Hookean material under arbitrary interface conditions.
Reference graph
Works this paper leans on
-
[1]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[2]
Shashank Subramanian, Peter Harrington, Kurt Keutzer, Wahid Bhimji, Dmitriy Morozov, Michael W Mahoney, and Amir Gholami. Towards foundation models for scientific machine learning: Characterizing scaling and transfer behavior.Advances in Neural Information Pro- cessing Systems, 36:71242–71262, 2023
work page 2023
-
[3]
Michael McCabe, Bruno Régaldo-Saint Blancard, Liam Parker, Ruben Ohana, Miles Cranmer, Alberto Bietti, Michael Eickenberg, Siavash Golkar, Geraud Krawezik, Francois Lanusse, et al. Multiple physics pretraining for spatiotemporal surrogate models.Advances in Neural Information Processing Systems, 37:119301–119335, 2024
work page 2024
-
[4]
On the feasibility of foundational models for the simulation of physical phenomena
Alicia Tierz, Mikel M Iparraguirre, Icíar Alfaro, David González, Francisco Chinesta, and Elías Cueto. On the feasibility of foundational models for the simulation of physical phenomena. International Journal for Numerical Methods in Engineering, 126(6):e70027, 2025
work page 2025
-
[5]
Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
work page 2021
-
[6]
Marco Maurizi, Derek Xu, Yu-Tong Wang, Desheng Yao, David Hahn, Mourad Oudich, Anish Satpati, Mathieu Bauchy, Wei Wang, Yizhou Sun, et al. Designing metamaterials with programmable nonlinear responses and geometric constraints in graph space.Nature Machine Intelligence, 7(7):1023–1036, 2025
work page 2025
-
[7]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019. 10
work page 2019
-
[8]
Learning data-efficient and generalizable neural operators via fundamental physics knowledge
Siying Ma, Mehrdad M Zadeh, Mauricio Soroco, Wuyang Chen, Jiguo Cao, and Vijay Ganesh. Learning data-efficient and generalizable neural operators via fundamental physics knowledge. arXiv preprint arXiv:2602.15184, 2026
-
[9]
Mikhail Masliaev, Dmitry Gusarov, Ilya Markov, and Alexander Hvatov. Towards universal neural operators through multiphysics pretraining.arXiv preprint arXiv:2511.10829, 2025
-
[10]
Qian-Ze Zhu, Paul Raccuglia, and Michael P Brenner. Generalizing pde emulation with equation-aware neural operators.arXiv preprint arXiv:2511.09729, 2025
-
[11]
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to PDEs.Journal of Machine Learning Research, 24(89):1–97, 2023. URLhttps://jmlr.org/papers/v24/21-1524.html
work page 2023
-
[12]
Springer Science & Business Media, 2004
Andrea Toselli and Olof Widlund.Domain decomposition methods-algorithms and theory, volume 34. Springer Science & Business Media, 2004
work page 2004
-
[13]
Tarek Poonithara Abraham Mathew.Domain decomposition methods for the numerical solution of partial differential equations. Springer, 2008
work page 2008
-
[14]
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nature Machine Intelligence, 3(3):218–229, 2021. doi: 10.1038/s42256-021-00302-5. URL https://doi.org/10.1038/s42256-021-00302-5
-
[15]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differen- tial equations.arXiv preprint arXiv:2010.08895, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[16]
Zongyi Li, Hongkai Zheng, Nikola Kovachki, David Jin, Haoxuan Chen, Burigede Liu, Kamyar Azizzadenesheli, and Anima Anandkumar. Physics-informed neural operator for learning partial differential equations.ACM/IMS Journal of Data Science, 1(3):1–27, 2024. doi: 10.1145/3648506. URLhttps://doi.org/10.1145/3648506
- [17]
-
[18]
Geometry-informed neural operator for large- scale 3d PDEs
Zongyi Li, Nikola Kovachki, Christopher Choy, Boyi Li, Jean Kossaifi, Shourya Otta, Mohammad Amin Nabian, Maximilian Stadler, Christian Hundt, Kamyar Azizzade- nesheli, and Animashree Anandkumar. Geometry-informed neural operator for large- scale 3d PDEs. InAdvances in Neural Information Processing Systems, volume 36,
-
[19]
URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 70518ea42831f02afc3a2828993935ad-Abstract-Conference.html
work page 2023
-
[20]
Transolver: A fast transformer solver for PDEs on general geometries
Haixu Wu, Huakun Luo, Haowen Wang, Jianmin Wang, and Mingsheng Long. Transolver: A fast transformer solver for PDEs on general geometries. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 53681–53705. PMLR, 2024. URL https://proceedings.mlr.press/v235/wu24r. html
work page 2024
-
[21]
Huakun Luo, Haixu Wu, Hang Zhou, Lanxiang Xing, Yichen Di, Jianmin Wang, and Mingsheng Long. Transolver++: An accurate neural solver for pdes on million-scale geometries.arXiv preprint arXiv:2502.02414, 2025
-
[22]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[23]
Andrey Bryutkin, Jiahao Huang, Zhongying Deng, Guang Yang, Carola-Bibiane Schönlieb, and Angelica I. Aviles-Rivero. HAMLET: Graph transformer neural operator for partial differential equations. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 4624–4641. PMLR, 2024. URL htt...
work page 2024
-
[24]
Society for Industrial and Applied Mathematics, Philadelphia, PA, 2015
Victorita Dolean, Pierre Jolivet, and Frédéric Nataf.An Introduction to Domain Decomposition Methods: Algorithms, Theory, and Parallel Implementation, volume 144 ofOther Titles in Applied Mathematics. Society for Industrial and Applied Mathematics, Philadelphia, PA, 2015. doi: 10.1137/1.9781611974065. URLhttps://doi.org/10.1137/1.9781611974065
-
[25]
Weihang Ouyang, Yeonjong Shin, Si-Wei Liu, and Lu Lu. Noem: efficient and scalable finite element method enabled by reusable neural operators.Nature Computational Science, 6(4): 417–429, 2026
work page 2026
-
[26]
Learning interface conditions in domain decomposi- tion solvers
Ali Taghibakhshi, Nicolas Nytko, Tareq Uz Zaman, Scott MacLachlan, Luke Ol- son, and Matthew West. Learning interface conditions in domain decomposi- tion solvers. InAdvances in Neural Information Processing Systems, volume 35,
-
[27]
URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 2f8928efe957139e9c0efc98f173f4be-Abstract-Conference.html
work page 2022
-
[28]
Jianing Huang, Kaixuan Zhang, Youjia Wu, and Ze Cheng. Operator learning with domain decomposition for geometry generalization in pde solving.arXiv preprint arXiv:2504.00510, 2025
-
[29]
A learning-based domain decomposition method
Rui Wu, Nikola Kovachki, and Burigede Liu. A learning-based domain decomposition method. Computer Methods in Applied Mechanics and Engineering, 453:118799, 2026
work page 2026
-
[30]
Zongyi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar. Fourier neural operator with learned deformations for pdes on general geometries.Journal of Machine Learning Research, 24(388):1–26, 2023
work page 2023
-
[31]
Geometric operator learning with optimal transport.arXiv preprint arXiv:2507.20065, 2025
Xinyi Li, Zongyi Li, Nikola Kovachki, and Anima Anandkumar. Geometric operator learning with optimal transport.arXiv preprint arXiv:2507.20065, 2025
-
[32]
Springer Science & Business Media, 2012
Anders Logg, Kent-Andre Mardal, and Garth Wells.Automated solution of differential equations by the finite element method: The FEniCS book, volume 84. Springer Science & Business Media, 2012
work page 2012
-
[33]
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Graph kernel network for partial differential equations.arXiv preprint arXiv:2003.03485, 2020
-
[34]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[35]
Simjeb: simulated jet engine bracket dataset
Eamon Whalen, Azariah Beyene, and Caitlin Mueller. Simjeb: simulated jet engine bracket dataset. InComputer Graphics Forum, volume 40, pages 9–17. Wiley Online Library, 2021
work page 2021
-
[36]
Oraib Al-Ketan and Rashid K Abu Al-Rub. Mslattice: A free software for generating uniform and graded lattices based on triply periodic minimal surfaces.Material Design & Processing Communications, 3(6):e205, 2021
work page 2021
-
[37]
Data-efficient discovery of hyperelastic tpms metamaterials with extreme energy dissipation
Maxine Perroni-Scharf, Zachary Ferguson, Thomas Butruille, Carlos Portela, and Mina Kon- akovi´c Lukovi´c. Data-efficient discovery of hyperelastic tpms metamaterials with extreme energy dissipation. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–12, 2025. 12 Appendix A Err...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.