Recognition: no theorem link
From Message-Passing to Linearized Graph Sequence Models
Pith reviewed 2026-05-13 05:58 UTC · model grok-4.3
The pith
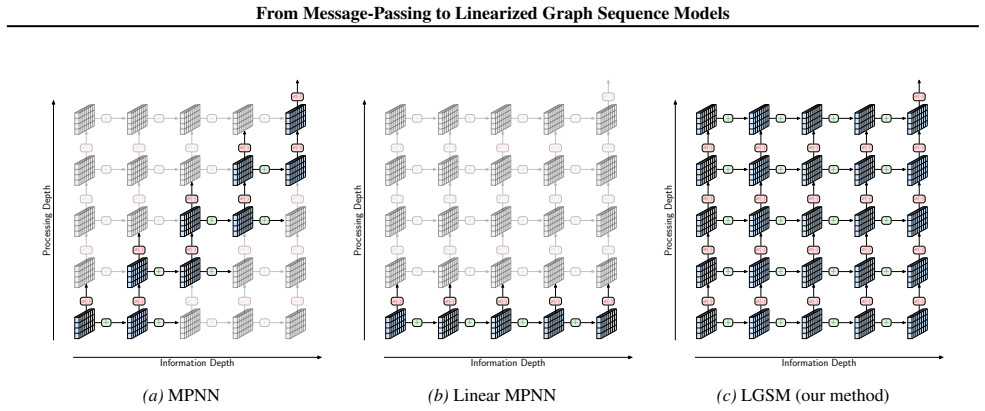
Linearized Graph Sequence Models recast message-passing by separating computational processing depth from information propagation depth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By recasting message-passing graph computation from the perspective of sequence modeling, the framework separates computational processing depth from information propagation depth. This separation allows core graph architectural decisions to be treated as sequence modeling choices. Analysis of sequence properties, both empirical and theoretical, identifies those that effectively learn and preserve the graph inductive bias, with validation showing improved performance on long-range information tasks in graphs.
What carries the argument
The separation of computational processing depth from information propagation depth, which recasts central graph architectural questions as input modeling choices within sequence models.
If this is right
- Improved accuracy on graph tasks that require information to travel across many hops.
- A direct method to import modern sequence-model advances such as efficient attention or state-space layers into graph architectures.
- Graph design choices such as layer ordering and neighborhood aggregation become explicit decisions about sequence input formatting.
- Preservation of the original graph inductive bias while still allowing deeper computational processing without proportional growth in propagation steps.
Where Pith is reading between the lines
- The depth separation could be applied to other structured domains such as point clouds or meshes by treating their connectivity as a sequence.
- Testing whether specific sequence properties like linearity or recurrence directly translate to measurable gains in graph expressivity would confirm the mapping.
- The framework suggests that future work could derive parameter-free relations between sequence length and required propagation depth for given graph diameters.
Load-bearing premise
That sequence modeling properties can be identified and applied to effectively learn and preserve the graph inductive bias without introducing new limitations on information flow or expressivity.
What would settle it
A sequence model built on the identified properties shows no gain in long-range task accuracy or fails to retain graph structural bias compared with standard message-passing networks on the same benchmarks.
Figures





read the original abstract
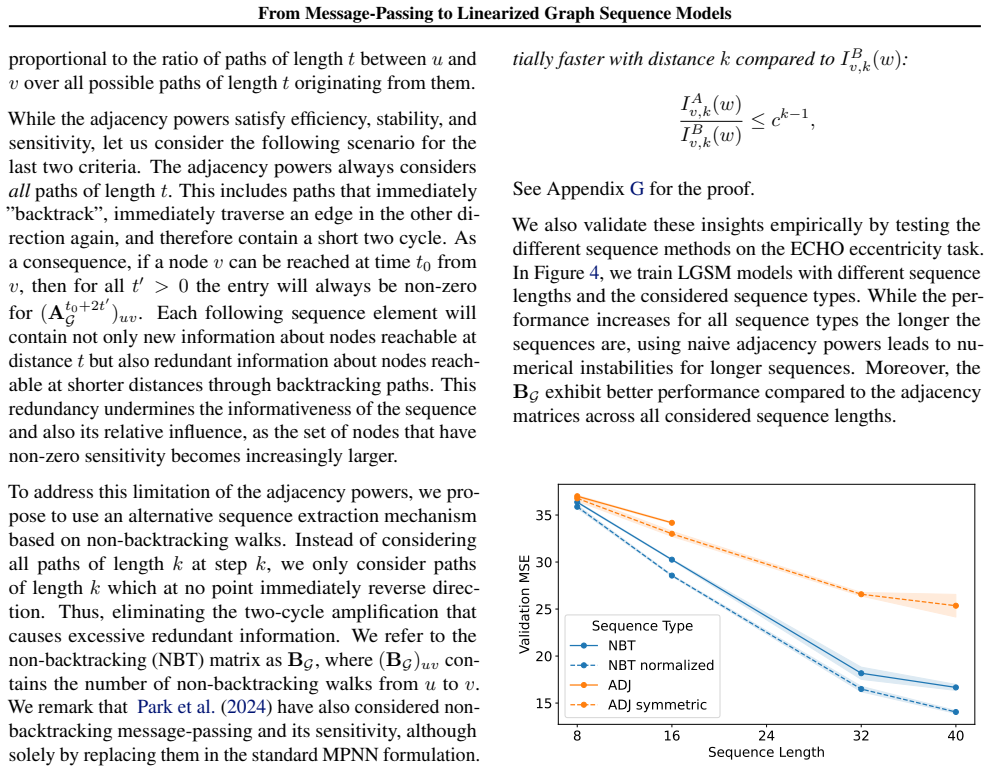
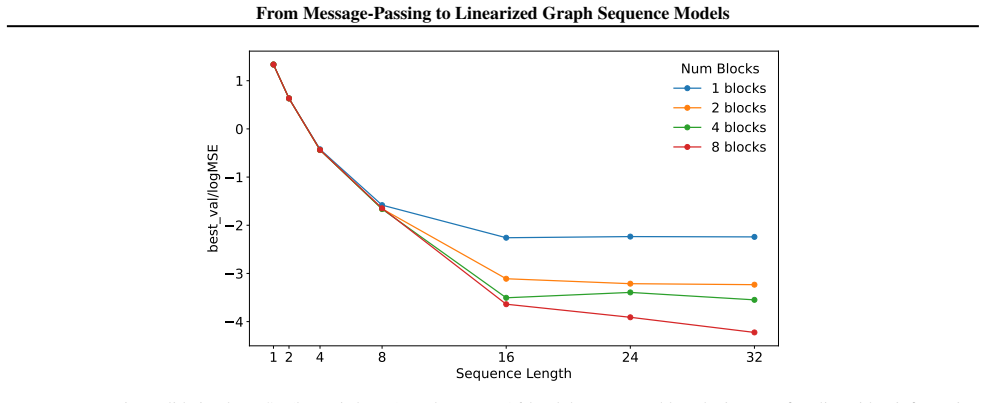
Message-passing based approaches form the default backbone of most learning architectures on graph-structured data. However, the rapid progress of modern deep learning architectures in other domains, particularly sequence modeling, raises the question of how graph learning can benefit from these advances. We introduce Linearized Graph Sequence Models, a framework that recasts message-passing graph computation from the perspective of sequence modeling to simplify architectural choices. Our approach systematically separates the computational processing depth from the information propagation depth, allowing core graph architectural decisions to be treated as sequence modeling choices. Specifically, we analyze, both empirically and theoretically, what sequence properties make methods effective for learning and preserving the graph inductive bias. In particular, we validate our findings, demonstrating improved performance on long-range information tasks in graphs. Our findings provide a principled way to integrate modern sequence modeling advances into message-passing based graph learning. Beyond this, our work demonstrates how the separation of processing and information depth can recast central architectural questions as input modeling choices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Linearized Graph Sequence Models, a framework that recasts message-passing graph computation from the perspective of sequence modeling. It systematically separates computational processing depth from information propagation depth, allowing core graph architectural decisions to be treated as sequence modeling choices. The authors analyze (empirically and theoretically) which sequence properties enable effective learning and preservation of graph inductive bias, and report improved performance on long-range information tasks in graphs.
Significance. If the separation of depths is shown to preserve graph structure without introducing ordering-dependent limitations on expressivity, the work could provide a principled bridge between message-passing GNNs and modern sequence models, enabling more flexible integration of sequence-modeling advances into graph learning and better handling of long-range dependencies.
major comments (1)
- [§3] §3 (linearization and depth separation): the central claim that graph architectural decisions reduce to sequence-modeling choices requires an explicit argument or theorem showing that the chosen linearization (traversal or ordering) embeds the full adjacency structure invariantly; without this, distant nodes in the original graph can become arbitrarily distant in the sequence, forcing reliance on the sequence model's long-range mechanism rather than the original topology and undermining the claimed separation.
minor comments (2)
- The abstract and experimental sections should include concrete metrics, baselines, and error bars for the long-range task results to allow assessment of the claimed improvements.
- Notation for propagation depth versus computational depth should be introduced with a clear equation or diagram early in the method section.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for identifying a point that merits clarification in §3. We address the major comment below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [§3] §3 (linearization and depth separation): the central claim that graph architectural decisions reduce to sequence-modeling choices requires an explicit argument or theorem showing that the chosen linearization (traversal or ordering) embeds the full adjacency structure invariantly; without this, distant nodes in the original graph can become arbitrarily distant in the sequence, forcing reliance on the sequence model's long-range mechanism rather than the original topology and undermining the claimed separation.
Authors: We agree that an explicit formal argument would strengthen the central claim. In the Linearized Graph Sequence Model framework, the linearization step produces a sequence whose successive positions correspond to message-passing steps along the graph edges; the propagation depth is exactly the length of this sequence, while the processing depth is the number of layers in the sequence model. Consequently, the adjacency structure is encoded directly in which positions are allowed to exchange information at each propagation step, independent of the Euclidean distances that arise from any particular traversal order. The sequence model then only needs to realize the chosen computational depth on this already-structured input. To make the invariance explicit, we will add a short theorem in the revised §3 stating that any complete traversal linearization preserves the original adjacency relation under the message-passing equivalence: for any pair of nodes connected by a path of length k, there exists a corresponding segment of length k in the sequence whose information flow is governed solely by the graph topology, not by the ordering chosen for the sequence. This shows that reliance on the sequence model’s long-range capabilities is not required; the topology is already injected via the linearization. We will also include a brief discussion of how different traversal heuristics affect only the computational efficiency of the linearization, not the preserved inductive bias. revision: yes
Circularity Check
Framework recasting introduces no circular derivations
full rationale
The paper introduces a conceptual framework by recasting message-passing as sequence modeling and separating computational processing depth from information propagation depth, then analyzes sequence properties empirically and theoretically for preserving graph inductive bias. No equations, derivations, or load-bearing steps are present in the abstract that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central claims rest on the separation as an organizing perspective plus validation, remaining self-contained without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum? id=i80OPhOCVH2. Arnaiz-Rodriguez, A. and Errica, F. Oversmoothing, Over- squashing, Heterophily, Long-Range, and more: Demys- tifying Common Beliefs in Graph Machine Learning, June 2025. URL http://arxiv.org/abs/2505. 15547. arXiv:2505.15547 [cs]. Arnaiz-Rodrıiguez, A., Begga, A., Escolano, F., and Oliver, N. M. DiffWire:...
-
[2]
Graph Mamba: Towards learning on graphs with state space models,
URL https://proceedings.mlr.press/ v198/arnaiz-rodri-guez22a.html. ISSN: 2640-3498. Arroyo, A., Gravina, A., Gutteridge, B., Barbero, F., Gallicchio, C., Dong, X., Bronstein, M. M., and Van- dergheynst, P. On Vanishing Gradients, Over-Smoothing, and Over-Squashing in GNNs: Bridging Recurrent and Graph Learning. October 2025. URL https: //openreview.net/fo...
-
[3]
URL https://proceedings.mlr.press/ v119/chen20v.html. Cohen, S. and Agmon, N. Convexified Graph Neural Net- works for Distributed Control in Robotic Swarms. vol- ume 3, pp. 2307–2313, August 2021. doi: 10.24963/ ijcai.2021/318. URL https://www.ijcai.org/ proceedings/2021/318. ISSN: 1045-0823. Dao, T. and Gu, A. Transformers are SSMs: general- ized models ...
work page 2021
-
[4]
URL https://proceedings.mlr.press/ v235/ding24d.html. Dwivedi, V . P., Ramp´avsek, L., Galkin, M., Parviz, A., Wolf, G., Luu, A. T., and Beaini, D. Long range graph benchmark. InProceedings of the 36th International Con- ference on Neural Information Processing Systems, NIPS ’22, pp. 22326–22340, Red Hook, NY , USA, November
-
[5]
Curran Associates Inc. ISBN 978-1-7138-7108-8. Eliasof, M., Gravina, A., Ceni, A., Gallicchio, C., Bac- ciu, D., and Sch ¨onlieb, C.-B. Graph Adaptive Au- toregressive Moving Average Models. InProceed- ings of the 42nd International Conference on Ma- chine Learning, pp. 15232–15265. PMLR, October
-
[6]
node2vec: Scalable Feature Learning for Networks
URL https://proceedings.mlr.press/ v267/eliasof25a.html. Gilmer, J., Schoenholz, S. S., Riley, P. F., Vinyals, O., and Dahl, G. E. Neural message passing for Quantum chemistry. InProceedings of the 34th International Con- ference on Machine Learning - Volume 70, ICML’17, pp. 1263–1272, Sydney, NSW, Australia, August 2017. JMLR.org. URL https://dl.acm.org/...
-
[7]
Gu, A., Dao, T., Ermon, S., Rudra, A., and R ´e, C
URL https://openreview.net/forum? id=tEYskw1VY2. Gu, A., Dao, T., Ermon, S., Rudra, A., and R ´e, C. HiPPO: recurrent memory with optimal polynomial pro- jections. InProceedings of the 34th International Con- ference on Neural Information Processing Systems, NIPS ’20, pp. 1474–1487, Red Hook, NY , USA, December
- [8]
-
[9]
URL https://dl.acm.org/doi/10.5555/ 3495724.3495849. Gu, A., Goel, K., and Re, C. Efficiently Modeling Long Sequences with Structured State Spaces. October
-
[10]
Gutteridge, B., Dong, X., Bronstein, M., and Di Giovanni, F
URL https://openreview.net/forum? id=uYLFoz1vlAC. Gutteridge, B., Dong, X., Bronstein, M., and Di Giovanni, F. DRew: dynamically rewired message passing with delay. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofICML’23, pp. 12252– 12267, Honolulu, Hawaii, USA, July 2023. JMLR.org. Heilig, S., Gravina, A., Trenta, A.,...
work page 2023
-
[11]
Huang, Y ., Miao, S., and Li, P
URL https://openreview.net/forum? id=03EkqSCKuO. Huang, Y ., Miao, S., and Li, P. What Can We Learn from State Space Models for Machine Learning on Graphs? October 2024. URL https://openreview.net/ forum?id=xAM9VaXZnY. Keriven, N. Not too little, not too much: a theoretical analysis of graph (over)smoothing. InProceedings of the 36th International Confere...
work page 2024
-
[12]
Ma, L., Lin, C., Lim, D., Romero-Soriano, A., Dokania, P
URL https://openreview.net/forum? id=SJU4ayYgl. Ma, L., Lin, C., Lim, D., Romero-Soriano, A., Dokania, P. K., Coates, M., Torr, P. H., and Lim, S.-N. Graph inductive biases in transformers without message passing. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofICML’23, pp. 23321– 23337, Honolulu, Hawaii, USA, July 202...
-
[13]
Perozzi, B., Al-Rfou, R., and Skiena, S
URL https://openreview.net/forum? id=64HdQKnyTc. Perozzi, B., Al-Rfou, R., and Skiena, S. DeepWalk: on- line learning of social representations. InProceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, KDD ’14, pp. 701– 710, New York, NY , USA, August 2014. Association for Computing Machinery. ISBN 978-1-4503-2...
-
[14]
Scarselli, F., Gori, M., Tsoi, A
URL https://proceedings.mlr.press/ v162/rusch22a.html. Scarselli, F., Gori, M., Tsoi, A. C., Hagenbuchner, M., and Monfardini, G. The Graph Neural Network Model. IEEE Transactions on Neural Networks, 20(1):61–80, January 2009. ISSN 1941-0093. doi: 10.1109/TNN. 2008.2005605. URL https://ieeexplore.ieee. org/document/4700287. Stoll, T., M ¨uller, L., and Mo...
work page doi:10.1109/tnn 2009
-
[15]
T¨onshoff, J., Ritzert, M., Rosenbluth, E., and Grohe, M
URL https://openreview.net/forum? id=vgXnEyeWVY. T¨onshoff, J., Ritzert, M., Rosenbluth, E., and Grohe, M. Where Did the Gap Go? Reassessing the Long-Range Graph Benchmark.Transactions on Machine Learning Research, January 2024. ISSN 2835-8856. URL https: //openreview.net/forum?id=Nm0WX86sKv. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L.,...
work page 2024
-
[16]
URL https://openreview.net/forum? id=ryGs6iA5Km. Xu, K., Li, C., Tian, Y ., Sonobe, T., Kawarabayashi, K.-i., and Jegelka, S. Representation Learning on Graphs with Jumping Knowledge Networks. InPro- ceedings of the 35th International Conference on Ma- chine Learning, pp. 5453–5462. PMLR, July 2018. URL https://proceedings.mlr.press/v80/ xu18c.html. ISSN:...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.