Recognition: 2 theorem links
· Lean TheoremMetaColloc: Optimization-Free PDE Solving via Meta-Learned Basis Functions
Pith reviewed 2026-05-13 05:53 UTC · model grok-4.3
The pith
MetaColloc solves new PDEs by freezing meta-learned basis functions and performing one linear least-squares solve at test time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A meta-trained dual-branch neural network produces a universal dictionary of basis functions from Gaussian random fields; once frozen, any new PDE is solved by assembling a collocation matrix from those functions and finding the coefficients through one linear least-squares solve, with Newton-Raphson delivering quadratic convergence on nonlinear equations.
What carries the argument
Meta-trained dual-branch neural network that outputs basis functions from Gaussian random fields, which are then used to build the collocation matrix for the linear solve.
Load-bearing premise
Basis functions learned from Gaussian random fields will generalize without retraining to the specific operators and boundary conditions of new PDEs.
What would settle it
A new PDE whose solution cannot be represented accurately by the fixed basis functions, producing large residual errors in the collocation least-squares solve even after the meta-training step.
Figures


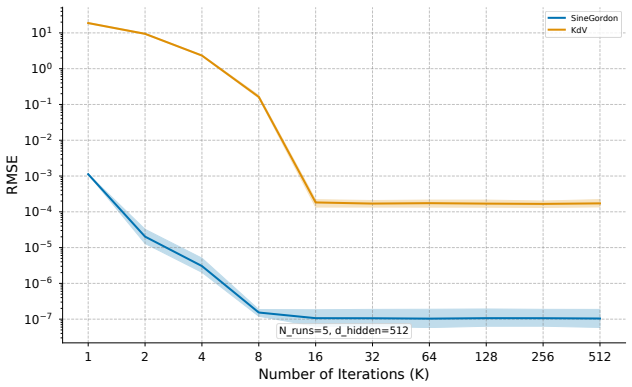


read the original abstract
Solving partial differential equations (PDEs) with machine learning typically requires training a new neural network for every new equation. This optimization is slow. We introduce MetaColloc. It is an optimization-free and data-free framework that removes this bottleneck completely. We decouple basis discovery from the solving process. We meta-train a dual-branch neural network on diverse Gaussian Random Fields. This offline process creates a universal dictionary of neural basis functions. At test time, we freeze the network. We solve the PDE by assembling a collocation matrix. We find the solution through a single linear least squares step. For non-linear PDEs, we apply the Newton-Raphson method to achieve fast quadratic convergence. Our experiments across six 2D and 3D PDEs show massive improvements. MetaColloc reaches state-of-the-art accuracy on smooth and non-linear problems. It also reduces test-time computation by several orders of magnitude. Finally, we provide a detailed frequency sweep analysis. This analysis reveals a critical mismatch between function approximation and operator stability at extremely high frequencies. This profound finding opens a clear path toward future operator-aware meta-learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MetaColloc, an optimization-free, data-free framework for solving PDEs. A dual-branch neural network is meta-trained offline on diverse Gaussian random fields to produce a fixed dictionary of neural basis functions. At test time the network is frozen and each new PDE is solved by assembling a collocation matrix and performing a single linear least-squares step (Newton-Raphson for nonlinear cases). Experiments on six 2D/3D PDEs claim state-of-the-art accuracy together with orders-of-magnitude reduction in test-time cost; a frequency-sweep study is presented that identifies a mismatch between function approximation quality and operator stability at high frequencies.
Significance. If the reported accuracy and generalization hold, the work would provide a practical route to decoupling expensive basis discovery from per-instance PDE solving, yielding a reusable dictionary that enables near-instant linear solves. The frequency-sweep analysis supplies a concrete diagnostic for when such dictionaries remain reliable, which is a useful contribution to neural-operator and physics-informed methods.
major comments (3)
- [frequency sweep analysis] The central generalization claim—that bases meta-trained on isotropic GRFs suffice for arbitrary test PDE operators and boundary conditions without retraining—receives no supporting analysis. The frequency-sweep section already documents operator-stability mismatches; the same mismatch can appear at moderate frequencies when the target operator differs from GRF statistics, rendering the single-step least-squares solve inaccurate or ill-conditioned.
- [experiments] No error analysis, condition-number bounds, or approximation-error guarantees are given for the span of the learned basis functions. Without these, the assertion that the collocation matrix yields SOTA accuracy on smooth and nonlinear problems rests solely on unverified experimental assertions.
- [experiments] The manuscript provides no ablation on the number of basis functions, meta-training distribution statistics, or sensitivity to boundary-condition mismatch. These omissions make it impossible to assess whether the reported orders-of-magnitude speed-up is achieved while preserving the claimed accuracy.
minor comments (2)
- [method] The dual-branch architecture and the precise construction of the collocation matrix should be stated with explicit equations and pseudocode.
- [experiments] Tables reporting L2 or H1 errors, wall-clock times, and direct comparisons to PINN, DeepONet, and FNO baselines are needed to substantiate the SOTA claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments raise important points on generalization, theoretical support, and experimental completeness. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [frequency sweep analysis] The central generalization claim—that bases meta-trained on isotropic GRFs suffice for arbitrary test PDE operators and boundary conditions without retraining—receives no supporting analysis. The frequency-sweep section already documents operator-stability mismatches; the same mismatch can appear at moderate frequencies when the target operator differs from GRF statistics, rendering the single-step least-squares solve inaccurate or ill-conditioned.
Authors: We appreciate this observation. The generalization claim is supported empirically by results on six PDEs spanning linear/nonlinear operators and varied boundary conditions, all solved accurately with the fixed GRF-trained dictionary. The frequency-sweep analysis shows breakdown only at extremely high frequencies; our test cases remain in the moderate-frequency regime where stability holds. In revision we will add a spectral comparison between training GRF statistics and test operators, plus new experiments on PDEs whose operators deviate further from GRF spectra. A full theoretical characterization of the stability region remains future work. revision: partial
-
Referee: [experiments] No error analysis, condition-number bounds, or approximation-error guarantees are given for the span of the learned basis functions. Without these, the assertion that the collocation matrix yields SOTA accuracy on smooth and nonlinear problems rests solely on unverified experimental assertions.
Authors: We agree that formal approximation bounds and condition-number guarantees would strengthen the theoretical foundation. Deriving such results for meta-learned neural bases requires substantial additional analysis that lies beyond the scope of the present work, which focuses on the practical framework and empirical performance. In the revision we will report empirical condition numbers observed across all test cases and clarify that SOTA accuracy claims are empirical, backed by the reported numerical results. revision: partial
-
Referee: [experiments] The manuscript provides no ablation on the number of basis functions, meta-training distribution statistics, or sensitivity to boundary-condition mismatch. These omissions make it impossible to assess whether the reported orders-of-magnitude speed-up is achieved while preserving the claimed accuracy.
Authors: We acknowledge the importance of these ablations for assessing robustness. The revised manuscript will include a new ablation subsection reporting: (i) accuracy and solve time versus number of basis functions (32–256), (ii) sensitivity to GRF hyperparameters (length scale and variance), and (iii) performance under boundary-condition mismatch (e.g., Dirichlet-trained dictionary tested on Neumann or mixed conditions). These results will quantify the accuracy–speed trade-off. revision: yes
Circularity Check
No significant circularity: test-time solve is independent of meta-training loss
full rationale
The paper decouples meta-training (on GRFs to produce frozen basis functions) from test-time solution (standard linear least-squares collocation on the fixed dictionary, or Newton-Raphson for nonlinear cases). This separation means the reported accuracy and speed claims do not reduce by the paper's own equations to a quantity defined in terms of the meta-training objective. No self-citations, uniqueness theorems, ansatzes smuggled via prior work, or fitted parameters renamed as predictions appear in the provided text. The frequency-sweep analysis is presented as an empirical observation rather than a load-bearing derivation. This is the normal case of a self-contained method whose central claim rests on external validation rather than internal redefinition.
Axiom & Free-Parameter Ledger
free parameters (1)
- meta-training hyperparameters
axioms (1)
- domain assumption Gaussian random fields provide sufficient diversity to learn basis functions that generalize to unseen PDE operators and domains
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe meta-train a dual-branch neural network on diverse Gaussian Random Fields... At test time, we freeze the network. We solve the PDE by assembling a collocation matrix... single linear least squares step.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearfrequency sweep analysis reveals a critical mismatch between function approximation and operator stability
Reference graph
Works this paper leans on
-
[1]
Universal physics transformers: A framework for efficiently scal- ing neural operators
Benedikt Alkin, Andreas Fürst, Simon Schmid, Lukas Gruber, Markus Holzleitner, and Johannes Brandstetter. Universal physics transformers: A framework for efficiently scal- ing neural operators. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Sys- tems, volume 37, pages...
work page 2024
-
[2]
Nachman Aronszajn. Theory of reproducing kernels.Transactions of the American mathemati- cal society, 68(3):337–404, 1950
work page 1950
-
[3]
Physics-informed diffusion models
Jan-Hendrik Bastek, WaiChing Sun, and Dennis Kochmann. Physics-informed diffusion models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=tpYeermigp
work page 2025
-
[4]
PRDP: Progressively refined differentiable physics
Kanishk Bhatia, Felix Koehler, and Nils Thuerey. PRDP: Progressively refined differentiable physics. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=9Fh0z1JmPU
work page 2025
-
[5]
Yuntian Chen et al. Solving partial differential equations with point source based on physics- informed neural networks.Journal of Computational Physics, 2021
work page 2021
-
[6]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradb...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Kronecker-factored approximate cur- vature for physics-informed neural networks
Felix Dangel, Johannes Müller, and Marius Zeinhofer. Kronecker-factored approximate cur- vature for physics-informed neural networks. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 34582–34636. Curran Associates, Inc., 2024. doi: 10.52202/079...
-
[8]
Suchuan Dong and Zongyi Li. Local extreme learning machines and domain decomposition for solving linear and nonlinear partial differential equations.Computer Methods in Applied Mechanics and Engineering, 387:114129, 2021. doi: 10.1016/j.cma.2021.114129
-
[9]
Solving high frequency and multi-scale PDEs with gaussian processes
Shikai Fang, Madison Cooley, Da Long, Shibo Li, Mike Kirby, and Shandian Zhe. Solving high frequency and multi-scale PDEs with gaussian processes. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=q4AEBLHuA6
work page 2024
-
[10]
SINGER: Stochastic network graph evolving operator for high dimensional PDEs
Mingquan Feng, Yixin Huang, Weixin Liao, Yuhong Liu, Yizhou Liu, and Junchi Yan. SINGER: Stochastic network graph evolving operator for high dimensional PDEs. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=wVADj7yKee
work page 2025
-
[11]
Randnet-parareal: a time-parallel pde solver using random neural networks
Guglielmo Gattiglio, Lyudmila Grigoryeva, and Massimiliano Tamborrino. Randnet-parareal: a time-parallel pde solver using random neural networks. In A. Globerson, L. Mackey, D. Bel- grave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 94993–95025. Curran Associates, Inc., 2024. doi...
-
[12]
The power of linear combinations: Learning with random convolutions, 2023
Paul Gavrikov and Janis Keuper. The power of linear combinations: Learning with random convolutions, 2023. URLhttps://arxiv.org/abs/2301.11360
-
[13]
Minh Ha Quang.Reproducing kernel Hilbert spaces in learning theory. Brown University, 2006
work page 2006
-
[14]
Newton informed neural operator for solv- ing nonlinear partial differential equations
Wenrui Hao, Xinliang Liu, and Yahong Yang. Newton informed neural operator for solv- ing nonlinear partial differential equations. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Pro- cessing Systems, volume 37, pages 120832–120860. Curran Associates, Inc., 2024. doi: 10.52202/07...
-
[15]
Sobolev regularity of gaussian random fields.Journal of Functional Analysis, 286(3):110241, 2024
Iain Henderson. Sobolev regularity of gaussian random fields.Journal of Functional Analysis, 286(3):110241, 2024
work page 2024
-
[16]
Poseidon: Efficient founda- tion models for pdes
Maximilian Herde, Bogdan Raoni ´c, Tobias Rohner, Roger Käppeli, Roberto Moli- naro, Emmanuel de Bézenac, and Siddhartha Mishra. Poseidon: Efficient founda- tion models for pdes. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Sys- tems, volume 37, pages 72525–72624. C...
work page 2024
-
[17]
Extreme learning machine: theory and applications
Guang-Bin Huang, Qin-Yu Zhu, and Chee-Kheong Siew. Extreme learning machine: theory and applications. InNeurocomputing, 2006
work page 2006
-
[18]
Diffusionpde: Gen- erative pde-solving under partial observation
Jiahe Huang, Guandao Yang, Zichen Wang, and Jeong Joon Park. Diffusionpde: Gen- erative pde-solving under partial observation. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Pro- cessing Systems, volume 37, pages 130291–130323. Curran Associates, Inc., 2024. doi: 10.52202/079017...
-
[19]
Dual cone gradient descent for training physics- informed neural networks
Youngsik Hwang and Dong-Young Lim. Dual cone gradient descent for training physics- informed neural networks. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Pa- quet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Sys- tems, volume 37, pages 98563–98595. Curran Associates, Inc., 2024. doi: 10.52202/ 079017-3128. URL https...
work page 2024
-
[20]
PIG: Physics-informed gaussians as adaptive parametric mesh representations
Namgyu Kang, Jaemin Oh, Youngjoon Hong, and Eunbyung Park. PIG: Physics-informed gaussians as adaptive parametric mesh representations. InThe Thirteenth International Con- ference on Learning Representations, 2025. URL https://openreview.net/forum?id= y5B0ca4mjt
work page 2025
-
[21]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Burigede liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. InInternational Conference on Learning Representations, 2021. URLhttps://openreview.net/forum?id=c8P9NQVtmnO
work page 2021
-
[22]
Zongyi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar. Fourier neural operator with learned deformations for pdes on general geometries.Journal of Machine Learning Research, 24(388):1–26, 2023. URLhttp://jmlr.org/papers/v24/23-0064.html
work page 2023
-
[23]
Chunyang Liao. Solving partial differential equations with random feature models.Communi- cations in Nonlinear Science and Numerical Simulation, page 109343, 2025
work page 2025
-
[24]
ConFIG: Towards conflict-free training of physics informed neural networks
Qiang Liu, Mengyu Chu, and Nils Thuerey. ConFIG: Towards conflict-free training of physics informed neural networks. InThe Thirteenth International Conference on Learning Representa- tions, 2025. URLhttps://openreview.net/forum?id=APojAzJQiq
work page 2025
-
[25]
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljacic, Thomas Y . Hou, and Max Tegmark. KAN: Kolmogorov–arnold networks. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=Ozo7qJ5vZi
work page 2025
-
[26]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum? id=Bkg6RiCqY7
work page 2019
-
[27]
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature machine intelligence, 3(3):218–229, 2021. doi: 10.1038/s42256-021-00302-5
-
[28]
Tianzheng Lu, Lili Ju, and Liyong Zhu. A multiple transferable neural network method with domain decomposition for elliptic interface problems.Journal of Computational Physics, 530:113902, 2025. ISSN 0021-9991. doi: https://doi.org/10.1016/j.jcp.2025.113902. URL https://www.sciencedirect.com/science/article/pii/S0021999125001858
-
[29]
Milan Luki´c and Jay Beder. Stochastic processes with sample paths in reproducing kernel hilbert spaces.Transactions of the American Mathematical Society, 353(10):3945–3969, 2001
work page 2001
-
[30]
Multiple physics pre- training for spatiotemporal surrogate models
Michael McCabe, Bruno Régaldo-Saint Blancard, Liam Parker, Ruben Ohana, Miles Cran- mer, Alberto Bietti, Michael Eickenberg, Siavash Golkar, Geraud Krawezik, Francois Lanusse, Mariel Pettee, Tiberiu Tesileanu, Kyunghyun Cho, and Shirley Ho. Multiple physics pre- training for spatiotemporal surrogate models. In A. Globerson, L. Mackey, D. Belgrave, A. Fan,...
-
[31]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Eberhardt, Bengio Yoshua, and Aaron Courville. On the spectral bias of neural networks. InInternational Conference on Machine Learning, pages 5301–5310. PMLR, 2019. 12
work page 2019
-
[32]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. InAdvances in neural information processing systems, 2007
work page 2007
-
[33]
Yeh, Jean Kossaifi, Kamyar Az- izzadenesheli, and Anima Anandkumar
Ashiqur Rahman, Robert Joseph George, Mogab Elleithy, Daniel Leibovici, Zongyi Li, Boris Bonev, Colin White, Julius Berner, Raymond A. Yeh, Jean Kossaifi, Kamyar Az- izzadenesheli, and Anima Anandkumar. Pretraining codomain attention neural operators for solving multiphysics pdes. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Pa- quet, J. Tomczak, a...
work page 2024
-
[34]
M. Raissi, P. Perdikaris, and G.E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707, 2019. ISSN 0021-9991. doi: https://doi.org/10.1016/j.jcp.2018.10.045. URL https://www.sciencedirect.com/ scien...
-
[35]
Aroma: Preserving spatial structure for latent pde modeling with lo- cal neural fields
Louis Serrano, Thomas X Wang, Etienne Le Naour, Jean-Noël Vittaut, and Patrick Gallinari. Aroma: Preserving spatial structure for latent pde modeling with lo- cal neural fields. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Sys- tems, volume 37, pages 13489–13521. Cu...
work page 2024
-
[36]
Improved sampling of diffusion models in fluid dynamics with tweedie’s formula
Youssef Shehata, Benjamin Holzschuh, and Nils Thuerey. Improved sampling of diffusion models in fluid dynamics with tweedie’s formula. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=0FbzC7B9xI
work page 2025
-
[37]
Aliaksandra Shysheya, Cristiana Diaconu, Federico Bergamin, Paris Perdikaris, José Miguel Hernández-Lobato, Richard E. Turner, and Emile Mathieu. On conditional diffusion mod- els for pde simulations. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Pa- quet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Sys- tems, volume ...
-
[38]
Fourier fea- tures let networks learn high frequency functions in low dimensional domains
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Ragha- van, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier fea- tures let networks learn high frequency functions in low dimensional domains. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Proce...
work page 2020
-
[39]
Metamizer: A versatile neural optimizer for fast and accurate physics simulations
Nils Wandel, Stefan Schulz, and Reinhard Klein. Metamizer: A versatile neural optimizer for fast and accurate physics simulations. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=60TXv9Xif5
work page 2025
-
[40]
Understanding and mitigating gradient flow pathologies in physics-informed neural networks
Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and mitigating gradient flow pathologies in physics-informed neural networks. InSIAM Journal on Scientific Computing, 2021
work page 2021
-
[41]
Sifan Wang, Hanwen Wang, and Paris Perdikaris. On the eigenvector bias of fourier feature networks: From regression to solving multi-scale pdes with physics-informed neural networks. InComputer Methods in Applied Mechanics and Engineering, 2021
work page 2021
-
[42]
Respecting causality is all you need for training physics-informed neural networks
Sifan Wang, Shyam Sankaran, and Paris Perdikaris. Respecting causality is all you need for training physics-informed neural networks. InarXiv preprint arXiv:2203.07404, 2022. 13
-
[43]
Sifan Wang, Jacob H Seidman, Shyam Sankaran, Hanwen Wang, George J. Pappas, and Paris Perdikaris. CVit: Continuous vision transformer for operator learning. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=cRnCcuLvyr
work page 2025
-
[44]
Latent neural operator for solving forward and in- verse pde problems
Tian Wang and Chuang Wang. Latent neural operator for solving forward and in- verse pde problems. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Sys- tems, volume 37, pages 33085–33107. Curran Associates, Inc., 2024. doi: 10.52202/ 079017-1042. URL https://proceedings...
work page 2024
-
[45]
CL-diffphycon: Closed-loop diffusion control of complex physical systems
Long Wei, Haodong Feng, Yuchen Yang, Ruiqi Feng, Peiyan Hu, Xiang Zheng, Tao Zhang, Dixia Fan, and Tailin Wu. CL-diffphycon: Closed-loop diffusion control of complex physical systems. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=PiHGrTTnvb
work page 2025
-
[46]
Christopher KI Williams and Carl Edward Rasmussen.Gaussian processes for machine learning, volume 2. MIT press Cambridge, MA, 2006
work page 2006
-
[47]
Ropinn: Re- gion optimized physics-informed neural networks
Haixu Wu, Huakun Luo, Yuezhou Ma, Jianmin Wang, and Mingsheng Long. Ropinn: Re- gion optimized physics-informed neural networks. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Pro- cessing Systems, volume 37, pages 110494–110532. Curran Associates, Inc., 2024. doi: 10.52202/0790...
-
[48]
Zezhong Zhang, Feng Bao, Lili Ju, and Guannan Zhang. Transferable neural networks for partial differential equations.Journal of Scientific Computing, 99(2):31, 2024. doi: 10.1007/ s10915-024-02463-y
work page 2024
-
[49]
Alias- free mamba neural operator
Jianwei Zheng, Wei Li, Ni Xu, Junwei Zhu, Xiaoxu Lin, and Xiaoqin Zhang. Alias- free mamba neural operator. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Pa- quet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Sys- tems, volume 37, pages 52962–52995. Curran Associates, Inc., 2024. doi: 10.52202/ 079017-1678. URL https:/...
work page 2024
-
[50]
Anthony Zhou, Zijie Li, Michael Schneier, John R Buchanan Jr, and Amir Barati Farimani. Text2PDE: Latent diffusion models for accessible physics simulation. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=Nb3a8aUGfj. 14 A Experimental Setup and Hyperparameters We provide the exact settings ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.