Recognition: no theorem link
Massive MIMO CSI Feedback with Spiking Neural Networks
Pith reviewed 2026-05-13 03:20 UTC · model grok-4.3
The pith
Spiking neural networks achieve CSI feedback performance competitive with transformers for massive MIMO systems while cutting energy use by over 93 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
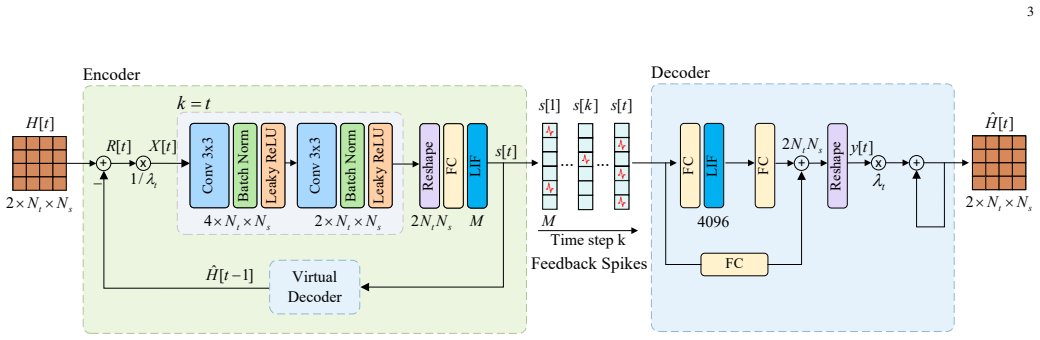
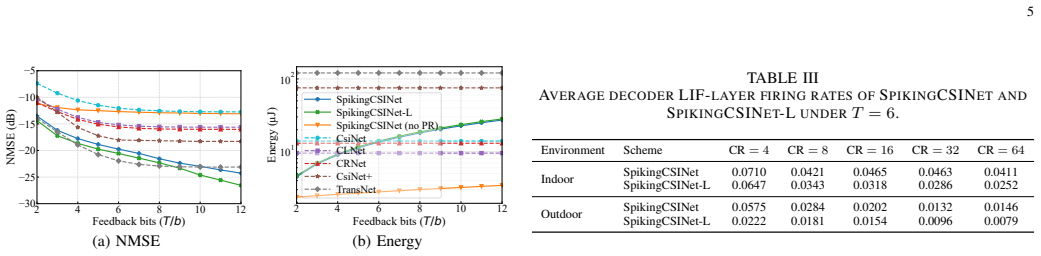
SpikingCSINet implements CSI feedback and its internal computations entirely with binary spikes. To compensate for the limited information carried by each spike, the progressive residual architecture transmits successive residuals of the reconstruction error across successive time steps of the spiking network. On the COST 2100 channel model, this yields reconstruction accuracy competitive with transformer-based feedback while reducing energy consumption by more than 93 percent compared with those baselines.
What carries the argument
The progressive residual architecture, which uses the temporal dimension inherent in spiking networks to encode successive residuals across discrete time steps and thereby increases the effective information capacity of the binary spike train.
Load-bearing premise
The progressive residual architecture sufficiently compensates for the information bottleneck of binary spikes to enable high-dimensional CSI reconstruction without significant performance loss under realistic channel conditions.
What would settle it
A direct comparison on the COST 2100 dataset showing that SpikingCSINet produces substantially higher normalized mean squared error than a transformer baseline at the same feedback compression rate would falsify the performance claim.
Figures
read the original abstract
Deep learning-based channel state information (CSI) feedback has achieved empirical success in massive multiple-input multiple-output (MIMO) systems. However, existing approaches largely rely on dense artificial neural networks (ANNs), whose computational overhead limits their practical applications. In this article, we exploit bio-inspired spiking neural networks (SNNs) for massive MIMO CSI feedback, referred to as SpikingCSINet, where both the feedback and the main network computations are implemented through spikes. To overcome the information bottleneck of binary spikes in high-dimensional reconstruction, we develop a progressive residual (PR) architecture that exploits the natural temporal dimension of SNNs, encoding successive residuals across time steps to enhance information compactness. Experiments on the COST 2100 benchmark show that SpikingCSINet attains a more favorable performance-efficiency tradeoff than lightweight convolutional baselines. Moreover, it achieves performance competitive with Transformer-based feedback while reducing energy consumption by over $93\%$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SpikingCSINet, a spiking neural network for CSI feedback in massive MIMO systems. Both the feedback and network computations use spikes; a progressive residual (PR) architecture encodes successive residuals over time steps to mitigate the information bottleneck of binary spikes. On the COST 2100 benchmark, the approach is reported to achieve a favorable performance-efficiency tradeoff versus lightweight convolutional baselines and performance competitive with Transformer-based methods while reducing energy consumption by over 93%.
Significance. If the reported tradeoff holds under rigorous validation, the work provides concrete evidence that SNNs can deliver substantial energy savings for high-dimensional CSI reconstruction tasks without prohibitive performance loss. This is a timely contribution at the intersection of bio-inspired computing and wireless communications, with potential implications for low-power edge deployment in 5G/6G systems. The explicit acknowledgment of the spike bottleneck and the use of a public benchmark are positive elements.
major comments (2)
- [Section 4 (Experiments) and Section 3.2 (Progressive Residual Architecture)] The central claim of >93% energy reduction and competitive performance rests on the PR architecture compensating for binary-spike information loss. An ablation that isolates the contribution of the temporal residual encoding (e.g., comparing SpikingCSINet with and without the PR mechanism under identical spike thresholds and time-step counts) is needed to confirm that this component, rather than other design choices, drives the observed tradeoff.
- [Section 4.3 (Energy Consumption Analysis)] The energy model underlying the 93% reduction figure must be fully specified, including the precise spike-counting method, hardware assumptions (e.g., synaptic operation energy), and whether the comparison holds under identical quantization and inference settings for the ANN baselines. Without this, the efficiency claim risks being sensitive to modeling choices.
minor comments (2)
- [Section 4.1 (Implementation Details)] Clarify the exact values and ranges used for the free parameters 'number of time steps' and 'spike threshold' in the experimental setup, and report sensitivity of NMSE to these choices.
- [Figure 3 and Table 2] Ensure all figures include error bars or standard deviations across random seeds to allow assessment of result stability.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. The comments highlight important aspects for strengthening the manuscript, and we address each major point below with plans for revision.
read point-by-point responses
-
Referee: [Section 4 (Experiments) and Section 3.2 (Progressive Residual Architecture)] The central claim of >93% energy reduction and competitive performance rests on the PR architecture compensating for binary-spike information loss. An ablation that isolates the contribution of the temporal residual encoding (e.g., comparing SpikingCSINet with and without the PR mechanism under identical spike thresholds and time-step counts) is needed to confirm that this component, rather than other design choices, drives the observed tradeoff.
Authors: We agree that isolating the PR architecture's contribution via ablation is necessary to substantiate the central claim. In the revised manuscript, we will add an ablation study comparing SpikingCSINet with and without the progressive residual mechanism. All other parameters, including spike thresholds and time-step counts, will be held identical to ensure the comparison directly attributes performance gains to the temporal residual encoding rather than ancillary design choices. revision: yes
-
Referee: [Section 4.3 (Energy Consumption Analysis)] The energy model underlying the 93% reduction figure must be fully specified, including the precise spike-counting method, hardware assumptions (e.g., synaptic operation energy), and whether the comparison holds under identical quantization and inference settings for the ANN baselines. Without this, the efficiency claim risks being sensitive to modeling choices.
Authors: We will fully specify the energy model in the revised Section 4.3. This includes: the spike-counting method (average spikes per neuron per inference, aggregated over all layers and time steps); hardware assumptions drawn from standard neuromorphic literature (e.g., 0.1 pJ per synaptic operation and 1 pJ per neuron update); and explicit confirmation that ANN baselines are evaluated under matching quantization levels and inference settings. These details will ensure the >93% energy reduction is presented transparently and is not sensitive to modeling choices. revision: yes
Circularity Check
No significant circularity; claims rest on empirical benchmark results
full rationale
The paper proposes SpikingCSINet with a progressive residual architecture to address the binary-spike information bottleneck in CSI feedback and validates it through experiments on the public COST 2100 benchmark. Performance and energy-efficiency claims are presented as direct outcomes of these comparisons against convolutional and Transformer baselines, without any closed-form derivation, fitted-parameter prediction, or self-citation chain that reduces the central result to its own inputs by construction. The architecture is introduced explicitly to compensate for spike limitations, and its effectiveness is asserted via reported metrics rather than tautological redefinition.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of time steps
- spike threshold
axioms (1)
- domain assumption Surrogate gradient or similar approximation allows effective training of spiking networks despite non-differentiable spikes.
Reference graph
Works this paper leans on
-
[1]
Massive MIMO for next generation wireless systems,
E. G. Larsson, O. Edfors, F. Tufvesson, and T. L. Marzetta, “Massive MIMO for next generation wireless systems,”IEEE Commun. Mag., vol. 52, no. 2, pp. 186–195, Feb. 2014
work page 2014
-
[2]
Distributed compressive CSIT estimation and feedback for FDD multi-user massive MIMO systems,
X. Rao and V . K. N. Lau, “Distributed compressive CSIT estimation and feedback for FDD multi-user massive MIMO systems,”IEEE Trans. Signal Process., vol. 62, no. 12, pp. 3261–3271, Jun. 2014
work page 2014
-
[3]
Deep learning for CSI feedback: One-sided model and joint multi-module learning perspectives,
Y . Guo, W. Chen, F. Sun, J. Cheng, M. Matthaiou, and B. Ai, “Deep learning for CSI feedback: One-sided model and joint multi-module learning perspectives,”IEEE Commun. Mag., vol. 63, no. 7, pp. 90–97, Jul. 2025
work page 2025
-
[4]
Deep learning for massive MIMO CSI feedback,
C.-K. Wen, W.-T. Shih, and S. Jin, “Deep learning for massive MIMO CSI feedback,”IEEE Wireless Commun. Lett., vol. 7, no. 5, pp. 748–751, Oct. 2018
work page 2018
-
[5]
J. Guo, C.-K. Wen, S. Jin, and G. Y . Li, “Convolutional neural network- based multiple-rate compressive sensing for massive MIMO CSI feed- back: Design, simulation, and analysis,”IEEE Trans. Wireless Commun., vol. 19, no. 4, pp. 2827–2840, Apr. 2020
work page 2020
-
[6]
Multi-resolution CSI feedback with deep learning in massive MIMO system,
Z. Lu, J. Wang, and J. Song, “Multi-resolution CSI feedback with deep learning in massive MIMO system,” inProc. IEEE Int. Conf. Commun. (ICC), Jun. 2020, pp. 1–6
work page 2020
-
[7]
CLNet: Complex input lightweight neural network designed for massive MIMO CSI feedback,
S. Ji and M. Li, “CLNet: Complex input lightweight neural network designed for massive MIMO CSI feedback,”IEEE Wireless Commun. Lett., vol. 10, no. 10, pp. 2318–2322, Oct. 2021
work page 2021
-
[8]
TransNet: Full attention network for CSI feedback in FDD massive MIMO system,
Y . Cui, A. Guo, and C. Song, “TransNet: Full attention network for CSI feedback in FDD massive MIMO system,”IEEE Wireless Commun. Lett., vol. 11, no. 5, pp. 903–907, May 2022
work page 2022
-
[9]
Towards spike-based machine intel- ligence with neuromorphic computing,
K. Roy, A. Jaiswal, and P. Panda, “Towards spike-based machine intel- ligence with neuromorphic computing,”Nature, vol. 575, no. 7784, pp. 607–617, Nov. 2019
work page 2019
-
[10]
SpikingIR: A novel converted spiking neural network for efficient image restoration,
Y . Ouyang, Z. Cheng, X. Luo, G. Li, and Y . Qu, “SpikingIR: A novel converted spiking neural network for efficient image restoration,”Proc. AAAI Conf. Artif. Intell., vol. 40, no. 10, pp. 8215–8223, 2026
work page 2026
-
[11]
E. O. Neftci, H. Mostafa, and F. Zenke, “Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimiza- tion to spiking neural networks,”IEEE Signal Process. Mag., vol. 36, no. 6, pp. 51–63, Nov. 2019
work page 2019
-
[12]
A survey of encoding techniques for signal processing in spiking neural networks,
D. Auge, J. Hille, E. Mueller, and A. Knoll, “A survey of encoding techniques for signal processing in spiking neural networks,”Neural Process. Lett., vol. 53, pp. 4693–4710, Jul. 2021
work page 2021
-
[13]
Delay learning based on temporal coding in spiking neural networks,
P. Sun, J. Wu, M. Zhang, P. Devos, and D. Botteldooren, “Delay learning based on temporal coding in spiking neural networks,”Neural Netw., vol. 180, Art. no. 106678, Dec. 2024
work page 2024
-
[14]
Direct training for spiking neural networks: Faster, larger, better,
Y . Wu, L. Deng, G. Li, J. Zhu, Y . Xie, and L. Shi, “Direct training for spiking neural networks: Faster, larger, better,” inProc. AAAI Conf. Artif. Intell., vol. 33, no. 1, 2019, pp. 1311–1318
work page 2019
-
[15]
The COST 2100 MIMO channel model,
L. Liu et al., “The COST 2100 MIMO channel model,”IEEE Wireless Commun., vol. 19, no. 6, pp. 92–99, Dec. 2012
work page 2012
-
[16]
Rethinking the performance comparison between SNNs and ANNs,
L. Deng et al., “Rethinking the performance comparison between SNNs and ANNs,”Neural Netw., vol. 121, pp. 294–307, Jan. 2020
work page 2020
-
[17]
1.1 Computing’s energy problem (and what we can do about it),
M. Horowitz, “1.1 Computing’s energy problem (and what we can do about it),” inIEEE Int. Solid-State Circuits Conf. Dig. Tech. Papers (ISSCC), Feb. 2014, pp. 10–14
work page 2014
-
[18]
Distributed deep convo- lutional compression for massive MIMO CSI feedback,
M. B. Mashhadi, Q. Yang, and D. G ¨und¨uz, “Distributed deep convo- lutional compression for massive MIMO CSI feedback,”IEEE Trans. Wireless Commun., vol. 20, no. 4, pp. 2621–2633, Apr. 2021
work page 2021
-
[19]
Spatio-temporal representation with deep neural recurrent network in MIMO CSI feedback,
X. Li and H. Wu, “Spatio-temporal representation with deep neural recurrent network in MIMO CSI feedback,”IEEE Wireless Commun. Lett., vol. 9, no. 5, pp. 653–657, May 2020
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.