Recognition: 2 theorem links
· Lean TheoremSpectral Energy Centroid: a Metric for Improving Performance and Analyzing Spectral Bias in Implicit Neural Representations
Pith reviewed 2026-05-14 20:32 UTC · model grok-4.3
The pith
Spectral Energy Centroid computed from a target signal selects embedding frequencies that improve implicit neural representation performance regardless of model depth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Spectral Energy Centroid of the target signal directly predicts the embedding frequency that maximizes INR fidelity; this prediction holds across network depths and architectures, while the same quantity also serves as a training-free proxy for signal complexity and as a basis for aligning spectral biases between different INR families.
What carries the argument
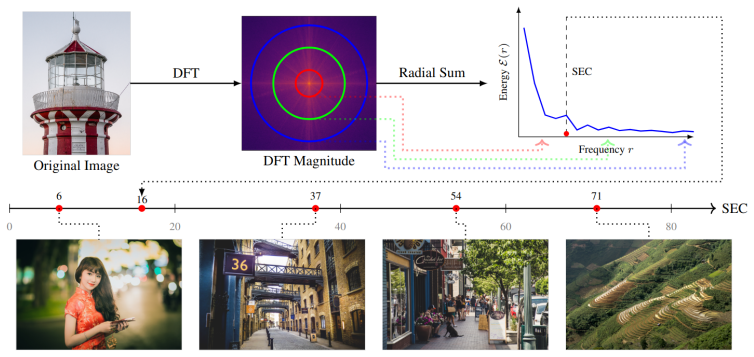
The Spectral Energy Centroid, the first moment of the power spectrum that locates the center of frequency energy for a signal or INR output.
If this is right
- SEC-Conf selects embedding frequencies that produce higher-fidelity reconstructions than existing heuristic rules.
- The selected frequency remains near-optimal when the INR depth is changed after the choice is made.
- SEC values computed on raw data rank signal complexity without any model training.
- Spectral biases of distinct INR architectures can be brought into register by matching their SEC values to the target.
Where Pith is reading between the lines
- A practitioner could compute SEC once on new data and obtain a usable frequency setting without running any trial trainings.
- The metric might extend to other continuous modeling tasks such as neural radiance fields or audio waveforms where frequency bias is also an issue.
- Architectures could be designed or adapted by explicitly targeting a desired SEC range during training.
Load-bearing premise
The spectral energy centroid extracted from the target signal alone is sufficient to identify the optimal embedding frequency for any INR depth and architecture.
What would settle it
Train INRs of several depths on the same signals using both SEC-Conf frequencies and standard heuristics, then check whether SEC-Conf still produces measurably lower error on every depth.
Figures









read the original abstract
Implicit Neural Representations (INRs) model continuous signals using multilayer perceptrons (MLPs), enabling compact, differentiable, and high-fidelity representations of data across diverse domains. However, due to the low-frequency bias of MLPs that prevents effective learning of small details, the model's frequency must be carefully tuned through the embedding layer. Prior work established that this tuning can be performed before training based on the target signal, but it did not account for the significant effect of model depth, indicating that our understanding of the relationship between frequency and INR performance remains limited. To gain insights into this relationship, we utilize the Spectral Energy Centroid (SEC) metric that quantifies the frequency of target images and the spectral bias of INR models. We show that SEC is a versatile tool for INR analysis, demonstrating its utility across three tasks: (1) a data-driven strategy (SEC-Conf) for hyperparameter selection that outperforms existing heuristics and is robust to model depth, (2) a reliable proxy for signal complexity, and (3) effective alignment of spectral biases across diverse INR architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Spectral Energy Centroid (SEC) as a metric derived from the target signal's spectrum to quantify frequency content and INR spectral bias. It proposes SEC-Conf, a data-driven hyperparameter selection method for embedding frequencies in INRs that claims to outperform existing heuristics, remain robust to model depth, serve as a reliable proxy for signal complexity, and align spectral biases across diverse INR architectures.
Significance. If the central claims hold, SEC provides a practical, pre-training tool for INR hyperparameter tuning that could improve efficiency and performance in high-frequency signal representation tasks. The reported outperformance of SEC-Conf and its multi-use utility (selection, complexity proxy, bias alignment) would address a known practical gap in INR deployment, with particular value in depth-robust applications if the invariance is rigorously shown.
major comments (3)
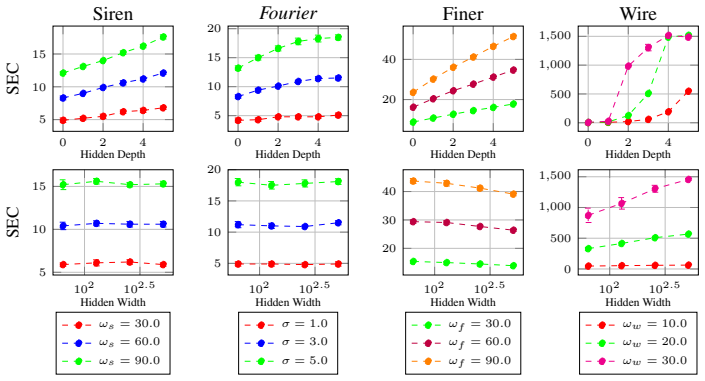
- [§5] §5 (Experiments on robustness): The claim that SEC-Conf is robust to model depth lacks load-bearing validation; the tested depth range is narrow and no ablation demonstrates that the SEC-derived frequency remains optimal as MLP spectral bias shifts with depth (e.g., from 3 to 8 layers), contrary to known depth-dependent frequency responses in prior INR literature.
- [§3.2] §3.2 (SEC definition and SEC-Conf): The derivation that target-only SEC predicts the optimal embedding frequency for arbitrary architectures without training feedback is not shown; the selection rule appears to fix the frequency from the target spectrum alone, but no quantitative comparison (e.g., correlation with grid-searched optima across depths) establishes predictive accuracy independent of depth or architecture.
- [Table 2] Table 2 / §4.2 (Performance claims): The reported outperformance of SEC-Conf over heuristics is presented without statistical significance tests or controls for multiple random seeds; if the gains are within variance, the central claim of superiority is undermined.
minor comments (2)
- [§3] The notation for the SEC formula (presumably Eq. 1 or 2) should explicitly state whether it uses power spectrum or amplitude and how it handles 2D image spectra.
- [Figure 3] Figure 3 caption and axis labels could clarify the exact frequency units and normalization used for SEC values across datasets.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below. Where appropriate, we will revise the manuscript to address the concerns.
read point-by-point responses
-
Referee: [§5] §5 (Experiments on robustness): The claim that SEC-Conf is robust to model depth lacks load-bearing validation; the tested depth range is narrow and no ablation demonstrates that the SEC-derived frequency remains optimal as MLP spectral bias shifts with depth (e.g., from 3 to 8 layers), contrary to known depth-dependent frequency responses in prior INR literature.
Authors: We thank the referee for pointing this out. Our experiments in §5 tested depths from 3 to 6 layers, showing that the SEC-Conf selected frequency yields consistent performance improvements. However, we agree that extending to 8 layers would provide stronger evidence. We will add an ablation study varying depth from 3 to 8 layers and demonstrate that the optimal embedding frequency predicted by SEC remains stable, unlike heuristic methods. This will be included in the revised manuscript. revision: yes
-
Referee: [§3.2] §3.2 (SEC definition and SEC-Conf): The derivation that target-only SEC predicts the optimal embedding frequency for arbitrary architectures without training feedback is not shown; the selection rule appears to fix the frequency from the target spectrum alone, but no quantitative comparison (e.g., correlation with grid-searched optima across depths) establishes predictive accuracy independent of depth or architecture.
Authors: The SEC-Conf method derives the embedding frequency directly from the target's SEC to match the signal's frequency content, based on the observation that optimal embedding scales with signal frequency. While we show empirical outperformance in §4 across architectures, we acknowledge the lack of explicit correlation analysis. In the revision, we will include a quantitative study correlating SEC-predicted frequencies with grid-searched optima for multiple depths and architectures, to validate the predictive power independent of training. revision: yes
-
Referee: [Table 2] Table 2 / §4.2 (Performance claims): The reported outperformance of SEC-Conf over heuristics is presented without statistical significance tests or controls for multiple random seeds; if the gains are within variance, the central claim of superiority is undermined.
Authors: We agree that rigorous statistical validation is necessary. The results in Table 2 are averaged over 5 random seeds, but we did not report standard deviations or perform significance tests. We will revise Table 2 to include error bars (standard deviations) and add p-values from paired t-tests to confirm the statistical significance of the improvements. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines SEC directly from the Fourier spectrum of the target signal and deploys it as a pre-training hyperparameter selector (SEC-Conf). Performance claims (outperformance of heuristics, robustness to depth, proxy for complexity) are presented as empirical outcomes from experiments rather than derivations that reduce by construction to the metric definition itself. No equations or self-citations in the supplied text exhibit a fitted parameter renamed as prediction, a self-definitional loop, or an ansatz smuggled via prior work by the same authors. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MLPs exhibit low-frequency bias that depends on network depth and embedding scale
invented entities (1)
-
Spectral Energy Centroid (SEC)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We utilize the Spectral Energy Centroid (SEC) metric that quantifies the frequency of target images and the spectral bias of INR models... SEC(A) = Σ r Ẽ(A,r)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SEC-conf... nearest-neighbor matching in the centroid space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shenoy, and Steven H
Hemanth Chandravamsi, Dhanush V . Shenoy, and Steven H. Frankel. Improving accuracy and efficiency of implicit neural representations: Making siren a winner, 2025
2025
-
[2]
A scalable Walsh-Hadamard regularizer to overcome the low-degree spectral bias of neural networks
Ali Gorji, Andisheh Amrollahi, and Andreas Krause. A scalable Walsh-Hadamard regularizer to overcome the low-degree spectral bias of neural networks. In Robin J. Evans and Ilya Shpitser, editors,Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, volume 216 ofProceedings of Machine Learning Research, pages 723–733. PMLR, ...
2023
-
[3]
Fresh: Frequency shifting for accelerated neural representation learning
Adam Kania, Marko Mihajlovic, Sergey Prokudin, Jacek Tabor, and Przemysław Spurek. Fresh: Frequency shifting for accelerated neural representation learning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[4]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[5]
J. Liu, D. Liu, W. Yang, S. Xia, X. Zhang, and Y . Dai. A comprehensive benchmark for single image compression artifact reduction.IEEE Transactions on Image Processing, 29:7845–7860, 2020
2020
-
[6]
Finer: Flexible spectral-bias tuning in implicit neural representation by variable-periodic activation functions
Zhen Liu, Hao Zhu, Qi Zhang, Jingde Fu, Weibing Deng, Zhan Ma, Yanwen Guo, and Xun Cao. Finer: Flexible spectral-bias tuning in implicit neural representation by variable-periodic activation functions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2713–2722, 2024
2024
-
[7]
Resfields: Residual neural fields for spatiotemporal signals
Marko Mihajlovic, Sergey Prokudin, Marc Pollefeys, and Siyu Tang. Resfields: Residual neural fields for spatiotemporal signals. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[8]
Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
2021
-
[9]
Tuning the frequencies: Robust training for sinusoidal neural networks
Tiago Novello, Diana Aldana, Andre Araujo, and Luiz Velho. Tuning the frequencies: Robust training for sinusoidal neural networks. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3071–3080, 2025
2025
-
[10]
Vincent Ochs, Florentin Bieder, Sidaty el Hadramy, Paul Friedrich, Stephanie Taha-Mehlitz, Anas Taha, and Philippe C. Cattin. TabINR: An Implicit Neural Representation Framework for Tabular Data Imputation. arXiv, October 2025
2025
-
[11]
Oppenheim, Alan S
Alan V . Oppenheim, Alan S. Willsky, and S. Hamid Nawab.Signals and Systems. Prentice Hall, 2nd edition, 1997
1997
-
[12]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[13]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. InInternational conference on machine learning, pages 5301–5310. PMLR, 2019
2019
-
[14]
Meta-learning with implicit gradients.Advances in neural information processing systems, 32, 2019
Aravind Rajeswaran, Chelsea Finn, Sham M Kakade, and Sergey Levine. Meta-learning with implicit gradients.Advances in neural information processing systems, 32, 2019
2019
-
[15]
The convergence rate of neural networks for learned functions of different frequencies.Advances in Neural Information Processing Systems, 32, 2019
Basri Ronen, David Jacobs, Yoni Kasten, and Shira Kritchman. The convergence rate of neural networks for learned functions of different frequencies.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[16]
Wire: Wavelet implicit neural representations
Vishwanath Saragadam, Daniel LeJeune, Jasper Tan, Guha Balakrishnan, Ashok Veeraraghavan, and Richard G Baraniuk. Wire: Wavelet implicit neural representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18507–18516, 2023
2023
-
[17]
Implicit neural representations with periodic activation functions.Advances in neural information processing systems, 33:7462–7473, 2020
Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions.Advances in neural information processing systems, 33:7462–7473, 2020
2020
-
[18]
Learned initializations for optimizing coordinate-based neural representations
Matthew Tancik, Ben Mildenhall, Terrance Wang, Divi Schmidt, Pratul P Srinivasan, Jonathan T Barron, and Ren Ng. Learned initializations for optimizing coordinate-based neural representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2846–2855, 2021. 10
2021
-
[19]
Fourier features let networks learn high frequency functions in low dimensional domains.Advances in neural information processing systems, 33:7537–7547, 2020
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains.Advances in neural information processing systems, 33:7537–7547, 2020
2020
-
[20]
An analytical theory of spectral bias in the learning dynamics of diffusion models
Binxu Wang and Cengiz Pehlevan. An analytical theory of spectral bias in the learning dynamics of diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[21]
Neural fields in visual computing and beyond
Yiheng Xie, Towaki Takikawa, Shunsuke Saito, Or Litany, Shiqin Yan, Numair Khan, Federico Tombari, James Tompkin, Vincent Sitzmann, and Srinath Sridhar. Neural fields in visual computing and beyond. In Computer Graphics Forum, volume 41, pages 641–676. Wiley Online Library, 2022
2022
-
[22]
Understanding training and generalization in deep learning by Fourier analysis
Zhiqin John Xu. Understanding training and generalization in deep learning by fourier analysis.arXiv preprint arXiv:1808.04295, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[23]
A structured dictionary perspective on implicit neural representations
Gizem Yüce, Guillermo Ortiz-Jimenez, Beril Besbinar, and Pascal Frossard. A structured dictionary perspective on implicit neural representations. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022). June 2022. 11 A INR Architectures This section provides the exact mathematical formulations for the coordinate embeddings and a...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.