Recognition: unknown
Constraint-Aware Flow Matching: Decision Aligned End-to-End Training for Constrained Sampling
Pith reviewed 2026-05-14 21:13 UTC · model grok-4.3
The pith
Constraint-Aware Flow Matching trains generative models by embedding constraint projections directly into the flow objective, closing the training-sampling mismatch that degrades quality in existing methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Constraint-Aware Flow Matching is a novel end-to-end framework that explicitly incorporates constraint projections into the training objective of flow matching models. By aligning the model's learned dynamics with the constrained sampling process, it mitigates distributional shift induced by projection-based corrections and enables high-quality constrained generation while maintaining strict feasibility guarantees.
What carries the argument
Constraint-Aware Flow Matching, the mechanism that folds constraint projections into the flow matching training objective so the learned vector field anticipates the corrections applied during sampling.
If this is right
- Models produce samples that satisfy constraints strictly without the quality loss seen in mismatched training-sampling pipelines.
- End-to-end training removes reliance on separate post-hoc correction steps at inference time.
- The approach generalizes across different constrained generation tasks as shown on three real-world benchmarks.
- Learned dynamics become consistent with the full sampling procedure that includes projections.
Where Pith is reading between the lines
- The same projection-folding idea could be tested in diffusion or score-based models to see if the alignment benefit transfers.
- In domains such as molecular design or engineering simulation, anticipating constraints during training may reduce the number of invalid samples that need rejection or repair.
- If gradients remain stable, the method might allow tighter integration of domain-specific simulators directly into the generative training loop.
Load-bearing premise
Folding constraint projections into the training objective will produce stable gradients and will not create new optimization difficulties or unintended biases in the learned distribution.
What would settle it
If samples generated by the trained model violate constraints after projection or exhibit lower quality metrics than those produced by standard training-free projection methods on the same benchmarks, the central claim would be falsified.
Figures



read the original abstract
Deep generative models provide state-of-the-art performance across a wide array of applications, with recent studies showing increasing applicability for science and engineering. Despite a growing corpus of literature focused on the integration of physics-based constraints into the generation process, existing approaches fail to enforce strict constraint satisfaction while maintaining sample quality. In particular, training-free constrained sampling methods, while providing per-sample feasibility guarantees, introduce a fundamental mismatch between the training objective and the constrained sampling procedure, often leading to performance degradation. Identifying this training-sampling misalignment as a central limitation of current constrained generative modeling approaches, this paper proposes Constraint-Aware Flow Matching, a novel end-to-end framework that explicitly incorporates constraint projections into the training objective. By aligning the model's learned dynamics with the constrained sampling process, the proposed method mitigates distributional shift induced by projection-based corrections, enabling high-quality constrained generation. The proposed approach is evaluated on three challenging real-world benchmarks, illustrating the generality and efficacy of the method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Constraint-Aware Flow Matching, a novel end-to-end training framework for flow-matching generative models that explicitly folds constraint projections into the training objective. By aligning the learned vector field with the projected sampling dynamics, the method aims to eliminate the distributional shift that arises when training-free projection corrections are applied at inference time, thereby enabling high-quality samples that strictly satisfy constraints. The approach is evaluated on three real-world benchmarks.
Significance. If the central claim holds, the work would provide a principled way to close the train-sampling gap that currently limits constrained generative modeling, potentially improving sample quality and feasibility rates in physics-informed and engineering applications without sacrificing the efficiency of flow-matching inference.
major comments (2)
- [§3.2] §3.2 (Loss formulation): the paper must derive the gradient of the composite loss that includes the projection operator P; without an explicit expression or proof that the composite remains differentiable almost everywhere, the claim that the learned dynamics match the constrained sampling process remains unsupported.
- [§4] §4 (Experiments): the reported improvements over training-free baselines are presented without ablation on the projection operator's smoothness or on gradient stability; if the optimization is unstable for any of the three benchmarks, the mitigation of distributional shift cannot be attributed to the proposed alignment.
minor comments (2)
- [§3] Notation for the projected vector field should be introduced once and used consistently; the current alternation between v_θ and v_θ^P is confusing.
- [Table 1] Table 1 caption should explicitly state whether the reported metrics are computed before or after the final projection step.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments have prompted us to strengthen the theoretical grounding and experimental validation of Constraint-Aware Flow Matching. We address each major comment point by point below and have revised the manuscript to incorporate the requested derivations and ablations.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Loss formulation): the paper must derive the gradient of the composite loss that includes the projection operator P; without an explicit expression or proof that the composite remains differentiable almost everywhere, the claim that the learned dynamics match the constrained sampling process remains unsupported.
Authors: We agree that an explicit gradient derivation is required to rigorously support the alignment claim. In the revised manuscript we have expanded Section 3.2 with a complete derivation of the composite loss gradient. Using the chain rule, the gradient with respect to the model parameters is expressed as the expectation of the inner product between the velocity error and the Jacobian of the projected vector field, where the Jacobian of P appears explicitly. We further include a short lemma establishing differentiability almost everywhere: because P is the Euclidean projection onto a closed convex set it is non-expansive and differentiable except on a set of Lebesgue measure zero (the boundary of the normal cone). This measure-zero exception is standard in the literature on projected dynamical systems and does not affect the validity of the training objective or the claimed equivalence between learned and constrained sampling dynamics. revision: yes
-
Referee: [§4] §4 (Experiments): the reported improvements over training-free baselines are presented without ablation on the projection operator's smoothness or on gradient stability; if the optimization is unstable for any of the three benchmarks, the mitigation of distributional shift cannot be attributed to the proposed alignment.
Authors: We acknowledge that the original experiments lacked explicit checks on projection smoothness and gradient stability. The revised Section 4 now contains two new ablation subsections. First, we compare hard projections against smoothed approximations (using a differentiable penalty with varying temperature) and report that the performance gains persist across smoothness levels, indicating robustness. Second, we plot gradient-norm histograms and maximum gradient values throughout training for all three benchmarks; the norms remain bounded and comparable to the unconstrained baseline, with no instances of instability. These results allow us to attribute the observed improvements in sample quality and strict constraint satisfaction to the alignment of training and sampling dynamics rather than to optimization artifacts. revision: yes
Circularity Check
No circularity detected; derivation is self-contained design choice
full rationale
The paper introduces Constraint-Aware Flow Matching as a new end-to-end training framework that folds constraint projections into the flow-matching objective to align learned dynamics with projected sampling. No equations, fitted parameters, or self-citations are shown in the abstract or description that reduce the central claim (mitigation of distributional shift) to an input by construction. The proposal is presented as a methodological response to an identified mismatch, with evaluation on external benchmarks providing independent content. No load-bearing self-definition, renaming of known results, or uniqueness theorems imported from prior author work appear. This is the expected honest non-finding for a methods paper whose core contribution is a new objective rather than a derived equality.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Constraint projections can be incorporated into the flow-matching training objective without destabilizing optimization.
Reference graph
Works this paper leans on
-
[1]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[2]
Tariq Berrada Ifriqi, John Nguyen, Karteek Alahari, Jakob Verbeek, and Ricky TQ Chen. Flowception: Temporally expansive flow matching for video generation.arXiv preprint arXiv:2512.11438, 2025
-
[3]
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling.arXiv preprint arXiv:2410.05954, 2024
-
[4]
Tsun-Hsuan Johnson Wang, Juntian Zheng, Pingchuan Ma, Yilun Du, Byungchul Kim, Andrew Spielberg, Josh Tenenbaum, Chuang Gan, and Daniela Rus. Diffusebot: Breeding soft robots with physics-augmented generative diffusion models.Advances in Neural Information Processing Systems, 36:44398–44423, 2023
work page 2023
-
[5]
Jingyi Cui, Jacob K Christopher, Ankita Biswas, Prasanna V Balachandran, and Ferdinando Fioretto. Con- strained diffusion for accelerated structure relaxation of inorganic solids with point defects.arXiv preprint arXiv:2602.19153, 2026
-
[6]
Physics-aware diffusion models for micro-structure material design
Jacob K Christopher, Stephen Baek, and Ferdinando Fioretto. Physics-aware diffusion models for micro-structure material design. InAI for Materials Science Workshop at NeurIPS 2024. AI For Material Science workshop, at NeurIPS-24, 2025. 9 Constraint-Aware Flow Matching
work page 2024
-
[7]
Dmflow: Disordered materials generation by flow matching.arXiv preprint arXiv:2602.04734, 2026
Liming Wu, Rui Jiao, Qi Li, Mingze Li, Songyou Li, Shifeng Jin, and Wenbing Huang. Dmflow: Disordered materials generation by flow matching.arXiv preprint arXiv:2602.04734, 2026
-
[8]
Jacob K Christopher, Austin Seamann, Jingyi Cui, Sagar Khare, and Ferdinando Fioretto. Constrained diffusion for protein design with hard structural constraints.arXiv preprint arXiv:2510.14989, 2025
-
[9]
Namrata Anand and Tudor Achim. Protein structure and sequence generation with equivariant denoising diffusion probabilistic models.arXiv preprint arXiv:2205.15019, 2022
-
[10]
Equivariant diffusion for molecule generation in 3d
Emiel Hoogeboom, Vıctor Garcia Satorras, Clément Vignac, and Max Welling. Equivariant diffusion for molecule generation in 3d. InInternational conference on machine learning, pages 8867–8887. PMLR, 2022
work page 2022
-
[11]
Motion planning diffusion: Learning and planning of robot motions with diffusion models
Joao Carvalho, An T Le, Mark Baierl, Dorothea Koert, and Jan Peters. Motion planning diffusion: Learning and planning of robot motions with diffusion models. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1916–1923. IEEE, 2023
work page 1916
-
[12]
Diffusion models beat gans on topology optimization
François Mazé and Faez Ahmed. Diffusion models beat gans on topology optimization. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 9108–9116, 2023
work page 2023
-
[13]
Nicolò Botteghi, Federico Califano, Mannes Poel, and Christoph Brune. Trajectory generation, control, and safety with denoising diffusion probabilistic models.arXiv preprint arXiv:2306.15512, 2023
-
[14]
Latent Generative Modeling of Random Fields from Limited Training Data
James E. Warner, Tristan A. Shah, Patrick E. Leser, Geoffrey F. Bomarito, Joshua D. Pribe, and Michael C. Stanley. Latent generative modeling of random fields from limited training data, 2026. URL https://arxiv.org/abs/ 2505.13007
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Physics-informed diffusion models.arXiv preprint arXiv:2403.14404, 2024
Jan-Hendrik Bastek, WaiChing Sun, and Dennis M Kochmann. Physics-informed diffusion models.arXiv preprint arXiv:2403.14404, 2024
-
[16]
Constrained synthesis with projected diffusion models
Jacob K Christopher, Stephen Baek, and Nando Fioretto. Constrained synthesis with projected diffusion models. Advances in Neural Information Processing Systems, 37:89307–89333, 2024
work page 2024
-
[17]
Jinhao Liang, Jacob K Christopher, Sven Koenig, and Ferdinando Fioretto. Simultaneous multi-robot motion planning with projected diffusion models.arXiv preprint arXiv:2502.03607, 2025
-
[18]
Utkarsh Utkarsh, Pengfei Cai, Alan Edelman, Rafael Gomez-Bombarelli, and Christopher Vincent Rack- auckas. Physics-constrained flow matching: Sampling generative models with hard constraints.arXiv preprint arXiv:2506.04171, 2025
-
[19]
Stefano Zampini, Jacob K Christopher, Luca Oneto, Davide Anguita, and Ferdinando Fioretto. Training-free constrained generation with stable diffusion models.arXiv preprint arXiv:2502.05625, 2025
-
[20]
Gradient-free generation for hard-constrained systems.arXiv preprint arXiv:2412.01786, 2024
Chaoran Cheng, Boran Han, Danielle C Maddix, Abdul Fatir Ansari, Andrew Stuart, Michael W Mahoney, and Yuyang Wang. Gradient-free generation for hard-constrained systems.arXiv preprint arXiv:2412.01786, 2024
-
[21]
Melding the data-decisions pipeline: Decision-focused learning for combinatorial optimization
Bryan Wilder, Bistra Dilkina, and Milind Tambe. Melding the data-decisions pipeline: Decision-focused learning for combinatorial optimization. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 1658–1665, 2019
work page 2019
-
[22]
Satnet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver
Po-Wei Wang, Priya Donti, Bryan Wilder, and Zico Kolter. Satnet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver. InInternational Conference on Machine Learning, pages 6545–6554. PMLR, 2019
work page 2019
-
[23]
Ferber, Bryan Wilder, Bistra Dilkina, and Milind Tambe
Aaron M. Ferber, Bryan Wilder, Bistra Dilkina, and Milind Tambe. Mipaal: Mixed integer program as a layer. InThe Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2...
work page 2020
-
[24]
Adam N Elmachtoub and Paul Grigas. Smart “predict, then optimize”.Management Science, 68(1):9–26, 2022
work page 2022
-
[25]
Akshay Agrawal, Brandon Amos, Shane Barratt, Stephen Boyd, Steven Diamond, and J Zico Kolter. Differentiable convex optimization layers.Advances in neural information processing systems, 32, 2019
work page 2019
-
[26]
Learning with differentiable perturbed optimizers
Quentin Berthet, Mathieu Blondel, Olivier Teboul, Marco Cuturi, Jean-Philippe Vert, and Francis Bach. Learning with differentiable perturbed optimizers. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 9508–9519, 2020
work page 2020
-
[27]
Learning with fenchel-young losses.J
Mathieu Blondel, André FT Martins, and Vlad Niculae. Learning with fenchel-young losses.J. Mach. Learn. Res., 21(35):1–69, 2020. 10 Constraint-Aware Flow Matching
work page 2020
-
[28]
Ferber, Taoan Huang, Daochen Zha, Martin Schubert, Benoit Steiner, Bistra Dilkina, and Yuandong Tian
Aaron M. Ferber, Taoan Huang, Daochen Zha, Martin Schubert, Benoit Steiner, Bistra Dilkina, and Yuandong Tian. Surco: Learning linear surrogates for combinatorial nonlinear optimization problems. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,International Conference on Machine Learning, ...
work page 2023
-
[29]
Fast differentiable sorting and ranking
Mathieu Blondel, Olivier Teboul, Quentin Berthet, and Josip Djolonga. Fast differentiable sorting and ranking. In International Conference on Machine Learning, pages 950–959. PMLR, 2020
work page 2020
-
[30]
Jayanta Mandi, James Kotary, Senne Berden, Maxime Mulamba, Victor Bucarey, Tias Guns, and Ferdinando Fioretto. Decision-focused learning: Foundations, state of the art, benchmark and future opportunities.Journal of Artificial Intelligence Research, 81:1623–1701, 2024. doi: 10.48550/arXiv.2307.13565
-
[31]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[32]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019
work page 2019
-
[34]
Maziar Raissi and George Em Karniadakis. Hidden physics models: Machine learning of nonlinear partial differential equations.Journal of Computational Physics, 357:125–141, 2018
work page 2018
-
[35]
Flow matching in latent space.arXiv preprint arXiv:2307.08698,
Quan Dao, Hao Phung, Binh Nguyen, and Anh Tran. Flow matching in latent space.arXiv preprint arXiv:2307.08698, 2023
-
[36]
Jinhao Liang, Yixuan Sun, Anirban Samaddar, Sandeep Madireddy, and Ferdinando Fioretto. Chance-constrained flow matching for high-fidelity constraint-aware generation.arXiv preprint arXiv:2509.25157, 2025
-
[37]
Stephen Gould, Basura Fernando, Anoop Cherian, Peter Anderson, Rodrigo Santa Cruz, and Edison Guo. On differentiating parameterized argmin and argmax problems with application to bi-level optimization.arXiv preprint arXiv:1607.05447, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[38]
Optnet: Differentiable optimization as a layer in neural networks
Brandon Amos and J Zico Kolter. Optnet: Differentiable optimization as a layer in neural networks. In International conference on machine learning, pages 136–145. PMLR, 2017
work page 2017
-
[39]
James Kotary, Jacob Christopher, My H Dinh, and Ferdinando Fioretto. Analyzing and enhancing the backward- pass convergence of unrolled optimization.arXiv preprint arXiv:2312.17394, 2023
-
[40]
Jayanta Mandi and Tias Guns. Interior point solving for lp-based prediction+ optimisation.Advances in Neural Information Processing Systems, 33:7272–7282, 2020
work page 2020
-
[41]
Mipaal: Mixed integer program as a layer
Aaron Ferber, Bryan Wilder, Bistra Dilkina, and Milind Tambe. Mipaal: Mixed integer program as a layer. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 1504–1511, 2020
work page 2020
-
[42]
Differentiation of blackbox combinatorial solvers
Marin Vlastelica Poganˇci´c, Anselm Paulus, Vit Musil, Georg Martius, and Michal Rolinek. Differentiation of blackbox combinatorial solvers. InInternational conference on learning representations, 2019
work page 2019
-
[43]
Subham Sekhar Sahoo, Anselm Paulus, Marin Vlastelica, Vít Musil, V olodymyr Kuleshov, and Georg Mar- tius. Backpropagation through combinatorial algorithms: Identity with projection works.arXiv preprint arXiv:2205.15213, 2022
-
[44]
Mathias Niepert, Pasquale Minervini, and Luca Franceschi. Implicit mle: backpropagating through discrete exponential family distributions.Advances in Neural Information Processing Systems, 34:14567–14579, 2021
work page 2021
-
[45]
Mathieu Blondel, Quentin Berthet, Marco Cuturi, Roy Frostig, Stephan Hoyer, Felipe Llinares-López, Fabian Pedregosa, and Jean-Philippe Vert. Efficient and modular implicit differentiation.Advances in Neural Information Processing Systems, 35:5230–5242, 2022
work page 2022
-
[46]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[47]
Matthieu Blanke, Yongquan Qu, Sara Shamekh, and Pierre Gentine. Strictly constrained generative modeling via split augmented langevin sampling.arXiv preprint arXiv:2505.18017, 2025
-
[48]
Jayanta Mandi, James Kotary, Senne Berden, Maxime Mulamba, Victor Bucarey, Tias Guns, and Ferdinando Fioretto. Decision-focused learning: Foundations, state of the art, benchmark and future opportunities.Journal of Artificial Intelligence Research, 80:1623–1701, 2024
work page 2024
-
[49]
Wuhua Hu, Ping Wang, and Hoay Beng Gooi. Toward optimal energy management of microgrids via robust two-stage optimization.IEEE Transactions on smart grid, 9(2):1161–1174, 2016. 11 Constraint-Aware Flow Matching
work page 2016
-
[50]
An investigation into prediction+ optimisation for the knapsack problem
Emir Demirovi ´c, Peter J Stuckey, James Bailey, Jeffrey Chan, Chris Leckie, Kotagiri Ramamohanarao, and Tias Guns. An investigation into prediction+ optimisation for the knapsack problem. InInternational Conference on Integration of Constraint Programming, Artificial Intelligence, and Operations Research, pages 241–257. Springer, 2019
work page 2019
-
[51]
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
work page 2019
-
[52]
Functional flow matching.arXiv preprint arXiv:2305.17209, 2023
Gavin Kerrigan, Giosue Migliorini, and Padhraic Smyth. Functional flow matching.arXiv preprint arXiv:2305.17209, 2023
-
[53]
Tristan A. Shah, Michael C. Stanley, and James E. Warner. Generative modeling of microweather wind velocities for urban air mobility. In2025 IEEE Aerospace Conference, pages 1–17, 2025. doi: 10.1109/AERO63441.2025. 11068624
-
[54]
D S Nithya, Giuseppe Quaranta, Vincenzo Muscarello, and Man Liang. Review of wind flow modelling in urban environments to support the development of urban air mobility.Drones, 8(4), 2024. ISSN 2504-446X. doi: 10.3390/drones8040147. URLhttps://www.mdpi.com/2504-446X/8/4/147
-
[55]
Monte carlo simulation of wind velocity fields on complex structures
Luigi Carassale and Giovanni Solari. Monte carlo simulation of wind velocity fields on complex structures. Journal of Wind Engineering and Industrial Aerodynamics, 94(5):323–339, 2006
work page 2006
-
[56]
Sehyun Chun, Sidhartha Roy, Yen Thi Nguyen, Joseph B Choi, Holavanahalli S Udaykumar, and Stephen S Baek. Deep learning for synthetic microstructure generation in a materials-by-design framework for heterogeneous energetic materials.Scientific reports, 10(1):13307, 2020
work page 2020
-
[57]
R. Li, I. Shikhov, and C. Arns. Bentheimer sandstone image data, March 2022. URL https://doi.org/10. 17612/1J6K-SH07. Dataset
work page 2022
-
[58]
Egon Peršak and Miguel F Anjos. Decision-focused forecasting: A differentiable multistage optimisation architecture.arXiv preprint arXiv:2405.14719, 2024
-
[59]
arXiv preprint arXiv:1910.03193 (2019)
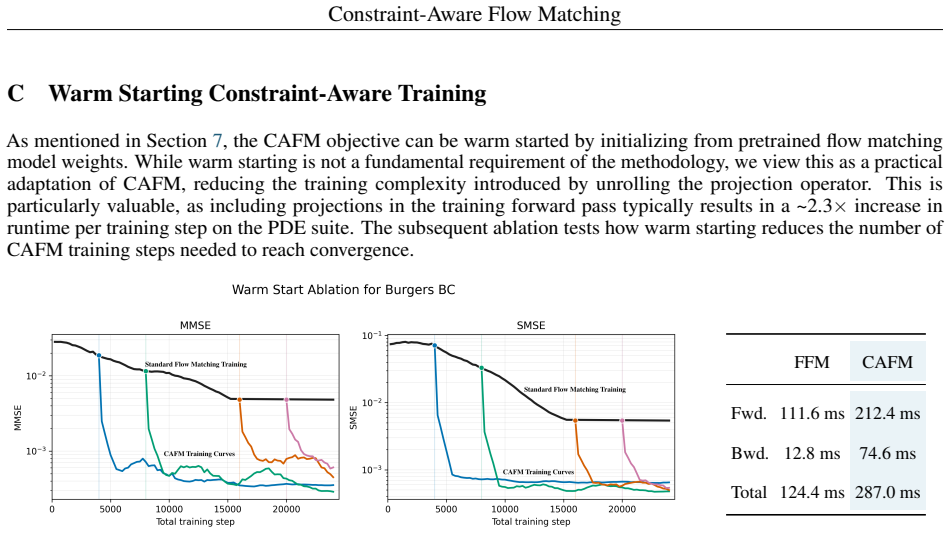
Lu Lu, Pengzhan Jin, and George Em Karniadakis. Deeponet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators.arXiv preprint arXiv:1910.03193, 2019. 12 Constraint-Aware Flow Matching A Experimental Setups and Reproducibility This section is dedicated to documenting the specific eval...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.