Recognition: unknown
SoK: A Comprehensive Analysis of the Current Status of Neural Tangent Generalization Attacks with Research Directions
Pith reviewed 2026-05-14 20:38 UTC · model grok-4.3
The pith
NTGA, the first black-box clean-label generalization attack, is vulnerable to adversarial training and image transformations while newer attacks perform better.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NTGA serves as the first well-known clean-label generalization attack in black-box settings for data protection, yet experiments demonstrate its vulnerability to adversarial training and image transformations, with linear separability on generated images increasing susceptibility, and multiple recent clean-label attacks outperforming it on data protection tasks.
What carries the argument
The Neural Tangent Generalization Attack (NTGA), which generates poisoned training data to impair model generalization in black-box scenarios without label modification.
If this is right
- Adversarial training serves as an effective countermeasure that reduces NTGA's impact on model generalization.
- Common image transformations can neutralize much of NTGA's poisoning effect on target data.
- Applying linear separability to NTGA images increases their vulnerability to defenses.
- Several newer clean-label generalization attacks achieve better data protection results than NTGA.
- NTGA robustness can be strengthened by addressing the identified weaknesses in future designs.
Where Pith is reading between the lines
- Privacy-focused poisoning techniques may need to incorporate built-in resistance to common defenses like adversarial training to remain viable.
- Standard evaluation protocols for clean-label attacks could enable more consistent comparisons across methods.
- Hybrid approaches that combine elements of NTGA with later techniques might produce stronger data-protection tools.
Load-bearing premise
The authors' experiments capture representative vulnerabilities and performance gaps across typical models, datasets, and threat models.
What would settle it
A new set of experiments showing NTGA-generated data remains highly effective against adversarial training and standard image transformations on diverse models and datasets would disprove the claimed vulnerabilities.
Figures




read the original abstract
There is recently a serious issue that Deep Neural Networks (DNNs) training uses more and more unauthorized data. A clean-label generalization attack, one type of data poisoning attacks, has been suggested to address this issue. The Neural Tangent Generalization Attack (NTGA) is considered as the first well-known clean-label generalization attack under the black-box settings, which provided an unprecedented step in data protection approaches. In this paper, we conduct a comprehensive analysis on the state-of-the-art of NTGA; to the best of our knowledge, this is the first thorough analysis regarding NTGA. First, we provide a classification of attacks against DNNs with their explanations and relations to NTGA. Then, this paper presents a taxonomy of black-box attacks and demonstrate that the NTGA is the first clean-label generalization attack under the black-box setting. We further analyze the existing studies of NTGA and give a comprehensive comparisons of their findings by conducting our own experiments to verify these findings. Moreover, our extensive experiments show that NTGA is vulnerable to adversarial training and image transformations, and applying linear separability to NTGA-generated images makes them more susceptible to such vulnerablities. We present the pros and cons of NTGA and suggest ways to improve NTGA robustness based on our analysis. Our further experiments indicate that several recently proposed clean-label generalization attacks outperform NTGA on data protection. Finally, we unveil the necessity of further research with future research insights on NTGA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a Systematization of Knowledge (SoK) on Neural Tangent Generalization Attacks (NTGA), positioning NTGA as the first well-known clean-label generalization attack under black-box settings. It classifies attacks against DNNs, presents a taxonomy of black-box attacks, analyzes prior NTGA studies via the authors' own verification experiments, demonstrates NTGA vulnerabilities to adversarial training and image transformations (with linear separability increasing susceptibility), discusses pros/cons and improvement suggestions, shows that several recent clean-label attacks outperform NTGA for data protection, and outlines future research directions.
Significance. If the experimental verification and comparisons hold, the work provides a valuable first comprehensive analysis of NTGA, empirically validating prior findings while identifying practical weaknesses and superior alternatives; this is significant for the data-poisoning and data-protection literature as it consolidates knowledge and highlights actionable research gaps in clean-label black-box attacks.
major comments (1)
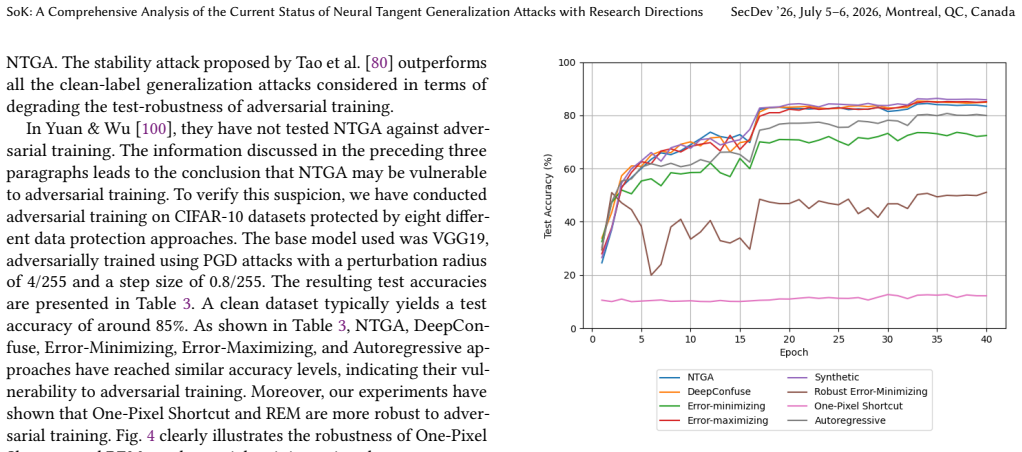
- [Abstract and Experiments] Abstract and Experiments section: The description of the authors' verification experiments provides no details on model architectures, datasets, hyperparameters, threat models, or evaluation protocols. This undermines the central claims that NTGA is vulnerable to adversarial training and image transformations, that linear separability increases susceptibility, and that recent attacks outperform NTGA, as these conclusions cannot be assessed for fairness, breadth, or reproducibility without the missing methodological information.
minor comments (2)
- [Abstract] Abstract: 'demonstrate that the NTGA' has a subject-verb agreement error and should read 'demonstrates that NTGA'.
- [Abstract] Abstract: Typo 'vulnerablities' should be corrected to 'vulnerabilities'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our SoK paper. We address the single major comment below and will incorporate the requested changes in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The description of the authors' verification experiments provides no details on model architectures, datasets, hyperparameters, threat models, or evaluation protocols. This undermines the central claims that NTGA is vulnerable to adversarial training and image transformations, that linear separability increases susceptibility, and that recent attacks outperform NTGA, as these conclusions cannot be assessed for fairness, breadth, or reproducibility without the missing methodological information.
Authors: We agree that the experimental details are essential for reproducibility and for allowing readers to assess the fairness of our verification results and comparisons. The current manuscript describes the high-level outcomes of our verification experiments but does not provide the specific methodological information requested. In the revised version we will add a dedicated 'Experimental Setup' subsection (and expand the abstract accordingly) that explicitly lists: model architectures (e.g., ResNet-18, VGG-16), datasets (CIFAR-10 and ImageNet subsets), training and attack hyperparameters, the precise black-box threat model, and the evaluation protocols (accuracy drop, robustness to adversarial training and transformations, linear-separability metric). These additions will directly support the claims regarding NTGA vulnerabilities and the relative performance of newer clean-label attacks without changing any conclusions. revision: yes
Circularity Check
No significant circularity: survey paper grounded in external citations and verification experiments
full rationale
This SoK paper performs a literature review, taxonomy construction, and verification experiments on prior NTGA work without any claimed derivations, fitted parameters, or predictions that reduce to the paper's own inputs. All central claims (vulnerabilities to adversarial training, outperformance by newer attacks, linear separability effects) are presented as empirical verifications of external findings or direct comparisons, with no self-definitional loops, fitted-input predictions, or load-bearing self-citation chains. The paper explicitly grounds its analysis in citations to original NTGA and related works rather than deriving results from its own definitions or ansatzes. No equations or uniqueness theorems are invoked in a manner that collapses the argument to self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
d.].Google Cloud AutoML
[n. d.].Google Cloud AutoML. https://cloud.google.com/automl
-
[2]
d.].Google Cloud Vision API
[n. d.].Google Cloud Vision API. https://cloud.google.com/vision
-
[3]
d.].Machine Learning on A WS
[n. d.].Machine Learning on A WS. https://aws.amazon.com/machine-learning/
-
[4]
d.].Use a Color Matrix to Transform a Single Color
[n. d.].Use a Color Matrix to Transform a Single Color. https: //learn.microsoft.com/en-us/dotnet/desktop/winforms/advanced/how-to-use- a-color-matrix-to-transform-a-single-color?view=netframeworkdesktop-4.8
-
[5]
Ibrahim M Ahmed and Manar Younis Kashmoola. 2021. Threats on Machine Learning Technique by Data Poisoning Attack: A Survey. InInternational Con- ference on Advances in Cyber Security. Springer, 586–600
2021
-
[6]
Arjun Nitin Bhagoji, Warren He, Bo Li, and Dawn Song. 2017. Exploring the Space of Black-box Attacks on Deep Neural Networks.CoRRabs/1712.09491 (2017). arXiv:1712.09491 http://arxiv.org/abs/1712.09491
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Battista Biggio, Blaine Nelson, and Pavel Laskov. 2012. Poisoning Attacks against Support Vector Machines. InProceedings of the 29th International Conference on Machine Learning (ICML). icml.cc / Omnipress. http://icml.cc/2012/papers/880. pdf
2012
-
[8]
Eitan Borgnia, Valeriia Cherepanova, Liam Fowl, Amin Ghiasi, Jonas Geiping, Micah Goldblum, Tom Goldstein, and Arjun Gupta. 2021. Strong Data Augmenta- tion Sanitizes Poisoning and Backdoor Attacks Without an Accuracy Tradeoff. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada. IEEE, 3855–3859. doi:1...
-
[9]
Qiong Cao, Li Shen, Weidi Xie, Omkar M. Parkhi, and Andrew Zisserman. 2018. VGGFace2: A Dataset for Recognising Faces across Pose and Age. In13th IEEE International Conference on Automatic Face & Gesture Recognition, Xi’an, China. IEEE Computer Society, 67–74. doi:10.1109/FG.2018.00020
-
[10]
Nicholas Carlini and David A. Wagner. 2017. Towards Evaluating the Robustness of Neural Networks. In2017 IEEE Symposium on Security and Privacy (SP). 39–57. doi:10.1109/SP.2017.49
-
[11]
Adrien Chan-Hon-Tong. 2019. An Algorithm for Generating Invisible Data Poi- soning Using Adversarial Noise That Breaks Image Classification Deep Learning. Mach. Learn. Knowl. Extr.1, 1 (2019), 192–204. doi:10.3390/make1010011
-
[12]
Sizhe Chen, Geng Yuan, Xinwen Cheng, Yifan Gong, Minghai Qin, Yanzhi Wang, and Xiaolin Huang. 2023. Self-Ensemble Protection: Training Checkpoints Are Good Data Protectors. InThe Eleventh International Conference on Learning Representations, ICLR, Kigali, Rwanda. OpenReview.net
2023
-
[13]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. A simple framework for contrastive learning of visual representations. InInter- national conference on machine learning. PmLR, 1597–1607
2020
-
[14]
Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song. 2017. Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning.CoRR abs/1712.05526 (2017). arXiv:1712.05526 http://arxiv.org/abs/1712.05526
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Xiaotian Chen, Yang Xu, Sicong Zhang, Jiale Yan, Weida Xu, and Xinlong He
- [16]
-
[17]
Sumit Chopra, Raia Hadsell, and Yann LeCun. 2005. Learning a Similarity Metric Discriminatively, with Application to Face Verification. In2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society, 539–546. doi:10.1109/CVPR.2005.202
-
[18]
Diya Chudasama, Tanvi Patel, Shubham Joshi, and Ghanshyam Prajapati. 2015. Image Segmentation using Morphological Operations.International Journal of Computer Applications117 (05 2015), 16–19. doi:10.5120/20654-3197
-
[19]
High-Performance Neural Networks for Visual Object Classification
Dan C. Ciresan, Ueli Meier, Jonathan Masci, Luca Maria Gambardella, and Jürgen Schmidhuber. 2011. High-Performance Neural Networks for Visual Object Classification.CoRRabs/1102.0183 (2011). arXiv:1102.0183 http://arxiv. org/abs/1102.0183
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[20]
Nilaksh Das, Madhuri Shanbhogue, Shang-Tse Chen, Fred Hohman, Siwei Li, Li Chen, Michael E. Kounavis, and Duen Horng Chau. 2018. SHIELD: Fast, Practical Defense and Vaccination for Deep Learning using JPEG Compression. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD), London, UK, Yike Guo and Faisal ...
-
[21]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. ImageNet: A large-scale hierarchical image database. InIEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society, 248–255. doi:10.1109/CVPR.2009.5206848
-
[22]
Terrance Devries and Graham W. Taylor. 2017. Improved Regularization of Convolutional Neural Networks with Cutout.CoRRabs/1708.04552 (2017). arXiv:1708.04552 http://arxiv.org/abs/1708.04552
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Hadi M. Dolatabadi, Sarah M. Erfani, and Christopher Leckie. 2023. The Devil’s Advocate: Shattering the Illusion of Unexploitable Data using Diffusion Models. CoRRabs/2303.08500 (2023). arXiv:2303.08500 doi:10.48550/arXiv.2303.08500
-
[24]
Xibin Dong, Zhiwen Yu, Wenming Cao, Yifan Shi, and Qianli Ma. 2020. A survey on ensemble learning.Frontiers Comput. Sci.14, 2 (2020), 241–258. doi:10.1007/s11704-019-8208-z
-
[25]
Jiaxin Fan, Qi Yan, Mohan Li, Guanqun Qu, and Yang Xiao. 2022. A Survey on Data Poisoning Attacks and Defenses. In7th IEEE International Conference on Data Science in Cyberspace, DSC 2022, Guilin, China, July 11-13, 2022. IEEE, 48–55. doi:10.1109/DSC55868.2022.00014
-
[26]
Bin Fang, Bo Li, Shuang Wu, Shouhong Ding, Ran Yi, and Lizhuang Ma. 2024. Re- thinking data availability attacks against deep neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12215– 12224
2024
-
[27]
Ji Feng, Qi-Zhi Cai, and Zhi-Hua Zhou. 2019. Learning to Con- fuse: Generating Training Time Adversarial Data with Auto-Encoder. InAnnual Conference on Neural Information Processing Systems, (NeurIPS). 11971–11981. https://proceedings.neurips.cc/paper/2019/hash/ 1ce83e5d4135b07c0b82afffbe2b3436-Abstract.html
2019
-
[28]
Liam Fowl, Micah Goldblum, Ping-yeh Chiang, Jonas Geiping, Wojciech Czaja, and Tom Goldstein. 2021. Adversarial Examples Make Strong Poisons. InAnnual Conference on Neural Information Processing Systems (NeurIPS). 30339–30351. https://proceedings.neurips.cc/paper/2021/hash/ fe87435d12ef7642af67d9bc82a8b3cd-Abstract.html
2021
-
[29]
Shaopeng Fu, Fengxiang He, Yang Liu, Li Shen, and Dacheng Tao. 2022. Robust Unlearnable Examples: Protecting Data Privacy Against Adversarial Learning. InThe Tenth International Conference on Learning Representations (ICLR). https: //openreview.net/forum?id=baUQQPwQiAg
2022
- [30]
-
[31]
Alex Galakatos, Andrew Crotty, and Tim Kraska. 2018. Distributed Machine Learning
2018
-
[32]
Estevão S Gedraite and Murielle Hadad. 2011. Investigation on the effect of a Gaussian Blur in image filtering and segmentation. InProceedings ELMAR. IEEE, 393–396
2011
-
[33]
Jonas Geiping, Liam H Fowl, Gowthami Somepalli, Micah Goldblum, Michael Moeller, and Tom Goldstein. 2022. What Doesn’t Kill You Makes You Robust(er): How to Adversarially Train against Data Poisoning. https://openreview.net/ forum?id=VMuenFh7IpP
2022
- [34]
-
[35]
Xueluan Gong, Yuji Wang, Yanjiao Chen, Haocheng Dong, Yiming Li, Mengyuan Sun, Shuaike Li, Qian Wang, and Chen Chen. 2025. ARMOR: Shielding Un- learnable Examples against Data Augmentation.CoRRabs/2501.08862 (2025). https://doi.org/10.48550/arXiv.2501.08862
-
[36]
2016.Deep Learning
Ian Goodfellow, Yoshua Bengio, and Aaron Courville. 2016.Deep Learning. MIT Press. http://www.deeplearningbook.org
2016
-
[37]
Explaining and Harnessing Adversarial Examples
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. 2015. Explaining and Harnessing Adversarial Examples. In3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, Yoshua Bengio and Yann LeCun (Eds.). http://arxiv.org/abs/1412.6572
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[38]
Thushari Hapuarachchi, Jing Lin, Kaiqi Xiong, Mohamed Rahouti, and Gitte Ost. 2024. Nonlinear Transformations Against Unlearnable Datasets.CoRR abs/2406.02883 (2024). https://doi.org/10.48550/arXiv.2406.02883
-
[39]
Thushari Hapuarachchi and Kaiqi Xiong. 2025. Advancing ensemble learning against unlearnable data.Neurocomputing(2025), 130422
2025
- [40]
-
[41]
Hanxun Huang, Xingjun Ma, Sarah Monazam Erfani, James Bailey, and Yisen Wang. 2021. Unlearnable Examples: Making Personal Data Unexploitable. In9th International Conference on Learning Representations (ICLR). OpenReview.net. https://openreview.net/forum?id=iAmZUo0DxC0
2021
-
[42]
Adversarial Attacks on Neural Network Policies
Sandy H. Huang, Nicolas Papernot, Ian J. Goodfellow, Yan Duan, and Pieter Abbeel. 2017. Adversarial Attacks on Neural Network Policies.CoRR abs/1702.02284 (2017). arXiv:1702.02284 http://arxiv.org/abs/1702.02284
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Ronny Huang, Jonas Geiping, Liam Fowl, Gavin Taylor, and Tom Goldstein
W. Ronny Huang, Jonas Geiping, Liam Fowl, Gavin Taylor, and Tom Goldstein. 2020. MetaPoison: Practical General-purpose Clean-label Data Poisoning. InAnnual Conference on Neural Information Process- ing Systems (NeurIPS). https://proceedings.neurips.cc/paper/2020/hash/ 8ce6fc704072e351679ac97d4a985574-Abstract.html
2020
- [44]
-
[45]
Arthur Jacot, Clément Hongler, and Franck Gabriel. 2018. Neu- ral Tangent Kernel: Convergence and Generalization in Neural Net- works. InAnnual Conference on Neural Information Processing Systems (NeurIPS). 8580–8589. https://proceedings.neurips.cc/paper/2018/hash/ 5a4be1fa34e62bb8a6ec6b91d2462f5a-Abstract.html
2018
-
[46]
Alex Krizhevsky, Geoffrey Hinton, et al . 2009. Learning multiple layers of features from tiny images. (2009)
2009
-
[47]
Goodfellow, and Samy Bengio
Alexey Kurakin, Ian J. Goodfellow, and Samy Bengio. 2017. Adversarial examples in the physical world. In5th International Conference on Learning Representations SecDev ’26, July 5–6, 2026, Montreal, QC, Canada Thushari Hapuarachchi and Kaiqi Xiong (ICLR). OpenReview.net. https://openreview.net/forum?id=HJGU3Rodl
2017
-
[48]
Deep Neural Networks as Gaussian Processes
Jaehoon Lee, Yasaman Bahri, Roman Novak, Samuel S. Schoenholz, Jeffrey Pennington, and Jascha Sohl-Dickstein. 2017. Deep Neural Networks as Gaussian Processes.CoRRabs/1711.00165 (2017). arXiv:1711.00165 http://arxiv.org/abs/ 1711.00165
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [49]
- [50]
-
[51]
Yi Li, Jing Lin, and Kaiqi Xiong. 2021. An Adversarial Attack Defending Sys- tem for Securing In-Vehicle Networks. In18th IEEE Annual Consumer Com- munications & Networking Conference (CCNC), Las Vegas, NV, USA. IEEE, 1–6. doi:10.1109/CCNC49032.2021.9369569
- [52]
-
[53]
Haiqing Liu, Daoxing Li, and Yuancheng Li. 2021. Poisonous Label Attack: Black-Box Data Poisoning Attack with Enhanced Conditional DCGAN.Neural Process. Lett.53, 6 (2021), 4117–4142. doi:10.1007/s11063-021-10584-w
-
[54]
Xinwei Liu, Xiaojun Jia, Yuan Xun, Siyuan Liang, and Xiaochun Cao. 2024. Multimodal Unlearnable Examples: Protecting Data against Multimodal Con- trastive Learning. In32nd ACM International Conference on Multimedia, MM 2024, Melbourne, VIC, Australia. ACM, 8024–8033. https://doi.org/10.1145/3664647. 3680708
-
[55]
Yanpei Liu, Xinyun Chen, Chang Liu, and Dawn Song. 2016. Delving into Transferable Adversarial Examples and Black-box Attacks.CoRRabs/1611.02770 (2016). arXiv:1611.02770 http://arxiv.org/abs/1611.02770
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[56]
Yixin Liu, Kaidi Xu, Xun Chen, and Lichao Sun. 2024. Stable Unlearn- able Example: Enhancing the Robustness of Unlearnable Examples via Sta- ble Error-Minimizing Noise. InThirty-Sixth Conference on Innovative Appli- cations of Artificial Intelligence, Vancouver, Canada. AAAI Press, 3783–3791. https://doi.org/10.1609/aaai.v38i4.28169
- [57]
-
[58]
Zhuoran Liu, Zhengyu Zhao, and Martha A. Larson. 2023. Image Shortcut Squeezing: Countering Perturbative Availability Poisons with Compression. CoRRabs/2301.13838 (2023). arXiv:2301.13838 doi:10.48550/arXiv.2301.13838
-
[59]
Teng Long, Qi Gao, Lili Xu, and Zhangbing Zhou. 2022. A survey on adversar- ial attacks in computer vision: Taxonomy, visualization and future directions. Comput. Secur.121 (2022), 102847. doi:10.1016/j.cose.2022.102847
-
[60]
Yuxin Ma, Tiankai Xie, Jundong Li, and Ross Maciejewski. 2020. Explaining Vulnerabilities to Adversarial Machine Learning through Visual Analytics.IEEE Trans. Vis. Comput. Graph.26, 1 (2020), 1075–1085. doi:10.1109/TVCG.2019. 2934631
-
[61]
Gabriel Resende Machado, Eugênio Silva, and Ronaldo Ribeiro Goldschmidt
-
[62]
arXiv:2009.03728 https://arxiv.org/abs/2009.03728
Adversarial Machine Learning in Image Classification: A Survey Towards the Defender’s Perspective.CoRRabs/2009.03728 (2020). arXiv:2009.03728 https://arxiv.org/abs/2009.03728
-
[63]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2017. Towards Deep Learning Models Resistant to Adversarial Attacks.CoRRabs/1706.06083 (2017). arXiv:1706.06083 http://arxiv.org/abs/ 1706.06083
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[64]
Mark Huasong Meng, Guangdong Bai, Sin Gee Teo, Zhe Hou, Yan Xiao, Yun Lin, and Jin Song Dong. 2022. Adversarial Robustness of Deep Neural Networks: A Survey from a Formal Verification Perspective.CoRRabs/2206.12227 (2022). arXiv:2206.12227 doi:10.48550/arXiv.2206.12227
-
[65]
Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, and Pascal Frossard. 2016. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA. IEEE Computer Society, 2574–2582. doi:10.1109/CVPR.2016.282
-
[66]
Transferability in Machine Learning: from Phenomena to Black-Box Attacks using Adversarial Samples
Nicolas Papernot, Patrick D. McDaniel, and Ian J. Goodfellow. 2016. Trans- ferability in Machine Learning: from Phenomena to Black-Box Attacks us- ing Adversarial Samples.CoRRabs/1605.07277 (2016). arXiv:1605.07277 http://arxiv.org/abs/1605.07277
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[67]
Nicolas Papernot, Patrick D. McDaniel, Ian J. Goodfellow, Somesh Jha, Z. Berkay Celik, and Ananthram Swami. 2017. Practical Black-Box Attacks against Ma- chine Learning. InProceedings of the Asia Conference on Computer and Commu- nications Security (AsiaCCS). 506–519. doi:10.1145/3052973.3053009
-
[68]
Poznyak, Isaac Chairez, and Tatyana Poznyak
Alexander S. Poznyak, Isaac Chairez, and Tatyana Poznyak. 2019. A survey on artificial neural networks application for identification and control in environ- mental engineering: Biological and chemical systems with uncertain models. Annu. Rev. Control.48 (2019), 250–272. doi:10.1016/j.arcontrol.2019.07.003
-
[69]
Tianrui Qin, Xitong Gao, Juanjuan Zhao, Kejiang Ye, and Cheng-Zhong Xu
- [70]
- [71]
-
[72]
Vinu Sankar Sadasivan, Mahdi Soltanolkotabi, and Soheil Feizi. 2023. CUDA: Convolution-based Unlearnable Datasets.CoRRabs/2303.04278 (2023). arXiv:2303.04278 doi:10.48550/arXiv.2303.04278
-
[73]
Vinu Sankar Sadasivan, Mahdi Soltanolkotabi, and Soheil Feizi. 2023. FUN: Filter- based Unlearnable Datasets. https://openreview.net/forum?id=iaCzfh6vtwQ
2023
-
[74]
Omer Sagi and Lior Rokach. 2018. Ensemble learning: A survey.WIREs Data Mining Knowl. Discov.8, 4 (2018). doi:10.1002/widm.1249
-
[75]
Pedro Sandoval Segura, Vasu Singla, Jonas Geiping, Micah Goldblum, and Tom Goldstein. 2023. What Can We Learn from Unlearnable Datasets?. InNeural Information Processing Systems, NeurIPS, New Or- leans, LA, USA. http://papers.nips.cc/paper_files/paper/2023/hash/ ee5bb72130c332c3d4bf8d231e617506-Abstract-Conference.html
2023
-
[76]
Pedro Sandoval Segura, Vasu Singla, Jonas Geiping, Micah Goldblum, Tom Goldstein, and David W. Jacobs. 2022. Autoregressive Perturbations for Data Poisoning.CoRRabs/2206.03693 (2022). arXiv:2206.03693 doi:10.48550/arXiv. 2206.03693
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[77]
Ronny Huang, Mahyar Najibi, Octavian Suciu, Christoph Studer, Tudor Dumitras, and Tom Goldstein
Ali Shafahi, W. Ronny Huang, Mahyar Najibi, Octavian Suciu, Christoph Studer, Tudor Dumitras, and Tom Goldstein. 2018. Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks. InAnnual Conference on Neural Infor- mation Processing Systems (NeurIPS). 6106–6116. https://proceedings.neurips. cc/paper/2018/hash/22722a343513ed45f14905eb07621686...
2018
-
[78]
Shawn Shan, Emily Wenger, Jiayun Zhang, Huiying Li, Haitao Zheng, and Ben Y. Zhao. 2020. Fawkes: Protecting Privacy against Unauthorized Deep Learning Models. In29th USENIX Security Symposium (USENIX), Srdjan Capkun and Franziska Roesner (Eds.). USENIX Association, 1589–1604. https://www.usenix. org/conference/usenixsecurity20/presentation/shan
2020
-
[79]
Mahmood Sharif, Sruti Bhagavatula, Lujo Bauer, and Michael K. Reiter. 2016. Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition. InProceedings of the ACM SIGSAC Conference on Computer and Communications Security. ACM, 1528–1540. doi:10.1145/2976749.2978392
-
[80]
Sunpreet Sharma, Ju Jia Zou, Gu Fang, Pancham Shukla, and Weidong Cai
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.