Recognition: no theorem link
Neurodata Without Boredom: Benchmarking Agentic AI for Data Reuse
Pith reviewed 2026-05-15 04:48 UTC · model grok-4.3
The pith
General-purpose AI coding agents handle isolated steps of neuroscience data reformatting but rarely complete error-free end-to-end pipelines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
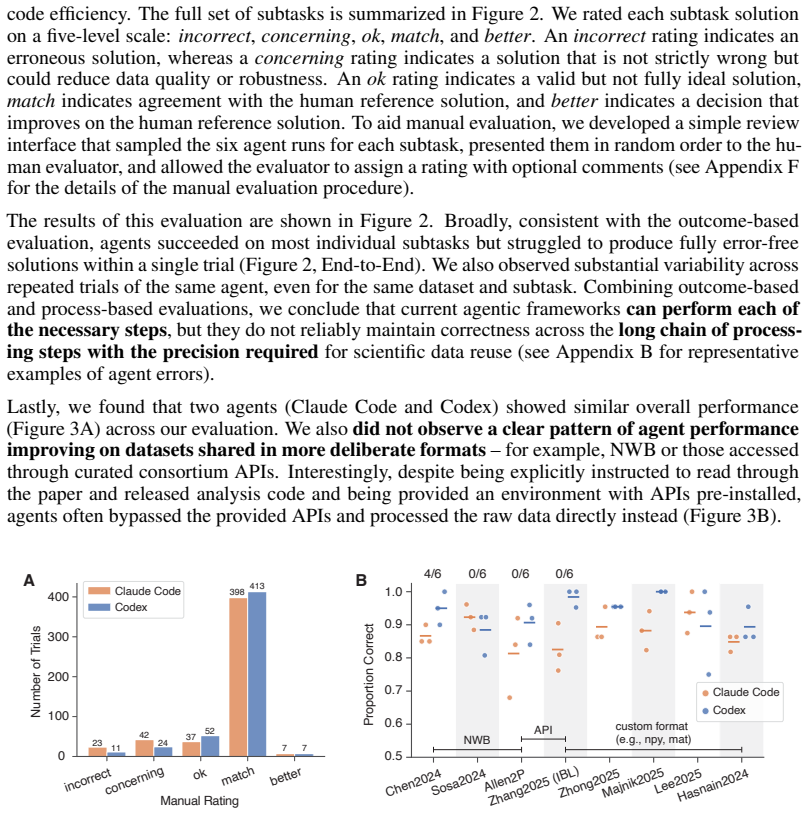
General-purpose coding agents commonly used by scientists performed well on each sub-task but rarely strung together a fully error-free end-to-end solution when reformatting data from eight diverse neuroscience papers for decoder training. Agents-as-judges are unreliable at catching errors, especially without ground-truth references, so interactive, human-in-the-loop coding remains necessary.
What carries the argument
The end-to-end reformatting benchmark that supplies papers, code, and raw data files to agents and requires them to produce clean inputs for training a neural decoder to behavioral variables.
If this is right
- Data-sharing practices can be updated to include explicit metadata and examples that reduce the specific error types agents currently make.
- Human oversight remains essential because agent self-evaluation does not reliably detect pipeline failures.
- Success on sub-tasks does not guarantee success on chained workflows, so future agent designs should target end-to-end consistency.
- Common flexible data formats still require external documentation that agents can exploit only when it is explicitly present.
Where Pith is reading between the lines
- If chaining reliability improves, large-scale integration of existing neural datasets could become routine without new manual curation for each reuse case.
- The same benchmarking approach could be applied to other fields that store raw experimental data in heterogeneous formats, such as genomics or materials science.
- Dataset properties that currently trigger agent errors, such as unusual file structures or missing variable descriptions, could be used to prioritize which legacy data to re-document first.
Load-bearing premise
The eight chosen papers and their formats are representative of typical neuroscience data-reuse obstacles and that performance on the decoder-training task serves as a good stand-in for broader reuse utility.
What would settle it
A follow-up test set of new neuroscience papers in which the same general-purpose agents produce complete, error-free reformatted files on the first attempt in at least 80 percent of cases without human edits.
Figures



read the original abstract
Neuroscience data are highly fragmented across labs, formats, and experimental paradigms, and reuse often requires substantial manual effort. A persistent roadblock to data reuse and integration is the need to decipher bespoke and diverse data formatting choices. Common data formats have been proposed in response, but the field continues to struggle with a fundamental tension: formats flexible enough to accommodate diverse experiments are rarely descriptive enough to be self-explanatory, and sufficiently descriptive formats demand detailed documentation and curation effort that few labs can sustain. Agentic AI is a natural candidate to solve this problem: LLMs read code and text faster and with sustained attention to the low-level details humans tend to skim over. To measure how well agentic AI performs on this task, we selected eight recent papers studying large-scale mouse neural population recordings that shared both data and code, spanning diverse recording modalities, behavioral paradigms, and dataset formats (e.g., NWB, specialized APIs, and general-purpose Python or MATLAB files). We provided agents with the data, code, and paper, and prompted them to load, understand, and reformat the data for a common downstream task: training a decoder from neural activity to task or behavioral variables. General-purpose coding agents commonly used by scientists performed well on each sub-task, but rarely strung together a fully error-free end-to-end solution. We characterize the types of mistakes agents made and the dataset properties that elicited them, and propose data-sharing best practices for the agentic-AI era. We further find that agents-as-judges are unreliable at catching errors, especially without ground-truth references, so interactive, human-in-the-loop coding remains necessary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This manuscript benchmarks general-purpose coding agents on neuroscience data reuse. From eight recent papers on large-scale mouse neural recordings that publicly share data and code, agents receive the paper, data, and code and are prompted to load, understand, and reformat the data for a downstream decoder-training task (neural activity to behavioral variables). The central empirical claims are that agents handle individual sub-tasks competently but rarely produce fully error-free end-to-end solutions, that common failure modes can be characterized, that agents-as-judges are unreliable at error detection without ground truth, and that specific data-sharing best practices would help.
Significance. If the empirical observations hold under more rigorous evaluation, the work supplies concrete, field-specific evidence of current agentic-AI limitations for data-reuse workflows in neuroscience. The characterization of failure modes and the call for human-in-the-loop practices could usefully inform both data-sharing standards and future agent design. The study also highlights a practical tension between flexible data formats and machine readability that is widely recognized but rarely quantified in this domain.
major comments (3)
- [Methods] Methods (dataset selection): the eight papers were chosen precisely because they already share both data and code; this selection criterion favors unusually clean, documented cases and does not represent the typical bespoke, poorly documented, or inaccessible formats that dominate neuroscience data reuse. The general claims about agent performance therefore rest on an unrepresentative sample.
- [Results] Results / Evaluation: the manuscript reports only qualitative outcomes and states that agents 'rarely strung together a fully error-free end-to-end solution' without defining 'error-free,' without reporting success rates, error frequencies, or inter-agent variability, and without error bars or statistical measures. This absence of quantitative metrics makes the central empirical claims impossible to assess rigorously.
- [Methods] Proxy task: decoder-training reformatting is presented as a representative reuse scenario, yet the paper does not demonstrate that success on this task correlates with performance on harder reuse problems (cross-dataset integration, missing metadata, multi-modal alignment). The stress-test concern that the chosen task underestimates real-world difficulty is therefore unaddressed.
minor comments (2)
- [Methods] Specify the exact agent implementations, LLM back-ends, versions, and prompting strategies used; reproducibility of the benchmark requires these details.
- [Abstract] The abstract claims agents 'performed well on each sub-task' but provides neither a breakdown of the sub-tasks nor any illustrative examples or failure cases.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us strengthen the manuscript. We address each major point below and have made revisions where appropriate to improve clarity, rigor, and transparency.
read point-by-point responses
-
Referee: [Methods] Methods (dataset selection): the eight papers were chosen precisely because they already share both data and code; this selection criterion favors unusually clean, documented cases and does not represent the typical bespoke, poorly documented, or inaccessible formats that dominate neuroscience data reuse. The general claims about agent performance therefore rest on an unrepresentative sample.
Authors: We intentionally selected papers that share both data and code to isolate the agents' performance on data interpretation and reformatting, rather than confounding the evaluation with data-access barriers. This establishes a baseline on relatively well-curated cases. We agree the sample is not representative of typical neuroscience datasets. In the revision we have added an explicit limitations section acknowledging this selection bias and noting that agent performance would likely degrade further on poorly documented data; we also outline how future benchmarks could incorporate more challenging cases. revision: partial
-
Referee: [Results] Results / Evaluation: the manuscript reports only qualitative outcomes and states that agents 'rarely strung together a fully error-free end-to-end solution' without defining 'error-free,' without reporting success rates, error frequencies, or inter-agent variability, and without error bars or statistical measures. This absence of quantitative metrics makes the central empirical claims impossible to assess rigorously.
Authors: We acknowledge that the original presentation relied primarily on qualitative characterization. For the revision we have added quantitative metrics: we now define 'error-free' as code that executes without runtime errors and produces output in the exact format required for the downstream decoder; we report per-agent success rates for end-to-end completion, frequencies of each error category, and inter-agent variability with appropriate error bars and statistical summaries. revision: yes
-
Referee: [Methods] Proxy task: decoder-training reformatting is presented as a representative reuse scenario, yet the paper does not demonstrate that success on this task correlates with performance on harder reuse problems (cross-dataset integration, missing metadata, multi-modal alignment). The stress-test concern that the chosen task underestimates real-world difficulty is therefore unaddressed.
Authors: The decoder-training reformatting task was selected because it is a frequent, concrete reuse goal in the field. We agree it does not automatically generalize to harder scenarios. The revised manuscript now includes a dedicated limitations paragraph discussing this proxy-task choice, provides illustrative examples of how the observed failure modes would compound on cross-dataset integration or missing-metadata cases, and states that the current results should be viewed as a lower bound on difficulty. revision: partial
Circularity Check
No circularity: purely empirical benchmarking on external datasets
full rationale
The paper reports direct empirical observations from running general-purpose coding agents on data and code from eight independently published neuroscience papers. No mathematical derivations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the described methodology or results. Central claims rest on observable agent behavior (sub-task success vs. end-to-end failures, judge unreliability) measured against external ground-truth data formats, with no reduction of outputs to the paper's own definitions or prior self-citations. The eight-paper selection is an explicit sampling choice whose representativeness is a separate generalizability concern, not a circularity issue.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The hippocampus as a predic- tive map
Kimberly L Stachenfeld, Matthew M Botvinick, and Samuel J Gershman. The hippocampus as a predic- tive map. Nature neuroscience, 20(11):1643–1653, 2017
work page 2017
-
[2]
Coarse graining, fixed points, and scaling in a large population of neurons
Leenoy Meshulam, Jeffrey L Gauthier, Carlos D Brody, David W Tank, and William Bialek. Coarse graining, fixed points, and scaling in a large population of neurons. Physical review letters , 123(17): 178103, 2019
work page 2019
-
[3]
Space is a latent sequence: A theory of the hippocampus
Rajkumar V asudeva Raju, J Swaroop Guntupalli, Guangyao Zhou, Carter Wendelken, Miguel Lázaro- Gredilla, and Dileep George. Space is a latent sequence: A theory of the hippocampus. Science Advances, 10(31):eadm8470, 2024
work page 2024
-
[4]
A unified, scalable framework for neural population decoding
Mehdi Azabou, Vinam Arora, V enkataramana Ganesh, Ximeng Mao, Santosh Nachimuthu, Michael Mendelson, Blake Richards, Matthew Perich, Guillaume Lajoie, and Eva Dyer. A unified, scalable framework for neural population decoding. Advances in Neural Information Processing Systems , 36: 44937–44956, 2023
work page 2023
-
[5]
Foundation model of neural activity predicts response to new stimulus types
Eric Y Wang, Paul G Fahey, Zhuokun Ding, Stelios Papadopoulos, Kayla Ponder, Marissa A Weis, An- dersen Chang, Taliah Muhammad, Saumil Patel, Zhiwei Ding, et al. Foundation model of neural activity predicts response to new stimulus types. Nature, 640(8058):470–477, 2025
work page 2025
-
[6]
Eva Dyer and Blake Richards. Accepting “the bitter lesson” and embracing the brain’s complexity. The Transmitter, March 2025. doi: 10.53053/ORXM6480. URL https://www.thetransmitter.org/ neuroai/accepting-the-bitter-lesson-and-embracing-the-brains-complexity/ . Online; accessed 2026-05-07. 10
-
[7]
The neurodata without borders ecosystem for neurophysiological data science
Oliver Rübel, Andrew Tritt, Ryan Ly, Benjamin K Dichter, Satrajit Ghosh, Lawrence Niu, Pamela Baker, Ivan Soltesz, Lydia Ng, Karel Svoboda, Loren Frank, and Kristofer E Bouchard. The neurodata without borders ecosystem for neurophysiological data science. eLife, 11:e78362, oct 2022. ISSN 2050-084X. doi: 10.7554/eLife.78362. URL https://doi.org/10.7554/eLife.78362
-
[8]
A brain-wide map of neural activity during complex behaviour
Dora Angelaki, Brandon Benson, Julius Benson, Daniel Birman, Niccolò Bonacchi, Kcénia Bougrova, Sebastian A Bruijns, Matteo Carandini, Joana A Catarino, et al. A brain-wide map of neural activity during complex behaviour. Nature, 645(8079):177–191, 2025
work page 2025
-
[9]
Brain-wide representations of prior information in mouse decision-making
Charles Findling, Felix Hubert, International Brain Laboratory, Luigi Acerbi, Brandon Benson, Julius Benson, Daniel Birman, Niccolò Bonacchi, E Kelly Buchanan, Sebastian Bruijns, et al. Brain-wide representations of prior information in mouse decision-making. Nature, 645(8079):192–200, 2025
work page 2025
-
[10]
Sharing neurophysiology data from the allen brain observatory
Saskia EJ de Vries, Joshua H Siegle, and Christof Koch. Sharing neurophysiology data from the allen brain observatory. Elife, 12:e85550, 2023
work page 2023
-
[11]
Liu, Han Hou, Nai-Wen Tien, Tim Wang, Timothy Harris, Shaul Druckmann, Nuo Li, and Karel Svoboda
Susu Chen, Yi Liu, Ziyue Aiden Wang, Jennifer Colonell, Liu D. Liu, Han Hou, Nai-Wen Tien, Tim Wang, Timothy Harris, Shaul Druckmann, Nuo Li, and Karel Svoboda. Brain-wide neural activity underlying memory-guided movement. Cell, 187(3):676–691.e16, 2024. doi: 10.1016/j.cell.2023.12.035
-
[12]
Carlos E Jimenez, John Y ang, Alexander Wettig, Shunyu Y ao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. Swe-bench: Can language models resolve real-world github issues? In The twelfth interna- tional conference on learning representations, 2023
work page 2023
-
[13]
Human-in-the-loop software development agents
Wannita Takerngsaksiri, Jirat Pasuksmit, Patanamon Thongtanunam, Chakkrit Tantithamthavorn, Ruix- iong Zhang, Fan Jiang, Jing Li, Evan Cook, Kun Chen, and Ming Wu. Human-in-the-loop software development agents. In 2025 IEEE/ACM 47th International Conference on Software Engineering: Soft- ware Engineering in Practice (ICSE-SEIP) , pages 342–352. IEEE, 2025
work page 2025
-
[14]
Super: Evaluating agents on setting up and executing tasks from research repositories, 2024
Ben Bogin, Kejuan Y ang, Shashank Gupta, Kyle Richardson, Erin Bransom, Peter Clark, Ashish Sab- harwal, and Tushar Khot. Super: Evaluating agents on setting up and executing tasks from research repositories, 2024. URL https://arxiv.org/abs/2409.07440
-
[15]
Siegel, Sayash Kapoor, Nitya Nagdir, Benedikt Stroebl, and Arvind Narayanan
Zachary S. Siegel, Sayash Kapoor, Nitya Nagdir, Benedikt Stroebl, and Arvind Narayanan. Core-bench: Fostering the credibility of published research through a computational reproducibility agent benchmark,
- [16]
-
[17]
PaperBench: Evaluating AI's Ability to Replicate AI Research
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Te- jal Patwardhan. Paperbench: Evaluating ai’s ability to replicate ai research, 2025. URL https: //arxiv.org/abs/2504.01848
work page internal anchor Pith review arXiv 2025
-
[18]
Mle-bench: Evaluating machine learning agents on machine learning engineering, 2025
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander Mdry. Mle-bench: Evaluating machine learning agents on machine learning engineering, 2025. URL https://arxiv.org/abs/2410. 07095
work page 2025
-
[19]
Qian Huang, Jian V ora, Percy Liang, and Jure Leskovec. Mlagentbench: Evaluating language agents on machine learning experimentation, 2024. URL https://arxiv.org/abs/2310.03302
-
[20]
Ziru Chen, Shijie Chen, Y uting Ning, Qianheng Zhang, Boshi Wang, Botao Y u, Yifei Li, Zeyi Liao, Chen Wei, Zitong Lu, Vishal Dey, Mingyi Xue, Frazier N. Baker, Benjamin Burns, Daniel Adu- Ampratwum, Xuhui Huang, Xia Ning, Song Gao, Y u Su, and Huan Sun. Scienceagentbench: To- ward rigorous assessment of language agents for data-driven scientific discovery...
-
[21]
Ken Gu, Ruoxi Shang, Ruien Jiang, Keying Kuang, Richard-John Lin, Donghe Lyu, Y ue Mao, Y ouran Pan, Teng Wu, Jiaqian Y u, Yikun Zhang, Tianmai M. Zhang, Lanyi Zhu, Mike A. Merrill, Jeffrey Heer, and Tim Althoff. Blade: Benchmarking language model agents for data-driven science, 2025. URL https://arxiv.org/abs/2408.09667
-
[22]
Discoverybench: Towards data-driven discovery with large language models, 2024
Bodhisattwa Prasad Majumder, Harshit Surana, Dhruv Agarwal, Bhavana Dalvi Mishra, Abhijeetsingh Meena, Aryan Prakhar, Tirth V ora, Tushar Khot, Ashish Sabharwal, and Peter Clark. Discoverybench: Towards data-driven discovery with large language models, 2024. URL https://arxiv.org/abs/ 2407.01725
-
[23]
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers, 2021. URL https://arxiv. org/abs/2105.03011. 11
-
[24]
Qasa: advanced question answering on scientific articles
Y oonjoo Lee, Kyungjae Lee, Sunghyun Park, Dasol Hwang, Jaehyeon Kim, Hong-in Lee, and Moontae Lee. Qasa: advanced question answering on scientific articles. In International Conference on Machine Learning, pages 19036–19052. PMLR, 2023
work page 2023
-
[25]
Scidqa: A deep reading comprehension dataset over scientific papers, 2024
Shruti Singh, Nandan Sarkar, and Arman Cohan. Scidqa: A deep reading comprehension dataset over scientific papers, 2024. URL https://arxiv.org/abs/2411.05338
-
[26]
Ritt, and Alexander Fleis- chmann
Andrea Pierré, Tuan Pham, Jonah Pearl, Sandeep Robert Datta, Jason T. Ritt, and Alexander Fleis- chmann. A perspective on neuroscience data standardization with neurodata without borders. Journal of Neuroscience , 44(38), 2024. ISSN 0270-6474. doi: 10.1523/JNEUROSCI.0381-24.2024. URL https://www.jneurosci.org/content/44/38/e0381242024
-
[27]
DANDI: Distributed archives for neurophysiology data integration
DANDI Archive. DANDI: Distributed archives for neurophysiology data integration. https:// dandiarchive.org/, 2024. Accessed: 2026-05-07
work page 2024
-
[28]
Neuroconv: Streamlining neurophysiology data conversion to the nwb standard
Heberto Mayorquin, Cody Baker, Paul Adkisson-Floro, Szonja Weigl, Alessandra Trapani, Luiz Tauffer, Oliver Rübel, and Benjamin Dichter. Neuroconv: Streamlining neurophysiology data conversion to the nwb standard. In Proceedings of the 24th Python in Science Conference , July 2025. doi: 10.25080/ cehj4257
work page 2025
-
[29]
Data Release – Brainwide Map – Q4 2022
The International Brain Laboratory. Data Release – Brainwide Map – Q4 2022. figshare preprint,
work page 2022
-
[30]
V ersion 7, updated 2024-09-19
URL https://figshare.com/articles/preprint/Data_release_-_Brainwide_map_-_ Q4_2022/21400815. V ersion 7, updated 2024-09-19
work page 2024
-
[31]
Allen Brain Observatory: Visual Behavior 2P Technical Whitepa- per
Allen Institute. Allen Brain Observatory: Visual Behavior 2P Technical Whitepa- per. Technical report, Allen Institute for Brain Science, March 2021. URL https: //brainmapportal-live-4cc80a57cd6e400d854-f7fdcae.divio-media.net/filer_ public/4e/be/4ebe2911-bd38-4230-86c8-01a86cfd758e/visual_behavior_2p_technical_ whitepaper.pdf. V1.0
work page 2021
-
[32]
Multi-session, multi-task neural decoding from distinct cell-types and brain regions
Mehdi Azabou, Krystal Xuejing Pan, Vinam Arora, Ian Jarratt Knight, Eva L Dyer, and Blake Aaron Richards. Multi-session, multi-task neural decoding from distinct cell-types and brain regions. In The Thirteenth International Conference on Learning Representations , 2025. URL https://openreview. net/forum?id=IuU0wcO0mo
work page 2025
-
[33]
Joel Y e, Fabio Rizzoglio, Adam Smoulder, Hongwei Mao, Xuan Ma, Patrick Marino, Raeed Chowdhury, Dalton Moore, Gary Blumenthal, William Hockeimer, Nicolas G. Kunigk, J. Patrick Mayo, Aaron Batista, Steven Chase, Adam Rouse, Michael L. Boninger, Charles Greenspon, Andrew B. Schwartz, Nicholas G. Hatsopoulos, Lee E. Miller, Kristofer E. Bouchard, Jennifer L...
-
[34]
Yizi Zhang, Y anchen Wang, Donato Jimenez-Beneto, Zixuan Wang, Mehdi Azabou, Blake Richards, Olivier Winter, International Brain Laboratory, Eva Dyer, Liam Paninski, and Cole Hurwitz. Towards a "universal translator" for neural dynamics at single-cell, single-spike resolution, 2024. URL https: //arxiv.org/abs/2407.14668
-
[35]
Munib A. Hasnain, Jaclyn E. Birnbaum, Juan Luis Ugarte Nunez, Emma K. Hartman, Chandramouli Chandrasekaran, and Michael N. Economo. Separating cognitive and motor processes in the behaving mouse. Nature Neuroscience, 28:640–653, 2025. doi: 10.1038/s41593-024-01859-1
-
[36]
J. Quinn Lee, Alexandra T. Keinath, Erica Cianfarano, and Mark P . Brandon. Identifying representational structure in CA1 to benchmark theoretical models of cognitive mapping. Neuron, 113(2):307–320.e5,
-
[37]
doi: 10.1016/j.neuron.2024.10.027
-
[38]
Longitudinal tracking of neuronal activity from the same cells in the developing brain using Track2p
Jure Majnik, Manon Mantez, Sofia Zangila, Stéphane Bugeon, Léo Guignard, Jean-Claude Platel, and Rosa Cossart. Longitudinal tracking of neuronal activity from the same cells in the developing brain using Track2p. eLife, 14:RP107540, 2025. doi: 10.7554/eLife.107540
-
[39]
Unsupervised pretraining in biological neural networks
Lin Zhong, Scott Baptista, Rachel Gattoni, Jon Arnold, Daniel Flickinger, Carsen Stringer, and Marius Pachitariu. Unsupervised pretraining in biological neural networks. Nature, 644:741–748, 2025. doi: 10.1038/s41586-025-09180-y
-
[40]
Marielena Sosa, Mark H. Plitt, and Lisa M. Giocomo. A flexible hippocampal population code for experi- ence relative to reward. Nature Neuroscience, 28:1497–1509, 2025. doi: 10.1038/s41593-025-01985-4
-
[41]
Yizi Zhang, Hanrui Lyu, Cole Hurwitz, Shuqi Wang, Charles Findling, Y anchen Wang, Felix Hu- bert, International Brain Laboratory, Alexandre Pouget, Erdem V arol, and Liam Paninski. Exploit- ing correlations across trials and behavioral sessions to improve neural decoding. Neuron, 2025. doi: 10.1016/j.neuron.2025.10.026. 12 Appendix A Supplementary Figure...
-
[42]
Do this BEFORE exploring any code or data
**CREATE CONVERSION_NOTES.md IMMEDIATELY** : Your very first action must be to create `CONVERSION_NOTES.md`. Do this BEFORE exploring any code or data. Document everything in this file as you work
- [43]
-
[44]
**MATCH THE REFERENCE PROCESSING** : Your processing must match what 's described in the reference paper and code. You will be assessed on this consistency. --- ## Project Context - You are a computational neuroscientist. Your goal is to load and reformat data from a neuroscience paper into a specified structure suitable for downstream analysis. - You nee...
-
[45]
Data structure is correct - will report errors and warnings to stdout
-
[46]
Dimensions are consistent - will report errors and warnings to stdout
-
[47]
Values are sensible - will report errors and warnings to stdout
-
[48]
Decoder can successfully train and predict
-
[49]
Poor performance indicates data formatting issues that need investigation ### Consistency requirements Your processing and formatting must **match the reference paper and code** with respect to: - Loading of data - Temporal alignment of different time series streams (neural, inputs, outputs) - Processing of neural, input, and output data streams - Curatio...
-
[50]
**FIRST**: Create `CONVERSION_NOTES.md` with the template structure shown at the end of this document
-
[51]
Verify you can run `python3` and import key packages (numpy, torch)
-
[52]
List the contents of this directory to understand what files are available
-
[53]
Step 5" - You have documented all decisions under
**REMINDER**: Do NOT look at any files outside this directory **Done when** : - `CONVERSION_NOTES.md` exists with the proper template structure - You have confirmed Python and key packages work - You have listed directory contents in CONVERSION_NOTES.md ** CHECKPOINT** : Before proceeding to Step 1, verify that `CONVERSION_NOTES.md` exists by running `ls ...
-
[54]
Verify the sample data structure matches the specification
Run `python -u convert_data.py sample_data.pkl --sample --show-processing 2>&1 | tee conversion_sample_out.txt` a. Verify the sample data structure matches the specification. b. Check dimensions are consistent across trials/sessions. c. Check that no data is missed during conversion. d. Validate that metadata accurately describes the data
-
[55]
Improve efficiency of conversion. a. Look at and note timing information for the conversion. b. Estimate how long the full conversion will run. When you do this, make sure that your estimate accounts for differences in lengths/numbers of trials/sessions. c. If full conversion time estimate is longer than 15 minutes, speed up the code by writing more effic...
-
[56]
Run `python -u train_decoder.py sample_data.pkl --verify-only 2>&1 | tee verification_sample_out.txt `
-
[57]
Analyze the output file `verification_sample_out.txt`: a. Verify no errors reported. b. Attempt to address any warnings c. Check input ranges and output value distributions against expectations from reference texts. **Done when** : - `sample_data.pkl` is created and passes manual inspection - `verification_sample_out.txt` is created and passes inspection ...
-
[58]
Run `python -u train_decoder.py sample_data.pkl 2>&1 | tee train_decoder_sample_out.txt `
-
[60]
--- ### Step 9: Full Conversion and Validation **Goal**: Process the complete dataset
**Check accuracy** : Verify accuracy is above chance for EVERY output **Investigate any issues** : - If accuracy is low: check for conversion bugs or reconsider output representation 32 **Done when** : - Decoder training completes without errors - Loss decreases over epochs - Accuracies are above chance - Document all results in CONVERSION_NOTES.md under ...
-
[61]
Review your time estimate from Step 7
-
[62]
longer than 15 minutes), optimize bottlenecks first
If estimated time is long (e.g. longer than 15 minutes), optimize bottlenecks first
-
[63]
Run `python -u convert_data.py converted_data.pkl --full 2>&1 | tee conversion_full_out.txt `
-
[64]
As the code runs, update your estimates of how long processing will take. If it is much longer than your previous estimate (> 1.5x), kill the process, optimize bottlenecks, and repeat
-
[65]
Run `python -u train_decoder.py converted_data.pkl --verify-only 2>&1 | tee verification_full_out.txt `
-
[66]
Check that no data was lost during conversion
-
[67]
Spot-check a few sessions to verify data integrity
-
[68]
**Check for consistency** between dataset statistics in `verification_full_out.txt` and the reference texts
-
[69]
Investigate any inconsistencies, and revise the conversion script until all dataset statistics are consistent **Done when** : - `converted_data.pkl` is created and passes manual inspection - `verification_full_out.txt` is created and passes inspection - **ALL** dataset statistics are consistent with values from reference texts - You have documented statis...
-
[73]
Document each iteration: what was found, what was fixed, what the re-check showed Write a report to CONVERSION_NOTES.md describing **every** check you did, to help convince the user that the conversion code works. **Done when** : You have documented your review findings and all issues are resolved in CONVERSION_NOTES.md under "Step 10". ** DO NOT PROCEED*...
-
[74]
Run `python -u train_decoder.py converted_data.pkl --plot-samples 2>&1 | tee train_decoder_full_out.txt`. If the GPU does not have sufficient RAM for the network training, use the flag `--cpu` to specify to use the CPU to train
-
[75]
**Wait for complete execution** this may take significant time for large datasets
-
[76]
**Check training** : Verify loss decreases over epochs
-
[77]
**Check accuracy** : High accuracy is an indicator that data conversion has been done correctly. Accuracy near chance is a sign that there might be issues in temporal alignment of signals, choice of data streams, or filtering or processing of data. Compare accuracy to expectations based on the paper. **Done when** :
-
[78]
Full decoder training completes (the script finishes running)
-
[79]
Fix issues and re-run affected steps
Accuracy results are documented in CONVERSION_NOTES.md under "Step 11" with a table of accuracies --- ### Step 12: Critical Review 2 **Goal**: Find and fix any errors by performing the following checks. Fix issues and re-run affected steps. Iterate until no issues remain. Perform all of the following checks: **Check 1: Accuracy vs chance analysis** - For ...
-
[80]
Verify the output values are correct by loading raw data and checking 3 specific trials
-
[81]
Check temporal alignment plot neural + output for a single trial to verify they 're synchronized
-
[82]
Check whether the output has enough variation (not 99% one class)
-
[83]
Check that filtering steps for neural activity streams are followed
-
[84]
**Iteration protocol** : If ANY check above reveals an issue:
Check that processing of the data matches the reference code and paper. **Iteration protocol** : If ANY check above reveals an issue:
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.