Recognition: unknown
Reinforced Collaboration in Multi-Agent Flow Networks
Pith reviewed 2026-05-14 20:38 UTC · model grok-4.3
The pith
MANGO improves multi-agent LLM collaboration by building flow networks from successful workflows and optimizing them with reinforcement learning and textual gradients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
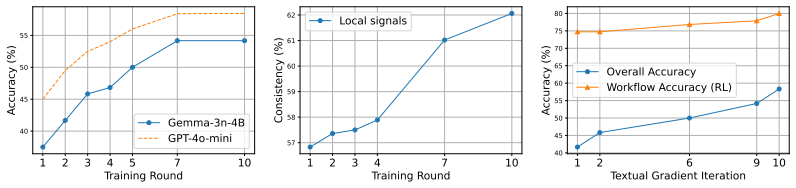
MANGO constructs a flow network from historical successful workflows, then jointly optimizes the network paths and agent behaviors through reinforcement learning for path selection and textual gradients for behavior adjustment, using a skipping mechanism to skip updates on already-optimized agents and thereby improve efficiency while reducing error propagation.
What carries the argument
A flow network built from past successful workflows, optimized jointly by reinforcement learning for path selection and textual gradients for agent behavior refinement, with a skipping mechanism to avoid redundant updates.
Load-bearing premise
Optimizing flow networks drawn from past successful workflows with RL and textual gradients will reliably cut error propagation and generalize to new domains without the optimization step itself creating new failures or overfitting to the training workflows.
What would settle it
A direct comparison on an unseen domain in which MANGO produces lower final accuracy or higher propagated error rates than the same agents run without the flow-network optimization.
Figures






read the original abstract
Multi-agent systems provide a powerful way to extend large language models (LLMs) by decomposing a complex task into specialized subtasks handled by different agents. However, their performance is often hindered by error propagation, arising from suboptimal workflow design or inaccurate agent outputs, which can propagate through the agent collaboration process and degrade final results. To address the challenges, we present MANGO (Multi-Agent Network Gradient Optimization), a data-driven framework that organizes and refines agent collaboration via a flow network constructed from past successful workflows. MANGO integrates reinforcement learning and textual gradients to jointly optimize workflow paths and agent behaviors, while a skipping mechanism prevents redundant updates to well-optimized agents for improving efficiency. Extensive experiments on seven benchmarks show that MANGO achieves up to 12.8% performance improvement over state-of-the-art baselines, enhances efficiency by 47.4%, and generalizes effectively to unseen domains. Our code and datasets are publicly available at https://github.com/openJiuwen-ai/agent-store/tree/main/community/mango.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MANGO, a data-driven framework for multi-agent LLM collaboration that builds flow networks from historical successful workflows, then jointly optimizes workflow paths and agent behaviors via reinforcement learning and textual gradients, augmented by a skipping mechanism to avoid redundant updates on well-optimized agents. The central empirical claims are that this approach reduces error propagation, yields up to 12.8% performance gains and 47.4% efficiency improvements over state-of-the-art baselines across seven benchmarks, and generalizes to unseen domains, with public code and datasets released.
Significance. If the performance and generalization claims are substantiated, the work would offer a practical method for constructing and refining multi-agent workflows that mitigates error propagation in LLM systems. The public release of code and datasets is a clear strength supporting reproducibility and follow-on research in multi-agent optimization.
major comments (2)
- [Experimental Evaluation] Experimental Evaluation section: The abstract and results report up to 12.8% performance improvement and 47.4% efficiency gains without providing details on experimental controls, number of runs, statistical significance tests, variance, or precise criteria for baseline selection; this information is load-bearing for validating the quantitative superiority claims.
- [Generalization Experiments] Generalization Experiments subsection: No ablation studies isolate the contribution of RL plus textual-gradient optimization versus the base flow-network construction from past workflows, nor do they test whether the skipping mechanism limits adaptation; without such evidence the claim of reliable generalization to truly unseen domains (and absence of new failure modes) cannot be assessed.
minor comments (2)
- [Abstract] The abstract introduces 'textual gradients' without a brief definition or forward reference to the methods section; adding one sentence of clarification would improve accessibility.
- [Method] Figure captions for the flow-network diagrams should explicitly state the meaning of edge weights and node labels to avoid ambiguity in the optimization description.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the paper. We address both major concerns by committing to specific additions in the revised manuscript, including expanded experimental details and new ablation studies. These changes will directly support the performance and generalization claims.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental Evaluation section: The abstract and results report up to 12.8% performance improvement and 47.4% efficiency gains without providing details on experimental controls, number of runs, statistical significance tests, variance, or precise criteria for baseline selection; this information is load-bearing for validating the quantitative superiority claims.
Authors: We agree that additional experimental details are required to substantiate the claims. In the revised manuscript, we will expand the Experimental Evaluation section to report: (i) all experiments run with 5 independent random seeds, (ii) mean and standard deviation for every metric, (iii) paired t-test p-values confirming statistical significance of the 12.8% and 47.4% gains, and (iv) explicit baseline selection criteria (most recent SOTA methods published in top venues with matching task settings and model backbones). The public code release already contains the exact experimental scripts, allowing full reproducibility. revision: yes
-
Referee: [Generalization Experiments] Generalization Experiments subsection: No ablation studies isolate the contribution of RL plus textual-gradient optimization versus the base flow-network construction from past workflows, nor do they test whether the skipping mechanism limits adaptation; without such evidence the claim of reliable generalization to truly unseen domains (and absence of new failure modes) cannot be assessed.
Authors: We acknowledge the absence of explicit component-wise ablations in the current version. The revised manuscript will add a new subsection with controlled ablations that isolate: (1) the base flow network built from historical workflows alone, (2) addition of RL path optimization, (3) addition of textual-gradient agent updates, and (4) the full model including the skipping mechanism. We will also evaluate on two further held-out domains and explicitly report any observed failure modes or adaptation limits. These results will be presented alongside the existing generalization experiments. revision: yes
Circularity Check
No significant circularity: framework derives from historical data and external benchmarks without self-referential reduction
full rationale
The paper presents MANGO as constructing flow networks from past successful workflows, then applying RL and textual gradients for optimization, with performance evaluated on seven benchmarks including generalization to unseen domains. No equations, fitted parameters, or central claims reduce the reported 12.8% gains or 47.4% efficiency improvements to quantities defined by the same inputs or self-citations. The derivation chain remains independent of the target results, with claims resting on empirical validation rather than construction or renaming.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Langchain.https://github.com/langchain-ai/langchain, 2022
Harrison Chase. Langchain.https://github.com/langchain-ai/langchain, 2022
2022
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Multi-agent collaboration via evolving orchestration.NeurIPS, 2025
Yufan Dang, Chen Qian, Xueheng Luo, Jingru Fan, Zihao Xie, Ruijie Shi, Weize Chen, Cheng Yang, Xiaoyin Che, Ye Tian, et al. Multi-agent collaboration via evolving orchestration.NeurIPS, 2025
2025
-
[6]
Improving factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. InICML, 2023
2023
-
[7]
DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gard- ner. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. arXiv preprint arXiv:1903.00161, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[8]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. ReTool: Reinforcement learning for strategic tool use in llms.arXiv preprint arXiv:2504.11536, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Huan-ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, et al. A survey of self-evolving agents: On path to artificial super intelligence.arXiv preprint arXiv:2507.21046, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
Chatllm network: More brains, more intelligence.AI Open, 6:45–52, 2025
Rui Hao, Linmei Hu, Weijian Qi, Qingliu Wu, Yirui Zhang, and Liqiang Nie. Chatllm network: More brains, more intelligence.AI Open, 6:45–52, 2025
2025
-
[11]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InICLR, 2020
2020
-
[12]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
MetaGPT: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and J¨urgen Schmidhuber. MetaGPT: Meta programming for a multi-agent collaborative framework. InICLR, 2024
2024
-
[14]
Automated design of agentic systems
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems. InICLR, 2024
2024
-
[15]
arXiv preprint arXiv:2410.16946 , year=
Yue Hu, Yuzhu Cai, Yaxin Du, Xinyu Zhu, Xiangrui Liu, Zijie Yu, Yuchen Hou, Shuo Tang, and Siheng Chen. Self-evolving multi-agent collaboration networks for software development. arXiv preprint arXiv:2410.16946, 2024
-
[16]
Plan-and-execute agents
LangChain. Plan-and-execute agents. https://blog.langchain.com/planning-agents/, 2024
2024
-
[17]
Camel: Communicative agents for “mind” exploration of large language model society
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for “mind” exploration of large language model society. InNeurIPS, 2023
2023
-
[18]
Agentswift: Efficient llm agent design via value-guided hierarchical search.AAAI, 2026
Yu Li, Lehui Li, Zhihao Wu, Qingmin Liao, Jianye Hao, Kun Shao, Fengli Xu, and Yong Li. Agentswift: Efficient llm agent design via value-guided hierarchical search.AAAI, 2026. 10
2026
-
[19]
Marft: Multi-agent reinforcement fine-tuning.arXiv preprint arXiv:2504.16129, 2025
Junwei Liao, Muning Wen, Jun Wang, and Weinan Zhang. Marft: Multi-agent reinforcement fine-tuning.arXiv preprint arXiv:2504.16129, 2025
-
[20]
Llamaindex
Jerry Liu and LlamaIndex Team. Llamaindex. https://github.com/run-llama/llama_ index, 2022
2022
-
[21]
arXiv preprint arXiv:2508.04652 , year=
Shuo Liu, Zeyu Liang, Xueguang Lyu, and Christopher Amato. Llm collaboration with multi- agent reinforcement learning.arXiv preprint arXiv:2508.04652, 2025
-
[22]
Dynamic llm-agent network: An llm-agent collaboration framework with agent team optimization
Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. Dynamic llm-agent net- work: An llm-agent collaboration framework with agent team optimization.arXiv preprint arXiv:2310.02170, 2023
-
[23]
Keer Lu, Chong Chen, Bin Cui, Huang Leng, and Wentao Zhang. Pilotrl: Training language model agents via global planning-guided progressive reinforcement learning.arXiv preprint arXiv:2508.00344, 2025
-
[24]
Self-refine: Iterative refinement with self-feedback.NeurIPS, 36:46534–46594, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback.NeurIPS, 36:46534–46594, 2023
2023
-
[25]
arXiv preprint arXiv:2502.18439 , year=
Chanwoo Park, Seungju Han, Xingzhi Guo, Asuman Ozdaglar, Kaiqing Zhang, and Joo-Kyung Kim. Maporl: Multi-agent post-co-training for collaborative large language models with reinforcement learning.arXiv preprint arXiv:2502.18439, 2025
-
[26]
Bernstein
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generalist agents. InUIST, 2023
2023
-
[27]
arXiv preprint arXiv:2503.13413 , year=
Dengyun Peng, Yuhang Zhou, Qiguang Chen, Jinhao Liu, Jingjing Chen, and Libo Qin. Dlpo: Towards a robust, efficient, and generalizable prompt optimization framework from a deep- learning perspective.arXiv preprint arXiv:2503.13413, 2025
-
[28]
Cooperate or collapse: Emergence of sustainability behaviors in a society of llm agents.CoRR, 2024
Giorgio Piatti, Zhijing Jin, Max Kleiman-Weiner, Bernhard Scholkopf, Mrinmaya Sachan, and Rada Mihalcea. Cooperate or collapse: Emergence of sustainability behaviors in a society of llm agents.CoRR, 2024
2024
-
[29]
gradient descent
Reid Pryzant, Dan Iter, Jerry Li, Yin Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with “gradient descent” and beam search. InEMNLP, pages 7957–7968, 2023
2023
-
[30]
ChatDev: Communicative Agents for Software Development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. Chatdev: Communicative agents for software development.arXiv preprint arXiv:2307.07924, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-T¨ur, Gokhan Tur, and Heng Ji. ToolRL: Reward is all tool learning needs.arXiv preprint arXiv:2504.13958, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InCOLM, 2024
2024
-
[33]
Toran Bruce Richards and Significant Gravitas. Autogpt. https://github.com/ Significant-Gravitas/AutoGPT, 2023
2023
-
[34]
Agentsquare: Automatic llm agent search in modular design space
Yu Shang, Yu Li, Keyu Zhao, Likai Ma, Jiahe Liu, Fengli Xu, and Yong Li. Agentsquare: Automatic llm agent search in modular design space. InICLR, 2024
2024
-
[35]
Shuaijie She, Yu Bao, Yu Lu, Lu Xu, Tao Li, Wenhao Zhu, Shujian Huang, Shanbo Cheng, Lu Lu, and Yuxuan Wang. Dupo: Enabling reliable llm self-verification via dual preference optimization.arXiv preprint arXiv:2508.14460, 2025
-
[36]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Barlas O˘guz, and Nazneen Rajani. Reflexion: Language agents with verbal reinforcement learning. InNeurIPS, 2023. 11
2023
-
[37]
Trial and error: Exploration-based trajectory optimization of llm agents
Yifan Song, Da Yin, Xiang Yue, Jie Huang, Sujian Li, and Bill Yuchen Lin. Trial and error: Exploration-based trajectory optimization of llm agents. InACL, pages 7584–7600, 2024
2024
-
[38]
In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents
Zhen Tan, Jun Yan, I Hsu, Rujun Han, Zifeng Wang, Long T Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, et al. In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents. InACL, 2025
2025
-
[39]
Toward self-improvement of llms via imagination, searching, and criticizing
Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Lei Han, Haitao Mi, and Dong Yu. Toward self-improvement of llms via imagination, searching, and criticizing. InNeurIPS, 2024
2024
-
[40]
V oyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. TMLR, 2024
2024
-
[41]
Xagent: An autonomous agent for complex task solving.https://github.com/OpenBMB/XAgent, 2023
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mand—dlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, Anima Anandkumar, and the XAgent Team. Xagent: An autonomous agent for complex task solving.https://github.com/OpenBMB/XAgent, 2023
2023
-
[42]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InICLR, 2022
2022
-
[43]
M-rag: Reinforcing large language model performance through retrieval-augmented generation with multiple partitions
Zheng Wang, Shu Teo, Jieer Ouyang, Yongjun Xu, and Wei Shi. M-rag: Reinforcing large language model performance through retrieval-augmented generation with multiple partitions. InACL, 2024
2024
-
[44]
Instructrag: Leveraging retrieval- augmented generation on instruction graphs for llm-based task planning
Zheng Wang, Shu Xian Teo, Jun Jie Chew, and Wei Shi. Instructrag: Leveraging retrieval- augmented generation on instruction graphs for llm-based task planning. InSIGIR, 2025
2025
-
[45]
Zhenhailong Wang, Shaoguang Mao, Wenshan Wu, Tao Ge, Furu Wei, and Heng Ji. Unleashing cognitive synergy in large lan-guage models: Atask-solving agent through multi-persona self- collaboration.arXiv preprint arXiv:2307.05300, 2023
-
[46]
Chain of thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. InNeurIPS, 2022
2022
-
[47]
Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
1992
-
[48]
Autogen: Enabling next-gen llm applications via multi-agent conversation framework
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. Autogen: Enabling next-gen llm applications via multi-agent conversation framework. InFirst Conference on Language Modeling, 2023
2023
-
[49]
Self-supervised prompt optimization.arXiv preprint arXiv:2502.06855, 2025
Jinyu Xiang, Jiayi Zhang, Zhaoyang Yu, Fengwei Teng, Jinhao Tu, Xinbing Liang, Sirui Hong, Chenglin Wu, and Yuyu Luo. Self-supervised prompt optimization.arXiv preprint arXiv:2502.06855, 2025
-
[50]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Hinrich Sch ¨utze, V olker Tresp, and Yunpu Ma. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Augmented runtime collaboration for self-organizing multi-agent systems: A hybrid bi-criteria routing approach
Qingwen Yang, Feiyu Qu, Tiezheng Guo, Yanyi Liu, and Yingyou Wen. Augmented runtime collaboration for self-organizing multi-agent systems: A hybrid bi-criteria routing approach. In AAAI, pages 29811–29819, 2026
2026
-
[52]
Webshop: Towards scalable real-world web interaction with grounded language agents.NeurIPS, 35:20744–20757, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.NeurIPS, 35:20744–20757, 2022
2022
-
[53]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In NeurIPS, 2023. 12
2023
-
[54]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InICLR, 2023
2023
-
[55]
Mas-gpt: Training llms to build llm-based multi-agent systems
Rui Ye, Shuo Tang, Rui Ge, Yaxin Du, Zhenfei Yin, Siheng Chen, and Jing Shao. Mas-gpt: Training llms to build llm-based multi-agent systems. InICML, 2025
2025
-
[56]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Evoagent: Towards automatic multi-agent generation via evolutionary algorithms
Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Dongsheng Li, and Deqing Yang. Evoagent: Towards automatic multi-agent generation via evolutionary algorithms. InNAACL, 2025
2025
-
[58]
Optimizing generative ai by backpropagating language model feedback.Nature, 639:609–616, 2025
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Pan Lu, Zhi Huang, Carlos Guestrin, and James Zou. Optimizing generative ai by backpropagating language model feedback.Nature, 639:609–616, 2025
2025
-
[59]
Simplerlzoo: Investigating and taming zero reinforcement learning for open base models in the wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerlzoo: Investigating and taming zero reinforcement learning for open base models in the wild. InCOLM, 2025
2025
-
[60]
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, et al. The landscape of agentic reinforcement learning for llms: A survey.arXiv preprint arXiv:2509.02547, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Maas: Multi-agent architecture search via agentic supernet
Guibin Zhang, Luyang Niu, Junfeng Fang, Kun Wang, Lei Bai, and Xiang Wang. Maas: Multi-agent architecture search via agentic supernet. InICML, 2025
2025
-
[62]
G-designer: Architecting multi-agent communication topologies via graph neural networks
Guibin Zhang, Yanwei Yue, Xiangguo Sun, Guancheng Wan, Miao Yu, Junfeng Fang, Kun Wang, Tianlong Chen, and Dawei Cheng. G-designer: Architecting multi-agent communication topologies via graph neural networks. InICML, 2025
2025
-
[63]
Aflow: Automating agentic workflow generation
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, XiongHui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. Aflow: Automating agentic workflow generation. InICLR, 2025
2025
-
[64]
Automatic chain of thought prompting in large language models
Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. Automatic chain of thought prompting in large language models. InICLR, 2023
2023
-
[65]
Symbolic learning enables self-evolving agents
Wangchunshu Zhou, Yixin Ou, Shengwei Ding, Long Li, Jialong Wu, Tiannan Wang, Jiamin Chen, Shuai Wang, Xiaohua Xu, Ningyu Zhang, et al. Symbolic learning enables self-evolving agents.arXiv preprint arXiv:2406.18532, 2024
-
[66]
Gptswarm: Language agents as optimizable graphs
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and J¨urgen Schmidhuber. Gptswarm: Language agents as optimizable graphs. InICML, 2024. 13 A Experimental Details A.1 Dataset Statistics We follow the train–test splits used in [63, 61] and report the dataset statistics in Table 6. Table 6: Dataset Statistics. Domain Dataset #...
2024
-
[67]
The implementation is from [64] 2
CoT.It prompts an agent to decompose reasoning into sequential steps instead of producing direct answers. The implementation is from [64] 2
-
[68]
SC (CoT×5).To improve robustness, we aggregate five CoT-generated solutions, following the approach in [63, 61]
-
[69]
We allow up to five refinement iterations3
Self-Refine.It first generates an answer using CoT reasoning and then prompts the agent to iteratively self-reflect. We allow up to five refinement iterations3
-
[70]
We use the implementation from [45] 4
MultiPersona.It transforms a single LLM into multiple dynamic personas via multi-turn self-collaboration to enhance problem-solving. We use the implementation from [45] 4
-
[71]
LLM-Debate.Following [ 61], we assign five LLM agents with distinct roles to engage in up to two rounds of debate, and the final decision is made through majority voting 5
-
[72]
We use the implementation from [22] 6
DyLAN.It is a framework that dynamically selects and coordinates a team of LLM-powered agents for diverse tasks. We use the implementation from [22] 6
-
[73]
8.GPTSwarm.It is implemented following the original settings described in [66] 8
Plan-and-Execute.The LangChain blog presents plan-and-execute agents that separate planning from execution to improve multi-step workflow efficiency and reduce LLM costs7. 8.GPTSwarm.It is implemented following the original settings described in [66] 8
-
[74]
We use the implementation from [14] 9
ADAS.It introduces a Meta Agent Search to iteratively program new agents based on an ever- growing archive of previous discoveries. We use the implementation from [14] 9
-
[75]
AgentSquare.Following [ 61], we adopt the modular search framework from [34] 10, using early stopping with a patience of five iterations
-
[76]
AFlow.We adopt the implementation from [ 63] 11, with the maximum number of iterations set to 20 following [61]
-
[77]
I”), it is executed incorrectly because the agent checks whether a sentence starts with the character “I
MaAS.It optimizes a probabilistic supernet of agentic architectures to dynamically sample query-specific multi-agent systems. We use the official implementation from [61] 12. 2https://github.com/amazon-science/auto-cot 3https://github.com/madaan/self-refine 4https://github.com/MikeWangWZHL/Solo-Performance-Prompting 5https://github.com/composable-models/l...
-
[78]
We are given the conditions x≥2andy≥5
Restatement of the Problem We have a deck of 54 cards, and we want to deal all of the cards toxplayers, with each player receiving y cards. We are given the conditions x≥2andy≥5. We need to determine how many possible values ofxsatisfy these conditions
-
[79]
The total number of cards dealt can be expressed as:x×y= 54
Explanation of Mathematical Concepts To solve this problem, we need to understand the relationship between the total number of cards, the number of players, and the number of cards each player receives. The total number of cards dealt can be expressed as:x×y= 54. We can derive the possible values forxby first expressingyin terms ofx:y= 54 x
-
[80]
Detailed Steps to the Solution
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.