Recognition: unknown
KAST-BAR: Knowledge-Anchored Semantically-Dynamic Topology Brain Autoregressive Modeling for Universal Neural Interpretation
Pith reviewed 2026-05-14 19:23 UTC · model grok-4.3
The pith
KAST-BAR builds an EEG foundation model that aligns brain signals with medical knowledge using dynamic topology modeling and achieves better results on six tasks.
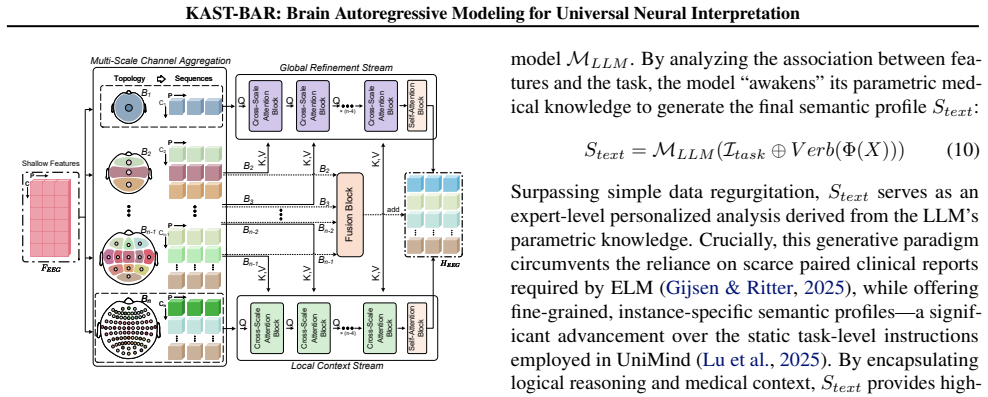
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
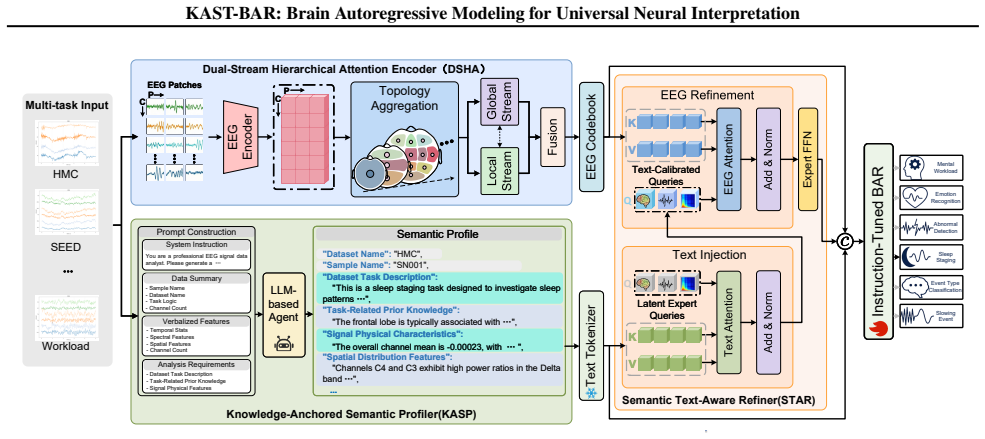
KAST-BAR dynamically aligns physiological representations from multi-level brain topology with an expert-level semantic space through its Dual-Stream Hierarchical Attention encoder that models local temporal dynamics alongside global spatial contexts, a Knowledge-Anchored Semantic Profiler that synthesizes physically-grounded textual profiles, and a Semantic Text-Aware Refiner that reconstructs EEG representations using Latent Expert Queries. After pre-training on 21 diverse datasets, the model integrates expert medical knowledge into EEG signals and delivers superior performance across six downstream tasks.
What carries the argument
Dual-Stream Hierarchical Attention encoder combined with Knowledge-Anchored Semantic Profiler and Semantic Text-Aware Refiner to capture brain topology and align with semantic space.
Load-bearing premise
The proposed encoders and profilers accurately capture brain topology and align signals with semantics without introducing artifacts or overfitting to the training data.
What would settle it
Evaluating the model on an independent EEG dataset not included in the 21 pre-training sets and finding no performance advantage over prior methods would falsify the superiority claim.
Figures












read the original abstract
While EEG foundation models have shown significant potential in universal neural decoding across tasks, their advancement remains constrained by the inadequacy modeling of complex spatiotemporal topology, as well as the inherent modality gap between low-level physiological signals and high-level textual semantics. To address these challenges, we propose a Knowledge-Anchored Semantically-Dynamic Topology Brain Autoregressive Model (KAST-BAR), which dynamically aligns physiological representations derived from multi-level brain topology with an expert-level semantic space. Specifically, we design a Dual-Stream Hierarchical Attention (DSHA) encoder that accurately captures the brain's intrinsic non-Euclidean topology by modeling local temporal dynamics with global spatial contexts. On this basis, a Knowledge-Anchored Semantic Profiler (KASP) is proposed to synthesize physically-grounded and instance-level textual profiles, which subsequently drive a Semantic Text-Aware Refiner (STAR) to dynamically reconstruct EEG representations using Latent Expert Queries. By conducting large-scale pre-training on 21 diverse datasets to build a foundation model, KAST-BAR effectively integrates expert-level medical knowledge into EEG signal representations, consistently achieving superior performance across six downstream tasks. Our code is available at https://github.com/KAST-BAR/KAST-BAR
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes KAST-BAR, a brain autoregressive foundation model for EEG signals that integrates expert medical knowledge via three new modules: a Dual-Stream Hierarchical Attention (DSHA) encoder to capture non-Euclidean spatiotemporal topology, a Knowledge-Anchored Semantic Profiler (KASP) to generate instance-level textual profiles from physiological signals, and a Semantic Text-Aware Refiner (STAR) that uses latent expert queries to dynamically align low-level EEG representations with high-level semantics. The central claim is that large-scale pre-training on 21 diverse datasets produces a model that consistently outperforms prior approaches on six downstream tasks.
Significance. If the performance claims and knowledge-integration mechanism are substantiated with rigorous evidence, the work could advance EEG foundation modeling by explicitly bridging the modality gap between raw physiological signals and textual medical semantics, offering a template for knowledge-anchored autoregressive architectures in neural decoding.
major comments (2)
- [Abstract] Abstract: the claim of 'consistently achieving superior performance across six downstream tasks' after pre-training on 21 datasets is presented without any quantitative metrics, baseline comparisons, ablation results, or error analysis, so the data-to-claim link cannot be evaluated.
- [Method] Method description: no details are supplied on the training objective, the loss terms that enforce knowledge anchoring between DSHA/KASP/STAR, the exact composition or preprocessing of the 21 datasets, or how non-Euclidean topology is encoded, leaving open the possibility that reported gains arise from standard autoregressive pre-training rather than the claimed semantic alignment.
minor comments (2)
- [Abstract] Abstract: the sentence 'dynamically aligns physiological representations derived from multi-level brain topology with an expert-level semantic space' uses vague phrasing; specify the exact alignment mechanism and any regularization used to prevent overfitting.
- [Abstract] The GitHub link is provided but no reproducibility checklist or hyperparameter table appears in the manuscript; add these to support verification of the pre-training setup.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the opportunity to clarify our work. We address each major comment point-by-point below, agreeing that certain aspects of the presentation require strengthening for better evaluation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistently achieving superior performance across six downstream tasks' after pre-training on 21 datasets is presented without any quantitative metrics, baseline comparisons, ablation results, or error analysis, so the data-to-claim link cannot be evaluated.
Authors: We agree that the abstract is a high-level summary and lacks specific quantitative metrics, which limits immediate evaluation of the claims. The full manuscript provides these details in the Experiments section, including performance tables with baseline comparisons, ablation studies isolating the contribution of each module, and error analyses across tasks. To address the concern directly, we will revise the abstract to include key quantitative highlights such as average accuracy improvements and statistical significance over baselines. revision: yes
-
Referee: [Method] Method description: no details are supplied on the training objective, the loss terms that enforce knowledge anchoring between DSHA/KASP/STAR, the exact composition or preprocessing of the 21 datasets, or how non-Euclidean topology is encoded, leaving open the possibility that reported gains arise from standard autoregressive pre-training rather than the claimed semantic alignment.
Authors: We acknowledge that the current method description could be more explicit on these points to rule out alternative explanations for the gains. The manuscript describes the DSHA encoder for non-Euclidean topology via hierarchical graph attention in Section 3.1, the combined autoregressive and semantic alignment losses (including contrastive terms for KASP/STAR anchoring) in Section 3.3, and the 21 datasets with preprocessing in Table 1 and Appendix A. However, to strengthen the link to semantic alignment, we will add a dedicated subsection on the full training objective with explicit loss equations, move key dataset composition details into the main text, and include further ablations comparing against pure autoregressive baselines without the knowledge-anchoring components. revision: yes
Circularity Check
No circularity: empirical architecture proposal with standard pre-training results
full rationale
The paper proposes DSHA+KASP+STAR components to align EEG topology with textual semantics and reports superior downstream performance after pre-training on 21 datasets. No mathematical derivation chain, first-principles prediction, or fitted parameter renamed as output is present in the provided text. Claims rest on experimental outcomes rather than any self-referential reduction (e.g., no equation where a 'prediction' equals a training fit by construction, and no load-bearing self-citation of uniqueness theorems). This is a standard empirical foundation-model paper whose central results are externally falsifiable via the released code and datasets.
Axiom & Free-Parameter Ledger
free parameters (1)
- Model hyperparameters and training settings
axioms (2)
- domain assumption Brain signals possess intrinsic non-Euclidean spatiotemporal topology that hierarchical attention can accurately capture.
- domain assumption Physiological EEG representations can be aligned with expert-level textual semantics via knowledge-anchored profiling.
invented entities (3)
-
Dual-Stream Hierarchical Attention (DSHA) encoder
no independent evidence
-
Knowledge-Anchored Semantic Profiler (KASP)
no independent evidence
-
Semantic Text-Aware Refiner (STAR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
universal neural representations
doi: 10.1109/SPMB.2017.8257018. Wang, G., Liu, W., He, Y ., Xu, C., Ma, L., and Li, H. EEGPT: Pretrained transformer for universal and reli- able representation of EEG signals. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. Wang, J., Zhao, S., Luo, Z., Zhou, Y ., Jiang, H., Li, S., Li, T., and Pan, G. CBramod: A cris...
-
[2]
leverage Transformer architectures, treating EEG signals as flattened 1D sequences or 2D time-frequency images, and utilize Masked Autoencoder (MAE) or Autoregressive (AR) objectives to capture long-range dependencies. Although these methods have verified the Scaling Laws in neural data, they inherently neglect the non-Euclidean properties of brain signal...
work page 2026
-
[3]
Brain Topology Hierarchy (BTH) Specification: Adhering to the 5-scale BTH architecture in THD-BAR (Yang et al., 2025), we organize electrodes into a coarse-to-fine hierarchy (B1 →B 5) based on spatial proximity and anatomical divisions, as illustrated in Figure 7. Specifically,Level 1 (Whole Brain, B1)treats all channels as a single global unit to capture...
work page 2025
-
[4]
Detailed network architecture specifications are provided in Table 7
Vector Quantizer Configuration.We employ the standard VQ-V AE (Van Den Oord et al., 2017) mechanism to discretize the multi-channel continuous EEG signals output by the DSHA encoder. Detailed network architecture specifications are provided in Table 7
work page 2017
-
[5]
DSHA Structure: Dual-Stream Interaction Mechanism.Going beyond simple unidirectional multi-scale feature aggregation, DSHA adopts an explicitBidirectional Progressive Interaction Strategyto address the dilution of local details or the absence of global context. Specifically, the model maintains two parallel processing streams: • Global Refinement Stream:I...
-
[6]
KASP Feature Operators ( Φ): Mathematical Formulation and Rationale.The KASP module utilizes a set of deterministic operators to extract robust physical features. Based on the logic defined in the main text, the detailed formulations are as follows: • Temporal Statistical Operator (ϕstat):Corresponding to the signal amplitude distribution modeling mention...
-
[7]
STAR: Construction Logic and Design PhilosophyThe design of the Semantic Text-Aware Refiner (STAR) is rooted in the cognitive principle of“Active Perception”. • Why use “Latent Experts”?EEG data streams are variable in length and extremely long, whereas LLMs require condensed inputs of fixed length. We initialize a fixed set of learnable vectors (Qlat) to...
-
[8]
The model is trained using the AdamW optimizer ( lr= 5e −5) with a batch size of 128 for 50 epochs
Stage 1: Self-Supervised Reconstruction Configuration.We adopt a patch size of 200 (corresponding to 1 second). The model is trained using the AdamW optimizer ( lr= 5e −5) with a batch size of 128 for 50 epochs. Detailed model hyperparameters and training configurations are presented in Table 7. As shown in Figure 10(b), the training losses converge withi...
-
[9]
Stage 2: Joint Autoregressive Pre-training Configuration.We construct the hybrid sequence S input to the BAR model using the following format: [BOS] KASP_Profile (S text) [SEP] STAR_Summary (S sem) [SEP] EEG_Tokens (SEEG ) [EOS] . This explicit separation ensures that the LLM can distinguish between the static knowledge context and dynamic signal tokens. ...
-
[10]
Multi-task Instruction Tuning Strategy.To adapt the foundation model to specific downstream tasks while mitigating catastrophic forgetting, we employ aDecoupled Update Strategy: • Adapter Decoupling:We freeze the pre-trained LoRA adapter or merge it into the backbone, and initialize a new, task-specific LoRA adapter for the Supervised Fine-Tuning (SFT) st...
-
[11]
Hyperparameter Configuration.Table 9 summarizes the hyperparameters used for downstream fine-tuning in detail. Compared to pre-training, we use a smaller global Batch Size (64) to accommodate the GPU memory overhead of task- specific gradients. A cosine learning rate schedule with a warm-up ratio of 0.1 is adopted to stabilize the initial adaptation proce...
-
[12]
Training Dynamics and Loss Curves.Figure 10(c) illustrates the training dynamics during the SFT stage. The training loss exhibits a rapid decline within the first 2-3 epochs, significantly faster than in the pre-training stage. This rapid convergence validates the efficacy of our pre-trained representations. Concurrently, the validation perplexity (dashed...
-
[13]
It effectively mitigates the bias introduced by skewed class distributions
Balanced Accuracy (B-Acc):B-Acc is defined as the arithmetic mean of the recall of the positive class and that of the negative class. It effectively mitigates the bias introduced by skewed class distributions. B-Acc= 1 2 T P T P+F N + T N T N+F P (22) whereT P, T N, F P,andF Ndenote True Positives, True Negatives, False Positives, and False Negatives, res...
-
[14]
Area Under the Receiver Operating Characteristic Curve (AUROC):AUROC quantifies the generalization ability of the model across all classification thresholds. It is calculated as the area under the curve plotting the True Positive Rate (TPR) against the False Positive Rate (FPR). The value ranges from 0.5 to 1, with a higher value indicating better discrim...
-
[15]
AUC-PR focuses specifically on the quality of positive predictions
Area Under the Precision-Recall Curve (AUC-PR):In scenarios with extreme class imbalance (where positive samples are rare), AUROC may overestimate performance. AUC-PR focuses specifically on the quality of positive predictions. It is the area under the curve plotting Precision against Recall. Precision= T P T P+F P ,Recall= T P T P+F N (23) Table 9.Hyperp...
-
[16]
Temporal Stats (ϕ stat): Mean 0.12, Std 14.5, Energy 250.4
-
[17]
Spectral Features (ϕ spec): Mean Peak Freq 2.5Hz, Delta Power 0.65
-
[18]
Spatial Features (ϕ spat): Channel T3 (Left Temporal) shows ... [Analysis Requirements] 1.Dataset Task Description: Describe the general experimental paradigm. 2.Task-Related Prior Knowledge: List relevant neuroscience background. 3.Signal Physical Features: Objectively describe time, frequency, and spatial features. [Output Format] Please respond strictl...
-
[19]
Balanced Accuracy (B-Acc):In the multi-class setting, B-Acc is defined as the macro-average of the recall scores for all classes. B-Acc= 1 C CX i=1 Recalli (24) whereCis the total number of classes, and Recall i is the recall for classi
-
[20]
Cohen’s Kappa Coefficient (κ):Cohen’s Kappa measures the agreement between the model’s predictions and the ground truth labels, correcting for agreement occurring by chance. κ= po −p e 1−p e (25) wherep o represents the observed agreement (accuracy), andp e is the expected agreement by chance
-
[21]
Weighted F1-Score (F1-W):To balance precision and recall while accounting for the support of each class, we employ the Weighted F1-Score. It is calculated as the weighted sum of per-class F1-scores, where the weight wi corresponds to the 23 KAST-BAR: Brain Autoregressive Modeling for Universal Neural Interpretation Table 10.Example of KASP-generated Seman...
work page 2018
-
[22]
Advantage of Cross-scale Feature Capture:CSBrain introduces a Cross-scale Spatiotemporal Tokenization (CST) mechanism, designed to explicitly aggregate local high-frequency transients and global low-frequency rhythms. For specific spectral anomalies in the TUSL task (such as slowing waves), this multi-scale inductive bias is more effective at precisely lo...
-
[23]
Negative Transfer in Multi-Task Learning:TUSL represents a highly specific clinical anomaly detection task, with a data distribution vastly different from tasks like emotion recognition or cognitive workload. In unified multi-task modeling, forcibly optimizing these semantically conflicting tasks simultaneously may introduce gradient interference, leading...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.