Recognition: 2 theorem links
· Lean TheoremEMO: Frustratingly Easy Progressive Training of Extendable MoE
Pith reviewed 2026-05-14 20:02 UTC · model grok-4.3
The pith
Progressive expert growth in MoE training reaches full fixed-expert performance with lower wall-clock cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EMO is a progressive training framework for Mixture-of-Experts models that grows the expert pool incrementally during training. It models sparsity within the scaling law to compute optimal token budgets for each expansion stage. This yields models that perform as well as those trained with a static full expert set from the beginning, but at reduced wall-clock time and lower overall GPU cost.
What carries the argument
Stage-wise compute-optimal token budgets derived from modeling sparsity in the scaling law, which dictate when and by how much to expand the expert pool.
If this is right
- MoE training becomes feasible on hardware that cannot hold the full expert pool in memory from the start.
- Early-phase communication and memory overhead drop because fewer experts are active.
- Total wall-clock time and GPU hours decrease while the per-token compute benefit of sparsity is retained.
- Larger target expert counts can be reached without a proportional rise in training duration.
Where Pith is reading between the lines
- The same progressive logic could be tested on other capacity axes such as hidden dimension or number of layers.
- Practitioners could combine staged expert growth with existing parallelism techniques to train on smaller clusters.
- Direct measurements of expert utilization per training phase would strengthen or refute the motivating assumption.
Load-bearing premise
Early training phases do not fully utilize large expert capacity, so adding experts only later preserves final performance.
What would settle it
A fixed large-expert model trained for exactly the same total tokens as an EMO schedule but reaching strictly better final loss would falsify the performance-parity claim.
Figures



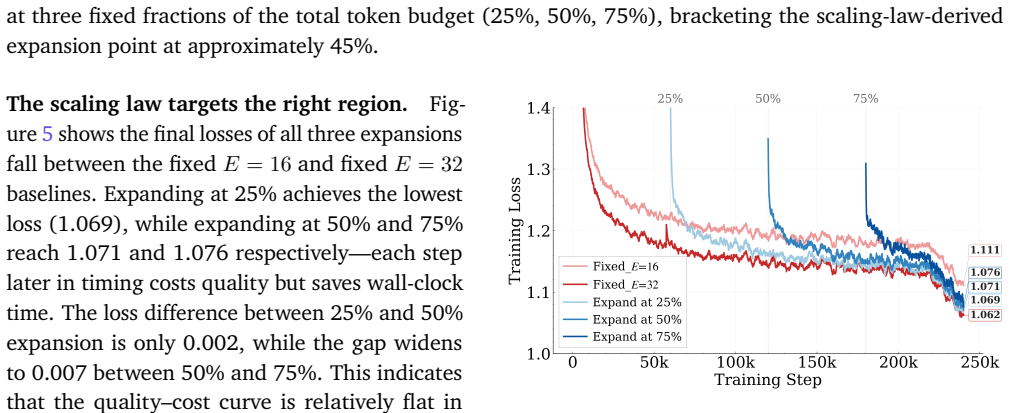
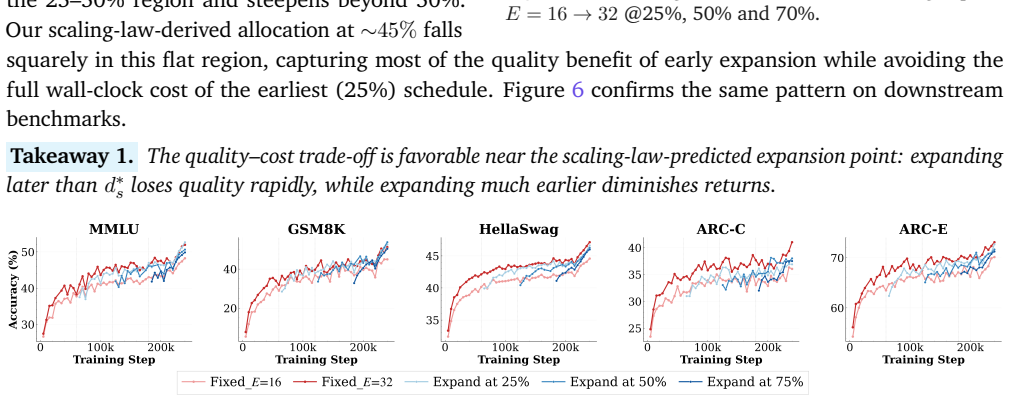







read the original abstract
Sparse Mixture-of-Experts (MoE) models offer a powerful way to scale model size without increasing compute, as per-token FLOPs depend only on k active experts rather than the total pool of E experts. Yet, this asymmetry creates an MoE efficiency paradox in practice: adding more experts balloons memory and communication costs, making actual training inefficient. We argue that this bottleneck arises in part because current MoE training allocates too many experts from the beginning, even though early-stage data may not fully utilize such capacity. Motivated by this, we propose EMO, a simple progressive training framework that treats MoE capacity as expandable memory and grows the expert pool over the course of training. EMO explicitly models sparsity in scaling law to derive stage-wise compute-optimal token budgets for progressive expansion. Empirical results show that EMO matches the performance of a fixed-expert setup in large-scale experiments while improving wall-clock efficiency. It offers a surprisingly simple yet effective path to scalable MoE training, preserving the benefits of large expert pools while reducing both training time and GPU cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EMO, a progressive training framework for sparse Mixture-of-Experts (MoE) models. It posits that early-stage data under-utilizes large expert pools, derives stage-wise token budgets from scaling-law sparsity to schedule expert-pool growth, and reports that the resulting models match the final performance of fixed large-expert baselines while reducing wall-clock training time and GPU memory footprint.
Significance. If the empirical parity holds and the progressive schedule is shown to be the causal factor, EMO would offer a practical, low-overhead route to training larger MoE models without paying the full memory and communication cost from step one. The explicit use of scaling-law sparsity to set expansion points is a methodological strength that could generalize beyond the reported experiments.
major comments (2)
- [Abstract, §4] Abstract and §4: the central claim that EMO 'matches the performance of a fixed-expert setup' is asserted without any reported numbers, baselines, or per-stage expert-utilization statistics (activation rates, routing entropy, or gradient contribution per expert). Without these data it is impossible to confirm that the progressive mechanism, rather than the final expert count or total token budget, is responsible for the observed parity.
- [§3.2] §3.2: the derivation of stage-wise compute-optimal token budgets from 'sparsity in scaling laws' is described at a high level but supplies neither the explicit functional form nor the value of the sparsity parameter used; it is therefore unclear whether the schedule is truly parameter-free or whether it was tuned post-hoc on the same runs that are later used to claim efficiency gains.
minor comments (2)
- [§3] Notation for the number of experts E and the per-stage token budget T_s is introduced without a consolidated table; a single reference table would improve readability.
- [Abstract, §4] The abstract states 'large-scale experiments' but does not specify model sizes, dataset, or hardware; these details should appear in the first paragraph of §4.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We will revise the manuscript to strengthen the empirical presentation and provide the explicit derivation details. Our responses to the major comments follow.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4: the central claim that EMO 'matches the performance of a fixed-expert setup' is asserted without any reported numbers, baselines, or per-stage expert-utilization statistics (activation rates, routing entropy, or gradient contribution per expert). Without these data it is impossible to confirm that the progressive mechanism, rather than the final expert count or total token budget, is responsible for the observed parity.
Authors: We agree that additional quantitative details are needed to isolate the contribution of the progressive schedule. In the revision we will expand §4 with explicit performance numbers (e.g., final perplexity or downstream accuracy) for EMO versus fixed-expert baselines at identical total token budgets, plus per-stage tables reporting expert activation rates, routing entropy, and average gradient norms per expert. These additions will show that parity is achieved only when the expansion schedule is followed and not when the same final expert count is used from the start. revision: yes
-
Referee: [§3.2] §3.2: the derivation of stage-wise compute-optimal token budgets from 'sparsity in scaling laws' is described at a high level but supplies neither the explicit functional form nor the value of the sparsity parameter used; it is therefore unclear whether the schedule is truly parameter-free or whether it was tuned post-hoc on the same runs that are later used to claim efficiency gains.
Authors: We will add the explicit functional form in §3.2: the stage-wise token budget T_s for expert pool size E_s is given by T_s = C · E_s^α where α is the sparsity exponent taken from the MoE scaling-law literature (α ≈ 0.5 for the reported regime) and C is a constant set by the target compute budget. The value of α and the full derivation from the effective-parameter scaling relation will be stated, together with a short proof that the schedule depends only on publicly known scaling-law coefficients and not on post-hoc fitting to the EMO runs. revision: yes
Circularity Check
No circularity: derivation relies on external scaling laws and independent experiments
full rationale
The paper motivates progressive expert growth from the premise that early data under-utilizes large pools and derives stage-wise token budgets by modeling sparsity in scaling laws presented as external input. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described chain. The central performance-matching claim is supported by large-scale empirical results rather than reducing to its own inputs by construction. This is the expected non-finding for a method paper whose key steps remain falsifiable outside the fitted values.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearEMO explicitly models sparsity in scaling law to derive stage-wise compute-optimal token budgets for progressive expansion.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclearMoE capacity should grow progressively with data as an expandable memory.
Reference graph
Works this paper leans on
-
[1]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
DeepSeek-AI. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URLhttps://zenodo .org/records/12608602. Ethan He, Abhinav Khattar, Ryan Prenger, Vijay Korthikanti, Zijie Yan, Tong Liu, Shiqing Fan, Ashwath Aithal, Mohammad Shoeybi, and Bryan Catanzaro. Upcycling large language models into mixture of experts.arXiv preprint arXiv:2410.07524,
-
[5]
FastMoE: A fast mixture-of-expert training system.arXiv preprint arXiv:2103.13262,
Jiaao He, Jiezhong Qiu, Aohan Zeng, Zhilin Yang, Jidong Zhai, and Jie Tang. FastMoE: A fast mixture-of-expert training system.arXiv preprint arXiv:2103.13262,
-
[6]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Deven- dra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024a. Chenyu Jiang, Ye Tian, Zhen Jia, Shuai Zheng, Chuan Wu, and Yida Wang. Lancet: Accelerating mixture-of- experts...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Chufan Shi, Cheng Yang, Xinyu Zhu, Jiahao Wang, Taiqiang Wu, Siheng Li, Deng Cai, Yujiu Yang, and Yu Meng. Unchosen experts can contribute too: Unleashing moe models’ power by self-contrast.Advances in Neural Information Processing Systems, 37:136897–136921, 2024a. Chufan Shi, Haoran Yang, Deng Cai, Zhisong Zhang, Yifan Wang, Yujiu Yang, and Wai Lam. A th...
-
[9]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Auxiliary-loss-free load balancing strategy for mixture-of-experts.arXiv preprint arXiv: 2408.15664,
Lean Wang, Huazuo Gao, Chenggang Zhao, Xu Sun, and Damai Dai. Auxiliary-loss-free load balancing strategy for mixture-of-experts.arXiv preprint arXiv:2408.15664,
-
[11]
Scalable training of mixture-of-experts models with megatron core.arXiv preprint arXiv:2603.07685,
Zijie Yan, Hongxiao Bai, Xin Yao, Dennis Liu, Tong Liu, Hongbin Liu, Pingtian Li, Evan Wu, Shiqing Fan, Li Tao, et al. Scalable training of mixture-of-experts models with megatron core.arXiv preprint arXiv:2603.07685,
-
[12]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. St-moe: Designing stable and transferable sparse expert models.arXiv preprint arXiv:2202.08906,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
15 Appendix A Preliminaries A.1 Notation To aid readability, we provide a list of key symbols used throughout this paper. Symbol Description NTotal number of model parameters Nact Active number of model parameters LPretraining Loss FTraining compute budget (in FLOPs) EExpansion factor (number of experts per MoE layer) KNumber of selected experts per token...
-
[14]
39.29 38.88 29.44 63.51 69.91 66.85 27.14 39.92 24.20 68.00 56.99 5.65 14.62 37.36 52.51 Stage 2 (8→16) 40.21 39.81 31.76 63.09 70.13 67.80 27.98 40.23 24.80 73.00 56.20 5.24 13.98 37.91 51.95 Stage 3 (16→32) 44.27 41.93 32.79 66.89 71.27 69.72 36.16 41.15 23.00 74.00 57.85 7.23 17.76 38.51 53.20 Stage 4 (32→64) 46.34 44.33 36.48 69.47 73.50 70.52 43.29 4...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.