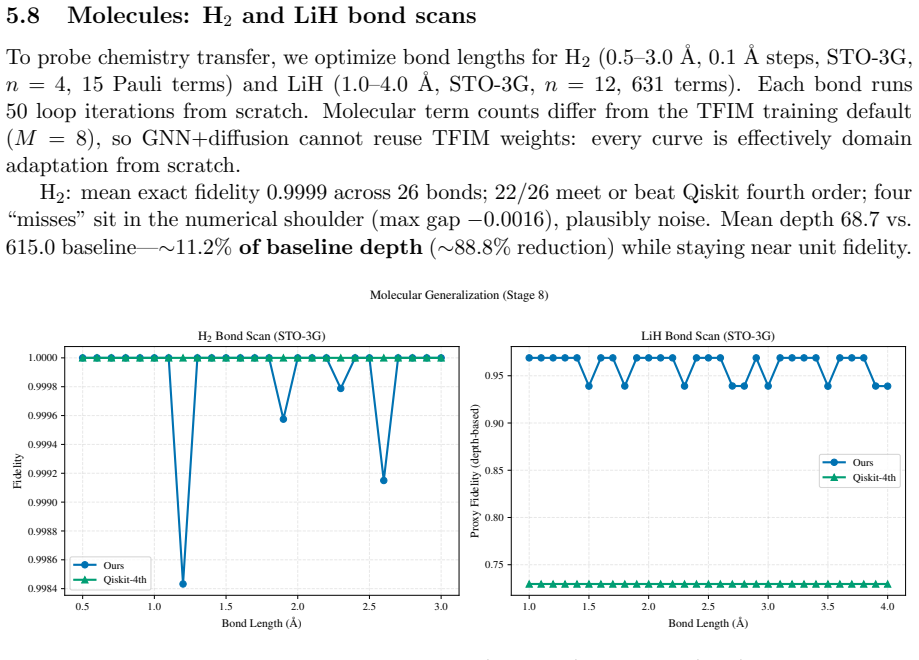
Recognition: no theorem link
Physics Guided Generative Optimization for Trotter Suzuki Decomposition
Pith reviewed 2026-05-14 18:36 UTC · model grok-4.3
The pith
A conditional diffusion model guided by physics-informed fidelity feedback produces Trotter-Suzuki decompositions that reach 85.6 percent of fourth-order baseline accuracy at 22 percent circuit depth on the transverse Ising model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a hybrid optimization loop combining a conditional diffusion model for proposing decomposition strategies, a physics-informed neural network for differentiable fidelity supervision, and a graph neural network for commutator encoding can generate Trotter-Suzuki product formulas whose accuracy-to-depth trade-off on the transverse field Ising model substantially exceeds that of hand-tuned baselines such as fourth-order Qiskit.
What carries the argument
The generate-and-evaluate loop that uses a conditional diffusion model to sample hybrid discrete-continuous decomposition strategies, guided by fidelity gradients from a physics-informed neural network and commutator structure from a graph neural network, trained via REINFORCE with Pareto tracking.
If this is right
- Shallow circuits become practical for Hamiltonian simulation on NISQ hardware without sacrificing most of the target accuracy.
- Manual heuristics for term grouping and order selection can be replaced by automated search under a fixed training budget.
- Explicit Pareto control allows users to trade depth for fidelity according to hardware limits.
- Fine-tuning inside the loop can push performance near unity when depth is not the binding constraint.
- The same supervision signal may transfer to other Hamiltonians whose commutator graphs are similar.
Where Pith is reading between the lines
- If the PINN fidelity predictor remains accurate for larger or non-Ising Hamiltonians, the method could automate compilation for models where exhaustive search is impossible.
- The loop could be extended to incorporate device-specific noise models directly into the physics-informed feedback.
- Combining the diffusion proposer with other generative architectures might lower the data or compute needed for training.
- The same generate-evaluate pattern might apply to other discrete-continuous compilation problems such as gate scheduling or ansatz design.
Load-bearing premise
The physics-informed neural network must continue to give reliable differentiable fidelity estimates across the discrete groupings and formula orders that the diffusion model explores during training.
What would settle it
Run the reported optimized decompositions on the transverse field Ising model and check whether they achieve at least 0.85 fidelity at the stated 21.8 percent depth and 19.2 percent CNOT reduction relative to the fourth-order Qiskit baseline.
Figures






read the original abstract
Product formulas for Trotter Suzuki simulation remain a practical route to Hamiltonian evolution on noisy intermediate scale quantum (NISQ) hardware, yet their accuracy hinges on three coupled choices: term grouping, product formula order, and timestep allocation. Toolchains such as Qiskit and Paulihedral lean on hand tuned heuristics, while the discrete nature of grouping and order makes naive gradient based optimization awkward. We describe a generate and evaluate loop: a conditional diffusion model proposes strategies, a physics informed neural network (PINN) supplies differentiable fidelity feedback, and a graph neural network (GNN) encodes commutator structure. Training spans a hybrid space (discrete grouping and order, continuous time steps); the closed loop uses REINFORCE and a Pareto tracker. On the transverse field Ising model (TFIM), under our primary comparison setup, the method reaches 85.6% of the fidelity of a fourth order Qiskit baseline (0.856) at roughly 21.8% of the circuit depth and 19.2% of the baseline CNOT count. Under an equal depth budget, fine tuning in the loop reached a best observed fidelity of 0.9994. Updated ablations show that, for a fixed training budget and default guidance knobs, module contributions depend on the training recipe and guidance hyperparameters CFG in particular needs to be tuned jointly with compute budget. Overall, the results suggest that "generative model and physics supervision" is a viable angle for NISQ oriented compilation, though where it wins still depends on the operating point.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a generate-and-evaluate framework for optimizing Trotter-Suzuki decompositions that combines a conditional diffusion model to propose discrete groupings and orders together with continuous timesteps, a physics-informed neural network (PINN) to supply differentiable fidelity feedback, and a graph neural network (GNN) to encode commutator structure. Training proceeds via a closed REINFORCE loop with a Pareto tracker. On the transverse-field Ising model the method is reported to reach 85.6 % of the fidelity of a fourth-order Qiskit baseline at 21.8 % circuit depth and 19.2 % CNOT count, with equal-depth fine-tuning attaining a best observed fidelity of 0.9994.
Significance. If the PINN surrogate remains accurate for the discrete structural choices explored by the diffusion model and the learned strategies generalize, the approach would constitute a viable data-driven alternative to hand-tuned heuristics for NISQ-oriented product-formula compilation. The hybrid discrete-continuous generative optimization and the explicit use of physics supervision are technically interesting and could be extended to other Hamiltonian simulation tasks.
major comments (2)
- [Results on TFIM and ablation studies] The headline performance figures (85.6 % relative fidelity at reduced depth, 0.9994 under equal-depth fine-tuning) are obtained from a closed REINFORCE loop whose reward is the PINN fidelity estimate. No section reports a held-out validation of this estimate against exact Trotter fidelity (or high-fidelity reference simulation) across the discrete grouping and order axes that the diffusion model explores. Without this check the optimizer may exploit surrogate artifacts rather than genuine improvements.
- [Abstract and experimental results] The abstract and results claim concrete fidelity and resource numbers (0.856 relative fidelity, 21.8 % depth, 19.2 % CNOT) yet provide neither error bars nor a description of the training-data distribution over Hamiltonian instances and hyper-parameters. This omission makes it impossible to assess the statistical reliability of the reported gains.
minor comments (2)
- [Ablation studies] The updated ablations note that module contributions depend on training recipe and CFG guidance scale, but the manuscript does not quantify how these dependencies affect generalization beyond the specific TFIM instances used.
- [Methods] Notation for the conditional diffusion model, the PINN architecture, and the GNN commutator encoder should be introduced with explicit equations or diagrams to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and indicate the revisions that will be incorporated in the updated version.
read point-by-point responses
-
Referee: [Results on TFIM and ablation studies] The headline performance figures (85.6 % relative fidelity at reduced depth, 0.9994 under equal-depth fine-tuning) are obtained from a closed REINFORCE loop whose reward is the PINN fidelity estimate. No section reports a held-out validation of this estimate against exact Trotter fidelity (or high-fidelity reference simulation) across the discrete grouping and order axes that the diffusion model explores. Without this check the optimizer may exploit surrogate artifacts rather than genuine improvements.
Authors: We agree that the absence of an explicit held-out validation of the PINN surrogate against exact fidelity on the discrete structural choices is a limitation that should be addressed. The current manuscript uses the PINN reward inside the closed training loop but does not report an independent comparison on held-out configurations. In the revised manuscript we will add a dedicated subsection that computes exact Trotter fidelities (via direct high-fidelity simulation) for 500 held-out discrete groupings and orders sampled from the diffusion model and reports the correlation with the PINN estimates. revision: yes
-
Referee: [Abstract and experimental results] The abstract and results claim concrete fidelity and resource numbers (0.856 relative fidelity, 21.8 % depth, 19.2 % CNOT) yet provide neither error bars nor a description of the training-data distribution over Hamiltonian instances and hyper-parameters. This omission makes it impossible to assess the statistical reliability of the reported gains.
Authors: We acknowledge that the abstract and main results section lack error bars and a clear description of the training-data distribution. The revised manuscript will include error bars obtained from five independent training runs with different random seeds. We will also expand the experimental setup to specify the distribution of TFIM instances (system sizes, transverse-field ranges) and the hyper-parameter sampling procedure used during training. revision: yes
Circularity Check
No significant circularity in claimed results or optimization chain
full rationale
The paper presents an empirical generative optimization pipeline (diffusion model proposals + PINN surrogate fidelity + GNN commutator encoding + REINFORCE loop) whose outputs are evaluated on TFIM instances. The headline metrics (85.6 % of Qiskit-4 fidelity at 21.8 % depth, 0.9994 under equal-depth fine-tuning) are stated as measured fidelities of the produced decompositions, not as quantities defined or fitted inside the surrogate itself. No equation, self-citation, or ansatz reduces the reported performance to a tautological re-expression of the training objective; the PINN is used only for differentiable guidance during search, while final numbers are presented as independent evaluations. No uniqueness theorem, renaming of known patterns, or load-bearing self-citation appears in the abstract or described method. The chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- CFG guidance scale
axioms (1)
- domain assumption The physics-informed neural network provides a faithful differentiable proxy for Trotter-Suzuki fidelity across the explored grouping and order space.
Reference graph
Works this paper leans on
-
[1]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces. InAdvances in Neural In- formation Processing Systems (NeurIPS), volume 34, pages 17981–17993, 2021
2021
-
[2]
Dominic W. Berry, Andrew M. Childs, Richard Cleve, Robin Kothari, and Rolando D. Somma. Simulating hamiltonian dynamics with a truncated taylor series.Physical Review Letters, 114(9):090502, 2015. doi: 10.1103/PhysRevLett.114.090502
-
[3]
Kottmann, Tim Menke, Wai-Keong Mok, Sukin Sim, Leong-Chuan Kwek, and Al´ an Aspuru-Guzik
Kishor Bharti, Alba Cervera-Lierta, Thi Ha Kyaw, Tobias Haug, Sumner Alperin-Lea, Abhinav Anand, Matthias Degroote, Hermanni Heimonen, Jakob S. Kottmann, Tim Menke, Wai-Keong Mok, Sukin Sim, Leong-Chuan Kwek, and Al´ an Aspuru-Guzik. Noisy intermediate-scale quantum algorithms.Reviews of Modern Physics, 94(1):015004, 2022. doi: 10.1103/RevModPhys.94.015004
-
[4]
Theory of Trotter error with commutator scaling,
Andrew M. Childs, Yuan Su, Minh C. Tran, Nathan Wiebe, and Shuchen Zhu. Theory of Trotter error with commutator scaling.Physical Review X, 11(1):011020, 2021. doi: 10.1103/PhysRevX.11.011020
-
[5]
Ophelia Crawford, Barnaby van Straaten, Daochen Wang, Thomas Parks, Earl Campbell, and Stephen Brierley. Efficient quantum measurement of Pauli operators in the presence of finite sampling error.Quantum, 5:385, 2021. doi: 10.22331/q-2021-01-20-385
-
[6]
Salvatore Cuomo, Vincenzo Schiano Di Cola, Fabio Giampaolo, Gianluigi Rozza, Maziar Raissi, and Francesco Piccialli. Scientific machine learning through physics-informed neural networks: where we are and what’s next.Journal of Scientific Computing, 92(3):88, 2022. doi: 10.1007/s10915-022-01939-z
-
[7]
Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, and T. Meyarivan. A fast and elitist mul- tiobjective genetic algorithm: NSGA-II.IEEE Transactions on Evolutionary Computation, 6(2):182–197, 2002. doi: 10.1109/4235.996017. 17
-
[8]
Phoenix: Pauli-based high-level opti- mization engine for instruction execution on NISQ devices.arXiv preprint, 2025
Zeyuan Feng, Zhen Xie, Yufei Shi, and Gushu Li. Phoenix: Pauli-based high-level opti- mization engine for instruction execution on NISQ devices.arXiv preprint, 2025
2025
-
[9]
Quantum circuit optimization with deep reinforcement learning.arXiv preprint arXiv:2103.07585, 2021
Thomas F¨ osel, Murphy Yuezhen Niu, Florian Marquardt, and Li Li. Quantum circuit optimization with deep reinforcement learning.arXiv preprint arXiv:2103.07585, 2021
-
[10]
Schoenholz, Patrick F
Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, and George E. Dahl. Neural message passing for quantum chemistry. InProceedings of the 34th International Conference on Machine Learning (ICML), pages 1263–1272, 2017
2017
-
[11]
Pranav Gokhale, Olivia Angiuli, Yongshan Ding, Kaiwen Gui, Teague Tomesh, Martin Suchara, Margaret Martonosi, and Frederic T. Chong. Optimization of simultaneous mea- surement for variational quantum eigensolver applications. In2020 IEEE International Conference on Quantum Computing and Engineering (QCE), pages 379–390, 2020. doi: 10.1109/QCE49297.2020.00054
-
[12]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 6840– 6851, 2020
2020
-
[14]
Equivariant diffusion for molecule generation in 3D
Emiel Hoogeboom, V´ ıctor Garcia Satorras, Cl´ ement Vignac, and Max Welling. Equivariant diffusion for molecule generation in 3D. InProceedings of the 39th International Conference on Machine Learning (ICML), pages 8867–8887, 2022
2022
-
[15]
Wood, Jake Lishman, Julien Gacon, Simon Martiel, Paul D
Ali Javadi-Abhari, Matthew Treinish, Kevin Krsulich, Christopher J. Wood, Jake Lishman, Julien Gacon, Simon Martiel, Paul D. Nation, Lev S. Bishop, Andrew W. Cross, Blake R. Johnson, and Jay M. Gambetta. Quantum computing with Qiskit.arXiv preprint, 2024
2024
-
[16]
Tetris: re- architecting convolutional neural network computation for machine learning accelerators
Sung-Min Jin, Yi-Lin Liu, Yuan Su, Cheng Liang, Jian Tan, and Songhua Lu. Tetris: re- architecting convolutional neural network computation for machine learning accelerators. In Proceedings of the 50th Annual International Symposium on Computer Architecture (ISCA), pages 1–14, 2023
2023
-
[17]
Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang
George Em Karniadakis, Ioannis G. Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021. doi: 10.1038/s42254-021-00314-5
-
[18]
Gushu Li, Yufei Shi, and Ali Javadi-Abhari. Paulihedral: a generalized block-wise com- piler optimization framework for quantum simulation kernels. InProceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), pages 554–569, 2022. doi: 10.1145/3503222.3507715
-
[19]
Lorenzo Moro, Matteo G. A. Paris, Marcello Restelli, and Enrico Prati. Quantum compiling by deep reinforcement learning.Communications Physics, 4(1):178, 2021. doi: 10.1038/ s42005-021-00684-3
2021
-
[20]
Quantum Computing in the NISQ era and beyond.Quantum, 2:79, August 2018
John Preskill. Quantum computing in the NISQ era and beyond.Quantum, 2:79, 2018. doi: 10.22331/q-2018-08-06-79
work page internal anchor Pith review doi:10.22331/q-2018-08-06-79 2018
-
[21]
Maziar Raissi, Paris Perdikaris, and George Em Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707,
-
[22]
doi: 10.1016/j.jcp.2018.10.045. 18
-
[23]
E(n) equivariant graph neural networks
V´ ıctor Garcia Satorras, Emiel Hoogeboom, and Max Welling. E(n) equivariant graph neural networks. InProceedings of the 38th International Conference on Machine Learning (ICML), pages 9323–9332, 2021
2021
-
[24]
Sch¨ utt, Huziel E
Kristof T. Sch¨ utt, Huziel E. Sauceda, Pieter-Jan Kindermans, Alexandre Tkatchenko, and Klaus-Robert M¨ uller. SchNet: A continuous-filter convolutional neural network for modeling quantum interactions. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30, 2017
2017
-
[25]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[26]
Masuo Suzuki. General theory of fractal path integrals with applications to many-body theories and statistical physics.Journal of Mathematical Physics, 32(2):400–407, 1991. doi: 10.1063/1.529425
-
[27]
Fourier features let networks learn high frequency functions in low dimensional domains
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 7537–7547, 2020
2020
-
[28]
Tran, Yuan Su, Daniel Carney, and Jacob M
Minh C. Tran, Yuan Su, Daniel Carney, and Jacob M. Taylor. Faster digital quantum simulation by symmetry protection.PRX Quantum, 2(1):010323, 2021. doi: 10.1103/ PRXQuantum.2.010323
2021
-
[29]
Quantum graph neural networks.arXiv preprint arXiv:1909.12264,
Guillaume Verdon, Trevor McCourt, Enxhell Luzhnica, Vikash Singh, Stefan Leichenauer, and Jack Hidary. Quantum graph neural networks.arXiv preprint arXiv:1909.12264, 2019
-
[30]
Vladyslav Verteletskyi, Tzu-Ching Yen, and Artur F. Izmaylov. Measurement optimization in the variational quantum eigensolver using a minimum clique cover.The Journal of Chemical Physics, 152(12):124114, 2020. doi: 10.1063/1.5141458
-
[31]
Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why PINNs fail to train: A neural tangent kernel perspective.Journal of Computational Physics, 449:110768, 2022. doi: 10.1016/j.jcp.2021.110768
-
[32]
Lyndon While, Lucas Bradstreet, and Luigi Barone. A fast way of calculating exact hy- pervolumes.IEEE Transactions on Evolutionary Computation, 16(1):86–95, 2012. doi: 10.1109/TEVC.2010.2077298
-
[33]
Berry, Peter Høyer, and Barry C
Nathan Wiebe, Dominic W. Berry, Peter Høyer, and Barry C. Sanders. Higher order decompositions of ordered operator exponentials.Journal of Physics A: Mathematical and Theoretical, 43(6):065203, 2010. doi: 10.1088/1751-8113/43/6/065203
-
[34]
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist rein- forcement learning.Machine Learning, 8:229–256, 1992. doi: 10.1007/BF00992696
-
[35]
Fonseca, and Viviane Grunert da Fonseca
Eckart Zitzler, Lothar Thiele, Marco Laumanns, Carlos M. Fonseca, and Viviane Grunert da Fonseca. Performance assessment of multiobjective optimizers: an analysis and review. IEEE Transactions on Evolutionary Computation, 7(2):117–132, 2003. doi: 10.1109/TEVC. 2003.810758. 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.