Recognition: unknown
GeoFlowVLM: Geometry-Aware Joint Uncertainty for Frozen Vision-Language Embedding
Pith reviewed 2026-05-14 20:40 UTC · model grok-4.3
The pith
A single masked velocity field on paired hyperspherical embeddings yields valid joint and conditional Riemannian flows for uncertainty in frozen vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a single masked velocity field trained by Riemannian flow matching on the joint distribution of paired l2-normalized embeddings on S^{d-1} x S^{d-1} recovers, in the population limit, valid Riemannian flow-matching velocity fields on the joint domain and on each conditional domain; the resulting conditional entropy supplies a decision-theoretically interpretable aleatoric score via a Fano-type bound, while the marginal-typicality score follows from an exact decomposition that isolates the structurally discriminative cross-modal pointwise mutual information term.
What carries the argument
A single masked velocity field trained via Riemannian flow matching on the product hypersphere
If this is right
- The conditional entropy provides a calibrated measure of aleatoric ambiguity that can be used to rank retrieval candidates by expected information gain.
- The marginal-typicality score isolates epistemic uncertainty after subtracting the cross-modal pointwise mutual information term, enabling selective prediction that improves accuracy.
- The cross-modal pointwise mutual information term alone is empirically uninformative for either uncertainty type and should be discarded in downstream decisions.
- Both derived scores can be computed from one forward pass of the trained velocity field without retraining the original vision-language encoders.
Where Pith is reading between the lines
- The same masked-field construction could be tested on other product manifolds arising from paired embeddings in different modalities.
- If the consistency result extends to finite samples, the method might serve as a lightweight calibration layer for any frozen dual-encoder system without requiring architectural changes.
- Selective accuracy gains observed on zero-shot tasks suggest the typicality score could be combined with existing outlier detectors to reduce false positives in deployed vision-language pipelines.
Load-bearing premise
That training a single masked velocity field on finite paired data will produce conditional and marginal distributions whose derived entropy and typicality scores remain calibrated on real retrieval and classification benchmarks.
What would settle it
Observation that the conditional retrieval entropy fails to track Recall@1 monotonically across the three reported retrieval benchmarks in either direction, or that marginal-typicality-based selective accuracy is no better than random selection on the four zero-shot classification benchmarks.
Figures







read the original abstract
Standard dual-encoder vision-language models that map images and text to deterministic points on a shared unit hypersphere through $\ell_2$ normalization typically expose neither \emph{aleatoric} uncertainty (cross-modal ambiguity) nor \emph{epistemic} uncertainty (lack of training-distribution support). Existing post-hoc methods either recover at most one of the two uncertainty components, or ignore the hyperspherical geometry of these models' embeddings. We propose \textbf{GeoFlowVLM} as a post-hoc adapter that learns the joint distribution of paired $\ell_2$-normalised dual-encoder VLM embeddings on the product hypersphere $\mathbb{S}^{d-1} \times \mathbb{S}^{d-1}$ via Riemannian flow matching with a single masked velocity field. A consistency result shows that, in the population limit, the trained network exposes the joint flow and both cross-modal conditional flows as valid Riemannian flow-matching velocity fields on their respective domains. We derive two quantities from this single model: a conditional retrieval entropy that quantifies aleatoric ambiguity with a decision-theoretic interpretation via a Fano-type bound, and a marginal-typicality epistemic score justified by an exact chain-rule decomposition of the joint NLL. This decomposition isolates a cross-modal pointwise-mutual-information term that is structurally discriminative rather than epistemic, and is empirically the only consistently uninformative standalone component. Empirically, the entropy tracks Recall@1 with near-ideal monotonic calibration across three retrieval benchmarks in both directions, and the marginal-typicality sum yields consistently calibrated selective accuracy across four zero-shot classification benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GeoFlowVLM, a post-hoc adapter for frozen dual-encoder VLMs. It models the joint distribution of paired ℓ₂-normalized embeddings on the product hypersphere S^{d-1} × S^{d-1} via Riemannian flow matching using a single masked velocity field. A population-limit consistency result is asserted, under which the trained network yields valid RFM velocity fields for the joint distribution and both cross-modal conditionals. Two derived quantities are introduced: a conditional retrieval entropy (aleatoric uncertainty, with Fano-type decision-theoretic interpretation) and a marginal-typicality epistemic score obtained from an exact chain-rule decomposition of the joint negative log-likelihood. Experiments report that the entropy tracks Recall@1 monotonically across three retrieval benchmarks and that the typicality score produces calibrated selective accuracy on four zero-shot classification benchmarks.
Significance. If the consistency result holds, the work supplies a unified geometry-respecting mechanism for extracting both aleatoric and epistemic uncertainty from a single post-hoc model without retraining the base VLM. The chain-rule isolation of the structurally discriminative PMI term and the empirical calibration on standard retrieval and selective-prediction tasks are concrete strengths that could improve uncertainty-aware multimodal pipelines.
major comments (2)
- [Abstract] Abstract: the population-limit consistency result is stated without derivation, key algebraic steps, or a numbered theorem. It is therefore impossible to verify whether the masking operation allows the joint RFM objective to factor exactly into conditional RFM objectives on each hypersphere (including tangent-space projection) or whether extra cross-terms vanish only under unstated assumptions on the embedding measure.
- [Method] Method section (consistency claim): the assertion that a single masked velocity field simultaneously satisfies the joint and both conditional Riemannian flow-matching objectives rests on an unshown decomposition. Without explicit verification that conditioning on one modality recovers the exact conditional velocity field, the central theoretical justification for deriving both uncertainty scores from one network remains load-bearing and unverifiable from the provided text.
minor comments (2)
- [Notation] Notation: the hypersphere is denoted S^{d-1} in the abstract but occasionally appears with inconsistent dimension subscripts in the text; a single global definition would improve readability.
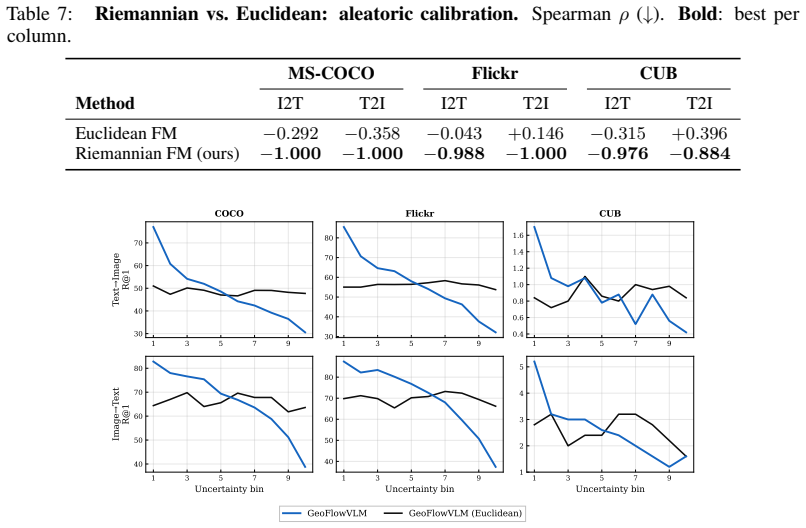
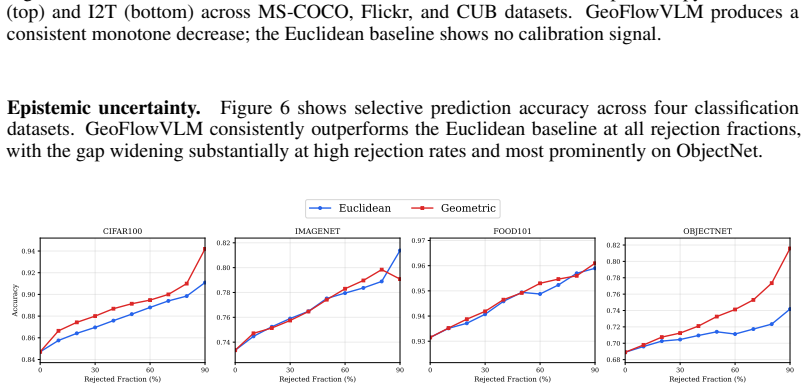
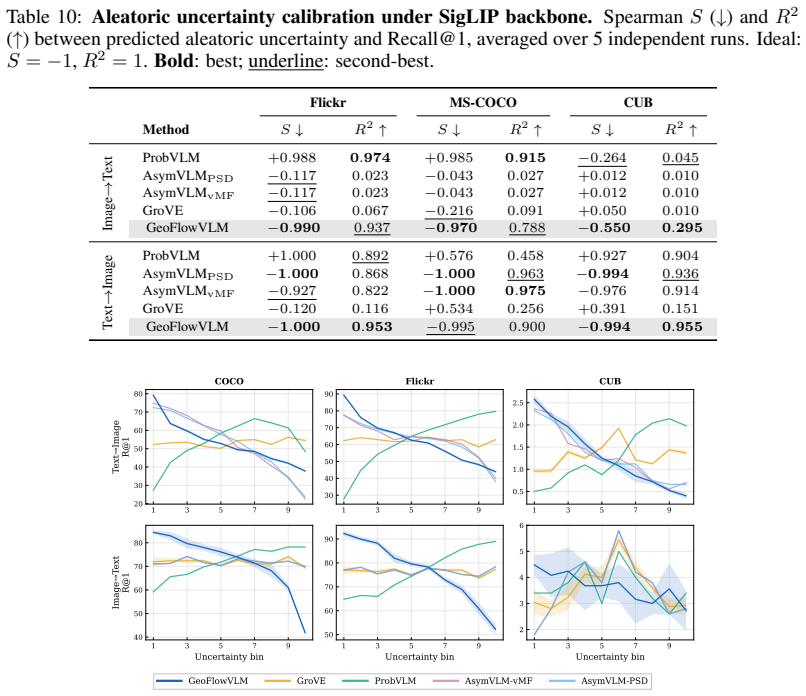
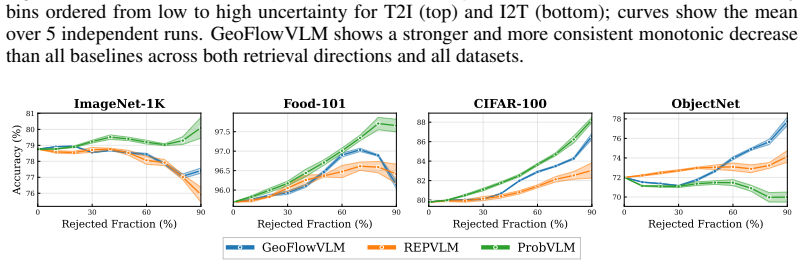
- [Experiments] Figures: the calibration plots for Recall@1 and selective accuracy would benefit from explicit confidence bands or bootstrap intervals to allow visual assessment of monotonicity strength.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments correctly identify that the population-limit consistency result is presented without sufficient detail for independent verification. We will revise the manuscript to include an explicit numbered theorem with the full algebraic derivation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the population-limit consistency result is stated without derivation, key algebraic steps, or a numbered theorem. It is therefore impossible to verify whether the masking operation allows the joint RFM objective to factor exactly into conditional RFM objectives on each hypersphere (including tangent-space projection) or whether extra cross-terms vanish only under unstated assumptions on the embedding measure.
Authors: We agree that the consistency result requires an explicit derivation. In the revised manuscript we will introduce a numbered theorem in the Method section that states the population-limit claim and provides the key algebraic steps. The proof will show that the single masked velocity field on the product hypersphere decomposes exactly into the joint RFM objective and the two conditional RFM objectives, with cross-terms vanishing because the masking isolates each modality and the product measure on S^{d-1} × S^{d-1} induces the required conditional independence in the population limit. Tangent-space projections will be handled explicitly via the standard Riemannian exponential and logarithmic maps on the hypersphere. revision: yes
-
Referee: [Method] Method section (consistency claim): the assertion that a single masked velocity field simultaneously satisfies the joint and both conditional Riemannian flow-matching objectives rests on an unshown decomposition. Without explicit verification that conditioning on one modality recovers the exact conditional velocity field, the central theoretical justification for deriving both uncertainty scores from one network remains load-bearing and unverifiable from the provided text.
Authors: We acknowledge that the current text asserts the decomposition without displaying the steps. The revision will contain a self-contained proof that, under the population limit, conditioning the masked velocity field on one modality recovers the exact conditional velocity field on the corresponding hypersphere. The argument relies only on the definition of Riemannian flow matching, the geometry of the product manifold, and the fact that the mask zeros the velocity components belonging to the unobserved modality; no additional assumptions on the embedding measure are required beyond those already stated for standard RFM on hyperspheres. revision: yes
Circularity Check
Derivation chain is self-contained with no circular reductions
full rationale
The paper asserts a consistency result in the population limit for the single masked velocity field yielding valid joint and conditional Riemannian flow-matching velocities, but this is presented as a derived mathematical property rather than a tautological redefinition or fitted input renamed as prediction. The marginal-typicality epistemic score follows from an exact chain-rule decomposition of the joint negative log-likelihood, which is a standard information-theoretic identity isolating the PMI term; this does not reduce the score to the model fit by construction. The conditional retrieval entropy is justified via an external Fano-type bound. No self-citations are load-bearing for the central claims, no ansatz is smuggled, and no uniqueness theorem is imported from prior author work. The derivation remains independent of the fitted values themselves.
Axiom & Free-Parameter Ledger
free parameters (1)
- masked velocity field parameters
axioms (2)
- domain assumption Dual-encoder VLM embeddings are l2-normalized and therefore lie on the unit hypersphere
- standard math Riemannian flow matching defines valid velocity fields on the hypersphere and its product manifold
Reference graph
Works this paper leans on
-
[1]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021
2021
-
[2]
Sigmoid loss for lan- guage image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for lan- guage image pre-training. In Proceedings of the IEEE/CVF international conference on com- puter vision, pages 11975–11986, 2023
2023
-
[3]
Probabilistic embeddings for cross-modal retrieval
Sanghyuk Chun, Seong Joon Oh, Rafael Sampaio De Rezende, Y annis Kalantidis, and Diane Larlus. Probabilistic embeddings for cross-modal retrieval. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 8415–8424, 2021
2021
-
[4]
Prob- vlm: Probabilistic adapter for frozen vison-language models
Uddeshya Upadhyay, Shyamgopal Karthik, Massimiliano Mancini, and Zeynep Akata. Prob- vlm: Probabilistic adapter for frozen vison-language models. In Proceedings of the IEEE/CVF international conference on computer vision , pages 1899–1910, 2023
1910
-
[5]
Probabilistic embeddings for frozen vision-language models: uncertainty quantification with gaussian process latent vari- able models
Aishwarya V enkataramanan, Paul Bodesheim, and Joachim Denzler. Probabilistic embeddings for frozen vision-language models: uncertainty quantification with gaussian process latent vari- able models. In Proceedings of the F orty-First Conference on Uncertainty in Artificial Intelli- gence, pages 4309–4328, 2025
2025
-
[6]
Post-hoc probabilistic vision-language models
Anton Baumann, Rui Li, Marcus Klasson, Santeri Mentu, Shyamgopal Karthik, Zeynep Akata, Arno Solin, and Martin Trapp. Post-hoc probabilistic vision-language models. arXiv preprint arXiv:2412.06014, 2024
-
[7]
Exploiting the asymmetric uncertainty structure of pre-trained vlms on the unit hypersphere
Li Ju, Max Andersson, Stina Fredriksson, Edward Glöckner, Andreas Hellander, Ekta V ats, and Prashant Singh. Exploiting the asymmetric uncertainty structure of pre-trained vlms on the unit hypersphere. In 39th Conference on Neural Information Processing Systems (NeurIPS 2025), 2025
2025
-
[8]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Y arin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pages 1050–1059, 2016
2016
-
[9]
Epistemic un- certainty quantification for pre-trained vlms via riemannian flow matching
Li Ju, Mayank Nautiyal, Andreas Hellander, Ekta V ats, and Prashant Singh. Epistemic un- certainty quantification for pre-trained vlms via riemannian flow matching. In International Conference on Machine Learning, 2026. URL https://arxiv.org/abs/2601.21662
-
[10]
Improved probabilistic image-text representations
Sanghyuk Chun. Improved probabilistic image-text representations. In The Twelfth Interna- tional Conference on Learning Representations , 2024
2024
-
[11]
Probabilistic language-image pre-training
Sanghyuk Chun, Wonjae Kim, Song Park, and Sangdoo Y un. Probabilistic language-image pre-training. In The Thirteenth International Conference on Learning Representations , 2025
2025
-
[12]
Alex Kendall and Y arin Gal. What uncertainties do we need in bayesian deep learning for computer vision? In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, pages 5580–5590, 2017
2017
-
[13]
Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods
Eyke Hüllermeier and Willem Waegeman. Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods. Machine learning, 110(3):457–506, 2021
2021
-
[14]
Riemannian continuous normalizing flows
Emile Mathieu and Maximilian Nickel. Riemannian continuous normalizing flows. Advances in neural information processing systems , 33:2503–2515, 2020
2020
-
[15]
Riemannian score-based generative modelling
V alentin De Bortoli, Emile Mathieu, Michael Hutchinson, James Thornton, Y ee Whye Teh, and Arnaud Doucet. Riemannian score-based generative modelling. Advances in neural infor- mation processing systems, 35:2406–2422, 2022
2022
-
[16]
Y aron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. In The Eleventh International Conference on Learning Representations (ICLR), 2023. 10
2023
-
[17]
Flow matching on general geometries
Ricky TQ Chen and Y aron Lipman. Flow matching on general geometries. In The Twelfth International Conference on Learning Representations , 2024
2024
-
[18]
Improving and generalizing flow-based gener- ative models with minibatch optimal transport
Alexander Tong, Kilian Fatras, Nikolay Malkin, Guillaume Huguet, Y anlei Zhang, Jarrid Rector-Brooks, Guy Wolf, and Y oshua Bengio. Improving and generalizing flow-based gener- ative models with minibatch optimal transport. Transactions on Machine Learning Research , pages 1–34, 2024
2024
-
[19]
Geometry-aware image flow matching
Junho Lee, Kwanseok Kim, and Joonseok Lee. Geometry-aware image flow matching. In International Conference on Machine Learning , Proceedings of Machine Learning Research, 2026
2026
-
[20]
The double-ellipsoid geometry of CLIP
Meir Y ossef Levi and Guy Gilboa. The double-ellipsoid geometry of CLIP. In F orty-second International Conference on Machine Learning , pages 33999–34019, 2025
2025
-
[21]
Whitened CLIP as a likelihood surrogate of im- ages and captions
Roy Betser, Meir Y ossef Levi, and Guy Gilboa. Whitened CLIP as a likelihood surrogate of im- ages and captions. In Proceedings of the 42nd International Conference on Machine Learning , volume 267 of Proceedings of Machine Learning Research, pages 4069–4095. PMLR, 2025
2025
-
[22]
On the importance of embedding norms in self-supervised learning
Andrew Draganov, Sharvaree V adgama, Sebastian Damrich, Jan Niklas Böhm, Lucas Maes, Dmitry Kobak, and Erik Bekkers. On the importance of embedding norms in self-supervised learning. In Proceedings of the 42nd International Conference on Machine Learning , volume 267 of Proceedings of Machine Learning Research. PMLR, 2025
2025
-
[23]
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning
Victor Weixin Liang, Y uhui Zhang, Y ongchan Kwon, Serena Y eung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. Advances in Neural Information Processing Systems , 35:17612–17625, 2022
2022
-
[24]
Understanding contrastive representation learning through alignment and uniformity on the hypersphere
Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In Proceedings of the 37th International Con- ference on Machine Learning, ICML. PMLR, 2020
2020
-
[25]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Quan Sun, Y uxin Fang, Ledell Wu, Xinlong Wang, and Y ue Cao. Eva-clip: Improved training techniques for clip at scale. arXiv preprint arXiv:2303.15389, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Sinkhorn distances: Lightspeed computation of optimal transport
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. Advances in neural information processing systems, 26, 2013
2013
-
[27]
Elements of information theory (wiley series in telecom- munications and signal processing)
Thomas M Cover and Joy A Thomas. Elements of information theory (wiley series in telecom- munications and signal processing) . Wiley-interscience, 2006
2006
-
[28]
Reproducible scaling laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition , pages 2818–2829, 2023
2023
-
[29]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Y ang, Y e Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Y un- Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning , pages 4904–4916. PMLR, 2021
2021
-
[30]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[31]
Food-101–mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc V an Gool. Food-101–mining discriminative components with random forests. In European conference on computer vision, pages 446–461. Springer, 2014
2014
-
[32]
Learning multiple layers of features from tiny images
A Krizhevsky. Learning multiple layers of features from tiny images. Master’s thesis, Univer- sity of Toronto, 2009. 11
2009
-
[33]
Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models
Andrei Barbu, David Mayo, Julian Alverio, William Luo, Christopher Wang, Dan Gutfreund, Josh Tenenbaum, and Boris Katz. Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models. Advances in neural information processing systems , 32, 2019
2019
-
[34]
Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 2556–2565, 2018
2018
-
[35]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Pi- otr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision , pages 740–755. Springer, 2014
2014
-
[36]
Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models
Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In Proceedings of the IEEE international conference on computer vision, pages 2641–2649, 2015
2015
-
[37]
The caltech- ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech- ucsd birds-200-2011 dataset. In California Institute of Technology , 2011. Technical Report CNS-TR-2011-001
2011
-
[38]
Learning deep representations of fine-grained visual descriptions
Scott Reed, Zeynep Akata, Bernt Schiele, and Honglak Lee. Learning deep representations of fine-grained visual descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016
2016
-
[39]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. Advances in neural information processing systems , 20, 2007
2007
-
[40]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision , pages 4195–4205, 2023
2023
-
[41]
Going deeper with image transformers
Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Hervé Jégou. Going deeper with image transformers. In Proceedings of the IEEE/CVF international confer- ence on computer vision , pages 32–42, 2021
2021
-
[42]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer. arXiv preprint arXiv:2002.05202 , 2020. URL https://arxiv.org/abs/2002.05202
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[43]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications , 2021. A Supplementary Material A.1 Datasets All models are trained on Conceptual Captions 1M (CC1M) [ 34], a web-crawled image-caption dataset providing one caption per image. Embeddings for all datasets are pre...
2021
-
[44]
Training uses AdamW with a cosine learning-rate schedule and linear warmup
We use a single hyperparameter configuration for all downstream evaluations and do not perform dataset-specific tuning. Training uses AdamW with a cosine learning-rate schedule and linear warmup. To stabilize joint density learning, we use a three-stage curriculum over the mask distribution. In the first stage, the model is trained only on conditional flow ta...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.