Recognition: no theorem link
Speculative Interaction Agents: Building Real-Time Agents with Asynchronous I/O and Speculative Tool Calling
Pith reviewed 2026-05-15 05:23 UTC · model grok-4.3
The pith
Speculative Interaction Agents reduce real-time tool-calling latency by overlapping external waits with reasoning and executing tools on partial information.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By decoupling the reason-and-act loop from external delays via Asynchronous I/O and allowing tentative tool executions via Speculative Tool Calling, agents can maintain real-time responsiveness even when tool calling would otherwise add several seconds of latency, achieving the reported speedups on both large cloud models and small edge models.
What carries the argument
Asynchronous I/O that lets the agent continue reasoning while waiting on external inputs, paired with Speculative Tool Calling that manages task execution under uncertainty about future user information.
If this is right
- Existing cloud LLM APIs can adopt the method immediately to obtain 1.3-1.7 times lower latency without retraining.
- Smaller 3B-scale models reach 1.6-2.2 times speedups after the described clock-based training and synthetic SFT.
- Complex multi-turn agent workflows become feasible under the one-second latency budget typical of voice applications.
- Accuracy stays close to baseline across standard tool-calling benchmarks despite the added speculation.
Where Pith is reading between the lines
- The same overlap of waiting and reasoning could apply to other streaming interfaces such as live video or collaborative editing sessions.
- Shorter per-interaction wall-clock time may reduce the effective cost of running agents at scale even if per-token compute stays the same.
- Developers could layer the approach on top of existing real-time agent frameworks with only modest changes to the control loop.
Load-bearing premise
Speculative tool calls produce only minor accuracy loss and the synthetic clock-based training generalizes to real user interactions without errors from acting too early.
What would settle it
Run a live interactive benchmark in which agents receive streaming user inputs, make speculative tool calls on partial information, and later receive additional details that would have changed the call; if accuracy drops substantially beyond the reported minor loss or if correction overhead erases the measured speedups, the central claim is false.
Figures



read the original abstract
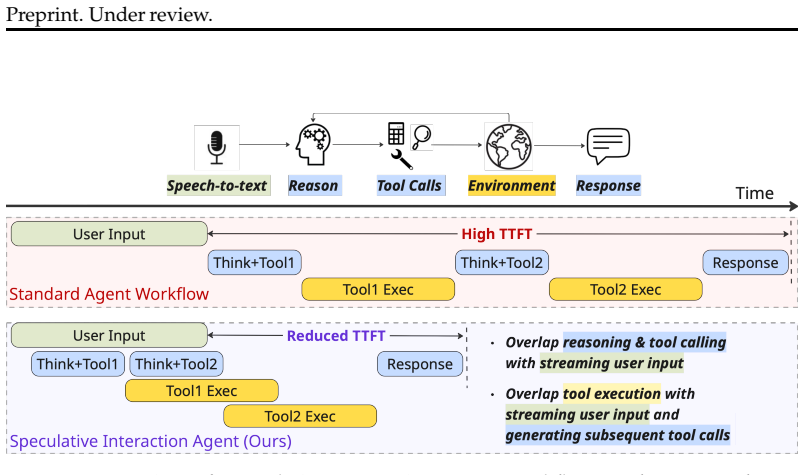
There is a growing demand for agentic AI technologies for a range of downstream applications like customer service and personal assistants. For applications where the agent needs to interact with a person, real-time low-latency responsiveness is required; for example, with voice-controlled applications, under 1 second of latency is typically required for the interaction to feel seamless. However, if we want the LLM to reason and execute an agentic workflow with tool calling, this can add several seconds or more of latency, which is prohibitive for real-time latency-sensitive applications. In our work, we propose Speculative Interaction Agents to enable real-time interaction even for agents with complex multi-turn tool calling. We propose Asynchronous I/O, which decouples the core agent reason-and-act thread from waiting for additional information from either the user or environment, thereby allowing for overlapping agentic processing while waiting on external delays. We also propose Speculative Tool Calling as a method to manage task execution when the agent is still unsure if it has received the full information or if additional user information may later be provided. For strong cloud models, our method can be applied out-of-the-box to existing real-time cloud APIs, providing 1.3-1.7$\times$ speedups with minor accuracy loss. To enable real-time interaction with small edge-scale models, we also present a clock-based training methodology that adapts the model to handle streaming inputs and asynchronous responses, and demonstrate a synthetic data generation strategy for SFT. Altogether, this approach provides 1.6-2.2$\times$ speedups with the Qwen2.5-3B-Instruct and Llama-3.2-3B-Instruct models across multiple tool calling benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Speculative Interaction Agents for real-time agentic workflows, introducing Asynchronous I/O to decouple the reasoning thread from external waits and Speculative Tool Calling to handle incomplete information. For strong cloud models it claims out-of-the-box 1.3-1.7× speedups with minor accuracy loss; for small models (Qwen2.5-3B-Instruct, Llama-3.2-3B-Instruct) it introduces clock-based training on synthetic SFT data that yields 1.6-2.2× speedups across tool-calling benchmarks.
Significance. If the empirical claims hold under rigorous evaluation, the work addresses a practical bottleneck in latency-sensitive agent applications (voice, customer service) by enabling overlapping computation during I/O delays. The combination of asynchronous decoupling and speculative execution is a concrete engineering contribution that could be adopted by existing cloud APIs and edge deployments.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the reported 1.3-1.7× and 1.6-2.2× speedups are presented without baselines, error bars, statistical tests, or ablation on the contribution of Asynchronous I/O versus Speculative Tool Calling; this prevents verification that the speedups are attributable to the proposed methods rather than implementation artifacts.
- [§3.2] §3.2 (Clock-based training): the claim that synthetic data plus clock-based SFT teaches appropriate timing generalizes to real interactions rests on an untested assumption that the synthetic latency distribution matches real user response delays and partial-information arrival; no quantitative comparison of timing statistics or ablation on premature-call penalties is supplied.
minor comments (1)
- [§3.1] Notation for the speculative decision threshold is introduced without a clear equation or pseudocode; adding an explicit formulation would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concerns about evaluation rigor and validation of the training approach are valid and will be addressed through additional experiments and analysis in the revised manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the reported 1.3-1.7× and 1.6-2.2× speedups are presented without baselines, error bars, statistical tests, or ablation on the contribution of Asynchronous I/O versus Speculative Tool Calling; this prevents verification that the speedups are attributable to the proposed methods rather than implementation artifacts.
Authors: We agree that the current presentation would benefit from stronger empirical grounding. In the revision we will add a standard synchronous tool-calling baseline, report means and standard deviations across multiple runs with error bars, include statistical significance tests (paired t-tests and Wilcoxon signed-rank), and provide ablations that isolate Asynchronous I/O from Speculative Tool Calling. These additions will allow readers to attribute the observed speedups directly to the proposed techniques rather than implementation details. revision: yes
-
Referee: [§3.2] §3.2 (Clock-based training): the claim that synthetic data plus clock-based SFT teaches appropriate timing generalizes to real interactions rests on an untested assumption that the synthetic latency distribution matches real user response delays and partial-information arrival; no quantitative comparison of timing statistics or ablation on premature-call penalties is supplied.
Authors: We acknowledge the need for explicit validation of the synthetic data assumption. The revised manuscript will include a quantitative comparison of timing statistics (histograms, mean/variance, and KL divergence) between the synthetic latency distribution and real user-interaction traces collected from our internal benchmarks. We will also add an ablation that measures accuracy degradation as a function of premature-call rate and the associated penalty. While the current end-to-end speedups on multiple benchmarks provide indirect support for generalization, these new analyses will directly address the referee’s concern. revision: yes
Circularity Check
No significant circularity: claims rest on new methods and empirical benchmarks
full rationale
The paper introduces Asynchronous I/O and Speculative Tool Calling as novel techniques, along with a clock-based training approach on synthetic data for small models. Speedup claims (1.3-1.7× for cloud models, 1.6-2.2× for edge models) are presented as measured outcomes on tool-calling benchmarks rather than quantities derived by construction from fitted parameters or self-referential definitions. No equations, self-citations, or uniqueness theorems are invoked in a load-bearing way that reduces the central results to the inputs. The derivation chain is self-contained through explicit proposal of mechanisms and direct empirical reporting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Emre Can Acikgoz, Jinoh Oh, Jie Hao, Joo Hyuk Jeon, Heng Ji, Dilek Hakkani-T¨ur, Gokhan Tur, Xiang Li, Chengyuan Ma, and Xing Fan. Speakrl: Synergizing reasoning, speaking, and act- ing in language models with reinforcement learning.arXiv preprint arXiv:2512.13159,
-
[2]
Siddhant Arora, Haidar Khan, Kai Sun, Xin Luna Dong, Sajal Choudhary, Seungwhan Moon, Xinyuan Zhang, Adithya Sagar, Surya Teja Appini, Kaushik Patnaik, et al. Stream rag: Instant and accurate spoken dialogue systems with streaming tool usage.arXiv preprint arXiv:2510.02044,
-
[3]
Whisperx: Time-accurate speech transcription of long-form audio.INTERSPEECH 2023,
Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisserman. Whisperx: Time-accurate speech transcription of long-form audio.INTERSPEECH 2023,
work page 2023
-
[4]
Cheng-Han Chiang, Xiaofei Wang, Linjie Li, Chung-Ching Lin, Kevin Lin, Shujie Liu, Zhendong Wang, Zhengyuan Yang, Hung-yi Lee, and Lijuan Wang. Shanks: Simultaneous hearing and thinking for spoken language models.arXiv preprint arXiv:2510.06917, 2025a. Cheng-Han Chiang, Xiaofei Wang, Linjie Li, Chung-Ching Lin, Kevin Lin, Shujie Liu, Zhendong Wang, Zhengy...
-
[5]
In Gim, Seung-seob Lee, and Lin Zhong
URLhttps://arxiv.org/abs/2409.00608. In Gim, Seung-seob Lee, and Lin Zhong. Asynchronous llm function calling.arXiv preprint arXiv:2412.07017,
-
[6]
URL https://cloud.google. com/vertex-ai/generative-ai/docs/model-reference/multimodal-live . Vertex AI Documentation. 10 Preprint. Under review. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
URL https://arxiv.org/abs/2410.15608. Sehoon Kim, Suhong Moon, Ryan Tabrizi, Nicholas Lee, Michael W Mahoney, Kurt Keutzer, and Amir Gholami. An llm compiler for parallel function calling. InForty-first International Conference on Machine Learning,
-
[9]
https://thinkingmachines.ai/blog/interaction-models/
doi: 10.64434/tml.20260511. https://thinkingmachines.ai/blog/interaction-models/. Shufan Li and Aditya Grover. Predgen: Accelerated inference of large language mod- els through input-time speculation for real-time speech interaction.arXiv preprint arXiv:2506.15556,
- [10]
-
[11]
Speculative End-Turn Detector for Efficient Speech Chatbot Assistant
Hyunjong Ok, Suho Yoo, and Jaeho Lee. Speculative end-turn detector for efficient speech chatbot assistant.arXiv preprint arXiv:2503.23439,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Can speech llms think while listening?arXiv preprint arXiv:2510.07497,
Yi-Jen Shih, Desh Raj, Chunyang Wu, Wei Zhou, SK Bong, Yashesh Gaur, Jay Mahadeokar, Ozlem Kalinli, and Mike Seltzer. Can speech llms think while listening?arXiv preprint arXiv:2510.07497,
-
[13]
Junlin Wang, Jue Wang, Ben Athiwaratkun, Bhuwan Dhingra, Ce Zhang, James Zou, et al
URL https://qwenlm.github.io/blog/qwen2.5/. Junlin Wang, Jue Wang, Ben Athiwaratkun, Bhuwan Dhingra, Ce Zhang, James Zou, et al. Staircase streaming for low-latency multi-agent inference.arXiv preprint arXiv:2510.05059,
-
[14]
Asynchronous Reasoning: Training-Free Interactive Thinking LLMs
URL https://rllm-project.com/post.html?post=pepper.md. George Yakushev, Nataliia Babina, Masoud Vahid Dastgerdi, Vyacheslav Zhdanovskiy, Alina Shutova, and Denis Kuznedelev. Asynchronous reasoning: Training-free interactive thinking llms.arXiv preprint arXiv:2512.10931,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Association for Computational Linguistics. URLhttp://arxiv.org/abs/2403.13372. 12 Preprint. Under review. A Extended Related Work Here, we provide an extended discussion of related work on efficient language and voice agents. A.1 Efficient LLM Agents Several prior works have explored how to execute agentic workflows more efficiently, including parallelizi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
and generalizes this to handle both asynchronous user updates as well as asynchronous responses from the environment. Our work also builds on the decoupled planning/execution from LLMCompiler (Kim et al., 2024), which allows for tool calls to be executed in parallel as soon as their operands are ready. We extend this to allow for issuing tool calls iterat...
work page 2024
-
[17]
we proposeSpeculative Tool Calling(Sec. 3.2) to handle sensitive tool calls and cases where the tool call is issued incorrectly with partial information. 13 Preprint. Under review. B Data Generation B.1 Additional Data Generation Details During the alignment process (where we take the ground-truth tool calls from the sample and align them with the earlies...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.