Recognition: unknown
Beyond Oversquashing: Understanding Signal Propagation in GNNs Via Observables
Pith reviewed 2026-05-14 20:28 UTC · model grok-4.3
The pith
Standard spectral GNNs diffuse signals broadly instead of routing them to specific regions, while Schrödinger GNNs maintain better directed propagation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By defining observables for the place a signal occupies, the amount of signal concentrated there, and the amount propagated toward a location of interest, the paper proves that standard spectral GNNs possess poor signal propagation capabilities. The proposed Schrödinger GNN is shown to possess a superior capacity to route the signal across the graph.
What carries the argument
Quantum-mechanics-inspired observables that quantify signal location, concentration at that location, and directed propagation toward a target under successive GNN layers.
If this is right
- Standard spectral GNNs will continue to lose information on tasks that require signals to reach specific distant nodes rather than averaging across the whole graph.
- Schrödinger GNNs provide a concrete architectural change that improves deliberate signal routing while remaining within the spectral GNN family.
- The observable framework supplies a new diagnostic tool for measuring how well any GNN layer preserves targeted information flow.
- Designs that optimize the observables directly can be expected to reduce reliance on very deep stacks or auxiliary attention mechanisms for long-range dependencies.
Where Pith is reading between the lines
- The same observable tracking could be applied to non-spectral message-passing networks to compare their routing behavior with spectral ones on equal terms.
- If the concentration and propagation metrics predict real accuracy, they could serve as training objectives or early-stopping criteria during GNN optimization.
- The approach opens a route to test whether graphs with known modular structure benefit more from Schrödinger GNNs than from conventional spectral baselines.
Load-bearing premise
The quantum-mechanics-inspired definitions of signal location, concentration, and propagation to a target location match the actual discrete behavior of finite-layer message passing on graphs.
What would settle it
A controlled experiment on synthetic graphs with distant target nodes where the Schrödinger GNN fails to produce higher concentration or propagation values than standard spectral GNNs, or where it yields no accuracy gain on a downstream task that requires long-range signal transfer.
Figures
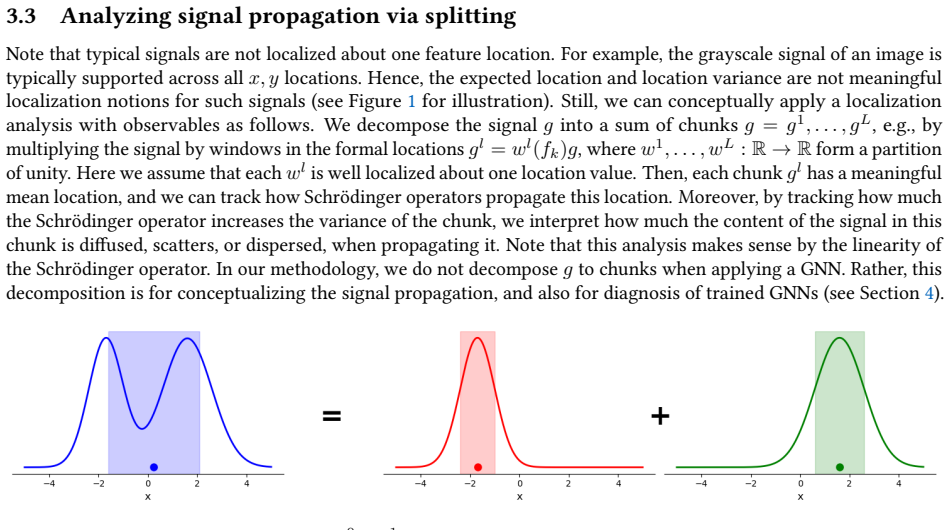




read the original abstract
Graph Neural Networks (GNNs) perform computations on graphs by routing the signal between graph regions using a graph shift operator or a message passing scheme. Often, the propagation of the signal leads to a loss of information, where the signal tends to diffuse across the graph instead of being deliberately routed between regions of interest. Two notions that depict this phenomenon are oversmoothing and oversquashing. In this paper, we propose an alternative approach for modeling signal propagation, inspired by quantum mechanics, using the notion of observables. Specifically, we model the place in the graph where the signal lies, how much the signal is concentrated there, and how much of the signal is propagated towards a location of interest when applying a GNN. Using these new concepts, we prove that standard spectral GNNs have poor signal propagation capabilities. We then propose a new type of spectral GNN, termed Schr\"odinger GNN, which we show has a superior capacity to route the signal across the graph.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces quantum-mechanics-inspired observables to model signal location, concentration, and propagation toward a target in graphs. It uses these to prove that standard spectral GNNs exhibit poor signal propagation and proposes a new Schrödinger GNN claimed to route signals more effectively across the graph.
Significance. If the observables are shown to faithfully reproduce finite-layer message-passing behavior, the framework could supply a new analytical lens on information flow that complements oversmoothing and oversquashing analyses and motivate architectures with better long-range routing.
major comments (2)
- [Sections defining the observables and the proofs of poor propagation / superiority] The central proofs that standard spectral GNNs have poor propagation and that Schrödinger GNNs are superior rest on the claim that the QM-inspired observables (signal location, concentration, and amount propagated) exactly capture discrete finite-layer computations performed by the graph shift operator or message passing. The manuscript must supply an explicit derivation or theorem establishing this equivalence; without it the separation between the two models does not follow for practical GNNs.
- [Definition of Schrödinger GNN and experimental comparisons] The Schrödinger GNN is introduced as a new spectral model derived from the same observables. The manuscript should clarify whether its update rule reduces to a standard spectral convolution under any parameter setting or whether it introduces additional free parameters that could explain the reported improvement.
minor comments (2)
- [Preliminaries / Observable definitions] Provide explicit mathematical definitions of the three observables (location, concentration, propagated amount) with all notation introduced before they are used in proofs.
- [Modeling section] Clarify the precise relationship between the continuous-time Hilbert-space framing and the discrete, finite-layer setting of standard GNNs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the theoretical foundations of our work. We address each major point below and will revise the manuscript to incorporate explicit derivations and clarifications as requested.
read point-by-point responses
-
Referee: [Sections defining the observables and the proofs of poor propagation / superiority] The central proofs that standard spectral GNNs have poor propagation and that Schrödinger GNNs are superior rest on the claim that the QM-inspired observables (signal location, concentration, and amount propagated) exactly capture discrete finite-layer computations performed by the graph shift operator or message passing. The manuscript must supply an explicit derivation or theorem establishing this equivalence; without it the separation between the two models does not follow for practical GNNs.
Authors: We agree that an explicit equivalence between the observables and finite-layer message-passing computations is essential for rigor. In the revised manuscript we will add a new theorem (Theorem 3.2) with a complete inductive derivation showing that the signal-location, concentration, and propagated-amount observables exactly reproduce the node-wise signal values after any finite number of layers of the graph shift operator. The proof proceeds by induction on the layer index, starting from the base case of the input features and using the recursive definition of the GNN update. With this addition the subsequent proofs of poor propagation in standard spectral GNNs and the superiority claims for Schrödinger GNNs will rest on a formally established equivalence. revision: yes
-
Referee: [Definition of Schrödinger GNN and experimental comparisons] The Schrödinger GNN is introduced as a new spectral model derived from the same observables. The manuscript should clarify whether its update rule reduces to a standard spectral convolution under any parameter setting or whether it introduces additional free parameters that could explain the reported improvement.
Authors: The Schrödinger GNN update is a spectral convolution whose filter coefficients are modulated by the observable-derived potential terms. When these potential terms are identically zero, the update rule reduces exactly to the standard spectral convolution used in the baseline models. The additional parameters are not free learnable weights; they are deterministic functions of the graph Laplacian and the target node set, so the total number of trainable parameters remains identical to that of a standard spectral GNN of the same order. We will insert a short proposition (Proposition 4.1) demonstrating the reduction and will update the experimental section to emphasize that performance gains arise from improved propagation rather than increased capacity. These clarifications will be added to the revised manuscript. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces new QM-inspired observables (signal location, concentration, and propagation toward a target) as modeling tools for GNN signal flow. It then applies these definitions to prove limitations of standard spectral GNNs and advantages for the proposed Schrödinger GNN. These steps consist of direct mathematical consequences of the defined observables acting on graph shift operators and finite-layer message passing; the conclusions are not presupposed by the inputs, nor do they reduce to fitted parameters renamed as predictions or to self-citation chains. The framework is externally motivated but internally self-contained, with no load-bearing self-referential definitions or uniqueness theorems imported from the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Quantum-mechanics observables can be meaningfully defined for signal location, concentration, and propagation on finite graphs under standard spectral GNN operators.
invented entities (1)
-
Schrödinger GNN
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Oversquashing in gnns through the lens of information contraction and graph expansion
Pradeep Kr Banerjee, Kedar Karhadkar, Yu Guang Wang, Uri Alon, and Guido Montúfar. Oversquashing in gnns through the lens of information contraction and graph expansion. In2022 58th Annual Allerton Conference on Communication, Control, and Computing (Allerton), pages 1–8. IEEE, 2022a. Pradeep Kr Banerjee, Kedar Karhadkar, Yu Guang Wang, Uri Alon, and Guid...
-
[2]
A generalization of transformer networks to graphs.arXiv preprint arXiv:2012.09699, 2020a
11 Vijay Prakash Dwivedi and Xavier Bresson. A generalization of transformer networks to graphs.arXiv preprint arXiv:2012.09699, 2020a. Vijay Prakash Dwivedi and Xavier Bresson. A generalization of transformer networks to graphs.arXiv preprint arXiv:2012.09699, 2020b. Vijay Prakash Dwivedi, Ladislav Rampášek, Michael Galkin, Ali Parviz, Guy Wolf, Anh Tuan...
-
[3]
ISSN 1522-2616. doi: 10.1002/mana.202100466. William L. Hamilton, Rex Ying, and Jure Leskovec. Inductive representation learning on large graphs. InAdvances in Neural Information Processing Systems, volume 30,
-
[4]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Christopher Morris, Nils M Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann. TUDataset: A collection of benchmark datasets for learning with graphs.arXiv preprint arXiv:2007.08663,
-
[7]
Graph unitary message passing.arXiv preprint arXiv:2403.11199,
Haiquan Qiu, Yatao Bian, and Quanming Yao. Graph unitary message passing.arXiv preprint arXiv:2403.11199,
-
[8]
Jan Tönshoff, Martin Ritzert, Hinrikus Wolf, and Martin Grohe. Walking out of the weisfeiler leman hierarchy: Graph learning beyond message passing.arXiv preprint arXiv:2102.08786,
-
[9]
Quantum graph neural networks.arXiv preprint arXiv:1909.12264,
Guillaume Verdon, Trevor McCourt, Enxhell Luzhnica, Vikash Singh, Stefan Leichenauer, and Jack Hidary. Quantum graph neural networks.arXiv preprint arXiv:1909.12264,
-
[10]
16 A.2 Comparison with related unitary neural architectures
14 Appendix A Extended background and related work 16 A.1 Spectral graph neural networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 A.2 Comparison with related unitary neural architectures . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 A.3 Relation to quantum and quantum-inspired graph neural networks . . . ...
work page 1986
-
[11]
This leads to the signal routing measure PM(g(0), g(t), r) = ⟨(M−rI) 2g(t),g(t)⟩ VM(g(0)) , which explicitly quantifies whether the final signal is concentrated near a target feature value r. This target-directed localization objective is absent from unitary convolutions. Role of complex phases.In [Kiani et al., 2024], complexification is used to make ope...
work page 2024
-
[12]
pairwise cost of dense Transformer attention. B Computational realization of Schrödinger GNNs In this appendix, we explain how the Schrödinger graph signal processing introduced in Section 3 is instantiated in practice. One important note is that the model does not require explicit construction of a dense matrix exponential. Instead, it applies sparse fea...
work page 2021
-
[13]
Claim 21(Mixed derivative of the signal routing measure)
We now simplify the notations and give a formula for D:= ∂ ∂θ ∂ ∂t PXf (g,S[t, f]D[θh]g, r) t=θ=0 . Claim 21(Mixed derivative of the signal routing measure). ∂ ∂θ ∂ ∂t PXf (g,S[t, f]D[θh]g, r) t=θ=0 = ⟨[Xh,[∆, X 2 f]]g, g⟩ −4rRe⟨[X h, Wf ∇f]g, g⟩ VXf (g) We see that whenhis constant, i.e., there is no modulation,Dis zero. Proof. Let ϕθ =D[θh]g=e iθXh g. S...
work page 2022
-
[14]
E.3.3 Training For a sample (xi, yi), we minimize the L2 loss ∥ˆyi −y i∥2. We train for 250 epochs with Adam [Kingma and Ba, 2014], using a base learning rate of 0.1, a 10× larger learning rate for the modulation parameters, and a ReduceLROnPlateau scheduler with factor 0.7 and patience
work page 2014
-
[15]
In Table 5, we report the parameter counts for the Schrödinger GNN and the competing methods
Figure 6 reports smoothed test curves for readability and the dashed line denotes a naive baseline. In Table 5, we report the parameter counts for the Schrödinger GNN and the competing methods. E.4 MNIST graph classification We conduct an experiment on the classical MNIST dataset [LeCun et al., 1998b] to evaluate our model’s performance on a standard imag...
work page 2016
-
[16]
This isolates differences in the propagation operator as much as possible
For the remaining models (GAT, GCN, GIN, Adaptive Unitary, Schrödinger, and Schrödinger PMO), we then adjust the hidden dimension so that the total number of trainable parameters falls within 0.6% of this reference budget. This isolates differences in the propagation operator as much as possible. For complex-valued models, each complex parameter is counte...
work page 2098
-
[17]
Runtime comparison.Table 9 reports the mean and standard deviation of the training time per epoch for each model on the TU datasets. Ablation study on ENZYMES datasetWe use the ENZYMES dataset to isolate the contribution of three ingredients in the Schrödinger framework: learnable propagation time, phase modulation, and PMO preprocessing. All models share...
work page 2024
-
[18]
A final linear layer maps the node embeddings to class logits
The dropout is set as {0.2,0.5} . A final linear layer maps the node embeddings to class logits. The performance is reported with the best results. E.7 Long range graph benchmark We follow the experimental setup and training scheme as in [Tönshoff et al., 2024, Kiani et al., 2024]. E.7.1 Peptides Edge features.The current unitary Schrödinger block does no...
work page 2024
-
[19]
For models that do not directly incorporate edge attributes in the message-passing layer, we follow [Kiani et al., 2024] and prepend a single GatedGCN layer as an edge-feature aggregator, which maps edge information into the node representations before applying the main network. We use the same positional encoding as in the reference setup: no additional ...
work page 2024
-
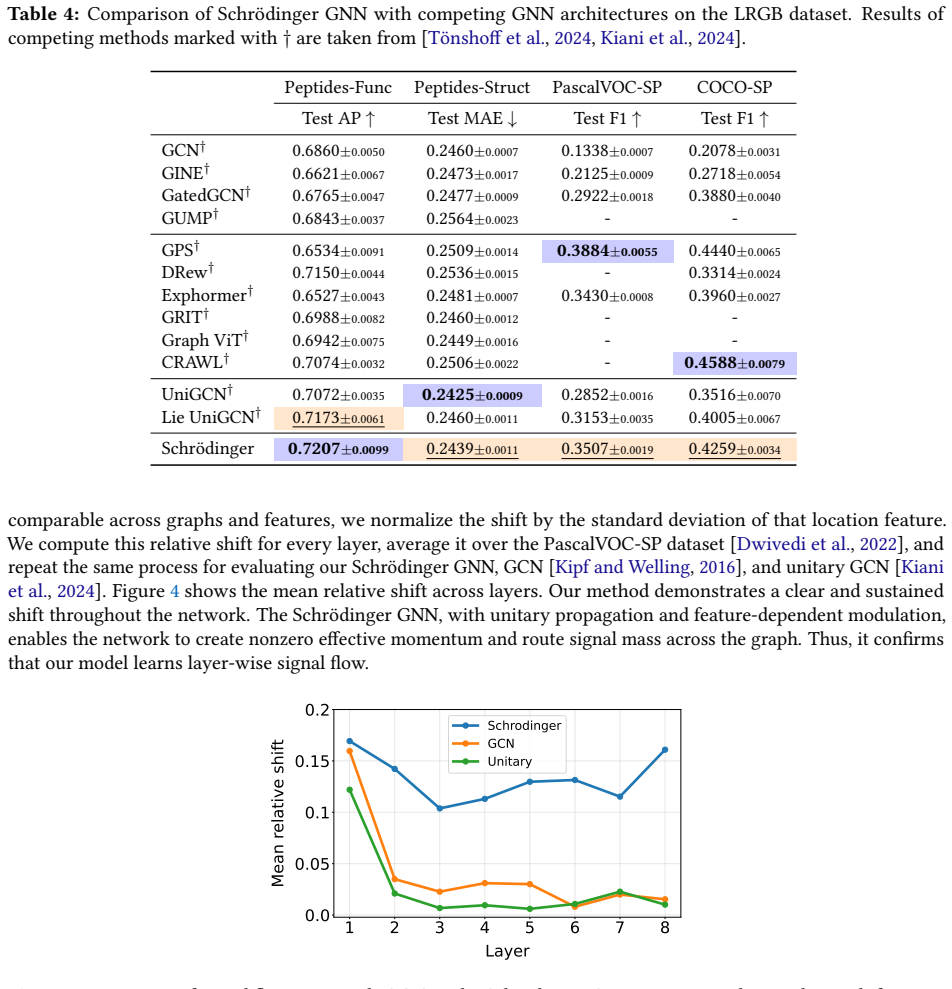
[20]
The purpose of this experiment is to measure whether the hidden signal of a trained model is transported across the graph by individual layers. All models are first trained on PascalVOC-SP using the standard training split and selected by validation performance. After training, all parameters are frozen and the diagnostic is run in evaluation mode, with d...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.