Recognition: unknown
Mixed neural posterior estimation for simulators with discrete and continuous parameters
Pith reviewed 2026-05-14 20:13 UTC · model grok-4.3
The pith
Neural posterior estimation extends to simulators with mixed discrete and continuous parameters through joint factorization and training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By factorizing the joint posterior into discrete and continuous components, pairing an autoregressive classifier for the discrete parameters with a generative model for the continuous parameters, and optimizing the combined network under a single simulation-based objective, the method produces accurate and calibrated posterior approximations for both tractable toy examples and real-world scientific simulators.
What carries the argument
The inference network that factorizes the joint posterior into an autoregressive classifier for discrete parameters and a generative model for continuous parameters, trained jointly under a single simulation-based objective.
Load-bearing premise
The factorization of the joint posterior into discrete and continuous components combined with joint training under a single simulation-based objective will produce accurate and calibrated approximations without additional constraints or post-training adjustments.
What would settle it
On a simulator whose true posterior is known exactly, draw samples from the learned approximation and check whether they match the true distribution or pass a calibration diagnostic; systematic mismatch would refute the claim.
Figures



read the original abstract
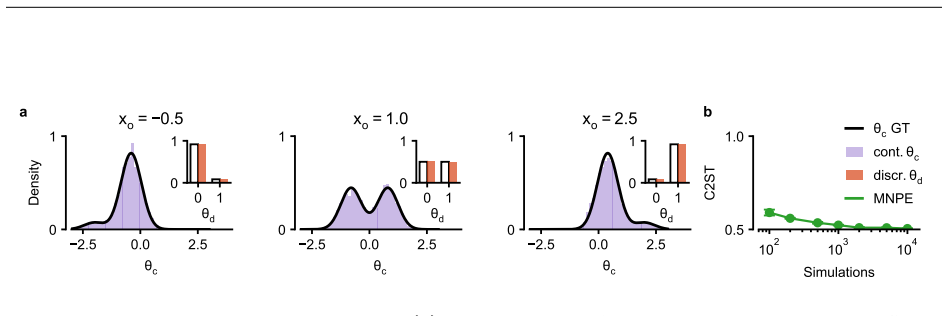
Neural Posterior Estimation (NPE) enables rapid parameter inference for complex simulators with intractable likelihoods. NPE trains an inference network to estimate a probability density over parameters given data, typically assumed to be \emph{continuous}. However, many scientific models involve parameter spaces that are \emph{mixed}, that is, they contain both discrete and continuous dimensions. We address this limitation by extending NPE to mixed parameter spaces through an inference network that jointly handles discrete and continuous parameters. The inference network factorizes the joint posterior into discrete and continuous components, combining an autoregressive classifier for the discrete parameters with a generative model for the continuous parameters, trained jointly under a single simulation-based objective. In addition, we propose a diagnostic tool to assess the calibration of the mixed posterior approximation. Across tractable toy examples and real-world scientific simulators, our joint inference approach yields accurate and calibrated posteriors. The inference framework is available in the \texttt{sbi} Python package.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends Neural Posterior Estimation (NPE) to simulators with mixed discrete and continuous parameters. It factorizes the joint posterior into an autoregressive classifier for the discrete parameters and a conditional generative model for the continuous parameters, with both components trained jointly under a single simulation-based objective. A diagnostic is proposed to assess calibration of the mixed posterior. The method is evaluated on tractable toy examples and real-world scientific simulators, claiming to yield accurate and calibrated posteriors, and is released in the sbi package.
Significance. If the joint training produces calibrated approximations for both discrete and continuous components without additional constraints or post-hoc adjustments, the work would be a useful practical extension of NPE to a common class of scientific models. The open-source implementation in sbi supports reproducibility. The significance is tempered by the lack of explicit analysis showing that the single-objective training does not allow continuous-component gradients to degrade discrete marginal calibration.
major comments (1)
- [Methods (joint training objective)] The central claim that joint training under a single simulation-based objective yields calibrated posteriors for both components rests on the unexamined assumption that gradients from the continuous density estimator will not dominate or bias the autoregressive classifier for discrete parameters. No analysis, weighting scheme, alternating optimization, or marginal calibration term is described to guard against this coupling, particularly when discrete choices depend strongly on continuous values.
minor comments (1)
- [Abstract] The abstract states that the diagnostic assesses calibration but does not specify the exact procedure or metrics (e.g., whether it checks marginal calibration for discrete parameters separately).
Simulated Author's Rebuttal
We thank the referee for their constructive review and for identifying a key point regarding the joint training procedure in our extension of NPE to mixed discrete-continuous parameter spaces. We address the major comment below and describe the revisions we will implement.
read point-by-point responses
-
Referee: The central claim that joint training under a single simulation-based objective yields calibrated posteriors for both components rests on the unexamined assumption that gradients from the continuous density estimator will not dominate or bias the autoregressive classifier for discrete parameters. No analysis, weighting scheme, alternating optimization, or marginal calibration term is described to guard against this coupling, particularly when discrete choices depend strongly on continuous values.
Authors: We appreciate the referee highlighting the need to examine potential gradient interference in the joint objective. Our current manuscript relies on extensive empirical validation across toy models and scientific simulators, where the proposed calibration diagnostic confirms accurate marginal posteriors for both discrete and continuous components even under strong interdependencies. To directly address this concern, the revised manuscript will include a new subsection on training dynamics. This will feature (i) monitoring of discrete marginal calibration throughout joint optimization, (ii) additional experiments that systematically vary the strength of dependence between discrete and continuous parameters, and (iii) a brief discussion of why explicit weighting or alternating optimization was not required in the evaluated settings. These additions will provide concrete evidence that continuous-component gradients do not degrade discrete calibration under the conditions tested. revision: yes
Circularity Check
No significant circularity; method is a direct extension trained on independent simulations
full rationale
The paper introduces a factorization of the joint posterior into an autoregressive classifier for discrete parameters and a conditional generative model for continuous parameters, trained jointly under a single simulation-based objective. This is presented as a straightforward methodological extension of standard NPE, with empirical validation on independent toy and scientific simulators. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation; the central claim rests on the joint training procedure and post-hoc calibration diagnostics rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ryan Prescott Adams and David J. C. MacKay. Bayesian online changepoint detection.arXiv preprint arXiv:0710.3742,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Patrick Cannon, Daniel Ward, and Sebastian M Schmon. Investigating the impact of model misspecification in neural simulation-based inference.arXiv preprint arXiv:2209.01845,
-
[3]
Michael Deistler, Pedro J. Goncalves, and Jakob H. Macke. Truncated proposals for scalable and hassle-free simulation-based inference. InAdvances in Neural Information Processing Systems, 2022a. Michael Deistler, Jakob H Macke, and Pedro J Gonçalves. Energy-efficient network activity from disparate circuit parameters.Proceedings of the National Academy of...
-
[4]
Simultaneous identification of changepoints and model parameters in switching dynamical systems.bioRxiv, pp
Xiaoming Fu, Kai Fan, Heinrich Zozmann, Lennart Schüler, and Justin M Calabrese. Simultaneous identification of changepoints and model parameters in switching dynamical systems.bioRxiv, pp. 2024.01.30.577909,
2024
-
[5]
Aurelien Ghiglino, Daniel Elenius, Anirban Roy, Ramneet Kaur, Manoj Acharya, Colin Samplawski, Brian Matejek, Susmit Jha, Juan Alonso, and Adam Cobb. Do diffusion models dream of electric planes? Discrete and continuous simulation-based inference for aircraft design.arXiv preprint arXiv:2603.13284,
- [6]
-
[7]
Ryan P. Kelly, David J. Warne, David T. Frazier, David J. Nott, Michael U. Gutmann, and Christo- pher Drovandi. Simulation-based Bayesian inference under model misspecification.arXiv preprint arXiv:2503.12315,
-
[8]
BayesFlow 2.0: Multi-backend amortized Bayesian inference in Python.arXiv preprint arXiv:2602.07098,
Lars Kühmichel, Jerry M Huang, Valentin Pratz, Jonas Arruda, Hans Olischläger, Daniel Habermann, Simon Kucharsky, Lasse Elsemüller, Aayush Mishra, Niels Bracher, et al. BayesFlow 2.0: Multi-backend amortized Bayesian inference in Python.arXiv preprint arXiv:2602.07098,
-
[9]
Du Phan, Neeraj Pradhan, and Martin Jankowiak. Composable effects for flexible and accelerated proba- bilistic programming in NumPyro.arXiv preprint arXiv:1912.11554,
-
[10]
Sean Talts, Michael Betancourt, Daniel Simpson, Aki Vehtari, and Andrew Gelman. Validating Bayesian inference algorithms with simulation-based calibration.arXiv preprint arXiv:1804.06788,
-
[11]
joint marginal
13 Appendix Contents A Calibration checks 15 A.1 Empirical baselines for discrete calibration checks . . . . . . . . . . . . . . . . . . . . . . . . . 15 A.2 Alternative Calibration checks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 B Additional examples 16 B.1 Coal mining disaster changepoint inference . . . . . . . . . . ....
2019
-
[12]
The observation is the full sequence of annual disaster countsx= (y 1851,...,y 1961)∈N111
and the continuous parameters areθc = (λearly,λlate)∈R2 >0. The observation is the full sequence of annual disaster countsx= (y 1851,...,y 1961)∈N111. The discrete switchpoint is analytically marginalized reducing inference to a purely continuous problem amenable to NUTS (Abril-Pla et al., 2023; Hoffman & Gelman, 2014). The discrete posteriorp(s|x) is the...
1961
-
[13]
compresses the observation before the density estimator. We also applied a variance-stabilizing√·transform to the Poisson counts before training, which produces a more uniform variance across rate regimes and improves z-scoring during training. We evaluate MNPE across seven training budgets from103 to10 5 simulations, with five independent training runs p...
1905
-
[14]
Both networks have 3 hidden layers with 32 hidden features each
C Experimental details C.1 Gaussian example MNPE uses a neural spline flow with 5 coupling transforms and 4 blocks for the continuous parameters, and a MADE for the discrete parameters. Both networks have 3 hidden layers with 32 hidden features each. Training uses up toN= 10,000simulations with learning rate set toη= 5e−4, validation set fraction of ten p...
2008
-
[15]
(2020) to cover biological meaningful ranges and are listed in Tab
and Gonçalves et al. (2020) to cover biological meaningful ranges and are listed in Tab. C-1. We used a step currentIinj of2µA/cm2 for1000msand run the simulation for1450ms. This stimulus and recording protocol corresponds to the voltage recordings from the Allen Institute for Brain Science (2016). 20 Table C-1: Parameter bounds and values that were used ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.