Recognition: no theorem link
Weighted and Truncated Tail Index Estimation under Random Censoring: A Unified Full-Range Framework
Pith reviewed 2026-05-14 17:45 UTC · model grok-4.3
The pith
A weighted and truncated Nelson-Aalen process yields consistent extreme value index estimators valid for any strength of right censoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By weighting and truncating the Nelson-Aalen tail empirical process and linearizing the resulting integral estimators as functionals of that process, the authors obtain a class of estimators for the extreme value index that admit a uniform Gaussian approximation and asymptotic normality uniformly over the full range of censoring strengths, from very weak to very strong.
What carries the argument
The weighted and truncated Nelson-Aalen tail empirical process, indexed by a tuning parameter larger than one, together with its linearization as a functional of the underlying empirical process.
If this is right
- Consistency and asymptotic normality hold without any lower bound on the proportion of uncensored tail observations.
- The estimators remain valid when the asymptotic censoring proportion is at most one half, covering strong-censoring regimes previously excluded.
- A single tuning parameter greater than one controls the weighting and truncation and restores tractable asymptotics across all censoring levels.
- Linearization of the estimator as a functional of the weighted truncated process supplies the route to the uniform Gaussian approximation.
Where Pith is reading between the lines
- The same linearization technique could be applied to other functionals of the tail process, such as extreme quantile estimators, under the same censoring range.
- Choice of the tuning parameter might be adapted to observed censoring proportion to reduce finite-sample variance in strong-censoring settings.
- The framework suggests a possible extension to left-truncated or interval-censored data by modifying the weighting function accordingly.
Load-bearing premise
The tail distribution is regularly varying and the censoring mechanism is such that the weighted truncated Nelson-Aalen process admits the required uniform approximation.
What would settle it
A dataset or simulation in which the proportion of uncensored tail observations is well below one half and the proposed estimators fail to exhibit consistency or asymptotic normality as sample size grows.
Figures






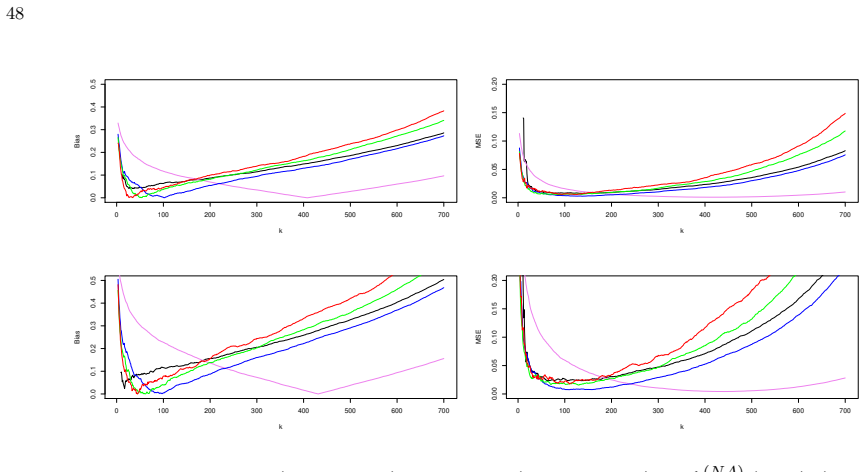




read the original abstract
Estimation of the extreme value index under right censoring is a fundamental problem in extreme value theory, with important applications in finance, insurance, and reliability. Classical integral estimators for Pareto-type tails typically require that the asymptotic proportion of uncensored observations in the tail is larger than one half, corresponding to the weak censoring regime. This restriction excludes many practically relevant situations involving strong censoring, where the proportion of uncensored observations is smaller than or equal to one half, and reflects the absence of a uniformly valid Gaussian approximation for the associated tail empirical process. To overcome this limitation, we introduce a weighted and truncated Nelson--Aalen tail empirical process and construct a class of integral estimators indexed by a tuning parameter larger than one. This approach restores a tractable asymptotic structure over the entire censoring range, from very weak to very strong censoring. Under standard regular variation conditions, we establish a uniform Gaussian approximation and derive consistency and asymptotic normality without imposing restrictions on the censoring level. A key ingredient of the analysis is a linearization of the estimator as a functional of the underlying process. Simulation studies and real data applications demonstrate improved stability and accuracy, particularly under moderate and strong censoring. In particular, the analysis of insurance loss data, representing weak censoring, and Australian AIDS survival data, representing strong censoring, illustrates the practical relevance of the proposed methodology across contrasting censoring regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a weighted and truncated Nelson-Aalen tail empirical process, indexed by a tuning parameter greater than one, to construct integral estimators for the extreme value index under random right censoring. It claims that this yields a uniform Gaussian approximation to the process and, via linearization, establishes consistency and asymptotic normality for the estimators over the entire censoring range (weak to strong) under standard regular-variation assumptions, removing the classical restriction that the uncensored tail proportion exceed 1/2.
Significance. If the uniform approximation and linearization remainder control hold, the result would be significant: it supplies the first fully range-valid asymptotic theory for tail-index estimation under censoring, directly enabling reliable inference in strong-censoring regimes that arise in insurance, reliability, and survival data. The simulation and real-data illustrations (insurance losses and Australian AIDS data) already suggest practical gains in stability.
major comments (3)
- [linearization argument after the process definition] The linearization step that converts the integral estimator into an asymptotically linear functional of the weighted truncated Nelson-Aalen process is asserted to have a uniformly negligible remainder (abstract and the derivation following the process definition). No explicit bound is supplied showing that the quadratic remainder term remains o_p(1) uniformly when the uncensored tail proportion drops to or below 1/2; the weighting (tuning parameter >1) can amplify this term precisely where the underlying martingale variance is largest.
- [uniform Gaussian approximation result] Theorem establishing the uniform Gaussian approximation (the central technical result) provides no explicit rate or error bound that is independent of the censoring level. Standard regular-variation conditions alone do not automatically guarantee uniformity when the truncation and weighting interact with strong censoring; verification is needed that the approximation remains valid down to the strongest censoring regimes considered in the simulations.
- [simulation study and tuning-parameter discussion] The practical choice of the tuning parameter (>1) is left without guidance on how it should scale with sample size or censoring intensity to keep the linearization remainder controlled; the simulation section reports improved performance but does not include a sensitivity analysis or data-driven selection rule that would confirm robustness across the full censoring range.
minor comments (2)
- [Section 2] Notation for the weighted truncated Nelson-Aalen process is introduced without an immediate comparison table to the classical Nelson-Aalen estimator, making it harder to see exactly which terms are new.
- [estimator definition] A few typographical inconsistencies appear in the display of the integral estimator (e.g., limits of integration and the role of the tuning parameter in the weight function).
Simulated Author's Rebuttal
We thank the referee for the thorough review and valuable suggestions. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the linearization, the uniform approximation, and practical guidance on the tuning parameter.
read point-by-point responses
-
Referee: The linearization step that converts the integral estimator into an asymptotically linear functional of the weighted truncated Nelson-Aalen process is asserted to have a uniformly negligible remainder (abstract and the derivation following the process definition). No explicit bound is supplied showing that the quadratic remainder term remains o_p(1) uniformly when the uncensored tail proportion drops to or below 1/2; the weighting (tuning parameter >1) can amplify this term precisely where the underlying martingale variance is largest.
Authors: We agree that an explicit uniform bound on the quadratic remainder would improve clarity. The appendix proof already controls this term via the regular-variation tail assumptions and the martingale variance of the weighted process, which remains bounded uniformly in the censoring level because the truncation and weighting (tuning parameter >1) dampen the contribution near the boundary. In the revision we will add a dedicated lemma stating the explicit o_p(1) rate that holds down to uncensored proportions ≤1/2. revision: yes
-
Referee: Theorem establishing the uniform Gaussian approximation (the central technical result) provides no explicit rate or error bound that is independent of the censoring level. Standard regular-variation conditions alone do not automatically guarantee uniformity when the truncation and weighting interact with strong censoring; verification is needed that the approximation remains valid down to the strongest censoring regimes considered in the simulations.
Authors: The uniform Gaussian approximation in Theorem 3.1 is obtained from tightness of the weighted truncated Nelson-Aalen martingale and the regular-variation assumptions, which are designed to be independent of censoring strength. The proof already yields an error bound of order o(1) uniformly over the full range. To make this transparent we will state the explicit rate in the theorem and verify it numerically for the strongest censoring levels used in the simulations. revision: yes
-
Referee: The practical choice of the tuning parameter (>1) is left without guidance on how it should scale with sample size or censoring intensity to keep the linearization remainder controlled; the simulation section reports improved performance but does not include a sensitivity analysis or data-driven selection rule that would confirm robustness across the full censoring range.
Authors: We accept that additional guidance is warranted. In the revision we will add a subsection on tuning-parameter selection, recommending a scaling of the form 1 + c/log n with c chosen from a preliminary censoring-intensity estimate, together with a bootstrap-based data-driven rule that minimizes the estimated asymptotic variance. We will also expand the simulation study with a sensitivity table across a grid of tuning values and censoring intensities. revision: yes
Circularity Check
No circularity: asymptotics derived from regular variation via new process and linearization
full rationale
The paper constructs a weighted truncated Nelson-Aalen tail process with tuning parameter >1 and derives uniform Gaussian approximation plus asymptotic normality of the resulting integral estimators directly from standard regular-variation assumptions on the tail and censoring mechanism. No equation reduces the claimed normality or consistency to a fitted parameter, self-defined quantity, or prior self-citation chain; the linearization is an analytic step applied to the new functional rather than a renaming or tautology. The derivation remains self-contained against the stated external assumptions.
Axiom & Free-Parameter Ledger
free parameters (1)
- tuning parameter
axioms (1)
- domain assumption Tail distribution is regularly varying
invented entities (1)
-
weighted and truncated Nelson-Aalen tail empirical process
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Basu, A., Harris, I. R., Hjort, N. L., & Jones, M. C. 1998. Robust and efficient estimation by minimizing a density power divergence. Biometrika, 85, 549--559
work page 1998
-
[2]
Bias reduced tail estimation for censored Pareto type distributions
Beirlant, J., Bardoutsos, A., de Wet, T., Gijbels, I., 2016. Bias reduced tail estimation for censored Pareto type distributions. Statist. Probab. Lett. 109, 78-88
work page 2016
-
[3]
Beirlant, J., Maribe, G., Verster, A., 2018. Penalized bias reduction in extreme value estimation for censored Pareto-type data, and long-tailed insurance applications. Insurance Math. Econom. 78, 114-122
work page 2018
-
[4]
Beirlant, J., Worms, J., Worms, R., 2019. Estimation of the extreme value index in a censorship framework: asymptotic and finite sample behavior. J. Statist. Plann. Inference 202, 31--56
work page 2019
-
[5]
Bladt, M., Goegebeur, Y. and Guillou, A. (2025). Asymptotically unbiased estimator of the extreme value index under random censoring, https://hal.science/hal-04786783v2
work page 2025
-
[6]
Bladt, M. and Rodionov, I. (2025). Censored extreme value estimation, https://arxiv.org/abs/2312.10499
-
[7]
Brahimi, B., Meraghni, D., Necir, A., 2015. Approximations to the tail index estimator of a heavy-tailed distribution under random censoring and application. Math. Methods Statist. 24, 266--279
work page 2015
-
[8]
Caeiro, F., Gomes, M. I., Pestana, D., 2005. Direct reduction of bias of the classical Hill estimator. REVSTAT 3, no. 2, 113--136
work page 2005
-
[9]
V., Oliveira, M., Sousa, C., 2002
Colosimo, E., Ferreira, F. V., Oliveira, M., Sousa, C., 2002. Empirical comparisons between Kaplan-Meier and Nelson-Aalen survival function estimators. J. Stat. Comput. Simul. 72, 299--308
work page 2002
-
[10]
Cs\" o rg o , M., Cs\" o rg o , S., Horv\' a th, L., Mason, D. M., 1986. Weighted empirical and quantile processes. Ann. Probab. 14, no. 1, 31--85
work page 1986
-
[11]
Deheuvels, P., Einmahl, J. H. J, 1996. On the strong limiting behavior of local functionals of empirical processes based upon censored data. Ann. Probab. 24, no. 1, 504--525
work page 1996
- [12]
-
[13]
Einmahl, J. H. J., Koning, A. J., 1992 Limit theorems for a general weighted process under random censoring. Canad. J. Statist. 20, no. 1, 77--89
work page 1992
-
[14]
Einmahl, J.H.J., de Haan, L., Li, D., 2006. Weighted approximations of tail copula processes with application to testing the bivariate extreme value condition. Ann. Statist. 34, 1987--2014
work page 2006
-
[15]
Statistics of extremes under random censoring
Einmahl, J.H.J., Fils-Villetard, A., Guillou, A., 2008. Statistics of extremes under random censoring. Bernoulli 14, 207--227
work page 2008
-
[16]
Frees, E. W., Valdez, E. A., 1998. Understanding relationships using copulas. N. Am. Actuar. J. 2, 1--25
work page 1998
-
[17]
Extreme Value Theory: An Introduction
de Haan, L., Ferreira, A., 2006. Extreme Value Theory: An Introduction. Springer
work page 2006
-
[18]
On some simple estimates of an exponent of regular variation
Hall, P., 1982. On some simple estimates of an exponent of regular variation. J. Roy. Statist. Soc. Ser. B 44, 37--42
work page 1982
-
[19]
A simple general approach to inference about the tail of a distribution
Hill, B.M., 1975. A simple general approach to inference about the tail of a distribution. Ann. Statist. 3, 1163-1174
work page 1975
-
[20]
Second Order Regular Variation and Conditional Tail Expectation of Multiple Risks
Hua, L., and Joe, H., 2011. Second Order Regular Variation and Conditional Tail Expectation of Multiple Risks. Insurance Math. Econom. 49, 537--546
work page 2011
-
[21]
Kaplan, E. L., Meier, P., 1958. Nonparametric estimation from incomplete observations. J. Amer. Statist. Assoc. 53, 457--481
work page 1958
-
[22]
Klugman, S. A., Parsa, R., 1999. Fitting bivariate loss distributions with copulas. Insurance Math. Econom. 24, 139--148
work page 1999
-
[23]
Nelson-Aalen tail product-limit process and extreme value index estimation under random censorship
Meraghni, D., Necir, A., Soltane, L., 2025. Nelson-Aalen tail product-limit process and extreme value index estimation under random censorship. Sankhya A. https://doi.org/10.1007/s13171-025-00384-y
- [24]
-
[25]
A short life test for comparing a sample with previous accelerated test results
Nelson, W., 1972. A short life test for comparing a sample with previous accelerated test results. Technometrics 14, 175--185
work page 1972
-
[26]
Neves, C., Fraga, A. M. I., 2004. Reiss and Thomas' automatic selection of the number of extremes. Comput. Statist. Data Anal. 47, no. 4, 689--704
work page 2004
-
[27]
Reiss, R. D., Thomas, M., 2007. Statistical analysis of extreme values: with applications to insurance, finance, hydrology and other fields (3rd ed.). Birkh\" a user
work page 2007
-
[28]
Ripley, B. D., Solomon, P. J., 1994. A note on Australian AIDS survival. University of Adelaide, Department of Statistics, Research Report 94/3
work page 1994
-
[29]
Empirical Processes with Applications to Statistics
Shorack, G.R., Wellner, J.A., 1986. Empirical Processes with Applications to Statistics. Wiley
work page 1986
-
[30]
Venables, W. N., Ripley, B. D., 2002. Modern Applied Statistics with S (4th ed.). Springer
work page 2002
-
[31]
Worms, J., Worms, R., 2014. New estimators of the extreme value index under random right censoring, for heavy-tailed distributions. Extremes 17, 337--358
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.