Recognition: no theorem link
Polyhedral Instability Governs Regret in Online Learning
Pith reviewed 2026-05-14 20:17 UTC · model grok-4.3
The pith
Regret in online learning over combinatorial actions scales with the square root of the number of polyhedral region switches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
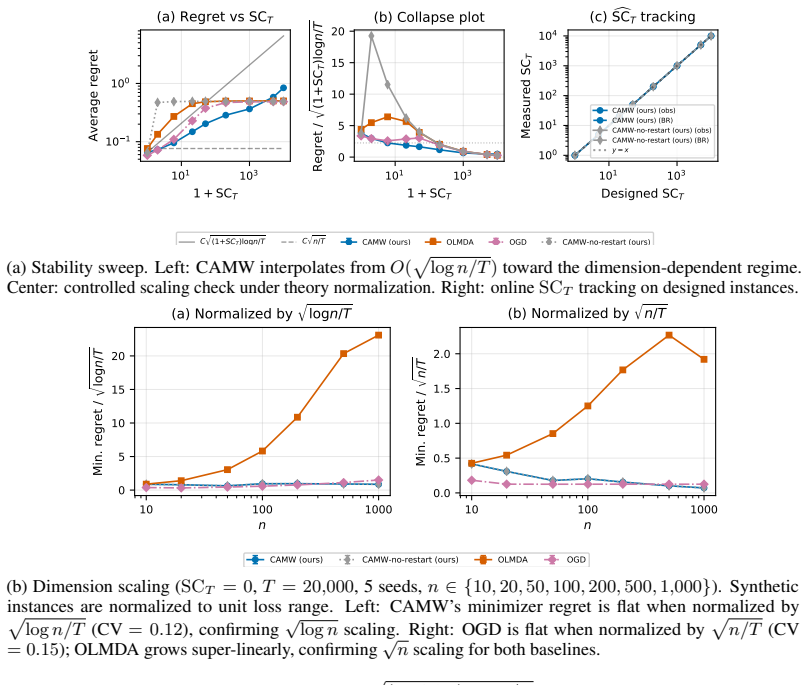
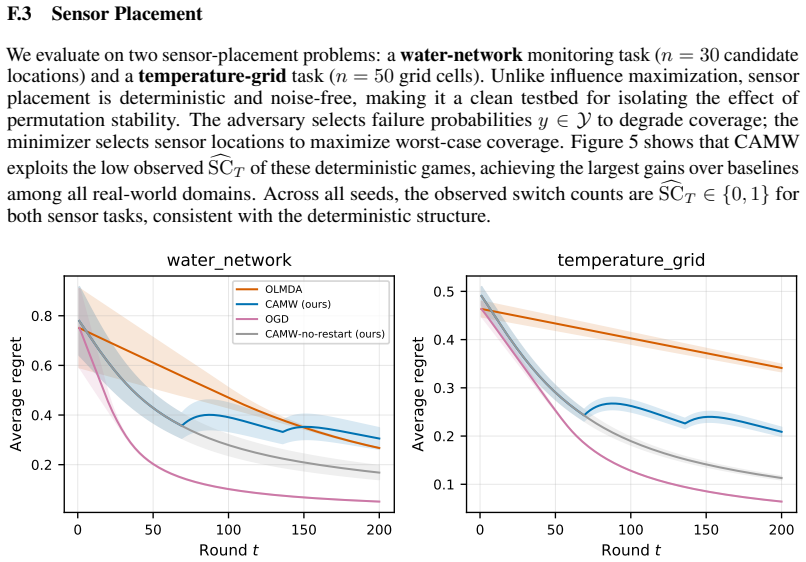
Under full information feedback and fixed partition assumptions, if RS_T denotes the number of region switches and V_max the maximum number of vertices per region, regret satisfies Regret_T = Theta(sqrt((1 + RS_T) T log V_max)), interpolating between experts-like and dimension-dependent OCO rates. For online submodular-concave games under Lovasz convexification the same argument reduces the bound to Theta(sqrt((1 + SC_T) T log n)) where SC_T counts permutation switches.
What carries the argument
polyhedral instability, measured by the count of changes in the active linear region of the convex relaxation
If this is right
- When region switches stay bounded, regret recovers the experts rate O(sqrt(T log V_max)).
- High switch counts push regret toward standard high-dimensional OCO bounds.
- In Lovasz-convexified submodular games regret is governed by the permutation-switch count instead of region switches.
- Low-instability regimes can appear in real combinatorial tasks without explicit action enumeration.
Where Pith is reading between the lines
- Algorithms could be designed to explicitly penalize or avoid region switches to tighten regret.
- The same counting argument may extend to other convex-relaxation settings such as matroid or matching problems.
- Tracking the current active region at runtime might yield practical regret improvements on large instances.
Load-bearing premise
The convex relaxation induces a fixed polyhedral partition that stays stable enough under full information that only the number of region switches matters for the regret analysis.
What would settle it
Measure regret while independently varying the number of region switches across otherwise identical problem instances and check whether the observed growth matches sqrt((1 + RS_T) T log V_max).
Figures











read the original abstract
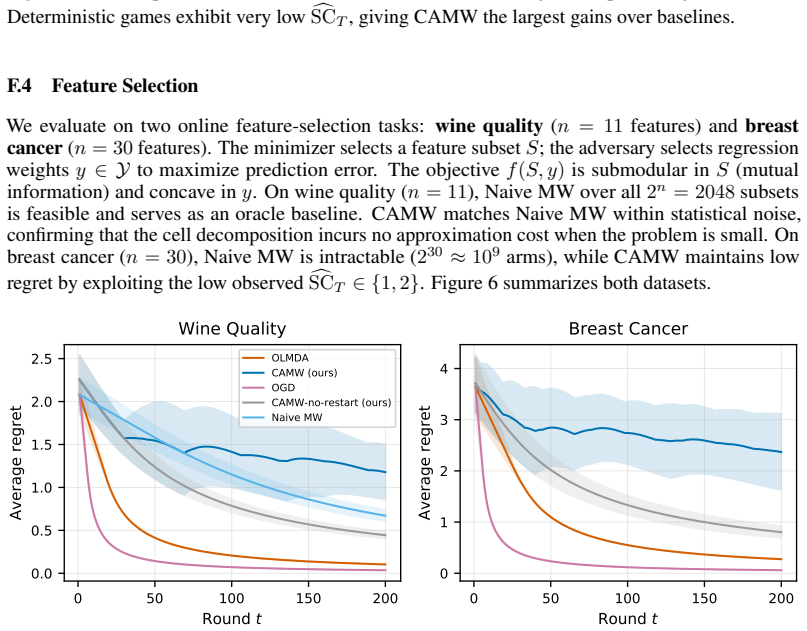
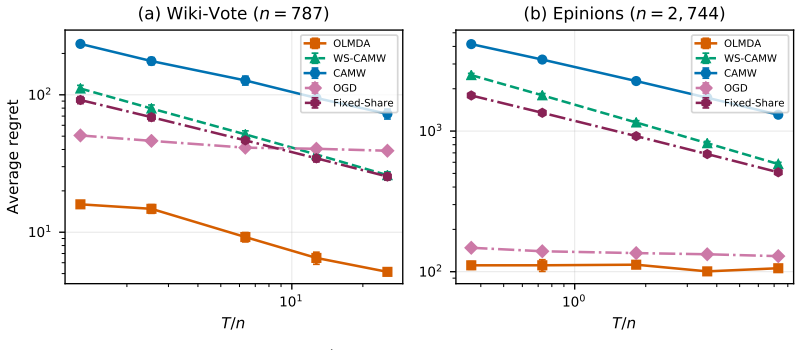
Many online decision problems over combinatorial actions are addressed via convex relaxations, leading to online convex optimization with piecewise linear objectives and induced polyhedral structure. We show that regret in such problems is governed by \emph{polyhedral instability}: the number of changes of the active region. Under full information feedback and fixed partition assumptions, if $\mathrm{RS}_T$ denotes the number of region switches and $V_{\max}$ the maximum number of vertices per region, we prove $\Regret_T= \Theta(\sqrt{(1+\mathrm{RS}_T)\,T\,\log V_{\max}})$ interpolating between experts-like and dimension-dependent OCO rates. For online submodular--concave games under Lov\'{a}sz convexification, this reduces to the permutation-switch count $\mathrm{SC}_T$, yielding the matching rate $\Regret_T= \Theta(\sqrt{(1+\mathrm{SC}_T)\,T\,\log n})$. Experiments on synthetic and real combinatorial problems (shortest path, influence maximization) validate the predicted scaling and indicate that low-instability regimes can arise in practice without explicit enumeration of actions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a new analysis of regret in online learning for combinatorial decision problems that use convex relaxations, resulting in piecewise-linear objectives with polyhedral structure. It introduces the concept of polyhedral instability, measured by the number of region switches RS_T, and proves that under full information feedback and fixed partition assumptions, the regret is Θ(√((1 + RS_T) T log V_max)), where V_max is the maximum number of vertices per region. This bound interpolates between the experts setting and standard online convex optimization rates. For the special case of online submodular-concave games with Lovász convexification, the bound reduces to one involving the permutation-switch count SC_T. The theoretical results are validated through experiments on problems like shortest path and influence maximization.
Significance. If the central result holds, this work is significant because it shifts the focus from traditional regret bounds dependent on dimension or action set size to a more instance-specific measure of instability in the polyhedral structure. The provision of matching upper and lower bounds, expressed in terms of an observable quantity RS_T, allows for better understanding and potentially tighter analysis of regret in practical combinatorial online problems. The reduction to known rates in special cases and the experimental evidence that low-instability regimes can occur naturally add to its value. This could lead to new algorithm designs that minimize region switches.
major comments (3)
- [Main Theorem (likely §3)] The upper bound derivation treats each stable region as an independent experts problem with fixed vertex set, leading to O(√(T log V_max)) per region; however, the manuscript must explicitly confirm that the fixed partition assumption holds for the Lovász extension in submodular games and for the chosen convexifications in the combinatorial examples (shortest-path, influence maximization), as this is the load-bearing condition for the region-switch counting argument to apply.
- [Lower Bound Construction] The matching lower bound of Ω(√((1+RS_T) T log V_max)) is claimed, but the construction of the adversarial sequence that forces this regret while respecting the polyhedral structure and full information feedback needs to be detailed more clearly to ensure it does not rely on additional assumptions beyond those stated.
- [§4 Experiments] While the experiments show scaling consistent with the bound, they do not include measurements or plots of the actual RS_T values observed during the runs, which would be necessary to directly validate the dependence on the instability term rather than other factors.
minor comments (2)
- [Abstract] The notation RS_T and V_max should be defined at first use in the abstract for clarity.
- [Notation] Ensure consistent use of math mode for all symbols like Regret_T throughout the manuscript.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments help clarify the presentation of our assumptions and strengthen the validation of the main result. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: The upper bound derivation treats each stable region as an independent experts problem with fixed vertex set, leading to O(√(T log V_max)) per region; however, the manuscript must explicitly confirm that the fixed partition assumption holds for the Lovász extension in submodular games and for the chosen convexifications in the combinatorial examples (shortest-path, influence maximization), as this is the load-bearing condition for the region-switch counting argument to apply.
Authors: We agree that an explicit confirmation strengthens the argument. For the Lovász extension of submodular-concave games, the polyhedral partition is induced by the fixed ordering of the n elements and remains invariant to the loss sequence. For the shortest-path and influence-maximization examples, the chosen convex relaxations (flow polytope and multilinear extension, respectively) likewise induce fixed vertex sets and facets. We will insert a short dedicated paragraph in Section 3 that states the fixed-partition property for each setting and briefly justifies why the vertex sets do not depend on the online losses. revision: yes
-
Referee: The matching lower bound of Ω(√((1+RS_T) T log V_max)) is claimed, but the construction of the adversarial sequence that forces this regret while respecting the polyhedral structure and full information feedback needs to be detailed more clearly to ensure it does not rely on additional assumptions beyond those stated.
Authors: The lower-bound construction embeds a standard experts lower bound inside each stable region and lets the adversary change the loss vector only when a region switch occurs, thereby forcing exactly RS_T switches while respecting full-information feedback. We will expand the appendix proof with an explicit step-by-step description of the adversarial sequence, including a verification that all loss vectors lie inside the assumed polyhedral partition and that no extra assumptions are introduced. revision: yes
-
Referee: While the experiments show scaling consistent with the bound, they do not include measurements or plots of the actual RS_T values observed during the runs, which would be necessary to directly validate the dependence on the instability term rather than other factors.
Authors: We accept the point. In the revised manuscript we will add (i) time-series plots of the cumulative number of region switches RS_T for each experimental setting and (ii) a table reporting the final RS_T values alongside the observed regret. These additions will allow readers to directly inspect the correlation between measured instability and regret. revision: yes
Circularity Check
No circularity; bound expressed via observable RS_T count under stated assumptions
full rationale
The derivation defines RS_T directly as the combinatorial count of region switches under the fixed-partition assumption and proves the Θ(√((1+RS_T) T log V_max)) regret bound from first principles on per-region expert-like subproblems. RS_T is an independent, observable input quantity rather than a fitted parameter or self-referential definition. No self-citations, ansatzes, or uniqueness theorems are invoked to force the result; the bound simply interpolates standard experts and OCO rates without reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption full information feedback
- domain assumption fixed partition assumptions
invented entities (1)
-
polyhedral instability (RS_T)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bartlett, Alexander Rakhlin, and Ambuj Tewari
Jacob Abernethy, Peter L. Bartlett, Alexander Rakhlin, and Ambuj Tewari. Optimal strategies and minimax lower bounds for online convex games. InProceedings of the 21st Annual Conference on Learning Theory (COLT), pages 415–424, 2008. Available at https://www2. eecs.berkeley.edu/Pubs/TechRpts/2008/EECS-2008-19.pdf
2008
-
[2]
Regret in online combinatorial optimization.Mathematics of Operations Research, 39(1):31–45, 2014
Jean-Yves Audibert, Sébastien Bubeck, and Gábor Lugosi. Regret in online combinatorial optimization.Mathematics of Operations Research, 39(1):31–45, 2014. doi: 10.1287/moor. 2013.0598
-
[3]
Adaptively tracking the best bandit arm with an unknown number of distribution changes
Peter Auer, Pratik Gajane, and Ronald Ortner. Adaptively tracking the best bandit arm with an unknown number of distribution changes. InProceedings of the Thirty-Second Conference on Learning Theory, volume 99, pages 138–158. PMLR, 2019. URL https://proceedings. mlr.press/v99/auer19a.html
2019
-
[4]
Learning with submodular functions: A convex optimization perspective
Francis Bach. Learning with submodular functions: A convex optimization perspective. In Foundations and Trends in Machine Learning, volume 6, pages 145–373, 2013
2013
-
[5]
Combinatorial bandits.Journal of Computer and System Sciences, 78(5):1404–1422, 2012
Nicolò Cesa-Bianchi and Gábor Lugosi. Combinatorial bandits.Journal of Computer and System Sciences, 78(5):1404–1422, 2012. doi: 10.1016/j.jcss.2012.01.001
-
[6]
Online optimization with gradual variations
Chao-Kai Chiang, Tianbao Yang, Chia-Jung Lee, Mehrdad Mahdavi, Chi-Jen Lu, Rong Jin, and Shenghuo Zhu. Online optimization with gradual variations. InProceedings of the 25th Annual Conference on Learning Theory, volume 23, pages 6.1–6.20. PMLR, 2012. URL https://proceedings.mlr.press/v23/chiang12.html
2012
-
[7]
Amir Ali Farzin, Yuen-Man Pun, Philipp Braun, Tyler Summers, and Iman Shames. Solving the offline and online min-max problem of non-smooth submodular-concave functions: A zeroth-order approach.arXiv preprint arXiv:2601.21243, 2026. URL https://arxiv.org/ abs/2601.21243
-
[8]
Yoav Freund and Robert E. Schapire. A decision-theoretic generalization of on-line learning and an application to boosting.Journal of Computer and System Sciences, 55(1):119–139, 1997. doi: 10.1006/jcss.1997.1504
-
[9]
Elad Hazan. Introduction to online convex optimization.Foundations and Trends in Optimiza- tion, 2(3–4):157–325, 2016. doi: 10.1561/2400000013. URL https://www.nowpublishers. com/article/Details/OPT-013
-
[10]
Online submodular minimization.Journal of Machine Learning Research, 13:2903–2922, 2012
Elad Hazan and Satyen Kale. Online submodular minimization.Journal of Machine Learning Research, 13:2903–2922, 2012
2012
-
[11]
Logarithmic regret algorithms for online convex optimization.Machine Learning, 69(2–3):169–192, 2007
Elad Hazan, Amit Agarwal, and Satyen Kale. Logarithmic regret algorithms for online convex optimization.Machine Learning, 69(2–3):169–192, 2007. doi: 10.1007/s10994-007-5016-8
-
[12]
Mark Herbster and Manfred K. Warmuth. Tracking the best expert.Machine Learning, 32(2): 151–178, 1998. doi: 10.1023/A:1007424614876
-
[13]
First-order methods for nonsmooth convex large-scale optimization, I: General purpose methods
Anatoli Juditsky and Arkadi Nemirovski. First-order methods for nonsmooth convex large-scale optimization, I: General purpose methods. In Suvrit Sra, Sebastian Nowozin, and Stephen J. Wright, editors,Optimization for Machine Learning, pages 121–148. MIT Press, 2011. doi: 10.7551/mitpress/8996.003.0007
-
[14]
Nick Littlestone and Manfred K. Warmuth. The weighted majority algorithm.Information and Computation, 108(2):212–261, 1994. doi: 10.1006/inco.1994.1009
-
[15]
Submodular functions and convexity
László Lovász. Submodular functions and convexity. InMathematical Programming: The State of the Art, pages 235–257. Springer, 1983. doi: 10.1007/978-3-642-68874-4_10
-
[16]
Springer, 2003
Alexander Schrijver.Combinatorial Optimization: Polyhedra and Efficiency. Springer, 2003. 11
2003
-
[17]
Non-stationary reinforcement learning without prior knowledge: an optimal black-box approach
Chen-Yu Wei and Haipeng Luo. Non-stationary reinforcement learning without prior knowledge: an optimal black-box approach. InProceedings of Thirty Fourth Conference on Learning Theory, volume 134, pages 4300–4354. PMLR, 2021. URL https://proceedings.mlr. press/v134/wei21b.html
2021
-
[18]
Dynamic regret of strongly adaptive methods
Lijun Zhang, Tianbao Yang, Rong Jin, and Zhi-Hua Zhou. Dynamic regret of strongly adaptive methods. InProceedings of the 35th International Conference on Machine Learning, volume 80, pages 5882–5891. PMLR, 2018. URL https://proceedings.mlr.press/v80/zhang18o. html
2018
-
[19]
awake” (receive loss feedback and participate in the MW update), while experts from other chains “sleep
Martin Zinkevich. Online convex programming and generalized infinitesimal gradient ascent. InProceedings of the Twentieth International Conference on Machine Learning (ICML), pages 928–936, 2003. 12 Appendix Table of Contents A.Background and Structural Foundations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 B.Algorithms and Imp...
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.